MySQL数据库基本操作【3】
1.事务
事务:是一个操作序列,这些操作只能都做,或者都不做,是一个不可分割的工作单位.
事务主要用于处理操作量大,复杂度高的数据
MySQL中,事务由单独单元中的一个或多个SQL语句组成。在这个单元中,每个MySQL 语句是相互依赖的。而整个单独单元作为一个不可分割的整体,要么都做,或者都不做
如果单元中某条SQL语句一旦执行失败或产生错误,可以让整个单元回滚。所有受到影响 的数据将返回到事务开始以前的状态(保证了数据的完整性)
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务
事物语句:
开启:begin 开启一个事物
提交:commit 将事务中的SQL语句提交给数据库
回滚:rollback 取消掉之前的所有操作(撤销事务)
举例:
CREATE TABLE t_person(id INT PRIMARY KEY AUTO_INCREMENT,sname VARCHAR(10),money INT) character set utf8 engine=INNODB;
创建一个InnoDB类型的数据表,或者在创建表之后改变:ALTER TABLE t_person engine=INNODB;
INSERT INTO t_person VALUES(1,'小明',1000);
INSERT INTO t_person VALUES(2,'丽丽',2000);
上面的代码中小明有1000块钱,丽丽有2000块钱
接下来要实现小明给丽丽转账500元
小明给丽丽转账500元
BEGIN; -- 开始事物
UPDATE t_person SET money=money-500 WHERE id=1;
UPDATE t_person SET money=money+500 WHERE id=2;
SELECT * FROM t_person; -- 查询结果是否有误
COMMIT; -- 发现结果无误,提交事物,提交后数据库中数据会修改
创建事务的一般过程是:开始事务、创建事务、应用SELECT语句查询数据、提交事务
BEGIN; -- 开始事物
UPDATE t_person SET money=money-500 WHERE id=1;
UPDATE t_person SET money=money+600 WHERE id=2;
SELECT * FROM t_person; -- 查询结有误果是否
ROLLBACK; -- 结果有误,回滚事物,取消所有操作
总结:
我们可以声明一个事务的开始,在确认提交或者指明放弃前的所有操作,都先在一个叫做事务日志的临时环境中进行操作。待操作完成,确保了数据一致性之后,那么我们可以手动确认提交,也可以选择放弃以上操作。
注意: 一旦选择了提交,就不能再利用回滚来撤销更改了
2.关联关系的使用
表的关系:mysql相互关联的表之间存在一对一,一对多(多对一),多对多的关系:
1,一对一的关系:表1中的一条数据,对应表2中的一条数据
- 这种关系即多个表具有相同的主键,A表中的一条数据对应B表中的一条数据。实际中用的并不多,因为完全可以将这种关系的合并为一张表(一夫一妻)
2,一对多(多对一)的关系:表1中的一条数据对应表2中的多条数据
- 其中表1的主键是表2的外键,(即表1的某字段作为主键,表2的相同字段绑定到表1的主键字段上)
CREATE TABLE stu( -- 学生表
stuId INT,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(stuId)
);
CREATE TABLE score_1( -- 成绩表
stuId INT,
score VARCHAR(32), #一个学生有多门成绩
FOREIGN KEY (stuId) REFERENCES stu(stuId)
);
多对多的关系:
比如:一个老师教很多学生的课,一个学生选了很多老师的课。那么,老师和学生之间就是多对多的关系
多对多的关系要借助于第3张表
1,首先创建老师表,设置id为主键
CREATE TABLE teacher(
teacherId INT,
NAME VARCHAR(10) NOT NULL,
PRIMARY KEY(teacherId)
);
2,然后创建学生表,同样设置id为主键
CREATE TABLE stu(
stuId INT,
NAME VARCHAR(10) NOT NULL,
PRIMARY KEY(stuId)
);
3,最后创建一个课程表,将前两张表关系起来
CREATE TABLE score(
scoresname VARCHAR(32)
stuId INT,
teacherId INT,
FOREIGN KEY (stuId) REFERENCES stu(stuId),
FOREIGN KEY (teacherId) REFERENCES teacher(teacherId)
);
关联查询
CREATE TABLE stu( -- 学生表
stuId INT,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(stuId)
);
INSERT INTO stu VALUES (1,'xiaoming');
CREATE TABLE score( -- 成绩表
stuId INT,
score INT,
FOREIGN KEY (stuId) REFERENCES stu(stuId)
);
INSERT INTO score VALUES(1,100);
现在要查询所有学生姓名和对应的成绩:后面的限定条件表示有对应关系才做查询
SELECT stu.name,score.score FROM stu,score WHERE stu.stuID=score.stuID;
子查询
子查询:子查询在主查询前执行一次,主查询使用子查询的结果
CREATE TABLE stu(
stuID INT,
sname VARCHAR(32),
score INT,
PRIMARY KEY(stuID)
);
INSERT INTO stu VALUES (1,‘xiaoming’,60), (2,‘xiaoli’,70)...;
1,如何查询所有比小明成绩高的学生名字
SELECT sname FROM stu WHERE score > (SELECT score FROM stu WHERE sname = 'xiaoming');#会先执行括号当中的查询语句(子查询)
2,查询成绩高于平均成绩的学生姓名和成绩
SELECT sname,score FROM stu WHERE score > (SELECT AVG(score) FROM stu);
子查询(嵌套查询): 查多次, 多个select
-
作为表名使用
- select * from (select * from person) as 表名;
-
ps:大家需要注意的是: 一条语句中可以有多个这样的子查询,在执行时,最里层括号具有优先执行权
注意: as 后面的表名称不能加引号('')
3.Python连接数据库
pip3 install pymysql
python连接数据库的过程
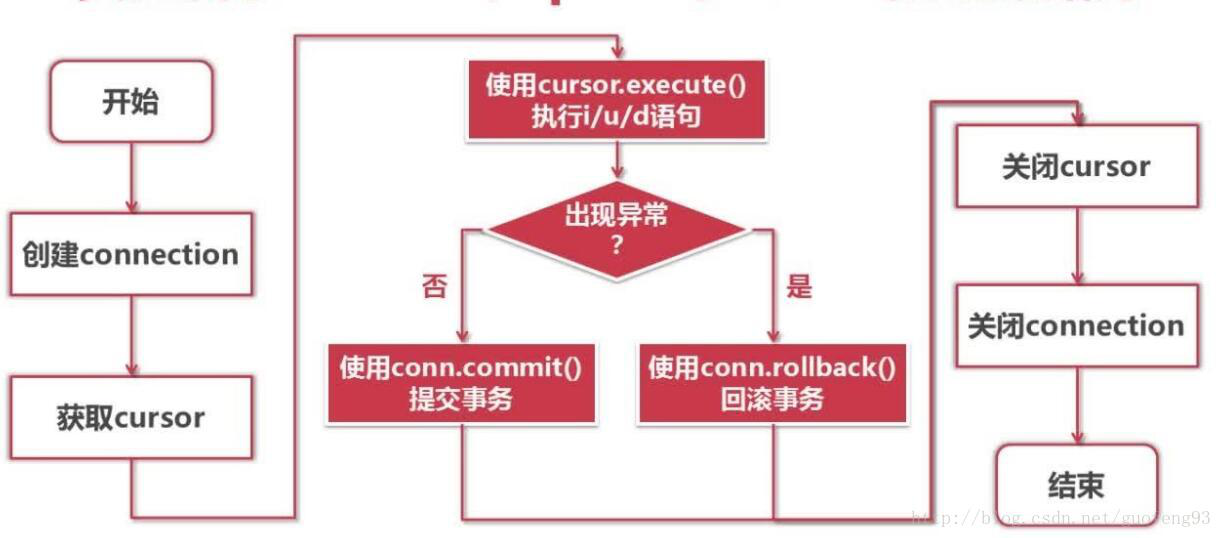
connection对象:用来跟数据库进行连接(建立通路)
创建connection对象:conn = connect(参数列表)
conn = pymysql.connect(host='localhost',user='root',password='123123',db='test1',charset='utf8')
参数列表:
- host:MySQL服务器地址,用来连接MySQL主机,本机是‘localhost’
- port:MySQL服务器的端口号,默认3306
- user:连接的用户名
- passwd:连接密码
- db:数据库名称(用来选择要连接哪个数据库)
- charset:通信采用的编码方式,默认是‘gb2312’,要求与数据库创建时指定的编码格式一致
cursor数据库交互对象:用来执行SQL语句并获得结果(从数据库取得数据)
对数据库进行查询操作:
import pymysql
#连接数据库
conn = pymysql.connect(host='localhost',user='root',password='123123',db='test1',charset='utf8')
#获取cursor对象
cur = conn.cursor()
#编写SQL语句
sql = 'select * from t_user '
#通过cursor的对象去执行SQL语句
cur.execute(sql)
#查看结果
emps = cur.fetchall()
print(emps)
在表中插入数据:
import pymysql
#连接数据库
conn = pymysql.connect(host='localhost',user='root',password='123123',db='test1',charset='utf8')
#获取cursor对象
cur = conn.cursor()
name = input("请输入名字:")
id = input("请输入ID:")
sql = 'insert into t_user values (%d,"%s")'%(int(id),name) #编写SQL语句
#通过cursor的对象去执行SQL语句
cur.execute(sql)
#提交事物
conn.commit()
关闭连接:在使用完时候要关闭连接 使用close()
- 先关闭cursor: cur.close()
- 再关闭connection:conn.close()
3.1封装工具模块:
- 每次使用Python连接数据库时,不需要都写一遍前面的代码
- 在包中新建Python文件,起名叫mysqlhelper
import pymysql
cur = None
conn = None
#用来执行查询
def getall(sql):
# 连接数据库
conn = pymysql.connect(host='localhost', user='root', password='123123', db='test1', charset='utf8')
cur = conn.cursor() #获取cursor对象
# 通过cursor的对象去执行SQL语句
cur.execute(sql)
return cur.fetchall()
#用来执行插入
def exceDML(sql):
conn = pymysql.connect(host='localhost', user='root', password='123123', db='test1', charset='utf8')
cur = conn.cursor()
# 通过cursor的对象去执行SQL语句
cur.execute(sql)
# 提交事物
conn.commit()
def close(): #用来关闭连接
if cur:
cur.close()
if conn:
conn.close()
使用工具模块:
from day3 import mysqlHelper
name = input("请输入名字:")
id = input("请输入ID:")
sql1 = 'insert into t_user values(%d,"%s")'%(int(id),name)
sql2 = 'select * from t_user'
mysqlHelper.exceDML(sql1)
print(mysqlHelper.getall(sql2))
mysqlHelper.close()
3.2模拟音乐播放器
CREATE DATABASE music;
CREATE TABLE t_music(
id INT PRIMARY KEY AUTO_INCREMENT, -- 标识
mname VARCHAR(32), -- 歌名
path VARCHAR(32) -- 音乐所在位置
);
# 音乐播放的路径和歌曲名应该添加到数据库中:
import pymysql
conn = pymysql.connect(host='localhost', user='root', password='123123', db='music', charset='utf8')
cur = conn.cursor() # 获取cursor对象
mpath = input("输入音乐下载路径:")
name = input("歌曲名:")
sql = "'insert into music(mname,path) values("%s","%s")'%(name,mpath)"
# 通过cursor的对象去执行SQL语句
cur.execute(sql)
# 最后一定要提交事物
conn.commit()
4.多表查询
建立一张员工表,包含编号/姓名/性别/年龄/部门/工资编号等信息
再建一张部门表,包含部门编号和部门名称(不需要关联关系)
插入数据时员工表放入一些属于不存在部门的人,部门表放一些没人的部门
在实际应用中,要查的数据很可能不在同一个表中,而是来自于不同的表
多表查询语法
select 字段1,字段2... from 表1,表2... [where 条件]
如果不加条件直接进行查询 select * from person,dept
这种结果我们称之为 笛卡尔乘积
笛卡尔乘积公式 : A表中数据条数 * B表中数据条数 = 笛卡尔乘积
所以: 多表查询时,一定要找到两个表中相互关联的字段,并且作为条件使用
笛卡尔乘积:从第一个表中选出第一条记录,和第二个表中的所有所有记录进行组合,然后再从第一个表中取出第二条记录,和第二张表的所有记录进行组合,这样的结果是没有实际意义的。我们需要的是相匹配的记录
所以: 多表查询时,一定要找到两个表中相互关联的字段,并且作为条件使用
查询人员和部门所有信息
select * from person,dept where person.did = dept.did;
不符合条件的数据都会被丢弃
4.1内连接
语法:
SELECT 字段列表 FROM 表1 INNER|LEFT|RIGHT JOIN 表2 ON 表1.字段 = 表2.字段;
内连接查询 (只显示符合条件的数据)
查询人员和部门所有信息
格式:select a.,b. from a [inner] join b on ab表的连接条件;
- select * from person inner join dept on person.did=dept.did;
- 内连接查询与多表联合查询的效果是一样的,表一表二中不符合条件的数据都会被丢弃
- 这种场景下得到的是满足某一条件的A,B内部的数据;正因为得到的是内部共有数据,所以连接方式称为内连接
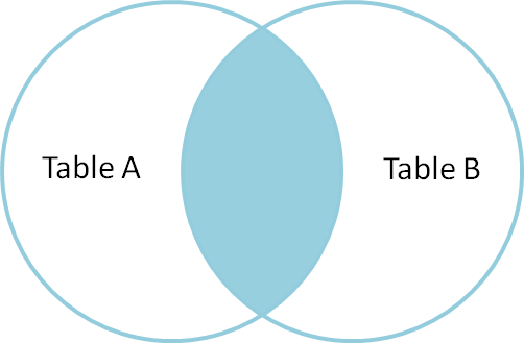
内连接格式2:
隐式的内连接
select a.,b. from a,b where ab表的连接条件
4.2外连接
外连接:左外连接,右外连接(全外链接MySQL不支持)
左外连接:select * from person left join dept on person.did =dept.did;
左边表中的数据优先全部显示
效果:人员表中的数据全部都显示,而 部门表中的数据符合条件的才会显示,不符合条件的会以 null 进行填充
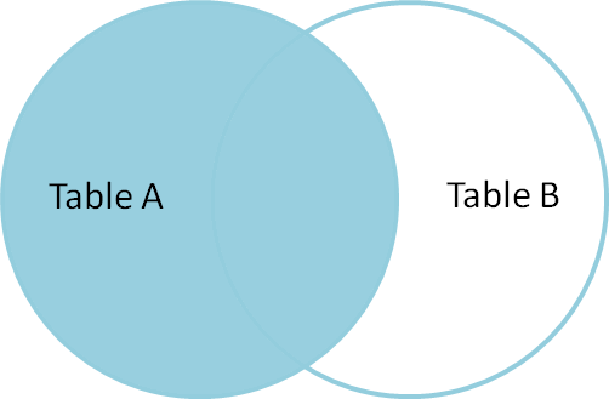
右外连接查询 (右边表中的数据优先全部显示)
select * from person right join dept on person.did =dept.did;
效果正好与左外连接相反
4.3全连接
全连接查询(显示左右表中全部数据)
全连接查询:是在内连接的基础上增加 左右两边没有显示的数据
注意: mysql并不支持全连接 full JOIN 关键字
但是mysql 提供了 UNION 关键字.使用 UNION 可以间接实现 full JOIN 功能
查询人员和部门的所有数据
SELECT * FROM person LEFT JOIN dept ON person.did = dept.did
UNION
SELECT * FROM person RIGHT JOIN dept ON person.did = dept.did;
注意: UNION 和 UNION ALL 的区别:
UNION 会去掉重复的数据,
UNION ALL 则直接显示结果
1,以内连接的方式查询部门表和员工表,找出年龄大于25的员工信息
select * from person inner join dept on person.did =dept.did where age>25
#单表查询时select * from 表名,现在是把表名的位置换成了一张连接后的新表
2,以内连接的方式查询部门表和员工表,以年龄字段升序的方式显示
select * from person inner join dept on person.did =dept.did order by age
3, 查询出 教学部 年龄大于20岁,并且工资小于40000的员工,按工资倒序排列.(要求:分别使用多表联合查询和内连接查询)
#1.多表联合查询方式:
select * from person p1,dept d2 where p1.did = d2.did
and d2.dname='python'
and age>20
and salary <40000
ORDER BY salary DESC;
#2.内连接查询方式:
SELECT * FROM person p1 INNER JOIN dept d2 ON p1.did= d2.did
and d2.dname='python'
and age>20
and salary <40000
ORDER BY salary DESC;
4, 查询每个部门中最高工资和最低工资是多少,显示部门名称
select MAX(salary),MIN(salary),dept.dname from
person LEFT JOIN dept
ON person.did = dept.did
GROUP BY person.did;

