
Mysql 系列 | order by
排序很常见,也很消耗资源,怎么尽可能地降低成本,提高效率!
场景
-
在市民系统的市民信息表中,查询“杭州”的市民信息,并按照姓名排序返回前 1000 人的姓名、年龄
-
城市字段 city 加索引,避免全表扫描
-
SQL 语句,
select city,name,age from t where city='杭州' order by name limit 1000![image]()
(丁奇原图) -
Mysql 中每个线程分配一块内存用于排序,称为 sort buffer,大小由下面的参数决定
mysql> show variables like "sort_buffer_size";
+------------------+----------+
| Variable_name | Value |
+------------------+----------+
| sort_buffer_size | 33554432 |
+------------------+----------+
1 row in set (0.01 sec)
全字段排序
explain select city,name,age from t where city='杭州' order by name limit 1000;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t
partitions: NULL
type: ref
possible_keys: city
key: city
key_len: 51
ref: const
rows: 4000
filtered: 100.00
Extra: Using index condition; Using filesort
-
Extra 中 Using filesort 表示需要排序
-
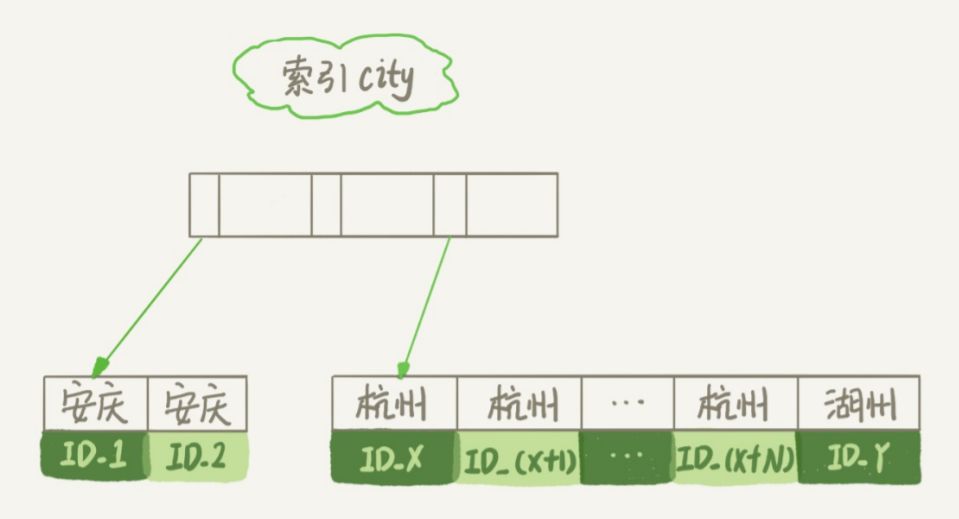
查询语句执行流程如下:
![image]()
(丁奇原图)-
初始化 sort buffer,确定放入 city、name、age
-
在 city 索引中找到满足条件的第一个 ID
-
到 ID 索引中找到完整数据,取出 city、name、age 放入 sort buffer
-
再去 city 索引取下一个 ID,然后回表查询字段放入 sort buffer,知道 city 不满足条件
-
对 sort buffer 中的数据按照 name 进行快排
-
取出前 1000 行数据返回给客户端
-
-
排序的过程,可能在内存中,也可能借助外部排序。如果排序的数据量小于 sort_buffer_size 时,在内存中完成。否则在外部排序(临时文件)
-
当查询返回的字段很多时,sort buffer 中存放的内容很多,内存中放不下,用到的临时表就会很多,排序的性能会很差
rowid 排序
-
当查询的字段很多时,mysql 不会再把所有字段都放在 sort buffer 中。字段长度由下面的参数决定,单行长度超过 4K 时会使用 rowid 排序。
mysql> show variables like "max_length_for_sort_data"; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | max_length_for_sort_data | 4096 | +--------------------------+-------+ 1 row in set (0.00 sec) -
rowid 排序,只把排序列(name)和 ID 放入 sort buffer
-
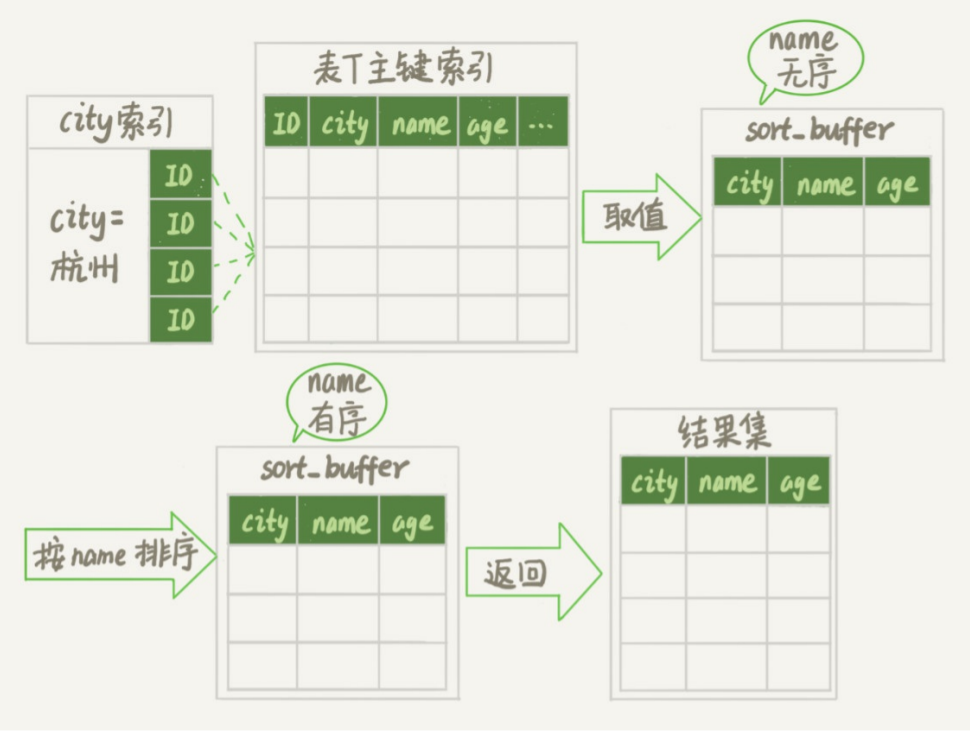
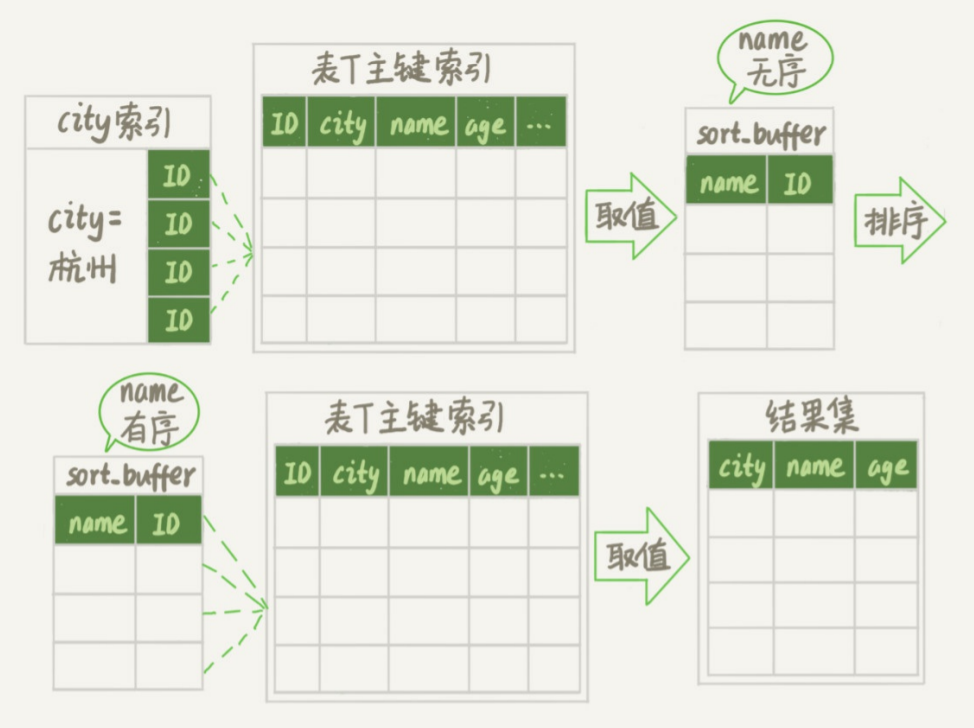
整个执行流程如下:
![image]()
(丁奇原图)-
初始化 row buffer,确定放入两个字段 name 和 ID
-
从索引 city 中找到满足条件的第一个 ID
-
回到主键索引中找到 name、id 放入 row buffer 中
-
再去 city 中找到下一个 id,回表找到 name、id 放入 sort buffer 直到不满足条件
-
sort buffer 中的数据按照 name 字段进行排序
-
遍历排序结果,取前 1000 行,按照 ID 值回表取得 city、name、age 返回给客户端
-
-
因为没有把需要的内容放入 row buffer,所以需要两次去主键索引找数据。
-
mysql 中,内存不够才会采用 rowid 排序,否则优先选择全字段排序,减少磁盘读写。
借助索引无需排序
-
当有 name 索引时,数据本来就是按照 name 排序的,查询时不再需要排序。
-
创建联合索引,
alter table t add index city_user(city, name);
![image]()
(丁奇原图) -
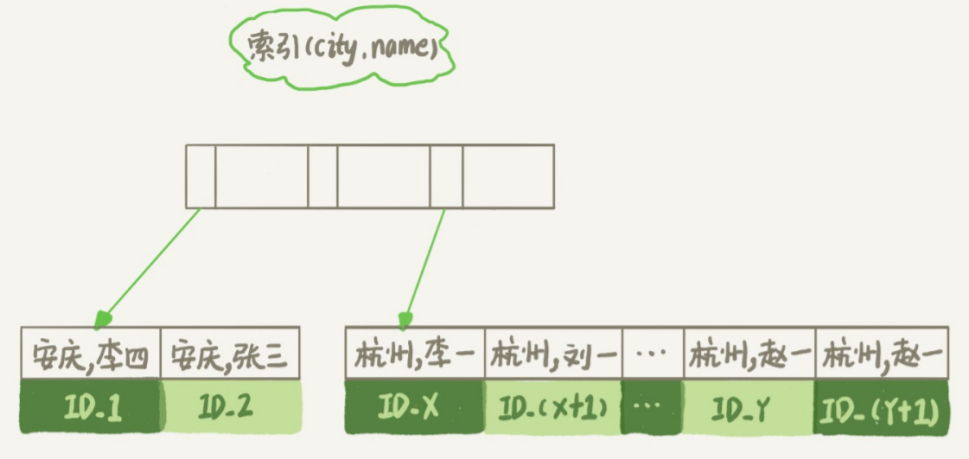
查询流程如下:
-
从 (city,name) 索引中找到满足条件的第一个 ID。
-
回表查到 city、name、age 数据,作为结果集的一部分直接返回。
-
再去 (city,name) 中找下一个 ID,回表查字段数据,以此类推,直到不满足条件时返回
-
-
此时不需要排序,Extra 中没有 Using filesort,扫描行数也将少为 1000
explain select city,name,age from t where city='杭州' order by name limit 1000; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t partitions: NULL type: ref possible_keys: city,city_user key: city_user key_len: 51 ref: const rows: 4000 filtered: 100.00 Extra: Using index condition
覆盖索引优化查询
alter table t add index city_user_age(city, name, age);
-
创建 (city,name,age) 索引,查询流程如下:
-
从 (city, name, age) 索引中找到第一个满足条件的 ID,取出 city、name、age 作为结果集返回
-
再取下一个满足条件的 ID,同样取出三个字段返回,知道不满足条件为止。
-
-
此时,使用了覆盖索引(Extra 中用 Using index),性能提升
explain select city,name,age from t where city='杭州' order by name limit 1000; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t partitions: NULL type: ref possible_keys: city,city_user,city_user_age key: city_user_age key_len: 51 ref: const rows: 4000 filtered: 100.00 Extra: Using where; Using index

 浙公网安备 33010602011771号
浙公网安备 33010602011771号