5、Python 数据分析-Pandas数据清洗【2】
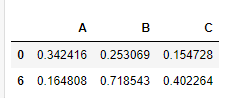
1、 处理重复数据drop_duplicates函数
#设定一些重复行数据
df.iloc[1] = [0,0,0,0,0,0,0,0]
df.iloc[3] = [0,0,0,0,0,0,0,0]
df.iloc[5] = [0,0,0,0,0,0,0,0]
df.iloc[7] = [0,0,0,0,0,0,0,0]
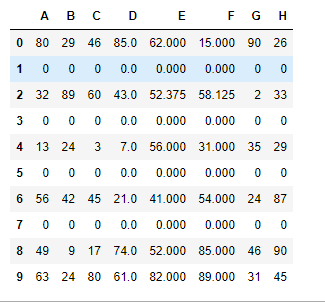
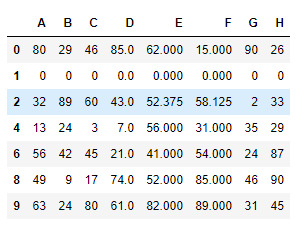
df.drop_duplicates(keep='first')#keep='first'只保留第一次出现的重复数据,last相反,只保留最后一次出现的重复数据,其他重复数据不保留
2、处理异常数据
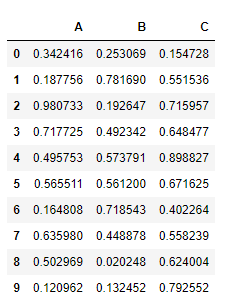
自定义一个10行3列(A,B,C)取值范围为0-1的数据源,然后将C列中的值大于其两倍标准差的异常值进行清洗
from pandas import DataFrame
import numpy as np
df = DataFrame(data=np.random.random(size=(10,3)),columns=['A','B','C'])
df.head(10)
#判定异常值的条件
std_twice = df['C'].std()*2
>>>
0.41596053666447336
# 将存有异常值的行进行删除
df['C'] > std_twice
# 将存有异常值的行数据取出
df.loc[df['C'] > std_twice]
# 获取异常值对应的行索引
indexs = df.loc[df['C'] > std_twice].index
df.drop(labels=indexs,axis=0)