交叉表思路
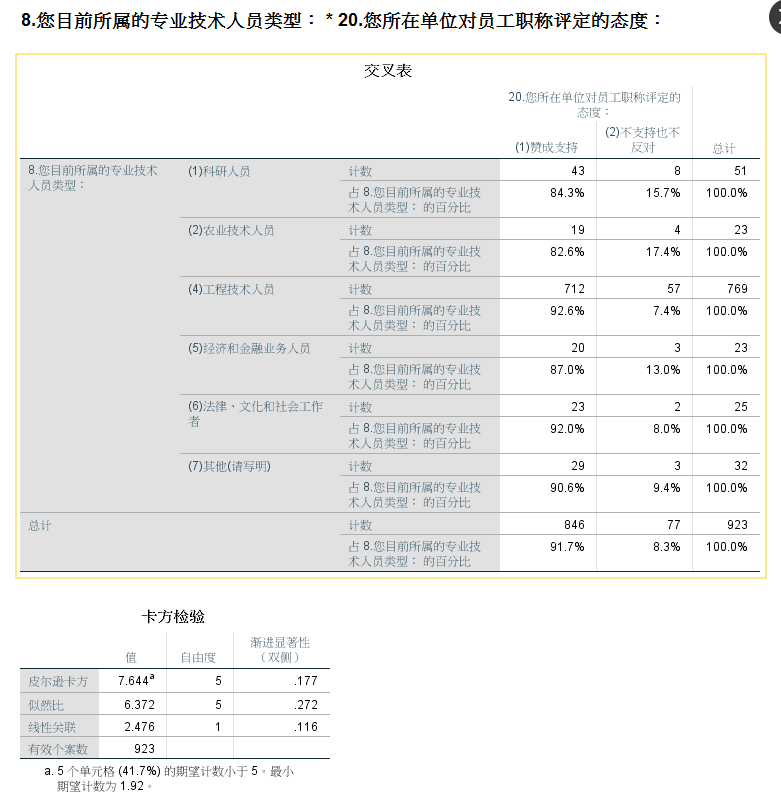

def cross_analysis(variable_list, table_name, sub_area): # print(variable_list) # data = cross_analysis(["TPWL", "TPEB", "TPTOPA"], data_all, area) # TPWL是省份数据, TPEB是X TPTOPA是Y,进行交叉, area是河北, 这里要用全国的数据才可以 # ["Q29_2", "Q42", "Q29_1"] -> ["Q42", "Q29_1"] # 省份 X Y result = read_indexs_by_index(table_name, variable_list) result_sort_data = result.dropna(how='all').sort_values(by=variable_list, ascending=False) # 出现了没有按照顺序columns """ PXD PSM PPL 41 5 8.0 卓资县 229 5 7.0 卓资县 246 5 8.0 卓资县 """ # print(result_sort_data) # 需要算两种值,一个是全国的,一个是局部的。 # 全国的只需要后两个 all_the_country_value_lables = value_lables[variable_list[1]] # 得到的是变量x的 # print(all_the_country_value_lables) # {1: '幼儿园', 2: '小学', 3: '初中', 4: '高中', 5: '职业高中/中专/技校'} cross_dict_data = {"全国": {}, sub_area: {}} for i in all_the_country_value_lables.keys(): # 全国对应值标签的count atc_data = result_sort_data[(result_sort_data[variable_list[1]] == i)].iloc[:, len(variable_list) - 1] # print("全国的:atc_data:\n ", atc_data) """ 可以理解为得到y 1359746 19.0 1347442 17.0 1367416 16.0 1334097 15.0 ... 963347 7.0 可以理解为series """ try: cross_dict_data["全国"][all_the_country_value_lables[i]] = float( "%.4f" % (atc_data.sum() / atc_data.count())) # print("i: \n", i) # print("sum(atc_data): \n", atc_data.sum()) # print("atc_data.count(): \n", atc_data.count()) except: cross_dict_data["全国"][all_the_country_value_lables[i]] = float("%.4f" % (0.0000)) # -----------------------------------------------------------------------------------------# atd_data = result_sort_data[(result_sort_data[variable_list[0]].map(lambda x: (sub_area in x))) & ( result_sort_data[variable_list[1]] == i)].iloc[:, len(variable_list) - 1] # print(atd_data) try: cross_dict_data[sub_area][all_the_country_value_lables[i]] = float( "%.4f" % (sum(atd_data) / atd_data.count())) except: cross_dict_data[sub_area][all_the_country_value_lables[i]] = float("%.4f" % (0.0000)) return pd.DataFrame(cross_dict_data)
作者:沐禹辰
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决