
Mysql 系列 | 性能优化 - 函数调用
sql 性能优化,是代码编写过程中必定要考虑的内容,弄懂性能背后的逻辑,起到事半功倍的效果。
今天学习几种常见的简单优化场景。
条件字段中调用函数
以公司的打卡信息表为例,表中存放了公司近三年的打卡记录,add_time 字段有索引。
查询自己每年 7 月份的打卡情况, select count(*) from works where month(add_time) = 7;
-
发现执行了很长时间才返回结果,是因为 Mysql 中,对字段做了函数处理,就用不上索引了。
-
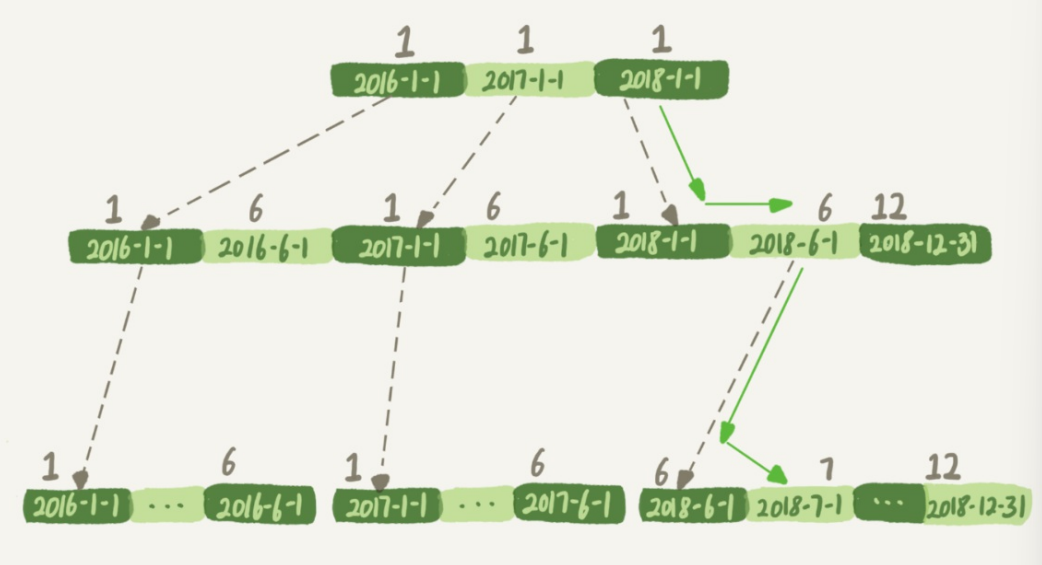
如下图,add_time 的索引图
-
如果使用
2018-7-1条件查询,引擎可以按照图中箭头快速定位到所需要的结果。因为 B+ 树中,同一层兄弟节点是有序的。 -
如果按照
month(2018-7-1)查询的话,当传入条件 7 的时候,在树的第一层就不知道该怎么往下找了。破坏了索引值的有序性,因此优化器决定放弃走树索引。
![image]()
-
-
条件字段加了函数处理后,破坏了索引有序性,这时优化器会选择其他方案。比起主键索引,add_time 索引更小,所以最终还是会选择 add_time 索引,但是会扫描索引的所有值。为了使用索引的快速定位功能,尽量避免破坏索引有序性。
-
即使不改变索引的有序性,有时候也会出现问题。
select * from t where id + 1 = 1000,这种时候优化器也不会用 id 索引快速定位到 999 行。要改成 where id = 1000 - 1。
隐式类型转换
select * from t where tid=110717;
-
tid 有索引,但 eplain 结果显示,进行了全表扫描。此时你会发现,tid 定义的字段类型是 varchar(32),而输入的参数却是整型。因此需要做类型转换。
-
此时实际的 sql 就是,
select * from t where CAST(tid AS signed int) = 110717。和第一种情况相同,对字段做函数处理,优化器放弃了树索引。
隐式字符编码转换
这种情况常在连表查询的时候常见,表 t、d 中 tid 都设置了索引。
select d.* from t, d where d.tid = t.tid and t.id = 2
-
explain 结果显示如下:
-
优化器先在 t 表上查到 id=2 的行,使用主键索引,扫描一行。
-
根据关联字段 tid 去表 d 中查找,第二行 key=NULL,进行了全表扫描
mysql> explain select d.* from t, d where d.tid = t.tid and t.id = 2 \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t partitions: NULL type: const possible_keys: PRIMARY,tid key: PRIMARY key_len: 4 ref: const rows: 1 filtered: 100.00 Extra: NULL *************************** 2. row *************************** id: 1 select_type: SIMPLE table: d partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 11 filtered: 100.00 Extra: Using where -
-
很明显,表 d.tid 的索引没有用上。此时,检查表定义语句发现,两张表的字符集不同。一个是 utf8,另一个是 utf8mb4。
-
utf8mb4 是 utf8 的超集,语句中需要先转换成一致的,才能进行比较。
... where CONVERT(d.tid USING utf8mb4) = t.tid ...。又同第一种情况,经过函数处理后,优化器放弃了树索引。 -
这时,常见的优化方案是将两个字符集都改为 utf8mb4
-
如果无法修改字符集,可以调换驱动表和被驱动表,把函数处理作用在参数值上,也可达到优化的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号