


PID算法-从单级PID到单神经元自适应PID控制器
0.0 写在前面的话
这是一篇我在学习PID控制算法的过程中的学习记录。在一开始学习PID的时候,我也看了市面上许多的资料,好的资料固然有,但是更多的是不知所云。(有的是写的太过深奥,有的则是照搬挪用,对原理则一问三不知)这一直让我对PID摸不着头脑。所以我打算从0开始去一层层学习它,直到自己掌握它的精髓。我不认为我有多聪明,所以相当多的部分我都写的很详细,觉得过于冗余的小伙伴可以跳着看。我并不是计算机科学\电控类专业的学生,所以对知识的理解可能有不到位的地方,还请大家指正。
最后,希望这篇长文对大家有所帮助,这也是我完成它的目标之一。
1.0 单级PID控制
1.1 单级PID的原理理解
这里强烈建议还不理解PID基本原理的同学观看视频:https://www.bilibili.com/video/BV1xQ4y1T7yv
单级PID也就是只使用一个PID控制块。一般讲到PID,大家都喜欢用调节洗澡水的水温来举例:
-
Kp(比例项),即希望调节到的温度与现在的温度差的越大,我们拧动加热旋钮的幅度就越大,这个差值越小,我们拧动加热旋钮的幅度就越小;
-
Ki(积分项),即P比例调节控制了一段时间之后,发现实际值与期望值还是有误差,那就继续拧懂加热旋钮,这是一个在时间上不断累积的过程,故为积分项;
-
Kd(微分项),当实际值与期望值的误差的导数,也就是水温变化的速度,这一项即控制达到期望值,即控制当前水温到达目标水温的速度。
然后将上面三项相加,就得到了基本的PID控制:
即下图
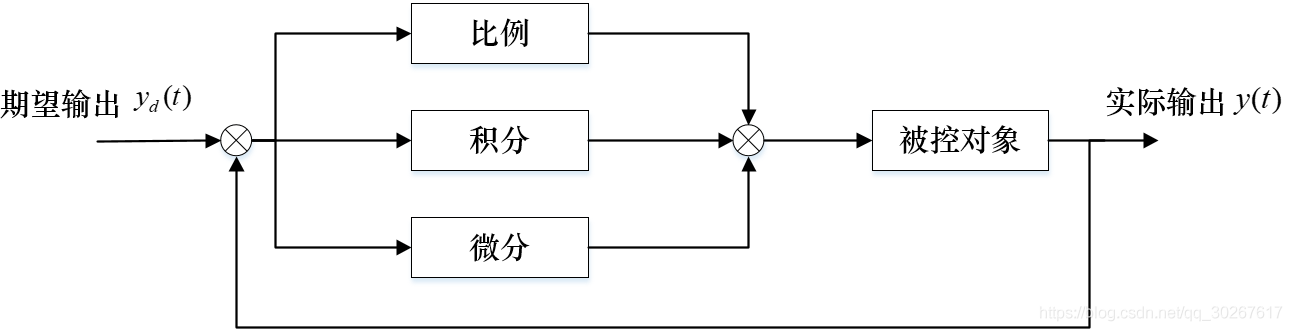
谈谈我对于PID控制的一些理解:
- 首先面对一个需要PID的控制系统的时候,增大P(比例控制系数)可以使得系统的反应灵敏,但是相应地会无法避免地产生稳态误差并且单纯使用比例控制的系统无法消除这种误差;
- 在得到一个较为灵敏同时拥有较小的稳态误差的系统时,这时引入I(积分控制项),积分控制可以有效地消除稳态误差,但是会使得系统达到稳态的时间延长,也是就是出现了震荡;
- 在PI控制完成之后,一般来说对于一些对时间不是很敏感的系统都已经拥有较好的控制表现了,对于时间要求苛刻的系统就需要引入D(微分控制项)来进一步缩短系统达到稳态的时间(减少震荡);
- D项的一个很不友好的特性就是对环境噪声极其敏感,引入D之后很容易就会使得先前已经稳定的系统突然变混乱起来,所以通常也需要较多的时间类来获取试验D的取值。
以上就是一个简单的PID控制系统的介绍。从实现来看,其实有着两种不同的实现方式,一种叫位置式PID,另外一种则为增量式PID。其中位置式PID我较少在平衡控制等项目中见过,而增量式PID则大量运用在电机的控制上(驱动平衡类项目),下面来简单说一下这两种PID控制的实现。
1.2 单级PID的代码实现
其中我们知道PID的公式如下:
但是我们会选用下面这个式子来进行实际的工程运用。可以看到除了积分变为累加之外(毕竟现实中数据都是一段一段不是连续的),D(微分项)中的形式变了,这是为了避免一个被称为“微分冲击”的现象,具体的原因在系列3中会有提到,这里可以暂时不去管它。
这里使用的是以tank_like模型(即四个电机的角度固定,靠转动的差速转弯的小车模型,与之相对的是Car_like模型,前面两个轮子可以偏转一定角度转弯)的四轮小车为例,需要控制其四轮转动同步(也就是能走直线)。
tank_like模型与Car_like模型:


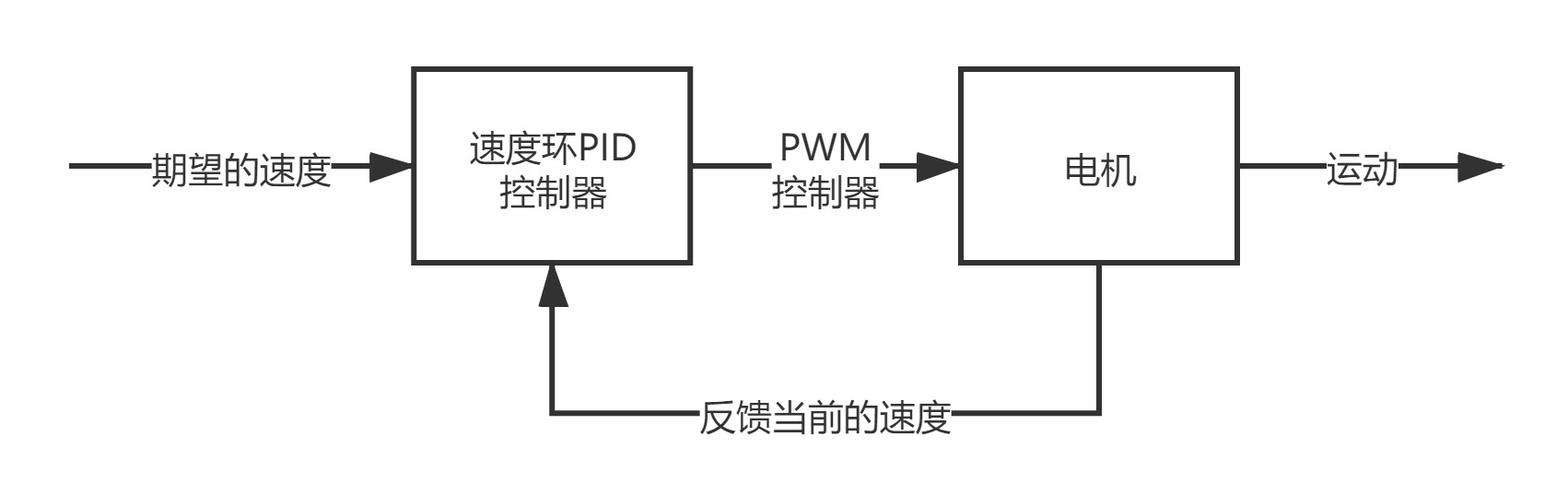
为了能够判断小车每个轮子的转动方向以及转动的幅度,需要使用带有编码器的电机,或者使用光电门也是同样的原理。这样就能获取到小车每一个轮子的实时速度值,与目标的速度 作差 后就是这个PID系统的输入。
而小车上单片机向电机输入的PWM波(可以控制小车电机油门),就这个PID系统的输出。
如下图:
//位置式PID
//定义所需要的变量
float Kp, Ki, Kd;
float Motor1_speed;//电机当前的速度
float target_speed;//我们需要电机达到的速度
float err_now;//当前速度与电机期望值的差,也就是当前的误差值
float err_last;//上一次计算的误差值
float err_Sum;//积分项,将累计时间内所有的误差值
float output;//经过PID算法后输出的数据,其实是一个控制PWM占空比的参数,我们只需要直接放在输出PWM的函数里就好了
//PID算法
err_now = target_speed -Motor1_speed;
err_Sum += err_now;
if(err_Sum > x) err_Sum = x;//这里需要设定一个极限值,以防积分变量溢出,其实一般来说并不会达到这个极限值,因为误差并不都是正数
//没有对D进行操作
output = Kp * err_now + Ki * err_Sum +Kd * (err_now - err_last);//PID公式
if(output > x) output = x;//这里需要对输出也进行一个限制,这里倒不是限制溢出,而是PWM输出的参数本身就有最大值,超过了就无效了。
TIM_SetCompare1(TIMx, output);//对产生PWM的定时器通道一进行输出
err_last = err_now;//将使用完的当前误差值赋给上一次的误差值,进行下一轮循环
增量式PID的原理就是不直接使用每一次PID产生的输出,而是将两次PID产生的输出相减,得到一个PID增量,再使用这个增量对系统进行输出。与位置式PID不同的地方就在于因为需要使用到前后两次的PID公式,那么也就需要当前误差、上一次误差与上上次的误差。在得到输出的增量之后就类似使用积分项一样直接将时间上的每一次增量相加,得到的结果在TIM_SetCompare1()中输出就可以,代码就不赘述了。
2.0 串级PID控制
2.1 串级PID的原理理解
有单级PID,那么也就一定会有串级PID。其实串级PID就是在原先的PID控制块的前面再接一个PID控制块,叫做外环,内外环串接起来就是大概下面这个样子: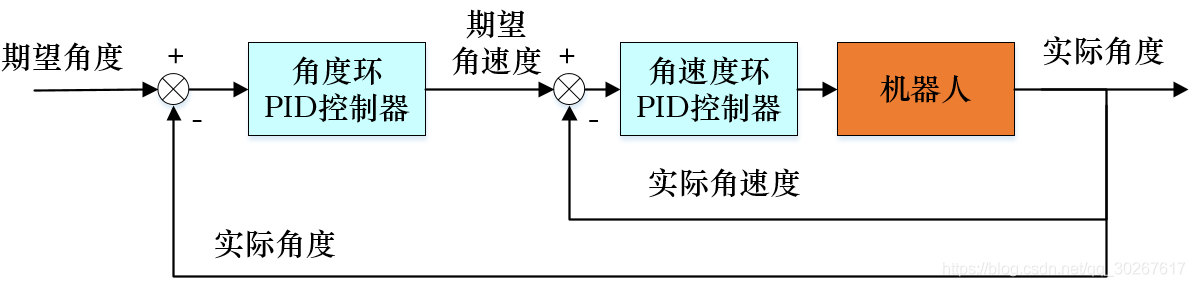
前面的控制块里面放着什么,以及其他的输入都先不用管,一步步来。
首先需要回答的第一个问题就是我们为什么需要串级的PID?
还是使用上面四轮小车作为例子说明。先不管我们建立的第一个PID模型,只看小车这一个整体,我们可以控制的是小车的速度。而小车这一个系统的任务可以有许多,其中就比如到达某一个具体的位置。我们虽然能够使用单级的PID系统控制小车的速度在某一时刻尽可能快地达到期望值,但是我们是没有办法控制小车的加速度的,除非我们每时每刻都能改变小车速度的期望值。我们所希望的是,当我们给定一个位置,也就是给定一个位移的时候,小车能够尽快地到达,其中小车的运动必然是一开始用较大的加速度做加速运动,快到终点了再用一定的加速度做减速运动,注意,是小车能够自行完成这样的任务。
显然单级PID是无法做到这一点的,所以需要在它的前边再添加一级PID控制器,这个控制器的功能只有一个,那就是提供一个合适的速度变化曲线,使得单级的PID具备前面所说的先加速,后减速的功能。
用数学公式去理解,设位移是S,也就是整个系统最后需要达到的目标,第一级PID直接控制了V,也就是控制了小车当前的速度,在没有外界干预的情况下它只能做匀速直线运动,也就是
那么这个小车到达S的方法是什么呢?是弹射启动与急刹。在启动瞬间达到速度V并且在通过终点的瞬间急刹,从而完成S的位移。但是学过高中物理的人都知道这是不可能的,小车达到速度V需要时间,从V降低速度到0也需要时间。
所以引入第二个PID控制器,它的目的前面说过,是找到合适的曲线来引导速度的变化,也就是小车有了一定的加速度,所以有:
现在就好了,小车就能在一个加速度增大的加速运动与一个加速度逐渐减小的减速运动中(可能是这样吧)平滑地到达终点了,这与上面单级PID不同,这是物理上真实可以实现的。
所以也有一句话是这么说的,外环的微分就是内环。在这个例子中外环实际上提供的就是一条速度变化曲线,在这条曲线上任意一点取微分,就得到了速度,也就是内环控制的物理量。
那么这个合适的速度变化曲线,我们上哪找呢?其实大部分使用的曲线都类似下面这两种:
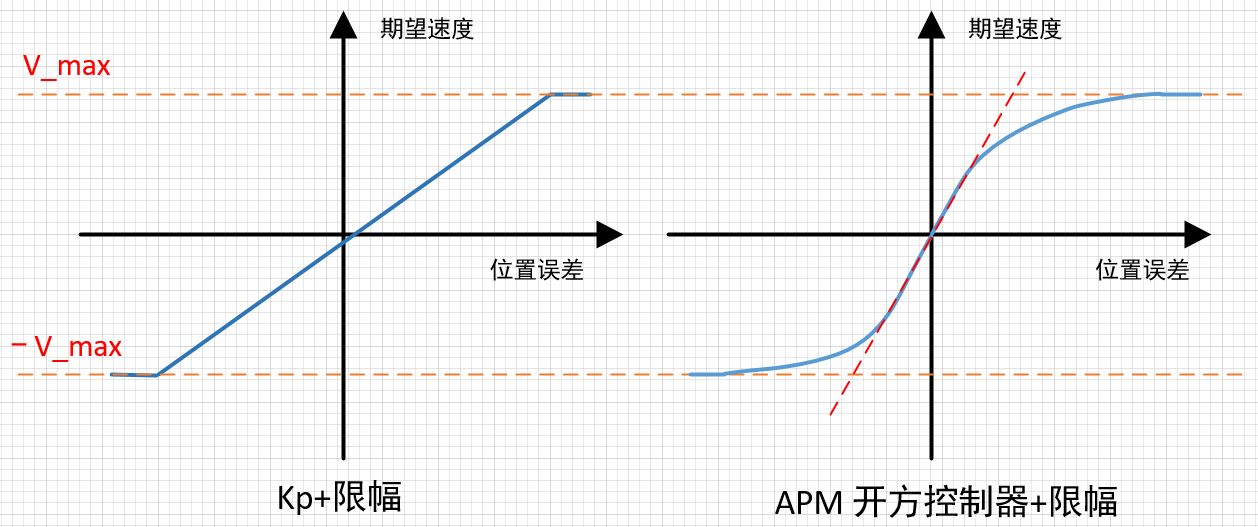
这里的曲线并不是指真的需要输入这种曲线,而是在这个PID控制器中,当参数设定好后,输出的控制结果就类似这种曲线。同时一般在外环中只会引入P(比例),而不使用I(积分)与D(微分),原因是添加I后响应会变慢,添加D后又对噪声敏感,我们要的只是一个大概的曲线,有比例系数控制就足够好了。
现在我们就拥有了一台能够实现下面功能的小车:
给定一个位置,小车可以实现自动控制加减速以一个尽可能短的时间到达终点,期间不需要人的干预
也就是下图的样子:

但是外环PID想要直接获取到当前的位移是比较困难的,所以做下面的处理来间接获取:
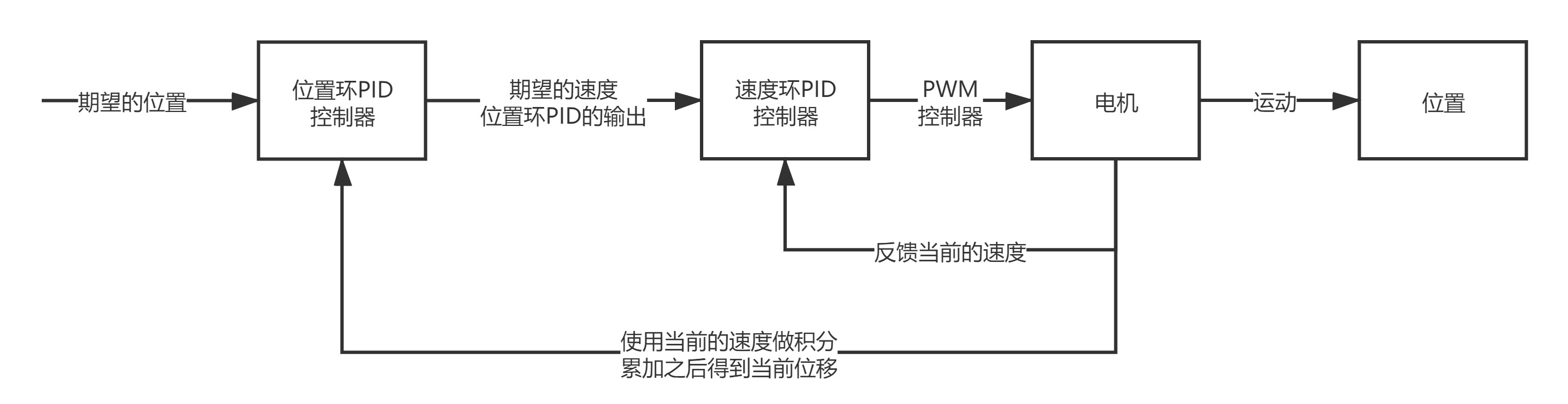
而小车的期望位置则由时间内油门摇杆偏移量的积分来求得。
所以现在我们就有了一个比较好的小车模型。需要注意的是,在这个模型中小车的转向是不受PID控制的,因为并没有相关的陀螺仪传感器来反馈角度与角速度的数据,也就是说小车的转向只能与人眼构成一个闭环系统,我们觉得它转得慢了,就加大油门量;觉得它转的快了,就降低油门量。
在油门量方面,如果通过遥杆来控制,那么小车能够保持直线行驶(没有PID的小车四个轮子的转速没办法达到一致);如果是通过其他的设备(例如上位机等)控制,那么小车不仅能够保证直线行,还能知道自己走了多远,还有多远没走,你让它往前开一米,它就能精确地到达一米的位置。
串级的PID多数用于二轮平衡小车上,在平衡小车上我们就没有办法通过摇杆来控制小车的速度实现小车的平衡了,必须由小车自己结合角度的PID进行融合控制。
那么单纯看二轮平衡小车的位置环设置大概就是下面这样:
当小车静止的时候,小车的期望位置就是原点,反馈的位置就是小车时间内的速度的积分;当小车运动的时候,小车的期望位置就是摇杆的偏移量在时间内的积分,反馈的位置同上。
2.2 串级PID的代码实现
//串级PID
//定义所需要的变量
float Kp_ex; //外环P
float Kp, Ki, Kd; //内环PID
float Motor1_speed; //电机当前的速度
float Position_now; //小车当前的位置,由当前速度积分得出
float target_speed; //我们需要电机达到的速度,外环的输出,也就是内环的输入
float target_position; //我们需要小车达到的位置,由摇杆积分得出
float err_position_now; //当前小车位置的误差
float err_position_last; //上一次小车位置的误差
float err_speed_now; //当前速度与电机期望值的差,也就是当前的误差值
float err_speed_last; //上一次计算的误差值
float err_speed_i; //积分项,将累计时间内所有的误差值
float output; //经过PID算法后输出的数据,其实是一个控制PWM占空比的参数,我们只需要直接放在输出PWM的函数里就好了
//外环PID
err_position_now = target_position - position_now;
target_speed = Kp_ex *err_position_now;//外环的输出就是内环的输入
//速度的限幅处理略
err_position_last = err_position_now;
//内环PID
err_speed_now = target_speed - Motor1_speed;
errspeed__i += err_speed_now;
if(err_speed_i > x) err_speed_i = x;//这里需要设定一个极限值,以防积分变量溢出,其实一般来说并不会达到这个极限值,因为误差并不都是正数
//没有对D进行操作
output = Kp * err_speed_now + Ki * err_speed_i +Kd * (err_speed_now - err_speed_last);//PID公式
if(output > x) output = x;//这里需要对输出也进行一个限制,这里倒不是限制溢出,而是PWM输出的参数本身就有最大值,超过了就无效了。
TIM_SetCompare1(TIMx, output);//对产生PWM的定时器通道一进行输出
err_speed_last = err_speed_now;//将使用完的当前误差值赋给上一次的误差值,进行下一轮循环
3.0 算法之外
3.1 PID的优化
PID的使用不仅仅包含PID算法本身,算法之外,依然有着足够多的问题让我们头疼。这些问题依次排序如下:
1.PID的调用频率
2.微分冲击
3.PID的开关
4.PID的反向工作
3.1.1 调用频率
PID控制并不是随时随地都能调用的。PID的工作频率必须在合理的范围之内才能让系统正常工作,而每一个系统的PID工作频率又是不一样的,那么究竟要如何确定工作频率呢?
首先对于小车的电机来说,拥有着最大瞬时转速、编码器最快测量时间间隔等参数,而在电机测速编码器反馈电机转速的间隔内,系统是不知道这一时刻小车的速度的,也就是说在这一段时间内PID的输出控制是无效的,而一般来说,单片机内定时器可以产生的定时间隔远小于测速编码器的反馈间隔,所以如果将PID的工作频率设置得过高的话,对于单片机来说并没有什么问题,而对于实际的系统来说,就会多出很多个无效的PID控制输出,容易导致系统的工作混乱。
所以在实际中确认PID的工作频率时,需要确定好反馈机构的工作频率,PID的工作频率与其接近即可。
3.1.2 微分冲击(Derivative Kick)
由于输入PID控制器的量是期望值与当前值之差,期望值的任何变化都会引起差值的瞬时变化。这种变化在时间上的导数使得它会变成一个很大的数字,从而导致PID的输出出现了尖峰,尖峰在引入D(微分项)后变得尤为明显,这种尖峰就是微分冲击:
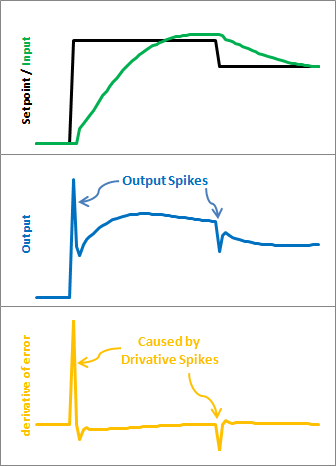
有许多种方法可以解决这种问题,例如输出过滤等等,在这里我介绍的是一种被称为"测量导数"的方法。
从系列的第一节我们知道,PID的方程如下:
我们要对付的就是D项。我们知道:
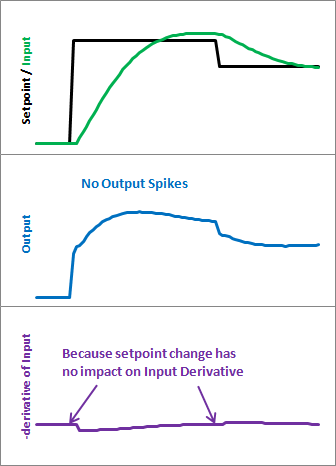
当\(target\)在时间上为一个常数,或者说在一定时间内\(target\)为一个常数的时候,该项导数为0,这个式子就不再会因为\(target\)产生尖峰了。所以在PID方程变成了下面这个样子:
所以在实际的编程中,\(\frac{d}{dt}feedback\)就等于当前的反馈与上一次反馈相减。
而在我们一般使用的PID方程
最后面的做差也是类似的原理。
当如此处理过后,就会有下面的效果:
3.1.3 PID的开关
有些时候,我们可能会需要关上PID控制块,让系统进行开环输出,或者说由于某种特殊的原因我们必须在某一个时刻输出某些特定的值,这个值不得不将PID的输出值覆盖掉。
单纯不调用PID控制块来解决这个问题可能会使得这一个小小的举动引发PID的剧烈反应。
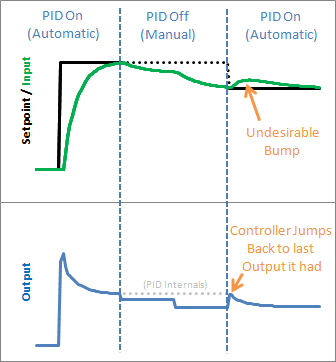
想象一下:PID控制块在控制着一个机器人跑步,PID当然可以完成的很好:它可以把某个期望速度与自己当前的速度做差来进行PID运算,分毫不差就能以期望速度跑上个十万八千里。但是你突然把PID的控制权给撤了,同时让机器人静止。PID吓呆了,它明明一直在输出控制信号,但是机器人丝毫不动!于是PID可能会觉得,我得加把劲。当你在某一瞬间突然又把控制权移交给PID时,PID早就以一种不可知的方式运行了好一阵子,那一瞬间的输出对于机器人来说可能是致命的,也许它会像疯子一样瞎窜,又或许它会直接宕机。
所以我们需要一种合适的方式去开关PID控制块,一种最为简单的关闭方式就是在PID的算法函数中的最前方放置一个开关,如果不使用PID,直接return;即可。这避免了PID在认识到输出有异样之前就将其停用了。但是与之相对的问题就又出现了,当PID再次开启的时候,PID就会使用最后一次使用的数据重新开始调整,这就会导致PID初始化出现尖峰。
面对这个问题,我们还是从方程开始讲起:
我们可以看到需要过去的误差的项有I、D项,P项只与当前的误差有关,所以我们处理的对象就是I、D项。我们需要在重新调用PID前,使得:
err_last = err_now;
Ki*err_Sum = Output;
第一行使得微分项为0,避免出现微分冲击;第二行的解释如下:
在PID的系统中,随着时间流逝系统在不断地运行,当系统稳定且时间足够长之后,整个系统的输出占比最大的应是积分项。比例项与微分项都完成了相应的任务,一个是调整系统达到期望的输出幅度大小,现在系统已经稳定,所以这个幅度约等于0;一个是调整系统达到期望所需的时间,系统已经稳定,所以这个时间还是约等于0。维持系统输出的就是I项中所累加的err_Sum.所以当一个系统需要重新启动的的时候,就将需要达到稳态的输出的值直接赋予给I项,这样就模拟出了一个系统已经达到稳态的结果,系统再次回到该稳态环境的时候也就不会出现大幅度的波动了。
3.1.4 PID的反向工作
前面我们讨论的似乎都是让PID去正向地控制某个物理量,但是还没有提及过让PID反向地控制它们————例如让你充满热水的浴缸重新冷下来。
为了达到这一个目的,我们可以将PID中的三个参数\(K_{P}\)、\(K_{I}\)、\(K_{D}\)都取相反数再做运算,但是相对来说更为简单的方法是让期望与反馈本身就可取负值,这样代入方程之后所取得的结果就能反着来啦。
写在最后面的是一个我的困惑。我看到有作者分享出,PID系统应该具备在运行过程中改变PID参数而保持系统稳态的能力,我不理解这有什么具体的用处,如果有读者明白的话,请务必告诉我,谢谢啦。
4.0 PID的软件在线仿真
如果你还没有经历过调整PID参数的日子,那么你可能不会知道这让人多么抓狂。不管如何编写PID算法,调整PID参数永远都是一件比较麻烦的事情。人们喜欢用“炼丹”来形容深度学习调参的过程,在我看来PID调参也大有几分相似的味道。
那么有没有什么办法来解决这一个难题呢?有,甚至还不止一个。
现在呈现在我们面前的就是其中之一:利用软件自整定PID参数,一般称为PIDAutoTurner.
4.1 原理理解
首先为了完全掌握这种方式,我们还是从原理入手。
还是拿出我们的PID方程:
这个就是我们PID系统的微分方程描述.为了使用方便,我们对它的两端进行拉普拉斯变换,得到下面这个式子:
其中这\(K_{P}\)、\(K_{I}\frac{1}{S}\)、\(K_{D}S\)就分别是图中的比例、积分与微分:
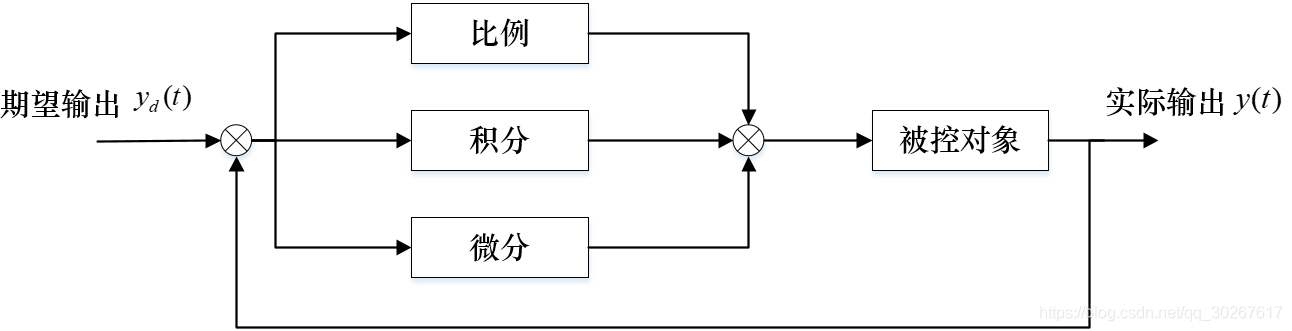
如果你不理解什么是拉普拉斯变换与传递函数,那么请接着看:
传递函数是指零状态下线性系统的响应(就是系统输出)拉普拉斯变换与激励(就是系统的输入)的拉普拉斯变换的比,记作:
其中\(G_{(s)}\)、\(Y_{(s)}\)、\(U_{(s)}\)分别是传递函数、输出与输入。
其实拉普拉斯变换的作用就是为了确定系统的输出响应\(G_{(S)}\),当一个系统的传递函数已知的时候,我们给定系统的输入\(U_{(S)}\),那么系统的输出响应\(G_{(s)}U_{(s)}\)就可以使用拉普拉斯反变换来直接求出。
你问为什么不直接用微分方程来求?我的理解就是图个方便……微分方程在求解多元问题上是非常麻烦的。
现在我们有了描述该系统的传递函数,也就是说只要有输入,我们就可以得到输出了。
现在如果将这个传递函数导入相应的软件(例如大名鼎鼎的Matlab,更具体来说应该是里面的工具箱simulink),那么软件就能不断地产生阶跃输出,与传递函数进行运算之后直接将输出结果呈现在我们面前,或者软件还能够自己判断一下输出的好坏,自行调整PID的参数,尽量将输出弄得漂亮一些,我们只需要在软件判断完成之后导出PID参数就好,这就是软件的PID自整定。
但是还有一个问题没有解决:虽然使用的PID方程是一致的,但是每一个系统都因为系统本身的性质不同,而导致其传递函数的不同。我们没办法依靠一个还没有参数的PID方程来推导出一个系统的传递函数。
所以我们需要大量的有关于此系统的输入与输出数据。拥有了足够多的数据之后,辅以自带的计算模型(什么积分滞后器啦、二阶系统啦等等),软件就能够通过大量的计算来还原这个系统的传递函数。
我们获取这些数据也不难,我们只要暂时让系统开环控制,然后不断地给系统输入阶跃信号:

说人话就是不断给系统期望值,同时记录系统的输出信号,以软件规定的格式把二者对应地记录下来即可。
软件自整定的原理差不多就是这些东西啦。
下面我们可以练练手。
4.2 利用Simulink软件自整定
Matlab是这个时代一项伟大的工具,其中Simulink工具箱更甚。Simulink几乎可以仿真任何物理模型,它不能做的可能只有为你生孩子了。
咳,simulink作为一款专业的仿真软件,它所具备的仿真精度肯定大于目前所知道的其他自整定软件,所以首先来介绍simulink的使用方式。
见下面的链接:https://www.guyuehome.com/17352
4.3 利用Web端工具自整定
我感觉国内好像还没有多少人知道这个网站,感觉上有可能是分享它的第一人所以有点兴奋哈哈哈(bushi)
使用方法的话,如果你看过了上边使用simulink仿真的部分,那么这一部分我相信大多数人都是可以无师自通的了。毕竟跟simulink黑压压的一大片按钮与输入栏相比,这个网站简直就小清新得不要不要的。
具体的效果我并没有实践过,但是从社区的反响来看,效果还是非常不错的,具体的实验就还是很留给大家试验啦.
下面给出链接:https://pidtuner.com
5.0 单神经元自适应PID控制器
写了前面几篇文章,其实面对大部分的场景来说应该是够用了,但是在PID中还有一个自适应版本的PID让我觉得十分神奇,所以打算把这个算法也填一填坑。
如今神经网络研究的火爆也让许多的控制领域学者开始将神经网络与自动控制相结合起来,其中的原因主要是神经网络的几大特性:
-
能够以任意的精度逼近任意连续非线性函数;
-
对复杂不确定的问题具有自适应和自学习的能力;
-
并行的信息处理机制可以解决控制系统中大规模的实时计算问题,并且并行机制中的冗余性可利用使得控制系统拥有很强的容错能力;
-
具有很强的信息综合能力,能同时处理定量和定性的信息,能很好地协调多种输入信息的关系,适用于多信息融合和多媒体技术;
下面我们就一起来看看这个神奇的控制器是怎么来的。
5.1 什么是单神经元自适应PID控制器?
单神经元自适应PID控制器就是使用单神经元控制的,可以实现自行调整系统PID参数的PID控制器。
其实自适应的PID还有其他的控制方式,本篇文章就只是介绍以单神经元控制的自适应PID控制器。(下文简称自适应PID控制器)
5.2 为什么需要自适应PID?它与传统PID控制器的区别是什么?
自适应PID与普通的PID算法最大的区别就是它能够根据系统的性质的改变从而自行调整PID的参数,而普通的PID算法则无法做到这一点。
在工业控制上,有很多的PID系统的运行时间极长,与我们平时做的平衡小车等玩意不同,工业设施在长时间的运转过程中其自身的物理性质是很容易发生改变的,比如更换了不同的零件、设施本身发生了腐蚀等等。一旦物理性质发生了改变,那么原来出厂时设定的PID参数就不是当前系统的最佳设定了。而如果设施采用的自适应的PID算法,它就能在运行的过程中不断修正自己的PID参数设定,从而保证系统一直都工作在最佳的状态。
综合看来,自适应PID的强大之处在于其的自适应能力,后面会详细介绍它是如何实现的。首先我们先从神经元开始讲起。
5.3 神经元与学习规则
-
脑袋中的神经元
神经元的大致结构就像下面这样: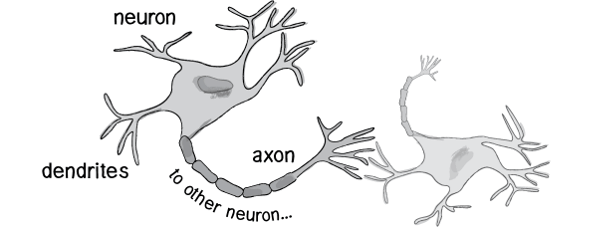
复习一下高初中的生物知识,神经元由细胞体与突起组成,而突起分为树突与轴突,树突就是上图中左侧的像网络一样的突起,它是一个接收器,与其他神经元细胞的轴突相连接,接受其他神经元细胞发出的信号;轴突就是上图中右侧的长条状的突起,是一个发射器,负责将信号发送给其他的神经元细胞。
无数的神经元组成了一个庞大的神经网络,叫做神经中枢,而人能够产生各种行为,就是根据神经中枢传出的指令而做出的反应。
-
芯片中的神经元
文章中所说的并不是生物大脑中的神经元,而是科学家们通过了解生物神经元的结构之后使用计算机模拟出来的一种计算机结构。为什么科学家会模拟大脑?原因是希望能将大脑“思考”的能力赋予给机器。最简单的神经元模型叫做“感知器”,长下面这个样子:
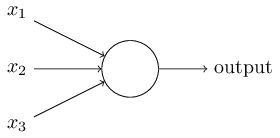
前面\(x_{1}\)、\(x_{2}\)、\(x_{3}\)模拟的就是生物神经元的树突,而\(output\)表示的就是神经元的轴突。无数个这样的神经元前后连接,就形成了芯片中的“大脑”。
但是常用的神经元模型的树突上还会加上“权重”,输入与权重相乘后相加,如果最后的值大于神经元的阈值,神经元就会产生一个\(output\)信号,这就是模拟了生物大脑中只有当一个神经元受到足够大的刺激才能产生电信号的过程。
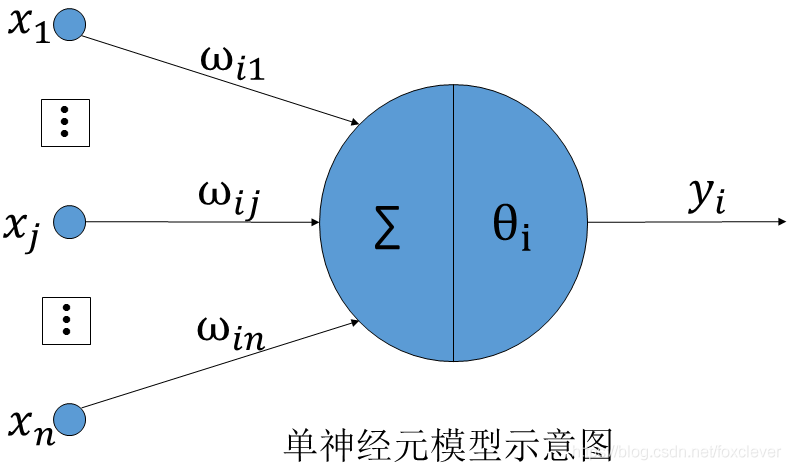
有:
其中神经元的阈值项\(\theta_{i}\)表示,只有输入的值的线性和大于这个值,神经元才会有输出。
-
学习规则
学习规则可以使得模拟出来的神经元通过某种方式得到“学习”的能力。它主要的功能是实现对神经元之间的连接强度的修正,即修改“权重”。不同的学习规则可以形成不同的神经网络,这些神经网路的具体性质也有不同。较为常用的学习规则有Hebb、Perceptron、Delta、BP等。学习分为无监督学习和监督学习,简单区分就是是否引入了期望值。通用的学习规则如下:
表达式表示的意思是权重在t时刻的差值\(\Delta W_{j(t)}\)与t时刻的输入\(x(t)\)和学习信号\(r\)的乘积成正比,这里的比例系数是\(\eta\),也称为学习常数,决定了学习的速率。
所以可以得到下一时刻的加权:
5.3.1 单神经元采用的学习规则
这里采用的神经元学习规则为有监督Hebb学习规则,可选用的规则并不局限于此。有监督的Hebb学习规则是Hebb学习规则与\(\Delta\)学习规则的结合,所以下面介绍一下学习规则的相关信息。
5.3.1.1 无监督的Hebb学习规则
Hebb学习规则默认所说的就是无监督的Hebb规则,后面人们提出了有监督的Hebb规则以适应不同模型的需要。Hebb学习规则其实与“条件反射”的机理一致。
相信大家都还记得生物书上巴普洛夫做过一个著名的实验以研究条件反射:
- 给狗听铃声,狗没有分泌唾液;
- 给狗食物,狗分泌唾液;
- 让铃声先于食物数秒后出现,狗分泌唾液,重复多次;
- 给狗听铃声,狗分泌唾液。
Hebb理论认为同一时间被激活的两个神经元(网络)之间的联系会被强化,从而让细胞记忆这两个事物之间存在着联系。相反如果这两个事物的联系越来越弱,那么这两个神经元(网络)之间的联系也就越来越被弱化。
Hebb学习规则就是通过调整神经元联结的权重来起到了“学习”的作用,也就是:权值的差值与输入输出的乘积呈正比例关系。
运用上边的公式\((2)\),可以看出如果一个树突结构(一个输入)经常有输入产生,那么在这条路线上的权值就会随着时间不断地累积,正好对应了上面所说的“同一时间被激活的两个神经元(网络)之间的联系会被强化”。但是最开始的Hebb学习并没有“弱化”的过程。
无监督的Hebb学习规则的学习表达式如下:
其中\(\Delta w_{j}(t)\)、\(\eta\)、\(X_{i}(t)\)、\(Y_{j}(t)\)分别表示权值的差值、学习速率、上一个神经元对此神经元的输入(即理解为当前神经元的输入)、当前神经元对下一个神经元的输入(即理解为当前神经元的输出)。
5.3.1.2 有监督的\(\Delta\)学习规则
首先作为一个有监督的学习规则,所以学习的过程中就必须引入期望值了。这里设期望值为\(y\),而当前神经元输出的值为\(\hat{y}\)。现在我们就能得到二者的差值了,不过在这里一般使用类似方差的方式来描述:
其中\(E\)就是所求的误差(是不是感觉跟前面PID控制器中的差值都是类似的东西?)
不管差值的形式如何,为了让学习的效果最大化,肯定是要让这个差值越小越好。它是一个\(y\)关于\(E\)的二次函数,但是我们需要讨论的是误差值\(E\)与权值的差值\(\Delta w_{ij}\)的关系。它们之间肯定也是呈一个凹函数的关系,那么我们只要找到它的最低点就好了,不是吗?
但是事情没有这么简单。神经元的学习差值函数并不是一个值都是已知的函数,我们只知道过去的以及当前的\(E\),对还未通过神经元的输入无法知道其输出值,这就无法直接计算了。所以我们采用的是梯度下降法:神经元通过一次次的迭代,每一次都根据当前输出的值做一次修正,直到找到目标误差函数的最小值。这就类似于我们如果想要找到一个山谷的最低处,我们只要一直往比当前低的地方走,直到没有更低的地方就好了。当然这其中可能会有比当前最低处更低的地方没有被发现,误以为当前的深度就是最低点的情况。只是对于本文讨论的单个神经元模型来说,并没有这种复杂的情况。
为了求得\(E\)上的最低点,我们对\((4)\)求\(E\)关于权值的偏导,有:
其中\(g\)表示的是激活函数,这个函数模拟的就是神经元的输出值,恒为正数。但简单来看,也可把中间这一步骤略去,因为非负值对权值的修正方向没有影响。所以\((5)\)式化简得到:
现在我们就得到了修正的规则,\(\Delta\)规则:权值的差值与当前输出值与期望之差和输入的乘积呈正比关系。
其学习规则的表达式为:
随着\(\Delta\)学习规则的不断调用,神经元会不断修正自己每一个树突上的权值,从而使得输出值向给出的期望值靠近。(听上去是不是有PID那味儿了?还没完呢!)这个修正的过程对于单神经元来说,权值的差值是一个负值。
等等,负值!前面的Hebb学习规则不就是没有“弱化”的过程吗?
5.3.1.3 有监督的Hebb学习规则
为了解决hebb学习规则没有“弱化”连接神经元的过程,所以我们用有监督的\(\Delta\)学习规则与其相乘,便得到了有监督的Hebb学习规则,这个学习规则可以在给定期望值的情况下将同一时间被激活的两个神经元(网络)之间的联系强化,从而让神经元记忆这两个事物之间存在着联系;相反如果这两个事物的联系越来越弱,那么这两个神经元之间的联系也就越来越被弱化。
其学习规则的表达式为:
5.4 PID的归来
学了那么久的计算机科学,你是否又开始想念我们的控制理论了呢?下面我们就将先前的PID控制论移植到神经元中去。
在这里我们还是选择将算法移植到增量式的PID算法中。(位置式PID:呜呜呜)
还是将增量式的PID表达式搬出来:
在这里可以将PID本身看作一个单神经元:三个树突分别是以上式子中的三项差值,输出就是轴突,其中三个PID参数就是三个树突的权值。为了对应单神经元的学习速率,我们再引入一个比例系数\(K\)好了。
所以上面这个增量式的PID表达式就被我们改写成了下面这个样子:
其中\({W}'\)PID的参数,也就是神经元树突的权值,计算的方式为:
我们将PID的输出直接写出来,并将PID参数的调整用前面的学习规则来书写,有:
式中:
可以看到在计算PID的三个参数的时候,其参数的权值增量使用了前面推导出来的有监督的Hebb学习规则来调整:学习速率直接照搬,误差值也就是PID中的误差值\(err(t)\);系统的输入便是上面的三个式子;系统的输出便是\(u(t)=u(t-1)+\Delta u(t)\).
其中(t-1)代表的就是上一时刻的量;我们在PID中需要的三个PID参数\(K_{p}\)、\(K_{I}\)、\(K_{D}\)分别对应着上面的\(w_{1}(t)\)、\(w_{2}(t)\)、\(w_{3}(t)\);\(\eta _{p}\)、\(\eta _{I}\)、\(\eta _{D}\)分别是比例、积分、微分项的学习速率,采用不同的学习速率的原因是以便对不同的权重进行分别调整。
这里还有最后一个参数的值需要确定:那就是我们引入的\(K\).K值的选择十分重要,可以看到K值越大则PID调整的也就越快速,但是如果过快的话会使得系统运行不稳定(类似单P控制)。所以一般来说当被控制的对象时延增大的时候K值必须减小以保证系统的稳定,但是K值如果设置得过小,又会使得系统得快速稳定性变差。
至此单神经元自适应PID控制器就已经被完全推导出来了。
5.5 改进的单神经元自适应PID控制
在大量的实际运用中,人们发现PID的在线学习修正主要与\(e(t)\)与\(\Delta e(t)\)有关,所以人们索性将PID三个参数的学习公式都改成了下面的形式:
其中\(\Delta e(t)=e(t)-e(t-1)\)。改进之后权重的在线修正就不再完全是根据神经网络的学习原理而是参杂了实际经验的考虑了。
5.6 单神经元自适应PID控制器的代码实现
有了前面的算法基础,我们就可以开始将他们转换成代码实现了。这里没有使用改进的算法,而还是使用原本的纯神经元自适应PID算法。
首先还是定义一个结构体,在其中准备算法所需要的变量:
/*定义结构体和公用体*/
typedef struct
{
float setpoint; /*设定值*/
float kcoef; /*神经元输出比例*/
float kp; /*比例学习速度*/
float ki; /*积分学习速度*/
float kd; /*微分学习速度*/
float lasterror; /*前一拍偏差*/
float preerror; /*前两拍偏差*/
float deadband; /*死区*/
float result; /*输出值*/
float output; /*百分比输出值*/
float maximum; /*输出值的上限*/
float minimum; /*输出值的下限*/
float wp; /*比例加权系数*/
float wi; /*积分加权系数*/
float wd; /*微分加权系数*/
}NEURALPID;
这一步是先先给PID参数赋一个基础值,目的是让PID的自适应功能先运转起来,后面这些值都会改变的。
/* 单神经元PID初始化操作,需在对vPID对象的值进行修改前完成 */
/* NEURALPID vPID,单神经元PID对象变量,实现数据交换与保存 */
/* float vMax,float vMin,过程变量的最大最小值(量程范围) */
void NeuralPIDInitialization(NEURALPID *vPID,float vMax,float vMin)
{
vPID->setpoint=vMin; /*设定值*/
vPID->kcoef=0.12; /*神经元输出比例*/
vPID->kp=0.4; /*比例学习速度*/
vPID->ki=0.35; /*积分学习速度*/
vPID->kd=0.4; /*微分学习速度*/
vPID->lasterror=0.0; /*前一拍偏差*/
vPID->preerror=0.0; /*前两拍偏差*/
vPID->result=vMin; /*PID控制器结果*/
vPID->output=0.0; /*输出值,百分比*/
vPID->maximum=vMax; /*输出值上限*/
vPID->minimum=vMin; /*输出值下限*/
vPID->deadband=(vMax-vMin)*0.0005; /*死区*/
vPID->wp=0.10; /*比例加权系数*/
vPID->wi=0.10; /*积分加权系数*/
vPID->wd=0.10; /*微分加权系数*/
}
下面是增量式单神经元自适应PID控制器的算法部分:
/* 神经网络参数自整定PID控制器,以增量型方式实现 */
/* NEURALPID vPID,神经网络PID对象变量,实现数据交换与保存 */
/* float pv,过程测量值,对象响应的测量数据,用于控制反馈 */
void NeuralPID(NEURALPID *vPID,float pv)
{
float x[3];
float w[3];
float sabs
float error;
float result;
float deltaResult;
error=vPID->setpoint-pv;
result=vPID->result;
if(fabs(error)>vPID->deadband)
{
x[0]=error;
x[1]=error-vPID->lasterror;
x[2]=error-vPID->lasterror*2+vPID->preerror;
sabs=fabs(vPID->wi)+fabs(vPID->wp)+fabs(vPID->wd);
w[0]=vPID->wi/sabs;
w[1]=vPID->wp/sabs;
w[2]=vPID->wd/sabs;
deltaResult=(w[0]*x[0]+w[1]*x[1]+w[2]*x[2])*vPID->kcoef;
}
else
{
deltaResult=0;
}
result=result+deltaResult;
if(result>vPID->maximum)
{
result=vPID->maximum;
}
if(result<vPID->minimum)
{
result=vPID->minimum;
}
vPID->result=result;
vPID->output=(vPID->result-vPID->minimum)*100/(vPID->maximum-vPID->minimum);
//单神经元学习
NeureLearningRules(vPID,error,result,x);
vPID->preerror=vPID->lasterror;
vPID->lasterror=error;
}
这里是有监督的Hebb学习规则的算法部分:
/*单神经元学习规则函数*/
static void NeureLearningRules(NEURALPID *vPID,float zk,float uk,float *xi)
{
vPID->wi=vPID->wi+vPID->ki*zk*uk*xi[0];
vPID->wp=vPID->wp+vPID->kp*zk*uk*xi[1];
vPID->wd=vPID->wd+vPID->kd*zk*uk*xi[2];
}
6.0 后记
在推导公式之前我曾经试过硬啃代码,结果发现啃了个寂寞……但是在一顿推导猛如虎之后,发现代码实现其实是一件很简单的事情。(我记得这事好像教我数据结构的老师说过……老师我学废了)
在这一段时间的PID算法学习过程中,逐渐发现了算法以及仿真验证的重要性。自己先前主力学习的是硬件设计等,以为会设计几块电路,能驱动单片机就学到头了,结果发现外面的世界是多么地广大。
最后的神经元代码是一位老哥在对照着Matlab的仿真代码移植到C中的。谈到MatLab,我也不禁感叹这个巨无霸工业软件能力的恐怖如斯。美帝对华部分的封锁中也包含着对matlab的禁用,这对许多科学研究来说都是一场不小的灾难。希望我们能够卧薪尝胆,早日摆脱帝国主义的技术封锁,实现中华的技术无限突破。
参考文献
[1]佚名. 单神经元自适应PID控制器设计. 辽宁科技大学本科生毕业设计论文
[2]郝志红. 单神经元自适应PID控制算法. 《冶金自动化》2012S1
[3]单神经元PID控制器的实现:https://blog.csdn.net/foxclever/article/details/84678393
[4]人工神经元和Delta规则:https://zhuanlan.zhihu.com/p/23478187
[5]深度学习 --- 神经网络的学习原理(学习规则):https://blog.csdn.net/weixin_42398658/article/details/83816633
[6]《先进PID控制MATLAB仿真》第四版 刘金琨编著
[7]理解PID的原理以及控制效果:https://www.bilibili.com/video/BV1xQ4y1T7yv
[8]理解PID的代码实现:https://www.bilibili.com/video/BV1Af4y1L7Lz
[9]理解串级PID的原理:https://zhuanlan.zhihu.com/p/135396298
[10]brettbeauregard的博客:http://brettbeauregard.com/blog/

