15、Python Scrapy Web爬虫框架【3】
1、校花网图片爬取
- 实现:
- 1.爬虫文件中将图片名称和地址获取,封装到item中,将item提交给管道
- 2.定义一个新的管道,在新的管道中进行图片的请求和持久化存储
- 需要事先配置文件中进行:IMAGES_STORE = './dirName'
创建scrapy项目
scrapy startproject imgpro
cd imgpro
scrapy genspider img www.xx.com
settings.py
IMAGES_STORE = './imgLibs'
BOT_NAME = 'imgpro'
SPIDER_MODULES = ['imgpro.spiders']
NEWSPIDER_MODULE = 'imgpro.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61'
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
ITEM_PIPELINES = {
'imgpro.pipelines.ImgproPipeline': 300,
}
items.py
import scrapy
class ImgproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img_src = scrapy.Field()
img_name = scrapy.Field()
pipelines.py
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class ImgproPipeline(ImagesPipeline):
# 可以接受爬虫文件传过来的item
# 可以对图片的地址进行请求发送
def get_media_requests(self, item, info):
print(item)
yield scrapy.Request(url=item['img_src'],meta={'item':item})
#详细制定图片存储的路径
def file_path(self, request, response=None, info=None):
item = request.meta['item']
img_name = item['img_name']
print(img_name,'下载成功!')
return img_name
def item_completed(self, results, item, info):
#可以将item传递给下一个传递给下一个即将被执行的管道类
return item
img.py
import scrapy
from imgpro.items import ImgproItem
class ImgSpider(scrapy.Spider):
name = 'img'
# allowed_domains = ['www.xx.com']
start_urls = ['http://www.521609.com/daxuemeinv/']
def parse(self, response):
li_list = response.xpath('//*[@id="content"]/div[2]/div[2]/ul/li')
for li in li_list:
img_src = 'http://www.521609.com' + li.xpath('./a[1]/img/@src').extract_first()
img_name = li.xpath('./a[1]/img/@alt').extract_first()+'.jpg'
item = ImgproItem()
item['img_src'] = img_src
item['img_name'] = img_name
yield item
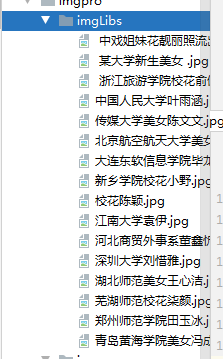
效果:
2、中间件-爬取网易新闻:
- 拦截响应,目的是为了篡改响应数据。

**分析**:
- 1.将国内,国际,航空,无人机,军事五个板块中的数据进行爬取
- 2.网易首页是没有动态加载数据
- 因此就可以直接在首页中解析出每一个板块对应的url
- 3.每一个板块对应的页面中新闻标题数据是动态加载出来。
- 问题:在当前解析环节中出现了动态加载数据。目前请求到的数据是不存在动态加载数据(不满足需求的响应数据)
- 将不满足需求的响应数据篡改成满足需求的响应数据(包含了动态加载的数据)
- 可以通过中间件拦截到不满足需求的响应对象,从而获取不满足需求的响应数据,然后对其进行篡改
- 4.通过selenium获取满足需求的响应数据
- 1.在爬虫类中实例化浏览器对象
- 2.在中间件中基于selenum发起请求获取数据
- 3.关闭浏览器:在爬虫类中重写一个closed方法,将关闭操作写入该方法中
创建scrapy项目
scrapy startproject imgpro
cd imgpro
scrapy genspider img www.xx.com
settings.py
BOT_NAME = 'wangyipro'
SPIDER_MODULES = ['wangyipro.spiders']
NEWSPIDER_MODULE = 'wangyipro.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61'
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
DOWNLOADER_MIDDLEWARES = {
'wangyipro.middlewares.WangyiproDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'wangyipro.pipelines.WangyiproPipeline': 300,
}
items.py
import scrapy
class WangyiproItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
pipelines.py
class WangyiproPipeline:
def process_item(self, item, spider):
print(item)
return item
wangyi.py
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
from wangyipro.items import WangyiproItem
class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://news.163.com/']
# 实例化浏览器对象
bro = webdriver.Chrome('E:\crawler\scrapy_07\chromedriver.exe')
five_model_urls = []
def parse(self, response):
li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
# 国内,国际,航空,无人机,军事五个板块中对用的索引位置
# 解析出5个板块对用的URL
model_index = [3,4,6,7,8]
for index in model_index:
li = li_list[index]
model_url = li.xpath('./a/@href').extract_first()
self.five_model_urls.append(model_url)
yield scrapy.Request(url=model_url,callback=self.parse_model)
# 解析板块页面中的新闻标题新闻标题的url,解析的这两个数据都是动态加载出来
def parse_model(self, response): # 用来解析每一个板块对应的页面内容
div_list = response.xpath('/html/body/div[1]/div[3]/div[4]/div[1]/div/div/ul/li/div/div')
for div in div_list:
new_title = div.xpath('./div/div[1]/h3/a/text()').extract_first()
new_detail_url = div.xpath('./div/div[1]/h3/a/@href').extract_first()
item = WangyiproItem()
item['title'] = new_title
if new_detail_url:
yield scrapy.Request(url=new_detail_url, callback=self.parse_new_detail, meta={'item': item})
def parse_new_detail(self, response):
item = response.meta['item']
content = response.xpath('//*[@id="endText"]//text()').extract()
content = ''.join(content)
content = content.strip("\t\n")
item['content'] = content
yield item
# 重写父类的一个方法
def closed(self, spider):
print('closed方法会在整个爬虫结束后调用一次')
self.bro.quit()
middlewares.py
from scrapy import signals
from time import sleep
from scrapy.http import HtmlResponse #scrapy封装好的响应对象
class WangyiproDownloaderMiddleware:
def process_request(self, request, spider):
return None
# 拦截所有的响应对象
def process_response(self, request, response, spider):
# 当前代码一共产生了6个响应对象,其中5个不满足需求的响应对象
# 通过process_response将5个不满足需求的响应对象找出
# 可以通过URL定位这5个响应对象
# 参数:spider爬虫类实例化的对象
if request.url in spider.five_model_urls:
# request.url就是每一个响应对象对应的URL
# 将响应数据篡改成满足需求的响应数据
# 什么是满足需求的响应数据:包含了动态加载的新闻数据
# 如何获取满足需求的响应数据:通过selenium
bro = spider.bro
bro.get(request.url)
sleep(2)
# execute_script让selenium让页面下滑一页数据,加载出更多的数据
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# 获取包含动态加载的页面数据,获取满足需求的响应数据
page_text = bro.page_source
# 将page_text篡改到当前的响应对象中
#实例化一个新的满足需求的响应对象进行返回
new_response = HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request)
sleep(2)
return new_response
else:
return response
def process_exception(self, request, exception, spider):
pass
效果:

3、全站数据爬取
全站数据爬取是值将一张页面中所有页码的数据进行爬取
CrawlSpider使用
-
创建一个工程
-
cd 工程
-
创建一个基于CrawlSpider的爬虫类
- scrapy genspider -t crawl sun www.xxx.com
-
CrawlSpider是Spider的一个子类
-
LinkExtractor:链接提取器
- 可以根据指定规则在页面中进行连接的提取
-
Rule:规则解析器
- 可以接受链接提取器提取到的链接,对其发起请求,然后根据指定规则进行相关的数据解析操作
爬取阳光热线问政平台问政标题数据
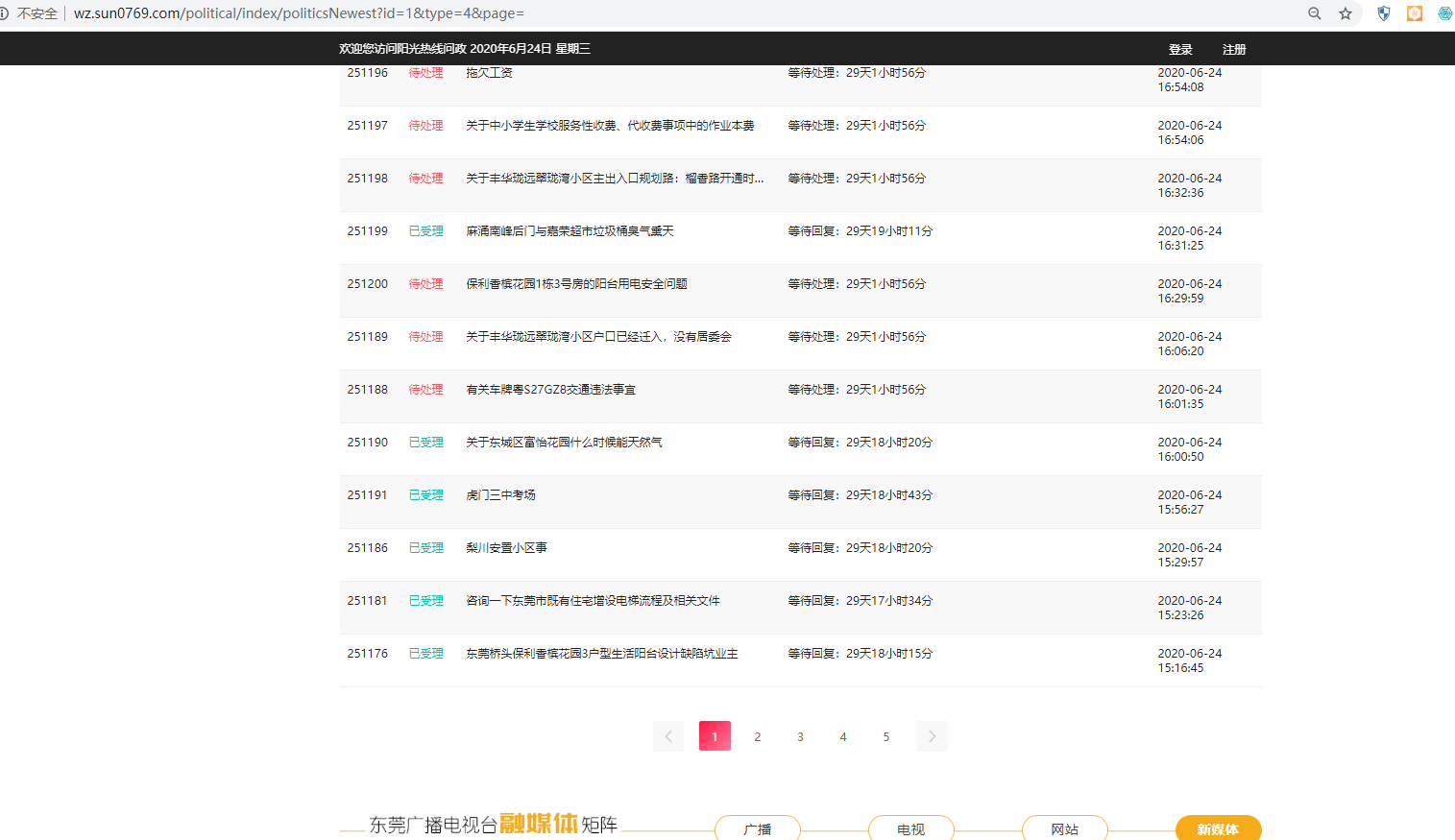
sun.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class SunSpider(CrawlSpider):
name = 'sun'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&type=4&page=']
#实例化的链接提取器的对象
#参数allow='正则':提取规则
#使用LinkExtractor提取所有的页码链接
link = LinkExtractor(allow=r'id=1&page=\d+')
# link = LinkExtractor(allow=r'') 可取取到网站中所有的链接
rules = (
Rule(link, callback='parse_item', follow=True),
)
def parse_item(self, response):
li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
for li in li_list:
title = li.xpath('./span[3]/a/text()').extract_first()
print(title)
settings.py
BOT_NAME = 'sunpro'
SPIDER_MODULES = ['sunpro.spiders']
NEWSPIDER_MODULE = 'sunpro.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
4、分布式-爬取阳光热线问政平台问政标题数据
-
什么是分布式:需要使用多台机器搭建一个分布式机群,让每一台电脑联合对一个资源进行数据爬取
-
实现分布式的方法:
-
scrapy+scrapy-redis
-
作用:Scrapy-redis可以给scrapy提供可以被分布式机群共享的管道和调度器
- scrapy-redis组件,可以帮助scrapy实现分布式
-
原生的scrapy框架是无法实现分布式
- 原因:调度器和管道无法被分布式机群共享
-
-
实现分布式的流程
- 下载scrapy-redis组件
pip instal scrapy-redis- 创建一个基于CrawlSpider的工程
- scrapy startproject fbs
- cd fbs
- scrapy genspider -t crawl fbs www.xxx.com
修改爬虫文件
-
导入scrapy-redis:from scrapy_redis.spiders import RedisCrawlSpider
-
将RedisCrawlSpider作为当前爬虫类的父类
-
将start_url修改成redis_key的属性
- redis_key属性值就表示可以被共享的调度器队列的名称
-
实现数据的爬取
-
修改工程的配置文件
settings.py
#指定管道: ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 400 } #指定调度器 #增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" #配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据 SCHEDULER_PERSIST = True #指定redis因为分布式只能将数据写入到redis数据库 REDIS_HOST = '127.0.0.1' REDIS_PORT = 6379 REDIS_PARAMS = {'password':'foobared'}fbs.py
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapy_redis.spiders import RedisCrawlSpider from fbspro.items import FbsproItem class FbsSpider(RedisCrawlSpider): name = 'fbs' # allowed_domains = ['www.xxx.com'] # start_urls = ['http://www.xxx.com/'] redis_key = 'fbsQueue' link = LinkExtractor(allow=r'id=1&page=\d+') rules = ( Rule(link, callback='parse_item', follow=True), ) def parse_item(self, response): li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li') for li in li_list: title = li.xpath('./span[3]/a/text()').extract_first() item = FbsproItem() item['title'] = title yield item-
修改redis的配置文件,然后启动redis的服务端和客户端
redis.windows.conf
56行:#bind 127.0.0.1
75行:protected-mode no -
执行工程
-
向调度器的队列中仍入一个起始的url:
-
调度器的队列是存在于redis中,需要在redis的客户端执行:
-
lpush fbsQueue 起始的url
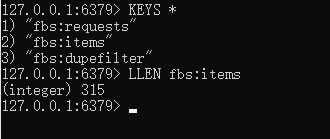
redis数据查看爬取到了315条数据
-
-
5、增量式-爬取4567电影网
- 作用:用来检测网站数据更新的情况,只把最新更新出来的数据进行爬取
- 核心:能够检测出哪些数据被爬取过。
- 记录表的机制检测数据是否被爬取过。
- 将爬取过的电影的详情页url存放到记录表中
- 下次在爬取数据前,需要在记录表中做检查,如果记录表中存在的电影我们就不爬取。
- 谁可以充当记录表?
- 记录表是需要持久化存储。选择使用redis的set充当记录表
- 核心:能够检测出哪些数据被爬取过。
zls.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from redis import Redis
from zlspro.items import ZlsproItem
class ZlsSpider(CrawlSpider):
name = 'zls'
conn = Redis(host='127.0.0.1',port=6379,password='foobared')
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.4567kan.com/index.php/vod/show/id/5/lang/%E5%9B%BD%E8%AF%AD/page/27.html']
rules = (
Rule(LinkExtractor(allow=r'page/\d+\.html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
title = li.xpath('./div/a/@title').extract_first()
item=ZlsproItem()
item['title'] = title
detail_url = 'https://www.4567kan.com'+li.xpath('./div/a/@href').extract_first()
ex = self.conn.sadd('movie_url',detail_url)
if ex == 1:#插入的电影的URL在movie_url这个Redis的集合中不存在
print(title,'爬取成功!!')
yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta={"item":item})
else:
print('无最新数据更新')
def parse_detail(self,response):
item = response.meta['item']
desc =response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
item['desc'] = desc
yield item
items.py
import scrapy
class ZlsproItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
desc = scrapy.Field()
pipelines.py
class ZlsproPipeline:
def process_item(self, item, spider):
conn = spider.conn
conn.lpush('movie_Deta',item)
return item
结果:
Redis中查询URL对应电影名称都是211条数据

再次爬取数据库中存在显示无数据更新


