
scrapy实战1,基础知识回顾和虚拟环境准备
视频地址
一. 基础知识回顾
1. 正则表达式
1)贪婪匹配,非贪婪匹配
.*? 非贪婪
.* 贪婪模式
2)中括号的三种用法:
1[34578][0-9]{9} 使用"-"表示区间,写多个值表示取任一个值
[^1] 不是1的任意值
[.*] 中括号的值没有特殊含义
3)[\u4E00-\U9FA5] 这个是unicode编码,表示任意汉字
4)\w,\d,"|" 以及\s
\w 表示任意字母数字下划线,等价于[a-zA-Z0-9_] \d 表示任意数字 "|" 表示这个符号两边的数值都可,相当于或 \s 表示任意空白字符
\S, \D, \W取反
2. 深度优先和广度优先
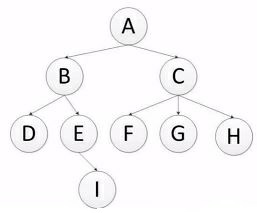
深度优先访问顺序: ABDEICFGH (递归实现)
广度优先访问顺序:ABCDEFGHI (队列实现)
深度优先实现过程
def depth_tree(tree_node): if tree_node is not None: print(tree_node._data) if tree_node._left is not None: return depth_tree(tree_node._left) if tree_node._right is not None: retrun depth_tree(tree_node._right)
广度优先实现过程
def level_queue(root): if root is None: return my_queue = [] node = root my_queue.append(node) while my_queue: node = my_queue.pop(0) print (node.elem) if node.lchild is not None: my_queue.append(node.lchild) if node.rchild is not None: my_queue.append(node.rchild)
3. 爬虫去重策略
1). 将访问过的url保存到数据库,效率低
2). 保存到内存中,比如set,只需要o(1)的代价即可,但是占用内存会越来越高
一亿条URL*2byte*50个字符/1024/1024/1024=9G
3). url经过md5等方法缩减后保存到set中,减少了内存占用,一亿URL只须2-3G, scrapy使用的是这样方法
4). 用bitmap方法,将访问过的url通过hash函数映射到某一位(bit),会有冲突
5). bloomfilter方法对bitmap改进,多重hash函数降低冲突, 一亿的url只须15M左右
4. 字符串编码
1)计算中8个bit作为一个字节,一个字节能表示的最大数字是255,英文比较简单,所以一个字节就能表示所有的字符了,所以有了ASCII(一个字节)是美国人的标准编码
2)但是中文不止255个汉字,所有中国制定了GB2312编码,用两个字节表示一个汉字;同理日文,韩文等也制定了自己的编码规则。
3)如果出现多种语言的混合显示就会出现乱码,所以出现了unicode,将所有语言统一到一套编码中。
4)unicode是用2个字节表示的,如果用unicode编码来表示ASCII编码内容,需要在原基础前面添加8位0,多占用了一倍的空间
5)utf-8:可变长编码,它把英文变为一个字节长度,汉字为3个字节,特别生僻的变成4-6个字节。如果传输大量的英文,utf8的作用就很明显了
6)在编程的时候,内存处理中使用unicode编码来处理会比较简单,因为统一占用2个字节的内容
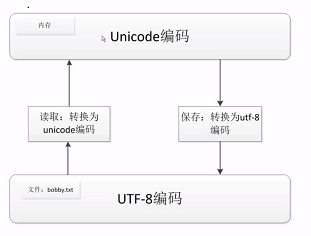
7)python3中,字符编码格式默认为unicode,若想编码为utf-8,如下
s="我用python"
s.encode("utf-8")
二. 虚拟环境准备
1. window下创建虚拟环境
1)进入cmd执行如下命令
pip install virtualenv
pip install virtualenvwrapper-win
python豆瓣源:https://pypi.douban.com/simple/
创建虚拟环境并启动
首先在E盘创建一个virtualenv文件夹,并设置环境变量如下
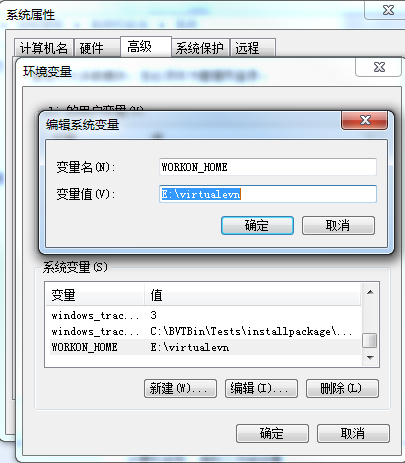
2)退出cmd,重新进入执行如下命令
mkvirtualenv spider,即可创建一个位于E:\virtualenv,名字为spider的虚拟环境
3)安装scrapy并创建项目
在spider虚拟环境中执行:pip install -i https://pypi.douban.com/simple scrapy
退出虚拟环境,然后在D盘创建目录workshop用来存放项目
cd workshop
workon spider #进入虚拟环境
scrapy startproject Article
4)开启pycharm,找到d:workshop导入项目Article
在setting中设置python解释器为d:\virtualenv下的python.exe
在cmd中执行如下命令,不能在pycharm的Terminal中执行
cd Article
scrapy genspider jobbole blog.jobbole.com
注意:
1. 如果安装有多个版本的python,比如想创建python2的虚拟环境,执行如下命令
virtualenv -p 安装路径/python.exe scrapytest
2. 创建项目的时候可能会出现下面错误
1) visual c++ 14 is required
2)UserWarning: You do not have a working installation of the service_identity module: 'cannot import name 'opentype''.
解决方法:
pip install -i https://pypi.douban.com/simple/ service_identity --force --upgrade
2. 创建调试功能
2.1 在scrapy.cfg的同级目录下创建main.py文件
from scrapy.cmdline import execute import sys import os sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(["scrapy", "crawl", "jobbole"])
注意:
1)其中execute中的3个列表元素就是下面cmd命令中scrapy crawl jobbole的字符
2)os.path.abspath(__file__)表示main.py文件,前面加上os.path.dirname()表示main.py的父级目录,也就是当前项目所在目录
在cmd中执行scrapy crawl jobbole,可能会出现一下错误
ImportError: No module named 'win32api'
解决方法:pip install -i https://pypi.douban.com/simple pypiwin32
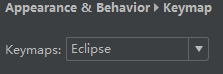
2.2 在setting->appearance->keymap选择keymaps为Eclipse
2.3 在spiders/jobbole.py中添加断点如下,然后debug main.py启动,F6, F8进行调试

努力生活,融于自然

 浙公网安备 33010602011771号
浙公网安备 33010602011771号