2、Python 数据分析-Pandas基础操作
2、Python 数据分析-Pandas
1、简介
Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
pandas的目的是什么?
- numpy能够帮助我们处理的是数值型的数据,在数据分析中除了数值型的数据还有好多其他类型的数据(字符串,时间序列),那么pandas就可以帮我们很好的处理除了数值型的其他数据!
2、什么是pandas?
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
数据类型概览
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近。Series如今能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
Time- Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。
Panel :三维的数组,可以理解为DataFrame的容器。
Panel4D:是像Panel一样的4维数据容器。
PanelND:拥有factory集合,可以创建像Panel4D一样N维命名容器的模块。
最常用的数据类型是一维Series和二维DataFrame
3、一维【Series】
3.1、Series组成
- values:一组数据(ndarray类型)
- index:相关的数据索引标签
#隐式索引:默认索引,行号默认从0开始。0,1,2,3,4
a = Series(data=[1,2,3])
>>>
0 1
1 2
2 3
dtype: int64
#显式索引:自定义的索引
b = Series(data=[1,2,3],index=['A','B','C'])
>>>
A 1
B 2
C 3
dtype: int64
3.2、Series的创建
-
由列表或numpy数组创建
a = Series(data=np.random.randint(0,10,size=(3))) >>> 0 3 1 0 2 7 dtype: int32 -
由字典创建
dic = { '语文':100, '数学':110, '外语':120, } b = Series(data=dic) >>> 语文 100 数学 110 外语 120 dtype: int64
3.3、Series的索引和切片
b = Series(data=[1,2,3],index=['A','B','C'])
b[1]
>>>
2
b["A"]
>>>
1
b.C
>>>
3
b[0:2] #或b['A':'B']
>>>
A 1
B 2
dtype: int64
b[0:3:2] #或b['A':'B':2]
>>>
A 1
C 3
dtype: int64
3.4、Series的常用属性
- shape#返回数组的形状
- size#返回数组的个数
- index#返回数组索引
- values#返回数组值
b = Series(data=[1,2,3],index=['A','B','C'])
b.shape
>>>
(3,)
b.size
>>>
3
b.index
>>>
Index(['A', 'B', 'C'], dtype='object')
b.values
>>>
array([1, 2, 3], dtype=int64)
3.5、Series的常用方法
- head(),tail()
b = Series(data=[1,2,3],index=['A','B','C'])
b.head(2) #显示前两个元素
>>>
A 1
B 2
dtype: int64
b.tail(2) #显示后两个元素
>>>
B 2
C 3
dtype: int64
- unique()
s = Series(data=[1,1,2,2,3,3,4,4,5,6,7,8,9])
s.unique() #去重
>>>
array([1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=int64)
- add() sub() mul() div()
3.6、Series的算术运算
- 法则:索引一致的元素进行算数运算否则补空
isnull(),notnull()
s1 = Series(data=[1,2,3,4,5])
s2 = Series(data=[1,2,3])
s = s1+s2
>>>
0 2.0
1 4.0
2 6.0
3 NaN
4 NaN
dtype: float64
s.isnull() #isnull检测哪些元素为空值,显示True,反之False
>>>
0 False
1 False
2 False
3 True
4 True
dtype: bool
s.notnull() #notnull检测哪些元素为空值,显示False,反之True
>>>
0 True
1 True
2 True
3 False
4 False
dtype: bool
#想要去除Seriese中的空值
s[[True,True,True,False,False]] #或s[s.notnull()]
>>>
0 2.0
1 4.0
2 6.0
dtype: float64
4、二维DataFrame
4.1、DataFrame组成
- DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
DataFrame(data=np.random.randint(0,100,size=(3,4)))
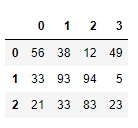
4.2、DataFrame的创建
- ndarray创建
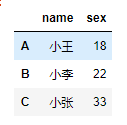
- 字典创建
dic = {
'name':['小王','小李','小张'],
'sex':[18,22,33]
}
DataFrame(data=dic,index=['A','B','C'])
4.3、DataFrame的属性
- values#返回数组值
- columns#返回数组列行索引
- index#返回数组列索引
- shape#返回数组的形状
dic = {
'name':['小王','小李','小张'],
'sex':[18,22,33]
}
df = DataFrame(data=dic,index=['A','B','C'])
df.values
>>>
array([['小王', 18],
['小李', 22],
['小张', 33]], dtype=object)
df.columns
>>>
Index(['name', 'sex'], dtype='object')
df.index
>>>
Index(['A', 'B', 'C'], dtype='object')
df.shape
>>>
(3, 2)
4.4、练习1:
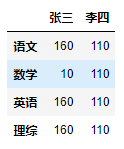
1、根据以下考试成绩表,创建一个DataFrame,命名为df:
张三 李四
语文 150 0
数学 150 0
英语 150 0
理综 300 0
dic = {
'张三':[150,150,150,150],
'李四':[0,0,0,0]
}
df = DataFrame(data=dic,index=['语文','数学','英语','理综'])
4.5、DataFrame索引操作
-
对行进行索引
dic = { '张三':[150,150,150,150], '李四':[0,0,0,0] } df = DataFrame(data=dic,index=['语文','数学','英语','理综']) iloc: - 通过隐式索引取行 #取单行 df.iloc[0] >>> 张三 150 李四 0 Name: 语文, dtype: int64 #取多行 df.iloc[[0,2]]
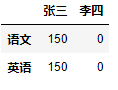
loc:
- 通过显示索引取行
df.loc['英语','张三'] #取单个值
>>>
150
df.loc[['英语','数学'],'张三'] #取多个值
>>>
英语 150
数学 150
Name: 张三, dtype: int64
-
队列进行索引
dic = { '张三':[150,150,150,150], '李四':[0,0,0,0] } df = DataFrame(data=dic,index=['语文','数学','英语','理综']) df['张三']#取一列 >>> 语文 150 数学 150 英语 150 理综 150 Name: 张三, dtype: int64 df[['李四','张三']] #取多列 # df[0] #error,如果df有显示索引,那么在索引取值的话,只能用显示索引不能用隐式索引

4.6、DataFrame切片操作
- 对行进行切片
#df[index1:index3]
df[0:2] #切行
- 对列进行切片
#df.iloc[:,col1:col3]
df.iloc[:,0:1] #切列

4.7、DataFrame的运算
- 同Series
4.8、练习2:
- 假设ddd是期中考试成绩,ddd2是期末考试成绩,请自由创建ddd2,并将其与ddd相加,求期中期末平均值。
- 假设张三期中考试数学被发现作弊,要记为0分,如何实现?
- 李四因为举报张三作弊立功,期中考试所有科目加100分,如何实现?
- 后来老师发现有一道题出错了,为了安抚学生情绪,给每位学生每个科目都加10分,如何实现?
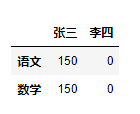
1️⃣
qimo = df
qizhong = df
(qizhong + qimo) / 2 #计算均值
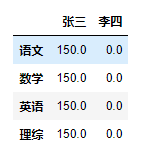
2️⃣
qizhong.iloc[1,0] = 0
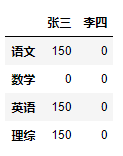
3️⃣
qizhong['李四'] += 100
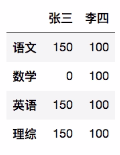
4️⃣
qizhong += 10