4、Python 数据解析【2】
1、xpath解析
1.1、环境的安装:
pip install lxml
1.2、实现流程:
- 1.实例化一个etree类型的对象,且把即将被解析的页面源码内容加载到该对象中
- 2.调用etree对象中的xpath方法结合着不同形式的xpath表达式进行标签定位和数据提取
1.3、etree对象的实例化
- etree.parse(fileName):将本地存储的html文档进行数据解析
- etree.HTML(page_text):将请求到的页面源码数据进行解析
1.4、xpath表达式
-
最左侧的/:xpath表达式需要从html树状结构的最外层的标签逐步的进行其他标签的定位
-
非最最侧的/:表示一个层级的意思
-
最左侧的//:可以从任意位置定位标签(推荐)
-
非最左侧的//:表示多个层级
-
标签定位
- 属性定位://tagName[@attrName="attrValue"]
- 索引定位://tagName[index]:index是从1开始
- 模糊匹配:
- //div[contains(@class, "ng")]
- //div[starts-with(@class, "ta")]
-
取文本
- /text():取得直系的文本内容(返回列表元素是单个)
- //text():取得所有的文本内容(返回列表元素是多个)
-
取属性
- /@attrName
from lxml import etree
tree = etree.parse('./test.html')
tree.xpath('/html/head/title')
tree.xpath('/html//title')
tree.xpath('//title')
tree.xpath('//div')
tree.xpath('/html//title')
tree.xpath('//div[@class="song"]')
tree.xpath('//div[@class="tang"]/ul/li[1]')
tree.xpath('//div[contains(@class, "ng")]')
tree.xpath('//title/text()')[0]
tree.xpath('//div[@class="tang"]//text()')
tree.xpath('//a[@id="feng"]/@href')
案例需求1,xpath爬取糗事百科段子
将糗事百科中的段子标题和内容进行解析爬取
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
url_model = 'https://www.qiushibaike.com/text/page/%d/'
f = open('./duanzi.txt','w+',encoding='utf-8')
for page in range(1,4):
url = format(url_model%page)
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
#列表中每一个div标签都包含了我们要解析的内容
#xpath是在做全局数据解析
div_list = tree.xpath('//div[@class="col1 old-style-col1"]/div')
for div in div_list:
#div表示:div是一个Element类型的对象,表示就是页面中的一个指定的div标签
#div:html源码中的一个局部数据
#局部数据解析中:./表示xpath方法调用者表示的标签
author = div.xpath('./div[1]/a[2]/h2/text()')[0] #局部数据解析,只可以定位div这个局部数据中的相关标签
content = div.xpath('./a[1]/div/span//text()')
content = ''.join(content)
# print(author,content)
f.write(f'作者:{author}内容:{content}')
f.close()

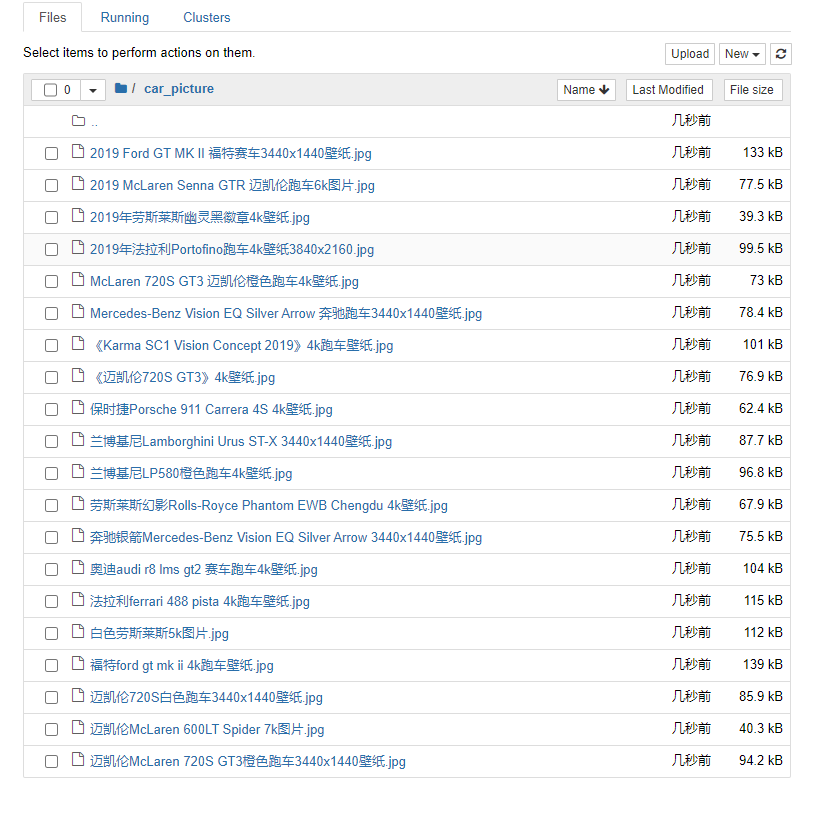
案例需求2,xpath图片数据爬取
import requests
from lxml import etree
import os
from urllib import request
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
dirName = 'car_picture'
if not os.path.exists(dirName):
os.mkdir(dirName)
url = 'http://pic.netbian.com/4kqiche/'
response = requests.get(url,headers=headers)
response.encoding = 'gbk'
page_text = response.text
tree = etree.HTML(page_text)
#解析图片名称+图片链接
li_list = tree.xpath('//*[@id="main"]/div[3]/ul/li')
for li in li_list:#局部数据解析,一定要使用./操作
img_name = li.xpath('./a/img/@alt')[0]+'.jpg'
img_src = 'http://pic.netbian.com'+li.xpath('./a/img/@src')[0]
img_path = dirName+'/'+img_name #图片存储路径
request.urlretrieve(img_src,img_path) #把图片存储到指定位置
print(img_name,'下载成功!!!')
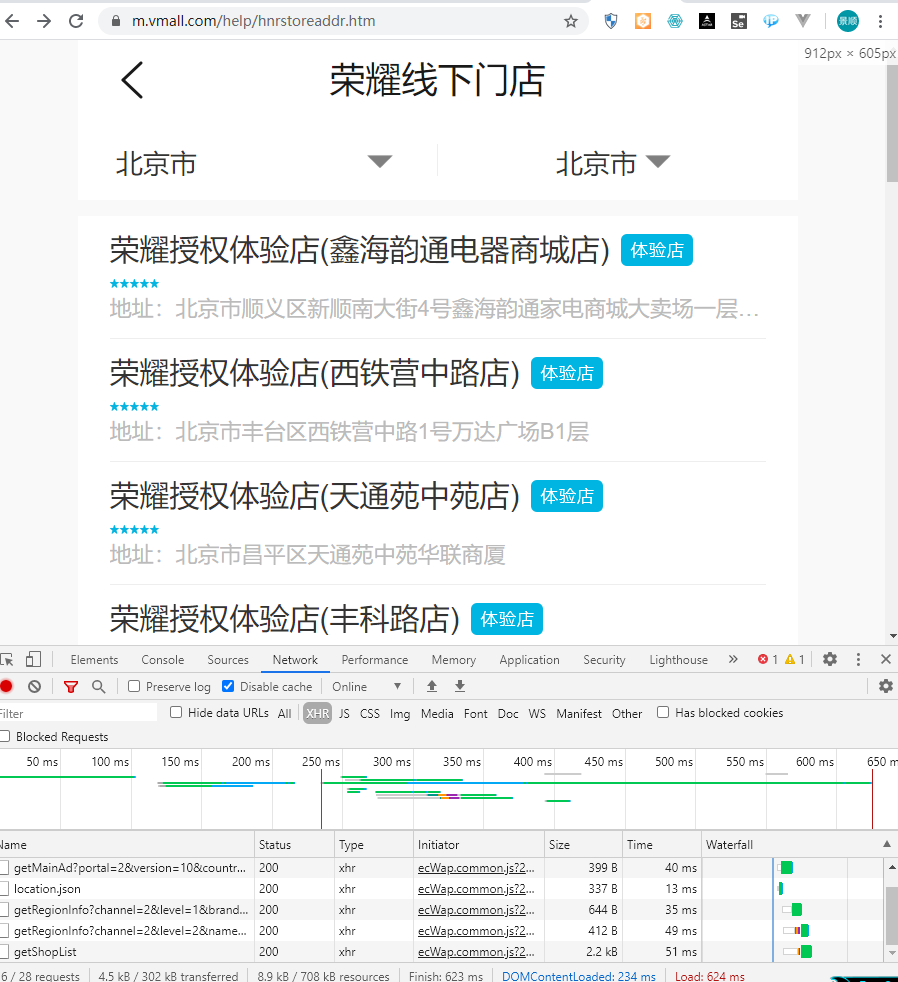
案例需求3,xpath爬取每一个店铺详情页中数据
面试题:
- url:https://m.vmall.com/help/hnrstoreaddr.htm
- 爬取每一个店铺详情页中的店铺地址+营业时间
1:将某一个店铺详情页的指定数据获取
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
url = 'https://openapi.vmall.com/mcp/offlineshop/getShopById'
params = {
'portal': '2',
'version': '10',
'country': 'CN',
'shopId': '107527',
'lang': 'zh-CN',
}
json_data = requests.get(url=url,headers=headers,params=params).json()
address = json_data['shopInfo']['address']
time_ = json_data['shopInfo']['serviceTime']
print(address,time_)
>>>
北京市顺义区新顺南大街4号鑫海韵通家电商城大卖场一层荣耀体验店 9:00-19:30
2、分析比较两次数据找出不同,获取每一家店铺的id即可
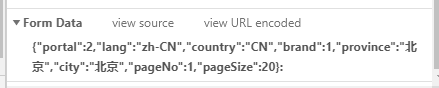
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
user_input = input('输入爬取多少条数据:')
main_url = 'https://openapi.vmall.com/mcp/offlineshop/getShopList'
data = {"portal":2,"lang":"zh-CN","country":"CN","brand":1,"province":"北京","city":"北京","pageNo":1,"pageSize":user_input}
# data是字典格式的数据需要进行dumps操作,通过requests中的json进行处理
main_json_data = requests.post(url=main_url,headers=headers,json=data).json()
for dic in main_json_data['shopInfos']:
id_ = dic['id']
url = 'https://openapi.vmall.com/mcp/offlineshop/getShopById'
params = {
'portal': '2',
'version': '10',
'country': 'CN',
'shopId': id_,
'lang': 'zh-CN',
}
json_data = requests.get(url=url,headers=headers,params=params).json()
address = json_data['shopInfo']['address']
time_ = json_data['shopInfo']['serviceTime']
print(address,time_)
>>>
输入爬取多少条数据:30
北京市顺义区新顺南大街4号鑫海韵通家电商城大卖场一层荣耀体验店 9:00-19:30
北京市丰台区西铁营中路1号万达广场B1层 9:00-18:00
北京市昌平区天通苑中苑华联商厦 9:30-21:30
北京市丰台区丰科路6号院丰台万达广场3层 9:00-18:00
北京市昌平区北清路一号院永旺国际商城一层D2口 10:00-22:00
北京市大兴区天宫院凯德MALL地下二层 9:00-22:00
北京市东城区崇文门外大街18号国瑞购物中心二层 9:00-22:00
北京市西城区西大北大街131号大悦城5层 10:00-22:00
北京市大兴区黄村镇狼垡长丰园2区3号楼底商 9:00-21:00
北京市通州区漷县镇通房路鑫玉园小区底商8号 8:00-21:00
窦店镇三仁商场地商华科数码 10:00-18:30
城关南大街51号 10:00-18:30
长阳路和长泽南路交汇处中粮万科半岛广场二层有氧。社UP+ 10:00-18:30
良乡北关西路22号 10:00-18:30
西四环南路101号富丰园社区大中电器 9:00-21:00
公益西桥乐天玛特四层苏宁电器荣耀展台 9:30-20:30
南三环中路10号苏宁电器一层 9:30-20:30
南三环东路27号芳群公寓底商 9:00-20:30
南三环马家堡店西路嘉园一里26号楼 9:00-20:30
大红门西路住宅小区24号配套商业楼 9:30-20:30
青塔西路11号苏宁电器 09:30-20:00
东铁匠营顺一条10号 10:00-18:30
南三环海户西里1号(洋桥东南角)大中电器 10:00-18:30
南宫商业街3号恒源商厦B1层 10:00-18:30
西三环南路甲10号国美六里桥电器 10:00-18:30
南三环东木樨园9号 10:00-18:30
西三环南路10号六里桥易初莲花超市边 10:00-18:30
西四环南路20号(兴隆手机市场一层) 10:00-18:30
顺八条一号宋家庄化工大楼(顺八条北) 10:00-18:30
正阳大街127号 10:00-18:30
案例需求4,xpath爬取所有城市名称

import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
url = 'https://www.aqistudy.cn/historydata/'
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
hot_cities = tree.xpath('//div[@class="bottom"]/ul/li/a/text()')
print(hot_cities)
>>>
['北京', '上海', '广州', '深圳', '杭州', '天津', '成都', '南京', '西安', '武汉']
all_cities = tree.xpath('//div[@class="bottom"]/ul/div[2]/li/a/text()')
print(all_cities)
>>>
['阿坝州', '安康', '阿克苏地区', '阿里地区', '阿拉善盟', '阿勒泰地区', '安庆', '安顺', '鞍山', '克孜勒苏州', '安阳', '蚌埠', '白城', '保定', '北海', '宝鸡', '北京', '毕节', '博州', '百色', '白沙', '白山', '保山', '保亭', '包头', '本溪', '白银', '巴彦淖尔', '滨州', '巴中', '亳州', '长春', '承德', '成都', '常德', '昌都', '赤峰', '昌江', '昌吉州', '五家渠', '澄迈', '重庆', '常熟', '长沙', '楚雄州', '朝阳', '滁州', '郴州', '潮州', '常州', '长治', '崇左', '沧州', '池州', '定安', '丹东', '东方', '东莞', '德宏州', '大连', '大理州', '大庆', '大同', '定西', '大兴安岭地区', '黔南州', '德阳', '东营', '达州', '德州', '儋州', '鄂尔多斯', '恩施州', '鄂州', '防城港', '抚顺', '佛山', '阜新', '阜阳', '富阳', '福州', '抚州', '广安', '贵港', '果洛州', '桂林', '甘南州', '贵阳', '广元', '固原', '广州', '甘孜州', '赣州', '淮安', '淮北', '鹤壁', '海北州', '河池', '邯郸', '海东地区', '哈尔滨', '合肥', '黄冈', '鹤岗', '红河州', '怀化', '黑河', '呼和浩特', '海口', '呼伦贝尔', '葫芦岛', '海门', '哈密地区', '淮南', '黄南州', '海南州', '黄山', '衡水', '黄石', '和田地区', '海西州', '衡阳', '河源', '湖州', '汉中', '杭州', '贺州', '菏泽', '惠州', '吉安', '金昌', '晋城', '景德镇', '西双版纳州', '金华', '九江', '吉林', '荆门', '江门', '即墨', '佳木斯', '济南', '济宁', '胶南', '酒泉', '句容', '湘西州', '金坛', '嘉兴', '鸡西', '济源', '揭阳', '江阴', '嘉峪关', '锦州', '荆州', '晋中', '焦作', '胶州', '库尔勒', '开封', '黔东南州', '克拉玛依', '昆明', '昆山', '喀什地区', '临安', '六安', '来宾', '聊城', '临沧', '乐东', '娄底', '廊坊', '临汾', '临高', '漯河', '丽江', '吕梁', '陇南', '六盘水', '丽水', '凉山州', '拉萨', '乐山', '陵水', '莱芜', '临夏州', '莱西', '辽源', '辽阳', '溧阳', '龙岩', '洛阳', '临沂', '连云港', '莱州', '林芝', '泸州', '柳州', '兰州', '马鞍山', '牡丹江', '茂名', '眉山', '绵阳', '梅州', '宁波', '南充', '南昌', '宁德', '南京', '内江', '怒江州', '南宁', '南平', '那曲地区', '南通', '南阳', '平度', '平顶山', '普洱', '盘锦', '蓬莱', '平凉', '莆田', '萍乡', '濮阳', '攀枝花', '青岛', '琼海', '秦皇岛', '曲靖', '齐齐哈尔', '七台河', '黔西南州', '清远', '庆阳', '钦州', '衢州', '琼中', '泉州', '荣成', '日喀则', '乳山', '日照', '寿光', '韶关', '上海', '绥化', '石河子', '石家庄', '商洛', '三明', '三门峡', '遂宁', '山南', '四平', '宿迁', '商丘', '上饶', '汕头', '汕尾', '绍兴', '松原', '沈阳', '十堰', '三亚', '邵阳', '双鸭山', '朔州', '苏州', '宿州', '随州', '深圳', '石嘴山', '泰安', '铜川', '屯昌', '太仓', '塔城地区', '通化', '天津', '铁岭', '铜陵', '通辽', '吐鲁番地区', '铜仁地区', '唐山', '天水', '太原', '台州', '泰州', '文昌', '文登', '潍坊', '瓦房店', '武汉', '乌海', '芜湖', '威海', '吴江', '乌兰察布', '乌鲁木齐', '渭南', '万宁', '文山州', '武威', '无锡', '温州', '梧州', '吴忠', '五指山', '兴安盟', '西安', '宣城', '许昌', '襄阳', '孝感', '迪庆州', '锡林郭勒盟', '厦门', '西宁', '咸宁', '湘潭', '邢台', '新乡', '咸阳', '新余', '信阳', '忻州', '徐州', '雅安', '延安', '延边州', '宜宾', '伊春', '银川', '宜春', '宜昌', '盐城', '运城', '云浮', '阳江', '营口', '玉林', '榆林', '伊犁哈萨克州', '阳泉', '玉树州', '烟台', '鹰潭', '义乌', '宜兴', '玉溪', '益阳', '岳阳', '永州', '扬州', '淄博', '自贡', '珠海', '镇江', '湛江', '诸暨', '张家港', '张家界', '张家口', '周口', '驻马店', '章丘', '肇庆', '舟山', '中山', '昭通', '中卫', '招远', '资阳', '张掖', '遵义', '郑州', '漳州', '株洲', '枣庄']
利用管道符进行合并
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
url = 'https://www.aqistudy.cn/historydata/'
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
all_cities = tree.xpath('//div[@class="bottom"]/ul/div[2]/li/a/text() |//div[@class="bottom"]/ul/li/a/text()')
print(all_cities)
>>>
['北京', '上海', '广州', '深圳', '杭州', '天津', '成都', '南京', '西安', '武汉', '阿坝州', '安康', '阿克苏地区', '阿里地区', '阿拉善盟', '阿勒泰地区', '安庆', '安顺', '鞍山', '克孜勒苏州', '安阳', '蚌埠', '白城', '保定', '北海', '宝鸡', '北京', '毕节', '博州', '百色', '白沙', '白山', '保山', '保亭', '包头', '本溪', '白银', '巴彦淖尔', '滨州', '巴中', '亳州', '长春', '承德', '成都', '常德', '昌都', '赤峰', '昌江', '昌吉州', '五家渠', '澄迈', '重庆', '常熟', '长沙', '楚雄州', '朝阳', '滁州', '郴州', '潮州', '常州', '长治', '崇左', '沧州', '池州', '定安', '丹东', '东方', '东莞', '德宏州', '大连', '大理州', '大庆', '大同', '定西', '大兴安岭地区', '黔南州', '德阳', '东营', '达州', '德州', '儋州', '鄂尔多斯', '恩施州', '鄂州', '防城港', '抚顺', '佛山', '阜新', '阜阳', '富阳', '福州', '抚州', '广安', '贵港', '果洛州', '桂林', '甘南州', '贵阳', '广元', '固原', '广州', '甘孜州', '赣州', '淮安', '淮北', '鹤壁', '海北州', '河池', '邯郸', '海东地区', '哈尔滨', '合肥', '黄冈', '鹤岗', '红河州', '怀化', '黑河', '呼和浩特', '海口', '呼伦贝尔', '葫芦岛', '海门', '哈密地区', '淮南', '黄南州', '海南州', '黄山', '衡水', '黄石', '和田地区', '海西州', '衡阳', '河源', '湖州', '汉中', '杭州', '贺州', '菏泽', '惠州', '吉安', '金昌', '晋城', '景德镇', '西双版纳州', '金华', '九江', '吉林', '荆门', '江门', '即墨', '佳木斯', '济南', '济宁', '胶南', '酒泉', '句容', '湘西州', '金坛', '嘉兴', '鸡西', '济源', '揭阳', '江阴', '嘉峪关', '锦州', '荆州', '晋中', '焦作', '胶州', '库尔勒', '开封', '黔东南州', '克拉玛依', '昆明', '昆山', '喀什地区', '临安', '六安', '来宾', '聊城', '临沧', '乐东', '娄底', '廊坊', '临汾', '临高', '漯河', '丽江', '吕梁', '陇南', '六盘水', '丽水', '凉山州', '拉萨', '乐山', '陵水', '莱芜', '临夏州', '莱西', '辽源', '辽阳', '溧阳', '龙岩', '洛阳', '临沂', '连云港', '莱州', '林芝', '泸州', '柳州', '兰州', '马鞍山', '牡丹江', '茂名', '眉山', '绵阳', '梅州', '宁波', '南充', '南昌', '宁德', '南京', '内江', '怒江州', '南宁', '南平', '那曲地区', '南通', '南阳', '平度', '平顶山', '普洱', '盘锦', '蓬莱', '平凉', '莆田', '萍乡', '濮阳', '攀枝花', '青岛', '琼海', '秦皇岛', '曲靖', '齐齐哈尔', '七台河', '黔西南州', '清远', '庆阳', '钦州', '衢州', '琼中', '泉州', '荣成', '日喀则', '乳山', '日照', '寿光', '韶关', '上海', '绥化', '石河子', '石家庄', '商洛', '三明', '三门峡', '遂宁', '山南', '四平', '宿迁', '商丘', '上饶', '汕头', '汕尾', '绍兴', '松原', '沈阳', '十堰', '三亚', '邵阳', '双鸭山', '朔州', '苏州', '宿州', '随州', '深圳', '石嘴山', '泰安', '铜川', '屯昌', '太仓', '塔城地区', '通化', '天津', '铁岭', '铜陵', '通辽', '吐鲁番地区', '铜仁地区', '唐山', '天水', '太原', '台州', '泰州', '文昌', '文登', '潍坊', '瓦房店', '武汉', '乌海', '芜湖', '威海', '吴江', '乌兰察布', '乌鲁木齐', '渭南', '万宁', '文山州', '武威', '无锡', '温州', '梧州', '吴忠', '五指山', '兴安盟', '西安', '宣城', '许昌', '襄阳', '孝感', '迪庆州', '锡林郭勒盟', '厦门', '西宁', '咸宁', '湘潭', '邢台', '新乡', '咸阳', '新余', '信阳', '忻州', '徐州', '雅安', '延安', '延边州', '宜宾', '伊春', '银川', '宜春', '宜昌', '盐城', '运城', '云浮', '阳江', '营口', '玉林', '榆林', '伊犁哈萨克州', '阳泉', '玉树州', '烟台', '鹰潭', '义乌', '宜兴', '玉溪', '益阳', '岳阳', '永州', '扬州', '淄博', '自贡', '珠海', '镇江', '湛江', '诸暨', '张家港', '张家界', '张家口', '周口', '驻马店', '章丘', '肇庆', '舟山', '中山', '昭通', '中卫', '招远', '资阳', '张掖', '遵义', '郑州', '漳州', '株洲', '枣庄']
-
xpath表达式中的管道符有什么好处
- 可以大大的增加xpath表达式的通用性
-
想要解析出携带html标签的页面局部内容,如何实现?
- 使用bs4

