
四、Oracle的体系结构
1. Oracle DB
- Oracle关系数据库管理系统(RDBMS)提供了开放的、全面的、集成信息管理方法;关系型数据库是基于关系模型所提出的数据库,关系模型是使用二维表的方式,行和列的方式来保存数据的模型
2. Oracle db 服务器体系架构
描述:数据库是硬盘上的文件,数据都存在文件中,要访问这些文件就要把它读到内存中,把内存中的镜像叫做实例
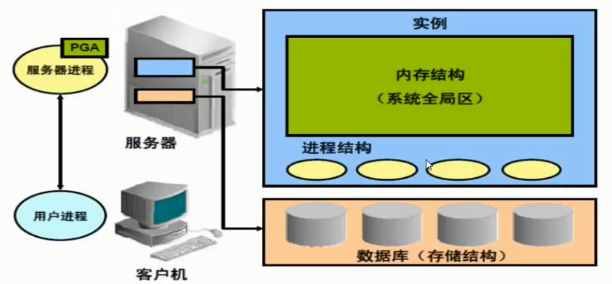
数据库文件:把以下文件读到内存中叫做实例,数据库与实例是1对多是oracle的集群,RAC
[oracle@oracledemo ~]$ ls /u01/app/oracle/oradata/orcl/ control01.ctl redo01.log redo03.log system01.dbf undotbs01.dbf example01.dbf redo02.log sysaux01.dbf temp01.dbf users01.dbf
注:dbf是数据文件, ctl是控制文件
3. oracle的存储结构
- 物理存储结构(操作系统上的文件)
a. 数据文件: dbf 保存数据
必须存在的:system(oracle数据库系统的一些关键数据)
sysaux(系统辅助的数据文件,AWR,通过它的报告可以对数据库进行优化)
temp(临时数据文件)
undo(还原数据,重要,而且闪回操作依赖于它)
可选的:example(有测试数据)、users(用户的表空间或数据文件,如普通用户要创建表来保存数据默认是放在users中)01.dbf
SQL> desc dba_data_files; Name Null? Type ----------------------------------------- -------- ---------------------------- FILE_NAME VARCHAR2(513) FILE_ID NUMBER TABLESPACE_NAME VARCHAR2(30) BYTES NUMBER BLOCKS NUMBER STATUS VARCHAR2(9) RELATIVE_FNO NUMBER AUTOEXTENSIBLE VARCHAR2(3) MAXBYTES NUMBER MAXBLOCKS NUMBER INCREMENT_BY NUMBER USER_BYTES NUMBER USER_BLOCKS NUMBER ONLINE_STATUS VARCHAR2(7) SQL> select FILE_NAME from dba_data_files; ##包含的数据文件 FILE_NAME -------------------------------------------------------------------------------- /u01/app/oracle/oradata/orcl/users01.dbf /u01/app/oracle/oradata/orcl/undotbs01.dbf /u01/app/oracle/oradata/orcl/sysaux01.dbf /u01/app/oracle/oradata/orcl/system01.dbf /u01/app/oracle/oradata/orcl/example01.dbf
b. 控制文件 ctl: 保存数据库的结构信息
- 记录了数据文件和日志文件的位置
- RMAN(recovery manager)备份时产生的元信息
SQL> desc v$controlfile #包含当前数据库中存在的控制文件 Name Null? Type ----------------------------------------- -------- ---------------------------- STATUS VARCHAR2(7) NAME VARCHAR2(513) IS_RECOVERY_DEST_FILE VARCHAR2(3) BLOCK_SIZE NUMBER FILE_SIZE_BLKS NUMBER SQL> select name from v$controlfile; NAME #以下两个控制文件是一致的,如果一个丢失,可以使用另一个来恢复,这种叫做多路复用 -------------------------------------------------------------------------------- /u01/app/oracle/oradata/orcl/control01.ctl #数据目录下 /u01/app/oracle/flash_recovery_area/orcl/control02.ctl #保存在快速恢复区下
c. log 日志文件(日志文件和数据文件的位置会保存在控制文件中)
描述:记录了客户端事务操作的信息,在客户端操作的事务信息,通过日志文件可以重现客户端事务操作,oracle的日志文件是通过日志组来保存,默认情况下,oracle11g r2存在三个日志组,如有3个日志组,要恢复,要保证每个日志组中存在两个成员,写日志时,是通过写日志组的方式来写,首先向第一个日志组中写入日志相关的信息,同时写两个文件,如果1号日志组已经写满了,会切换到2号日志组中继续写日志,如果2号日志组也写满了,会切换到3号日志组中写,但是在oracle中,默认每个日志组只有一个成员,所以为了保证能够恢复,要再添加一个成员
SQL> desc v$log
Name Null? Type
----------------------------------------- -------- ----------------------------
GROUP# NUMBER
THREAD# NUMBER
SEQUENCE# NUMBER
BYTES NUMBER
BLOCKSIZE NUMBER
MEMBERS NUMBER
ARCHIVED VARCHAR2(3)
STATUS VARCHAR2(16)
FIRST_CHANGE# NUMBER
FIRST_TIME DATE
NEXT_CHANGE# NUMBER
NEXT_TIME DATE
SQL> select GROUP#,MEMBERS,STATUS from v$log; #日志组的信息
GROUP# MEMBERS STATUS
---------- ---------- ----------------
1 1 INACTIVE
2 1 INACTIVE
3 1 CURRENT
SQL> desc v$logfile
Name Null? Type
----------------------------------------- -------- ----------------------------
GROUP# NUMBER
STATUS VARCHAR2(7)
TYPE VARCHAR2(7)
MEMBER VARCHAR2(513)
IS_RECOVERY_DEST_FILE VARCHAR2(3)
SQL> select GROUP#,MEMBER from v$logfile;
GROUP#
----------
MEMBER
--------------------------------------------------------------------------------
3
/u01/app/oracle/oradata/orcl/redo03.log
2
/u01/app/oracle/oradata/orcl/redo02.log
1
/u01/app/oracle/oradata/orcl/redo01.log
- 逻辑存储结构
4. 数据文件和日志文件的关系
描述:数据文件是后缀为dbf的,日志文件是记录客户端操作的日志信息,如客户端commit一条事务操作,那么事务的相关信息就会记录到日志文件中
客户端做一个连接操作后,连接到内存的实例中,操作完成后做一个commit操作,实际在内存中的实例是维护一个队列,叫做检查点对列,检查点队列上保存的都是脏数据,也就是这块数据已经被更改了而且保存在内存中,但是并没有写到硬盘上的数据文件中的数据叫做脏数据.
因此,客户端连接到实例上进行操作时,客户端操作的所有脏数据,实际是保存在检查点队列上的,要做一个commit,实际是把所有的脏数据写到数据文件上,提交时,日志文件会记录客户端事务操作的信息。
当客户端发送一个提交的操作后,首先oracle数据库会把客户端操作事务的信息写入到日志中,只要日志写入成功,commit就算成功,但是脏数据还是保存在内存中,当oracle系统发出检查点(信号)时,数据库会最高优先级唤醒dbwm进程来写脏数据到数据文件中
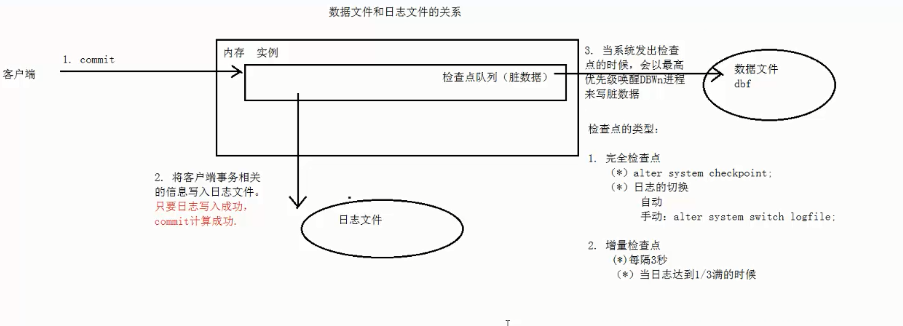
检查点类型:
a. 完全检查点(oracle9i前),数据库的写进程会把检查点队列中所有脏数据全部写到数据文件中发出检查点方式
- alter system checkpoint;
- 发生日志的切换时,oracle默认有三个日志组,写日志时是以组的单元来写,写满第一个日志组会写第二个日志组,第二个满到第三个,这个就是日志切换,日志切换有两种方式就是写满时切换,另一种就是手动触发alter system switch logfile
b.增量检查点(9i后),每次写数据时,不把所有的脏数据写入数据文件中,每次只写一部分的脏数据,
- 每隔3秒,系统默认的参数
- 当日志达到三分之一满时
设计原因:一旦事务提交,日志被写入日志文件中,如果检查点中的对应的脏数据也被写到对应的数据文件上,那么所对应的日志信息就可以被删除
5. 参数文件
两种类型:spfile(10g之后,二进制文件,比较安全)和pfile(oracle9i和之前,基于文本)
[oracle@oracledemo ~]$ sqlplus / as sysdba SQL> show parameter spfile; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ spfile string /u01/app/oracle/product/11.2.0 /dbhome_1/dbs/spfileorcl.ora [oracle@oracledemo ~]$ cd /u01/app/oracle/product/11.2.0/dbhome_1/dbs/ [oracle@oracledemo dbs]$ ls hc_DBUA0.dat hc_orcl.dat init.ora lkORCL orapworcl peshm_DBUA0_0 peshm_orcl_0 spfileorcl.ora #二进制文件,包含oracle最基本参数的设置
将spfile转换成pfile: create pfile='/home/oracle/pfile_orcl.ora' from spfile;
SQL> create pfile='/home/oracle/pfile_orcl.ora' from spfile; File created. [oracle@oracledemo ~]$ vim /home/oracle/pfile_orcl.ora #记录控制文件的位置,在控制文件中实际是记录数据文件 *.control_files='/u01/app/oracle/oradata/orcl/control01.ctl','/u01/app/oracle/flash_recovery_area/orcl/control02.ctl' # 8192表示8K块的大小 *.db_block_size=8192 #数据库的名称 *.db_name='orcl' # 审计:发生的一些事件会记录在数据库中,由这个参数决定 *.audit_trail='db' # 在同一个会话中,最多可以打开300个光标 *.open_cursors=300 # oracle默认的还原表空间 *.undo_tablespace='UNDOTBS1'
打开数据库的过程
spfile(startup命令) --> 记录控制文件信息 --> 控制文件中记录日志文件和数据文件的位置 --> 找到后才最终打开数据库
6. 告警日志和跟踪文件
- 记录警告和错误信息
SQL> show parameter dump NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ background_core_dump string partial background_dump_dest string /u01/app/oracle/diag/rdbms/orcl/orcl/trace #### core_dump_dest string /u01/app/oracle/diag/rdbms/orcl/orcl/cdump max_dump_file_size string unlimited shadow_core_dump string partial user_dump_dest string /u01/app/oracle/diag/rdbms/orcl/orcl/trace [oracle@oracledemo ~]$ ls /u01/app/oracle/diag/rdbms/orcl/orcl/trace alert_orcl.log 查找问题和错误 orcl_ora_17404.trc 跟踪会话或sql的执行过程文件,与调优相关 orcl_m000_20714.trm trc文件的源信息
- 记录启动和停止数据库的日志
描述:startup启动数据库时,shutdown数据库时都会被写入告警日志
- 强制审计的信息(5种类型审计,如强制)
- oracle数据库死锁的信息
7. 逻辑存储结构
- 表空间:tablespace 通过表空间来管理数据文件,一个表空间可以包含多个数据文件,一个数据文件只能属于一个表空间
必须存在:system, sysaux(系统辅助),temp,undo(还原数据)
可选: example,users(作为普通用户,如果没有指定对应的表空间,默认是users,对应就是users01.dbf)
- 段: segment, 一个表就是一个段,create table时就是创建一个段,也是一个逻辑结构,被包含在上层结构表空间中,一个表空间包含多个段,可能存在不同的数据文件上,一个段由区组成
常用的段是:表段和索引段
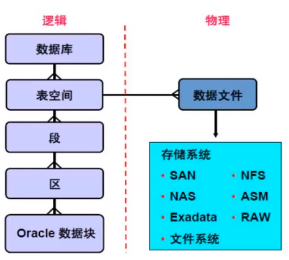
- 区:extent 分配数据的最小单元
- 数据块: 最小的逻辑单位是block,8K
8. 通过OEM查看Oracle的存储结构
https://192.168.201.93:1158/em/console/logon/logon username: sys password: password role: SYSDBA
9. 进程结构
描述:客户端提交时需要连接到oracle数据库上去,这是一个客户端进程
- 客户端进程: 代表客户端
- logwriter: 当客户端commit时,把事务日志写到日志文件中
- ckpt: checkpoint process 检查点进程来触发
- DBWn: 数据库写进程,n代表进程的个数
SQL> show parameter db_writer; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_writer_processes integer 1 #决定有几个写进程,原则上是越多越好,但是不要超过CPU的核数
- ARCn归档进程(n个数):客户端commit,lgwr会到事务写到日志中,如果这个日志被写满了,新的日志就无法写入
归档模式有两种方式:把新的日志覆盖旧的日志(非归档模式,默认)
归档模式(把日志存在一个新的文件中,归档模式下才能看到这个进程)
分析:如果要做数据库的备份在非归档模式下,只能做冷备份,把数据库进行停机之后才以进行备份,如果要做热备份,同时做备份,这时必须是归档模式
通过linux命令查看进程
[oracle@oracledemo ~]$ ps aux|grep ora_ oracle 20966 0.0 9.5 1401484 293472 ? Ss Jul13 0:44 ora_dbw0_orcl oracle 20968 0.0 1.3 1412624 42932 ? Ss Jul13 0:56 ora_lgwr_orcl oracle 20970 0.0 0.8 1397076 25912 ? Ss Jul13 1:54 ora_ckpt_orcl oracle 20948 0.0 0.5 1397708 16924 ? Ss Jul13 0:10 ora_pmon_orcl **** oracle 20972 0.0 6.4 1403796 199212 ? Ss Jul13 0:17 ora_smon_orcl **** pmon进程:process monitor 进程监视器,负责客户端的执行过程,如果客户端执行过程中有异常,它会自动启动,把遗留的垃圾清理 smon进程:system monitor 系统监视器,oracle最核心的进程,它死掉,oracle就死掉,关闭oracle最快方式直接把它杀掉
10. 内存结构PGA和SGA
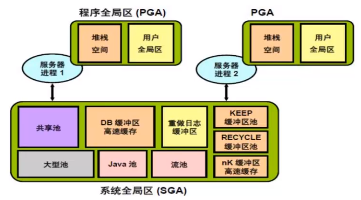
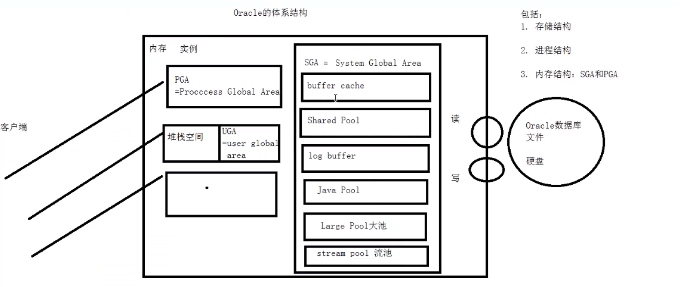
PGA分为堆栈空间(保存临时变量)、UGA(user gobal area保存用户规划的一些信息)
SQL> show parameter pga; #决定PGA大小,0是指大小由oracle数据库自动分配 NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ pga_aggregate_target big integer 0 SGA大小 SQL> show parameter sga; NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ lock_sga boolean FALSE pre_page_sga boolean FALSE sga_max_size big integer 1200M ###手动设置SGA,最大不能超过1200M,为了防止内存的溢出 sga_target big integer 0 ###自动分配
11.SGA中各个池及作用
- buffer cache池:数据的调整缓存,如果使用select语句查询时,已经存在这个池,就直接从它读取
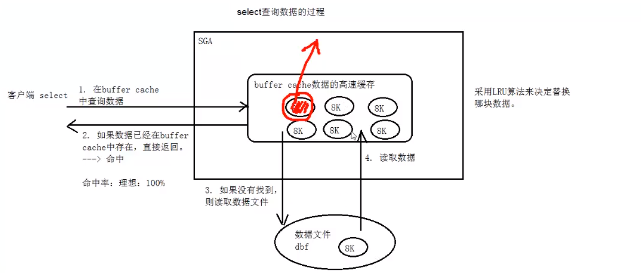
select查询语句的过程
描述:在内存中SGA池中,存在一块buffer cache的高速缓存区域,如客户端要执行一条select查询语句来查询数据,数据最终是存放在数据文件中,首先会到buffer cache中查询想要的数据,如果有就直接缓存数据给客户端,这种叫做一次命中,对于buffer cache的理想命中率是100%,也就是要查询的数据都可以在buffer cache中都可以找到,如果没有找到才真正去读
取数据文件,这时就会发生物理I/O把数据从数据文件中读取到内存buffer cache中,作为缓存.oracle数据库数据块默认的大小是8K,也就是从数据文件中读取数据到buffer cache时,默认也是8K
SQL> show parameter db_ #决定读取数据块的大小,也就是保存在buffer cache的大小 NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_16k_cache_size big integer 0 db_2k_cache_size big integer 0 db_32k_cache_size big integer 0 db_4k_cache_size big integer 0 db_8k_cache_size big integer 0
当buffer cache满了,要把那些数据删除,释放空间所采用的是LRU算法
LRU:最近最少使用算法
SQL> show parameter db_cache_size NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_cache_size big integer 0 #自动分配
shared pool共享池
(*) SQL的执行计划、数据字典的信息
描述:当一条SQL语句,可能被不同的用户执行,如果前面的用户已经执行过SQL语句,后面的用户直接取出执行计划就可以,
数据字典会被不同的用户进行查询,所以会放到共享池中提高数据库的性能
(*) 共享池的大小
SQL> show parameter shared_pool NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ shared_pool_reserved_size big integer 10066329 shared_pool_size big integer 0
log buffer:日志缓冲区
(*) 记录事务日志的缓冲区域
SQL> show parameter log_buffer #手动设置,不用设置过大,如果对应的数据写到数据文件中,日志就可以不用了 NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ log_buffer integer 12320768 JAVA pool 描述:需要JAVA虚拟机的资源可能会使用 large pool 描述:操作大对象时使用,如一首歌,或照片时,都会使用大池 stream pool: 流池 SQL> show parameter pool NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ buffer_pool_keep string buffer_pool_recycle string global_context_pool_size string java_pool_size big integer 0 large_pool_size big integer 0 olap_page_pool_size big integer 0 shared_pool_reserved_size big integer 10066329 shared_pool_size big integer 0 streams_pool_size big integer 0
12. Oracle的自动内存管理
- AMM: Automatic Memory Management
描述:实例内存总的大小是n*PGA + SGA,但PGA和SGA内存由oracle自行分配管理,这种PGA和SGA的管理方式叫做AMM
(*)决定实例内存总的大小: n*PGA + SGA #n是个数
(*)内存总的大小
SQL> show parameter memory_target NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ memory_target big integer 1200M #n个PGA加上SGA的大小 默认的SGA和PGA是oracle自动分配的 sga_target big integer 0 pga_aggregate_target big integer 0
- ASMM: Automatic Shared Memory Management
描述:自动共享内存管理
(*) 决定的是SGA中各个池的大小
db_cache_size big integer 0 shared_pool_size big integer 0 java_pool_size big integer 0 large_pool_size big integer 0 streams_pool_size big integer 0 OEM查看:https://192.168.201.93:1158/em 服务器--> 内存管理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号