
Python攻克之路-继承式调用(通过类去创建线程)
一、函数式创建子线程
import threading
def foo(n):
pass
t1=threading.Thread(target=foo,args=(1,))
t1.start()
1.继承式调用(通过类去创建线程)
[root@node2 threading]# cat class-threading.sh
#!/usr/local/python3/bin/python
import threading
import time
class Mythread(threading.Thread): #定义一个类,继承threading.Thread类
def __init__(self,num): #把要传入的参数num放在init中
threading.Thread.__init__(self)
self.num = num #实例变量,参数存放在对象中
def run(self): #定义每个线程要运行函数,run是父类方法的重写,变量给run方法使用
print("running on number:%s" %self.num)
time.sleep(3)
if __name__=='__main__':
t1 = Mythread(1) #创建子线程,也就是实例化一个对象,直接调用init方法,实例化对象的参数就是方法的参数
t2 = Mythread(2) #实例对象没有调用run方法,但是内部方法一系列运行后调用
t1.start() #开启子线程
t2.start()
[root@node2 threading]# python3 class-threading.sh
running on number:1
running on number:2
2.同步锁
需求:有一个数字100,让它减1,一个函数对它减1
实现:通过多线程同时执行100次减1

[root@node2 lock]# cat lock.py
#!/usr/local/python3/bin/python
import time
import threading
def addNum(): #100的数,调用这个函数一次减1就是99.num要为0就要执行100次,但是这种操作比较慢
global num #在每个线程中都获取这个全局变量
num-=1 ##CPU执行这种时,不用到CPU切换就直接执行完,全局变量已经被修改,下一个线程取的是99,以此类推
num = 100 #设定一个共享变量,也就是全局上定义
thread_list = []
for i in range(100): #通过for循环创建100个线程
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t) #把100个线程对象加入到列表中去,主要对一100个对象进行join(),不要与主线程一起跑
for t in thread_list: #等待所有线程执行完毕
t.join()
print('final num:',num)
[root@node2 lock]# python3 lock.py
final num: 0
需求:把累加的步骤拆分
问题:使用不同的格式来写变量,出现不同的结果,主要是做num-=1时,把动作插分开而导致

分析:程序执行从上到下执行,有一个100,100是一个全局的变量,100个线程可以同时操作一个变量,数据是共享的,同时起了100个线程,有先后,但是时间非常少,同样的去执行addNum函数,如第一个线程得到100后,当把temp=num,time.sleep(0.1)执行完后,可能cpu切换了,转换到另一个线程上,这时num还没有做减1的动作,CPU切换到另外一个线程上,它也是得到100,它也执行减1的动作,这两个线程都想对100进行减1,第二个线程减完后等于99,再加到另一个线程也是100-1,导致两个线程都同时做这件事,线程不安全
[root@node2 lock]# cat lock.py
#!/usr/local/python3/bin/python
import time
import threading
def addNum():
global num
temp=num ##使用temp替代num
time.sleep(0.1) ##sleep一下
num =temp-1
num = 100
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list:
t.join()
print('final num:',num)
[root@node2 lock]# python3 lock.py
final num: 99
[root@node2 lock]# cat lock.py
#!/usr/local/python3/bin/python
import time
import threading
def addNum():
global num
temp=num
time.sleep(0.00001)
num =temp-1
num = 100
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list:
t.join()
print('final num:',num)
[root@node2 lock]# python3 lock.py
final num: 25
问题:有时最终的结果产生不同结果,如0,1
分析:正常的情况下CPU是会切换的,结果是1,覆盖了1次,本来是0,覆盖一次就是1,主要是时间比较短,而不同的CPU也有不同的效果
[root@node2 lock]# cat lock.py
#!/usr/local/python3/bin/python
import time
import threading
def addNum():
global num
temp=num
num =temp-1
num = 100
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list:
t.join()
print('final num:',num)
[root@node2 lock]# python3 lock.py
final num: 0
[root@node2 lock]# python3 lock.py
final num: 0
[root@node2 lock]# python3 lock.py
final num: 0
[root@node2 lock]# cat lock.py
#!/usr/local/python3/bin/python
import time
import threading
def addNum():
global num
temp=num
print('ok')
num =temp-1
num = 100
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list:
t.join()
print('final num:',num)
[root@node2 lock]# python3 lock.py
ok #加上Print('ok')有了中间的时间,明显产生不同的结果,造成有的可以覆盖,有的不可以覆盖
final num: 14
[root@node2 lock]# python3 lock.py
ok
final num: 0
[root@node2 lock]# python3 lock.py
ok
final num: 11
中间加上时间,对于CPU来说,都是比较长的,所以切换就会覆盖掉原来的,时间短就不确定
[root@node2 lock]# cat lock.py
#!/usr/local/python3/bin/python
import time
import threading
def addNum():
global num
temp=num
time.sleep(0.2)
num =temp-1
num = 100
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list:
t.join()
print('final num:',num)
[root@node2 lock]# python3 lock.py
final num: 99 #99次都覆盖
[root@node2 lock]# python3 lock.py
final num: 99
[root@node2 lock]# python3 lock.py
final num: 99
summary
(1).num-=1没问题,这是因为动作太快
(2).if sleep(1),现象会更明显,100个线程每一个一定都没执行完就进行了切换,相当于造成I/O阻塞,1s内不会切换回来,所以最后的结果一定是99
(3).使用join会把整个线程halt住,造成了串行,失去了多线程意义,只需要把计算(涉及到操作公共数据)时串行
solution: 加锁,现在使用的线程要执行完,再切换(串行)
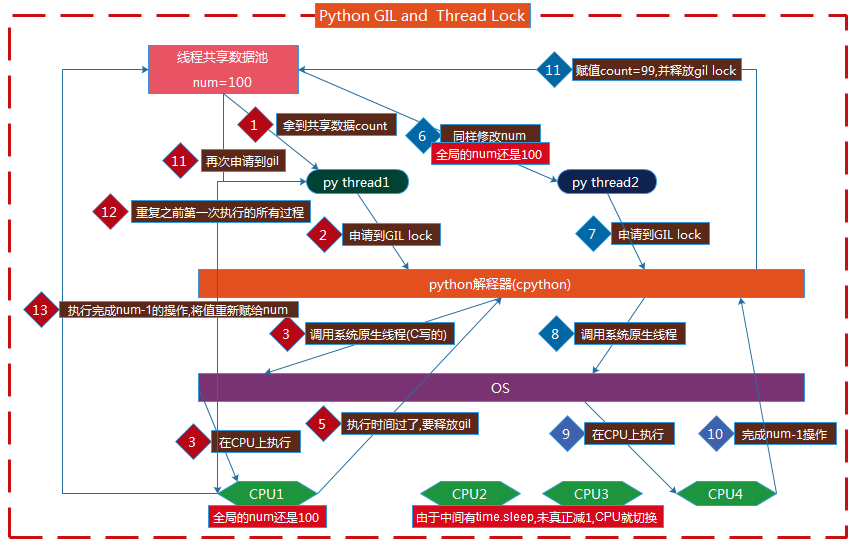
问题:python中已经有GIL,为什么还要自行加锁
分析: 主要是功能不一样,GIL保证同一时刻在解释器中,只有一个线程在工作,对num-=1速度很快的计算操作不影响,但是对于时间长的,由于CPU的切换才导致数据问题,这时自行所加的锁就在此,当某个线程完成工作前不切换
[root@node2 lock]# cat lock.py
#!/usr/local/python3/bin/python
import time
import threading
def addNum():
global num
r.acquire() #请求锁,这里加锁只是计算这部分是串行的,其他的还可以是多线程
temp=num
time.sleep(0.0001)
num =temp-1
r.release() #释放锁
num = 100
thread_list = []
r=threading.Lock() #线程锁
for i in range(100):
t = threading.Thread(target=addNum) ##解决方法是串行的,意义造成意义不大,但是这三行代码上下可能还有其他代码,这时还是有多线程的价值
t.start() ##
thread_list.append(t) ##
for t in thread_list:
t.join()
print('final num:',num)
[root@node2 lock]# python3 lock.py
final num: 0
[root@node2 lock]# python3 lock.py
final num: 0
join解决
[root@node2 lock]# cat lock-join.py
#!/usr/local/python3/bin/python
import time
import threading
def addNum():
global num
temp=num
time.sleep(0.0001)
num =temp-1
num = 100
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
t.join() #####也就是t1.start()后,t2不能start,这时CPU完全是t1的,但是程序就完全是串行的,就没意义
thread_list.append(t)
for t in thread_list:
t.join()
print('final num:',num)
[root@node2 lock]# python3 lock-join.py
final num: 0
3.线程死锁和递归锁
描述:在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所有这两个线程在无外力作用下将一直等待下去,下面是一个死锁的例子:
[root@node2 lock]# cat dead-recursion.py
#!/usr/local/python3/bin/python3
import threading,time
class myThread(threading.Thread):
def doA(self):
lockA.acquire() #A请求锁
print(self.name,"gotlockA",time.ctime())
time.sleep(3)
lockB.acquire() #B请求锁,但是A还没释放,在里面再加一把锁
print(self.name,"gotlockB",time.ctime())
lockB.release() #B锁先释放
lockA.release() #A锁释放
def doB(self): #操作与A相同
lockB.acquire()
print(self.name,"gotlockB",time.ctime())
#当线程1,从上到下走到这时得到lockB,其他线程是可以活动的,因为在doA最后已经释放了,线程2会来竞争,获得doA中的lockA,所以可以打印第一条,这时线程1,2各取得一把锁,当线程1从这向下走时,会请求lockA,但是lockA已经被线程2占用,而且线程2向下走时,也需要lockB,却也是被线程1所占用,造成各不相让,一直halt住,造成死锁
time.sleep(2)
lockA.acquire()
print(self.name,"gotlockA",time.ctime())
lockA.release()
lockB.release()
def run(self): #5个线程同时执行run方法
self.doA()
self.doB()
if __name__=="__main__":
lockA=threading.Lock() #两把锁
lockB=threading.Lock()
threads=[] #空列表
for i in range(5): #5个线程
threads.append(myThread()) #把实例化对象添加到空列表中
for t in threads: #循环取每个对象,第1个t就是第1个对象
t.start() #5个线程同时执行run方法
for t in threads:
t.join()
[root@node2 lock]# python3 dead-recursion.py
Thread-1 gotlockA Sun May 20 14:10:30 2018
Thread-1 gotlockB Sun May 20 14:10:33 2018
Thread-1 gotlockB Sun May 20 14:10:33 2018
Thread-2 gotlockA Sun May 20 14:10:33 2018 停住
死锁的solution:使用递归锁(可重用)
分析:锁要一层层的加,释放也要一层层的释放
问题:donA里,第一次已经请求锁了而且还没释放,为什么第二次还要请求加锁,本身第一次加锁时就只有一个线程在工作
[root@node2 lock]# cat dead-recursion.py
#!/usr/local/python3/bin/python3
import threading,time
class myThread(threading.Thread):
def doA(self):
lock.acquire() ##请求锁时,计时器做一个累加的操作
print(self.name,"gotlockA",time.ctime())
time.sleep(3)
lock.acquire() ##
print(self.name,"gotlockB",time.ctime())
lock.release() ##释放锁时,计时器进行一个递减的操作,所以不产生列锁
lock.release() ##
def doB(self):
lock.acquire() ##
print(self.name,"gotlockB",time.ctime())
time.sleep(2)
lock.acquire() ##
print(self.name,"gotlockA",time.ctime())
lock.release() ##
lock.release() ##
def run(self):
self.doA()
self.doB()
if __name__=="__main__":
lock=threading.RLock() ####内部有一个计时器和一把锁
threads=[]
for i in range(5):
threads.append(myThread())
for t in threads:
t.start()
for t in threads:
t.join()
[root@node2 lock]# python3 dead-recursion.py
Thread-1 gotlockA Sun May 20 15:40:12 2018 ##运行时,是4个的出现,说明thread1执行doA,释放完所有锁到doB的时间要比不同线程进行竞争抢资源快
Thread-1 gotlockB Sun May 20 15:40:15 2018
Thread-1 gotlockB Sun May 20 15:40:15 2018
Thread-1 gotlockA Sun May 20 15:40:17 2018
Thread-3 gotlockA Sun May 20 15:40:17 2018
Thread-3 gotlockB Sun May 20 15:40:20 2018
Thread-3 gotlockB Sun May 20 15:40:20 2018
Thread-3 gotlockA Sun May 20 15:40:22 2018
Thread-5 gotlockA Sun May 20 15:40:22 2018
Thread-5 gotlockB Sun May 20 15:40:25 2018
Thread-5 gotlockB Sun May 20 15:40:25 2018
Thread-5 gotlockA Sun May 20 15:40:27 2018
Thread-4 gotlockA Sun May 20 15:40:27 2018
Thread-4 gotlockB Sun May 20 15:40:30 2018
Thread-4 gotlockB Sun May 20 15:40:30 2018
Thread-4 gotlockA Sun May 20 15:40:32 2018
Thread-2 gotlockA Sun May 20 15:40:32 2018
Thread-2 gotlockB Sun May 20 15:40:35 2018
Thread-2 gotlockB Sun May 20 15:40:35 2018
Thread-2 gotlockA Sun May 20 15:40:37 2018
4.使用重用锁的原因
分析:一个简单的账户存还款,取款,会有这种情况转账户之类的,如果有两用户同时对一个用户进行转账户操作,就可能会产生数据安全问题,同时操作时,两个账户取的原始数都一样,导致最后操作结果有问题
繁琐的solution: 每增加一个方法对同样数据操作就加一把锁
[root@node2 lock]# cat class.py
#!/usr/local/python3/bin/python3
class Account:
def __init__(self,id,money):
self.id=id
self.balance=money
def withdraw(self,num): #取款方法
self.balance-=num
def repay(self,num): #还款方法
self.balance+=num
#def ttt(self): #如另一个线程对这方法,对同样的数据操作,这时要用同样锁对象,这里用,另一个停,这样影响是多个方法就要加多把锁
# r.acquire()
# _from.withdraw(count)
# to.repay(count)
# r.release()
def transfer(_from,to,count): #转账方法
r.acquire() #这里请求一把锁,进行一个取款,和还款的操作,还是不安全,可能还有另一个函数调用这些数据
_from.withdraw(count) #这里加锁只能控制在这个方法中只有一个线程能操作,可能另一个线程在另一个方法也在对同一数据调用
to.repay(count)
r.release()
a1=Account('reid',500)
a2=Account('lin',900)
t1=threading.Thread(target=transfer,args=(a1,a2,100,r))
t2=threading.Thread(target=transfer,args=(a2,a1,200,r))
t1.start()
t2.start()
简单优好的solution: 在类中增加锁
[root@node2 lock]# cat class.py
#!/usr/local/python3/bin/python3
class Account:
def __init__(self,id,money,r):
self.id=id
self.balance=money
def withdraw(self,num):
r.acquire() ##对操作数据本身的方法就加锁
self.balance-=num
r.release() ##
def repay(self,num):
r.acquire() ##
self.balance+=num
r.release() ##
def abc(self,num): #其他需求,同时还有方法对数据进行操作
r.acquire() #自身修改数据时,要请求锁
self.withdraw() #withdraw中还有一个请求锁
self.balance+=num
r.release()
def transfer(_from,to,count,r):
r.acquire()
_from.withdraw(count)
to.repay(count)
r.release()
r.threading.RLock()
a1=Account('reid',500)
a2=Account('lin',900)
t1=threading.Thread(target=transfer,args=(a1,a2,100,r))
t2=threading.Thread(target=transfer,args=(a2,a1,200,r))
t1.start()
t2.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号