
音频工具kaldi部署及模型制作调研学习
语音识别简介
语音识别(speech recognition)技术,也被称为自动语音识别(英语:Automatic Speech Recognition, ASR)、计算机语音识别(英语:Computer Speech Recognition)或是语音转文本识别(英语:Speech To Text, STT),其目标是以计算机自动将人类的语音内容转换为相应的文字。
按照不同纬度如下分类:
- 按词汇量(vocabulary)大小分类:
- 小词汇量:几十个词;
- 中等词汇量:几百个到上千个词
- 大词汇量:几千到几万个
- 按说话的方式(style)分类:
- 孤立词(isolated words)
- 连续(continously)
- 按声学(Acoustic)环境分类:
- 录音室
- 不同程度的噪音环境
- 按说话人(Speaker)分类:
- 说话人相关(Speaker depender)
- 说话音素(Phoneme):单词的发音都是由音素构成,对于英语,常用的音素集是 CMU 的 39 个音素构成的音素集。而对于汉语,一般直接用全部声母和韵母作为音素集,另外汉语识别还要考虑音调。
The CMU Pronouncing Dictionary.
- 声学模型 :是将声学和发音学(phonetics)的知识进行整合,以特征提取部分生成的特征作为输入,并为可变长特征序列生成声学模型分数。
- 语言模型 :通过从训练语料(通常是文本形式)学习词之间的相互关系,来估计假设词序列的可能性,又叫语言模型分数。
- GMM :Gaussian Mixture Model, 高斯混合模型,描述基于傅里叶频谱语音特征的统计模型,用于传统声学模型的建模中。
- HMM :Hidden Markov Model, 隐马尔科夫模型,是一种用来描述含有隐含未知参数的马尔科夫过程,其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
- MFCC :Mel-Frequency Cepstral Coefficients, 梅尔频率倒谱系数,是组成梅尔频率倒谱的系数。衍生自音讯片段的倒频谱(cepstrum)。倒谱与梅尔频率倒谱的区别在于,梅尔频率倒谱的频带划分是在梅尔刻度上等距划分的,它比用于正常的对数倒频谱中的线性间隔的频带更接近人类的听觉系统。广泛应用于语音识别中。
- Fbank :Mel Frequency Filter Bank, 梅尔频率滤波器组。
- WER :Word Error Rate, 词错误率,是最常见的衡量语音识别系统性能的指标。
GNN-HMM基本原理

一个语音识别系统主要包括信号处理和特征提取、声学模型训练、语言模型训练以及识别引擎等几个核心部分,下图为语音识别的原理框图:
- 特征提取 :语音识别第一步就是特征提取,去除掉语音信号中对于语音识别无用的冗余信息(如背景噪音),保留能够反映语音本质特征的信息(为后面的声学模型提取合适的特征向量),并用一定的形式表示出来;较常用的特征提取算法有 MFCC。
- 声学模型训练 :根据语音库的特征参数训练出声学模型参数,在识别的时候可以将待识别的语音的特征参数同声学模型进行匹配,从而得到识别结果。目前主流的语音识别系统多采用 HMM 进行声学模型建模。
- 语言模型训练 :就是用来计算一个句子出现的概率模型,主要用于决定哪个词序列的可能性更大。语言模型分为三个层次:字典知识、语法知识、句法知识。对训练文本库进行语法、语义分析,经过基于统计模型训练得到语言模型。
- 语音解码与搜索算法 :其中解码器就是针对输入的语音信号,根据已经训练好的声学模型、语言模型以及字典建立一个识别网络,再根据搜索算法在该网络中寻找一条最佳路径,使得能够以最大概率输出该语音信号的词串,这样就确定这个语音样本的文字。
DNN-HMM(基于神经网络)
但随着神经网络技术的发展,后面又出现了基于DNN-HMMs的语音识别模型,一句话概括就是用DNN代替之前的GMMs,有更好的建模能力。
主流的DNN模型,包括FFDNN、CDDNN、TDNN、RNN等,以及一些训练中可以使用的trick等。
https://blog.csdn.net/Magical_Bubble/article/details/90674521
本文档模型训练方式采用的是GNN-HMM
为什么调研kaldi工具

Kaldi 的架构如下图:
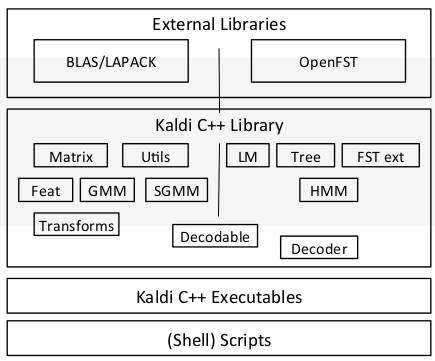
kaldi部署
依赖环境
Gcc 4.8及以上

Patch

Make .

automake

Autoconf

zlib zlib-devel

gdbm
bzip2

sqlite

openssl-devel

Readline

python3
这里我是编译安装,没有替换之前的2.7; /usr/bin下直接建立的python3的软连

Kaldi安装
解压 kaldi-master.zip
[root@localhost mnt]# cd kaldi-master/tools/
查看环境要求
[root@localhost tools]# cat INSTALL
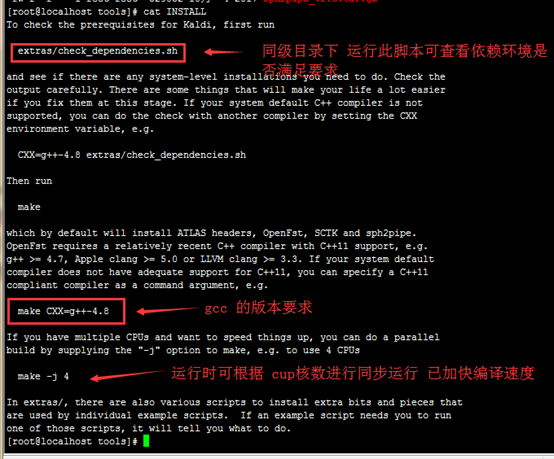
依赖环境满足的情况下 运行检查脚本 会 回执 OK 如下图

查看 cup 内核数

确认内核数 开始编译
[root@localhost tools]# make -j 8
[root@localhost tools]# ./extras/install_irstlm.sh
安装语言模型
安装编译安装,时间会有些长, 可能会出现一些编译失败的错误信息,可以根据实际报错内容进行逐个排查,
[root@localhost tools]# cd ../src/
[root@localhost src]# ./configure
[root@localhost src]# make depend
[root@localhost src]# make
检查编译成功后的执行文件
[root@localhost kaldi-master]# cd src/bin
[root@localhost bin]# ls
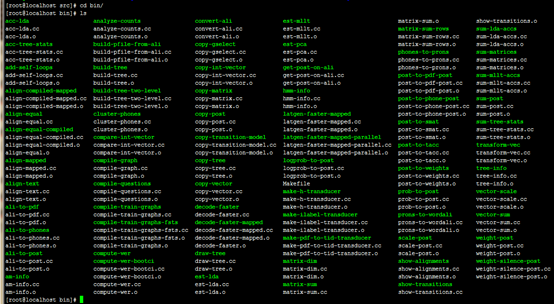
kaldi目录说明

- ./tools目录下是kaldi依赖的包
- ./src目录存放kaldi的源代码
- ./egs目录保存着一些kaldi在公共语音数据集上的训练步骤(shell脚本)以及测试的结果
- s5/run.sh包含了在这个数据集上所有的训练步骤,包括数据预处理、训练以及测试gmm/dnn/lstm/tdnn等模型、实验结果统计在内的各种脚本。理论上来说只要相关环境配置正确,运行run.sh就能完成整个训练步骤。
- s5/RESULTS里面保存着最近的实验结果
- s5/conf就是一些训练所要用到的配置文件
- s5/{local, steps, utils}里面则是run.sh所要用到的一些脚本文件
在kaldi中,目前针对深度神经网络提供三种代码库。第一个是"nnet1"(位于nnet/和nnetbin/下),最初由Karel Vesely维护;第二个"nnet2"(位于nnet2/和nnet2bin/下)最初由Daniel Povey维护;第三个"nnet3"(位于nnet3/和nnet3bin/下)由Daniel的nnet2转化而来

验证基础demo
[root@localhost kaldi-master]# cd egs/yesno/s5/
[root@localhost s5]# ./run.sh
开始下载学习集并开始制作

输出后的结果,运行到这里,说明kaldi 已经正确安装好。

WER(WordError Rate)是字错误率,是一个衡量语音识别系统的准确程度的度量。其计算公式是WER=(I+D+S)/N,其中I代表被插入的单词个数,D代表被删除的单词个数,S代表被替换的单词个数。也就是说把识别出来的结果中,多认的,少认的,认错的全都加起来,除以总单词数。这个数字当然是越低越好。
[root@localhost s5]# cd waves_yesno/
[root@localhost waves_yesno]# ll
生成的音频

制作第一个训练模型thchs30
Kaldi中文语音识别公共数据集一共有4个(据我所知),分别是:
1.aishell: AI SHELL公司开源178小时中文语音语料及基本训练脚本,见kaldi-master/egs/aishell
2.gale_mandarin: 中文新闻广播数据集(LDC2013S08, LDC2013S08)
3.hkust: 中文电话数据集(LDC2005S15, LDC2005T32)
4.thchs30: 清华大学30小时的数据集,可以在http://www.openslr.org/18/下载

这里使用thchs30数据集进行训练
已下载的数据包
|
数据集 |
音频时长(h) |
句子数 |
词数 |
|
train(训练) |
25 |
10000 |
198252 |
|
dev(开发) |
2:14 |
893 |
17743 |
|
test(测试) |
6:15 |
2495 |
49085 |
数据包简介
还有训练好的语言模型word.3gram.lm和phone.3gram.lm以及相应的词典lexicon.txt。
其中dev的作用是在某些步骤与train进行交叉验证的,如local/nnet/run_dnn.sh同时用到exp/tri4b_ali和exp/tri4b_ali_cv。训练和测试的目标数据也分为两类:word(词)和phone(音素)
1.local/thchs-30_data_prep.sh主要工作是从$thchs/data_thchs30(下载的数据)三部分分别生成word.txt(词序列),phone.txt(音素序列),text(与word.txt相同),wav.scp(语音),utt2pk(句子与说话人的映射),spk2utt(说话人与句子的映射)
2.#produce MFCC features是提取MFCC特征,分为两步,先通过steps/make_mfcc.sh提取MFCC特征,再通过steps/compute_cmvn_stats.sh计算倒谱均值和方差归一化。
3.#prepare language stuff是构建一个包含训练和解码用到的词的词典。而语言模型已经由王东老师处理好了,如果不打算改语言模型,这段代码也不需要修改。
a)基于词的语言模型包含48k基于三元词的词,从gigaword语料库中随机选择文本信息进行训练得到,训练文本包含772000个句子,总计1800万词,1.15亿汉字
b)基于音素的语言模型包含218个基于三元音的中文声调,从只有200万字的样本训练得到,之所以选择这么小的样本是因为在模型中尽可能少地保留语言信息,可以使得到的性能更直接地反映声学模型的质量。
c)这两个语言模型都是由SRILM工具训练得到。
制作开始
[root@localhost ~]# mkdir -p /DATA/works/
上传学习包并解压

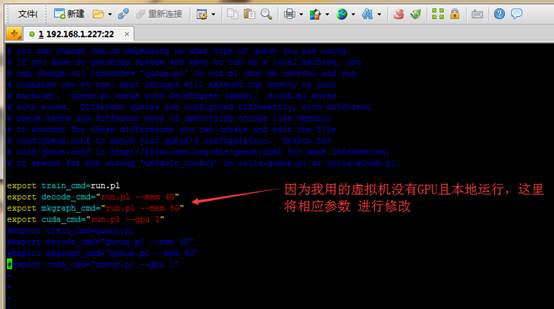
[root@localhost ~]# cd /mnt/kaldi-master/egs/thchs30/s5/
修改内容如下:
export train_cmd=run.pl
export decode_cmd="run.pl --mem 4G"
export mkgraph_cmd="run.pl --mem 8G"
export cuda_cmd="run.pl --gpu 1"
[root@localhost s5]# vim cmd.sh
[root@localhost s5]# vim run.sh
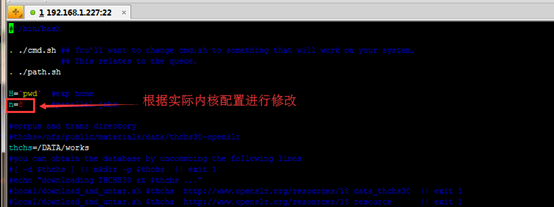
开始制作模型
[root@localhost s5]# ./run.sh
我们没有DNN(无GPU)来跑,所以运行起来会比较慢。//后续有资源的情况尝试大数据
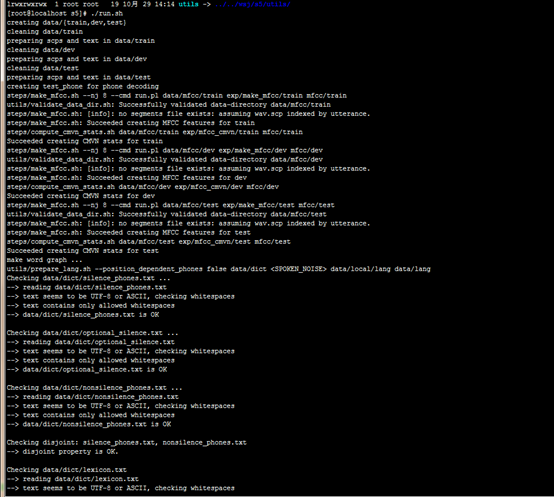
模型生成目录说明
模型生成后存放的路径thchs30/s5/exp/tri1
final.mdl 就是训练出来的可以使用的模型,另外,在 graph_word 下面的 words.txt 和 HCLG.fst 分别为字典以及有限状态机。单独介绍这三个文件,是因为我们下面的示例主要基于这三个文件来识别的。

验证模型
将制作好的模型 复制到以下路径
/mnt/kaldi-master/egs/thchs30/online_demo/online-data/models/tri1

/mnt/kaldi-master/egs/thchs30/online_demo
[root@localhost online_demo]# vim run.sh
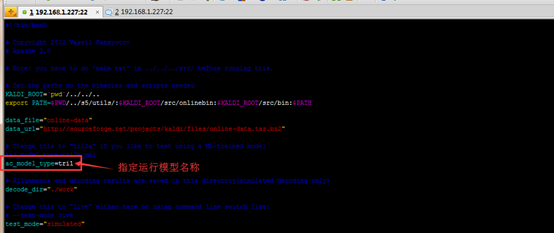
[root@localhost online_demo]# ./run.sh 模型识别的是
/mnt/kaldi-master/egs/thchs30/online_demo/online-data/audio路径下所有的单音频文件

识别的结果内容
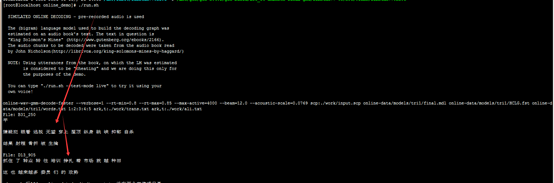
算法过程描述
大概有几个过程:数据准备,monophone单音素训练, tri1三因素训练, trib2进行lda_mllt特征变换,trib3进行sat自然语言适应,trib4做quick(这个我也不懂),后面就是dnn了
Run 脚本说明
这个脚本的输入参数有三个:1.data/mfcc/train 2.exp/make_mfcc/train 3.mfcc/train
1.data/mfcc/train中有数据预处理后的一些文件:phone.txt spk2utt text utt2spk wav.scp word.txt
2.exp/make_mfcc/train中应该是要保存程序运行的日志文件的
3.mfcc/train中是提取出的特征文件
待研究的方向
Kaldi在线识别方法
用的虚拟机,没有音频入口
后续补充
Kaldi封装实时语音翻译
后续补充
基于Kaldi+GStreamer搭建线上的实时语音识别器
https://www.jianshu.com/p/ef7326b27786
Kaldi结合GPU的模型训练
后续补充
Kaldi结合CNN的模型训练
https://blog.csdn.net/DuishengChen/article/details/50085707?locationNum=11&fps=1
后续补充
Kaldi 声纹识别ivector模型
后续补充
https://blog.csdn.net/u011930705/article/details/85340905
https://blog.csdn.net/monsieurliaxiamen/article/details/79638227
Kaldi中文识别开源模型CVTE
后续补充
https://www.jianshu.com/p/d64e70faaf1d
https://blog.csdn.net/snowdroptulip/article/details/78952428
Kaldi 训练唤醒词模型
后续补充
https://blog.csdn.net/cj1989111/article/details/88017908
FAQ
模型制作报错:/lib64/libstdc++.so.6: version `GLIBCXX_3.4.21' not found
[root@localhost ~]# find / -name libstdc++.so.6 本地看看是否有此库
这里可以看到,我本地是存在的,应该是调不到的原因
[root@localhost ~]# vim /etc/ld.so.conf
/usr/lib64/
/usr/local/lib
/usr/local/lib64
/usr/lib
加入依赖库路径
重新加载
[root@localhost ~]# ldconfig
如果不行,就用编译的gcc里的库做个软连接
[root@localhost online_demo]# ln -s
/mnt/gcc/gcc-5.4.0/gcc-build/x86_64-unknown-linux-gnu/libstdc++-v3/src/.libs/libstdc++.so.6
/usr/lib64/libstdc++.so.6
[root@localhost online_demo]# ll /usr/lib64/libstdc++.so.6
