
Python攻克之路-编码解码
字符编码
二进制
----> ASCII: 只能存英文和拉丁字符,一个字符占一个字节
----> gb2312: 只能存6700多个中文, 1980
----> gbk1.0: 存了2万多字符, 1995
----> gb18030: 2000, 27000中文
----> unicode: 万国码, 最初utf-32,一个字符占4个字符
utf-16,一个字符占2个字符或2个以上,可以存65535
utf-8,一个可变长的字符,一个英文使用ASCII码来存,一个中文占3个字节
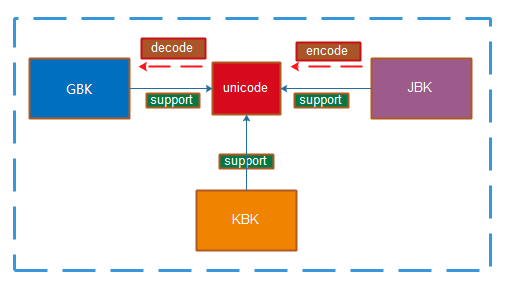
场景分析:例如在国内程序是使用GBK编码,在日本使用JPK编码,假设日本发行的游戏到中国,但是国内的是GBK,但是他们开发时没考虑到会发展到中国,造成GBK是识别不到JPK出现乱码
方案一:在原程序上修改源代码加个中文包来支持,这种是限于重新发版本,旧的就无法实现,如果再到另一个国家也会再次出现这种情况
方案二:在各个编码间找个中间代理,无论是是那个国家的软件,在开发时都默认支持某个语言,就可以实现全部通用,在计算机里,这个中间代理语言是unicode,所以当JPK要与GBK进行沟通,JPK要先转换成unicode,这个转码的过程叫作编码(encode),国内GBK支持JPK,要从unicode转换成GBK
Python2
描述:默认是ASCII码,程序,运行的系统等编码都要保持一致
utf-8 --> unicode --> gbk
# -*- coding:utf-8 -*- #在开端声明使用utf-8
s = '你好'
s_to_unicode = s.decode("utf-8") #要指明原先是什么编码,否则使用Python默认的版本ACSII,这部没到gbk就可以支持中文,utf-8默认就支持中文
unicode_to_gbk = s_to_unicode.encode('gbk') #unicode是向下兼容的
print(s.decode() n)
print(unicode_to_gbk)
注意:
unicode直接encode是节省一个decode的过程,python不会少这个过程,它知道当前的不是unicode的编码,它是不能直接encode,Python先decode,它程序没声明使用什么decode,python就会使用默认的ASCII,所以

gbk_to_unicode = unicode_to_gbk.encode("utf-8") #等于unicode_to_gbk.decode("ascii").encode("utf-8")
因此gbk到utf-8操作要先decode,再encode
gbk_to_unicode = unicode_to_gbk.decode("gbk") ##运行的环境windows是gbk
unicode_to_utf8 = gbk_to_unicode.encode("utf-8")
print(gbk_to_unicode) #中文
print(unicode_to_utf-8) #乱码
Python3
描述:默认是unicode,encode在编码的同时,会把数据转换顾byte类型(不同机器间的文件数据传输需要使用的),只有英文可见decode在解码时,会把bytes类型转换成字符串
b = byte = 字节类型 = [0-255]间纯数字类型
In [1]: s = 'i am 你好'
In [2]: s_to_gbk = s.encode("gbk") #s默认是unicode,所以直接编码
In [3]: print(s)
i am 你好
In [4]: print(s_to_gbk)
b'i am \xc4\xe3\xba\xc3'
In [5]: print(s_to_gbk.decode("gbk")) #转回去了
i am 你好
编码补充
Python3数据类型: string bytes
string: unicode
In [1]: s='hello林'
In [2]: print(type(s))
<class 'str'> 数据类型是str,但是存的是unicode的编码
str --> bytes 是编码
方法一:
bytes: 16进制
描述:无论放在磁盘还是网络传输都是使用Bytes类型,bytes离底层更近
In [3]: s='hello林'
In [4]: bytes(s,'utf8')
Out[4]: b'hello\xe6\x9e\x97'
#16进制的内容,hello不变是因为在ACSII中与utf8是相同的,相当于h对应ACSII的内容,e对应的ACSII对应内容,到了汉字却发生变化了,
utf8规定每个汉字占三个字节,xe6\x9e\x97这三个字节就对应林,这就是utf8规则下的bytes类型
#s是要转的参数,utf8是要转成的类型
#目标是str转成16进制的内容,也就是bytes类型,有utf8的bytes编码类型,有gbk的bytes的编码类型,每个国家都有自身一套编码类型,
它们都是一个规则,有了这个规则utf8就把s转换成16进制,
方法二:
In [5]: s='hello林'
In [6]: s.encode('utf8')
Out[6]: b'hello\xe6\x9e\x97'
bytes ----> string 解码
方法一:
In [10]: b2=s.encode('utf8')
In [11]: str(b2,'utf8')
Out[11]: 'hello林'
方法二:
In [12]: b2=s.encode('utf8')
In [13]: b2.decode('utf8')
Out[13]: 'hello林'
gbk:
In [17]: s='hello林'
In [18]: b2=s.encode('gbk')
In [19]: b2
Out[19]: b'hello\xc1\xd6' ##使用的是两个字节
In [20]: b2.decode('gbk') ##对应上编码的方式
Out[20]: 'hello林'
In [21]: b2.decode('utf8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc1 in position 5: invalid start byte

 浙公网安备 33010602011771号
浙公网安备 33010602011771号