
Mysql 系列 | 索引(唯一索引 or 普通索引)
索引时数据库优化最常考虑的内容之一,用对索引可以大大提高查询效率。
场景
一个市民系统,每个人都有唯一的身份证号码,
业务代码已经保证了不会有两个重复的身份证号,
系统要按照身份证号查询姓名,
select name from CUser where id_card = 'xxxxxxxyyyyyyzzzzz';
那么,给 id_card 设置索引有几种方式,
-
设置主键索引,因为身份证号字段比较大,所以 pass 掉
-
设置唯一索引 ?
-
设置普通索引 ?
分析
(丁奇原图)
查询过程
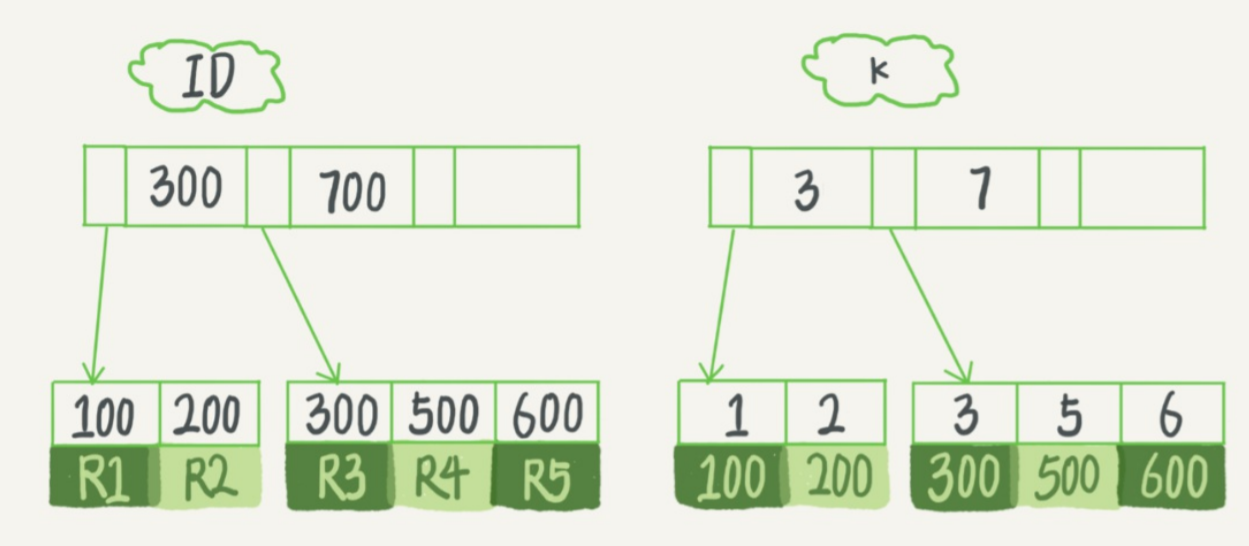
select ID from t where k=5;
-
普通索引,在 B+ 树中从树根开始查找,然后在数据页中二分法定位,当查找到第一个满足条件的数据(5,500)后,会继续往后找,直到第一个不满足 k=5 的位置
-
唯一索引,还是在索引树中查找定位,当找到第一个满足条件的数据后,结束查找。
InnoDB 中,数据以数据页为单位读取。当找到第一个满足条件的数据后,会把一页数据(16k)读入内存中,往后查找都是在内存中进行。所以上面两种索引对性能的影响几乎没有差异。
更新过程
change buffer
-
当需要更新一个数据页时,如果数据刚好在内存中则直接更新;
-
不在数据页时,不影响数据一致性的前提下,InnoDB 会先把更新操作记录在 change buffer 中,下次需要访问这个数据页时,再将数据加载到内存中,然后执行在 change buffer 中与这个数据页有关的操作。加快了 sql 执行速度,也加大了内存利用率
-
change buffer 在内存中有拷贝,也会写入磁盘中,可以持久化
-
将 change buffer 应用到数据页得到新结果的过程是 merge
-
访问数据页会触发 merge,系统后台也会定期 merge,数据库正常 shutdown 也会进行 merge
-
change buffer 使用 buffer pool 的内存,不能无限大,默认最大占用 50%
mysql> show variables like "innodb_change_buffer_max_size";
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| innodb_change_buffer_max_size | 25 |
+-------------------------------+-------+
1 row in set (0.01 sec)
唯一索引
- 有数据更新时,唯一索引需要先判断是否违背唯一性原则,所以都要先把数据页读入内存才能判断,这样更新直接就在内存中完成了,不会用到 change buffer
普通索引
-
当要更新的数据页在内存中,则直接更新
-
还不在内存中,先把更新操作缓存在 change buffer 中,更新结束
-
将数据从磁盘读入内存,是数据库中成本最高的操作之一,change buffer 减少了随机磁盘访问,对性能的提升很明显
索引选择
-
唯一索引和普通索引在查询方面差别不大
-
对于写多读少的业务(账单、日志等),使用普通索引结合 change buffer 收益很大
-
对于读多写少的业务,操作写入 change buffer,读时立马又会触发 merge,不但没减少 I/O,反而增加了 change buffer 的维护代价,得不偿失。
正确选择索引,事半功倍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号