
关于词频统计的效能测试
这里使用的是 Java visualVM:
目前只对不同的输出方式进行了分析,结果如图(测试文件为《战争与和平》):
输出到文件:
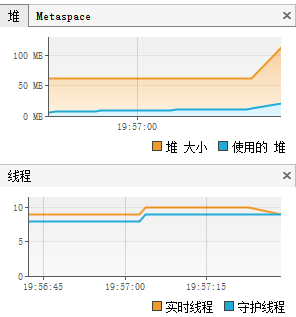
CPU占用率最高仅有0.7%,目前未能得知是什么问题导致的波动这么小,或者是CPU运算能力太强?又或者是算法太好(当作玩笑吧,还没自大的认为自己的算法这么厉害)?
输出到控制台:
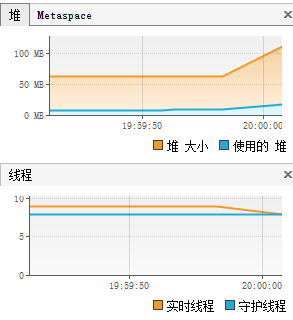
同样的问题,在折线图中CPU占用率波动几乎显示不出来,最高仅有1.1%。
由于统计数据有问题,改用Jprofiler进行统计分析。首先是输出到控制台的方式:
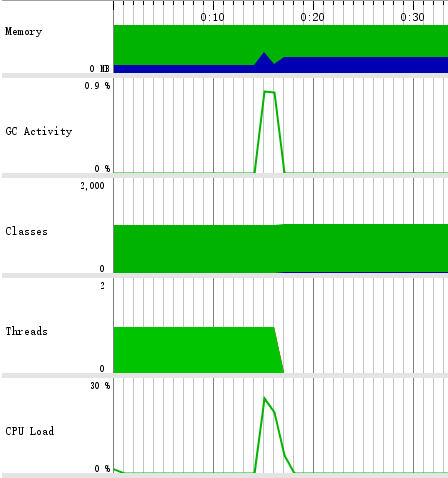
其中CPU占用率达到24.41%,其后再次测试了改动后的输出方式:
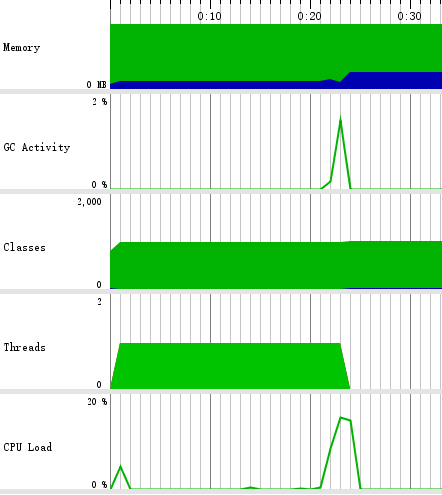
CPU占用率最高只有15.6%,优化了不少。当输出到文件时,运行速率明显提升,因此加入了一项判断:当统计的文件过大时自动将结果输出到文件中。
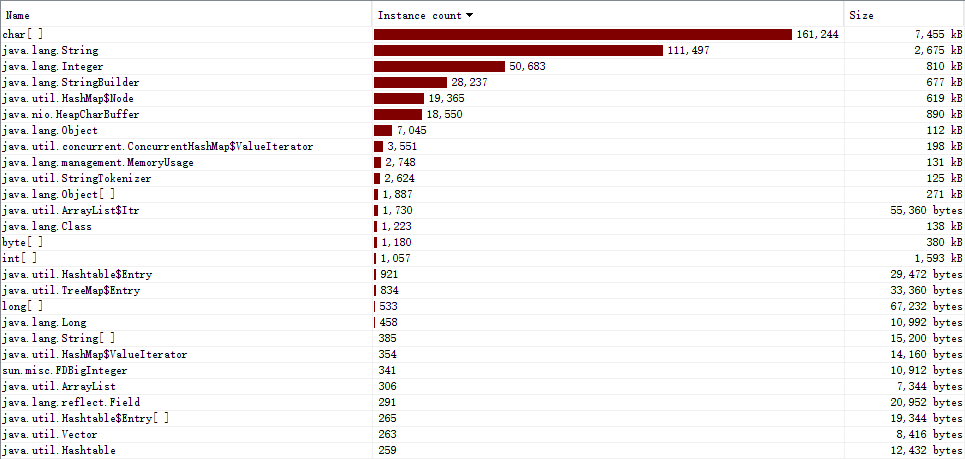
这里因为需要用char[]来接收文件中字符,因此使用次数最多。
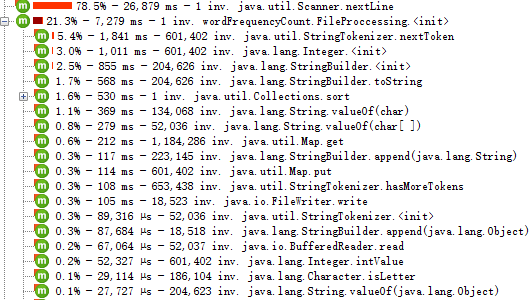
本次采用重定向输入方式,因此scanner.nextline占据了绝大部分,也可以看到其总耗时超过3万毫秒。另外程序中只自定义了一个函数,用来统计词频,因此调用次数只有一次。下面直接用传入文件的方式重新运行一遍,结果如下:
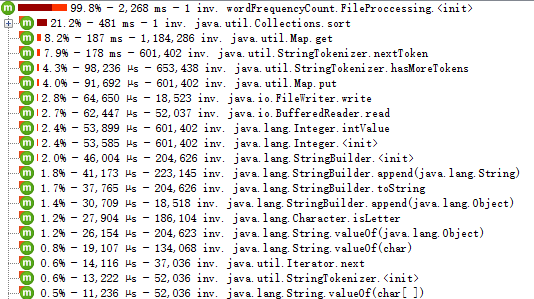
不需要scanner读入文件内容,运行速度明显提高,总耗时不到3000毫秒!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号