北航OO(2020)第一单元博客作业
北航OO(2020)第一单元博客作业
基于度量的程序结构分析
Homework 1
代码度量
| Method | CONTROL | ev(G) | iv(G) | LOC | v(G) |
|---|---|---|---|---|---|
| "Expression.Expression()" | 0 | 1 | 1 | 1 | 1 |
| "Expression.Expression(String)" | 7 | 1 | 8 | 38 | 10 |
| "Expression.computeDerivative()" | 0 | 1 | 1 | 5 | 1 |
| "Expression.toString()" | 1 | 1 | 2 | 7 | 2 |
| "Main.main(String[])" | 0 | 1 | 1 | 5 | 1 |
| "Polynomial.Polynomial()" | 0 | 1 | 1 | 3 | 1 |
| "Polynomial.addTerm(BigInteger,BigInteger)" | 2 | 2 | 2 | 11 | 3 |
| "Polynomial.computeDerivative()" | 3 | 3 | 2 | 12 | 3 |
| "Polynomial.termToString(Entry<BigInteger, BigInteger>)" | 6 | 2 | 7 | 34 | 7 |
| "Polynomial.toString()" | 3 | 2 | 3 | 16 | 4 |
| Class | CSA | CSO | LOC | OCavg | WMC |
|---|---|---|---|---|---|
| "Constants" | 9 | 12 | 14 | n/a | 0 |
| "Expression" | 1 | 16 | 54 | 3.00 | 12 |
| "Main" | 0 | 13 | 7 | 1.00 | 1 |
| "Polynomial" | 1 | 17 | 79 | 3.60 | 18 |
UML类图
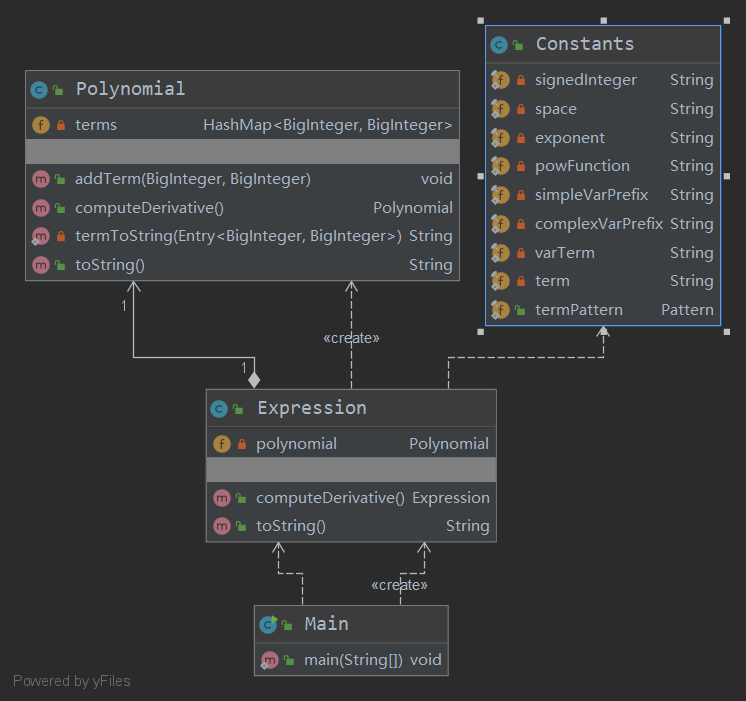
优缺点分析
本次作业要求较为简单,因此我的架构较为清晰。方法的最大长度仅为38行,类的最大长度也只有79行,复杂度整体可控。
但是,我将解析输入与Expression类的构造方法合并,增加了耦合度。从量化分析中也可看出,这一做法显著增加了Expression类及其构造方法的复杂度。此外,我还错误地预判了未来的扩展方向,架构的可扩展性也出现了偏差。
Homework 2
代码度量
| Method | CONTROL | ev(G) | iv(G) | LOC | v(G) |
|---|---|---|---|---|---|
| "Expression.Expression()" | 0 | 1 | 1 | 3 | 1 |
| "Expression.addTerm(Term,BigInteger)" | 2 | 2 | 2 | 11 | 3 |
| "Expression.computeDerivative()" | 4 | 4 | 3 | 14 | 4 |
| "Expression.equals(Object)" | 2 | 3 | 2 | 11 | 4 |
| "Expression.getRandomTerm()" | 0 | 1 | 1 | 4 | 1 |
| "Expression.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "Expression.isOneTerm()" | 0 | 1 | 1 | 3 | 1 |
| "Expression.termEntryToString(Entry<Term, BigInteger>)" | 5 | 2 | 6 | 30 | 6 |
| "Expression.toString()" | 4 | 2 | 4 | 19 | 5 |
| "FactorType.FactorType(FunctionType,Expression)" | 0 | 1 | 1 | 4 | 1 |
| "FactorType.deriveEmbedded()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.deriveType()" | 6 | 2 | 2 | 14 | 4 |
| "FactorType.equals(Object)" | 2 | 3 | 3 | 12 | 5 |
| "FactorType.getEmbeddedExpression()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.getFunctionType()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "FactorType.toString()" | 8 | 8 | 2 | 25 | 8 |
| "Main.main(String[])" | 1 | 1 | 2 | 12 | 2 |
| "Pair.Pair(T1,T2)" | 0 | 1 | 1 | 4 | 1 |
| "Pair.getFirst()" | 0 | 1 | 1 | 3 | 1 |
| "Pair.getSecond()" | 0 | 1 | 1 | 3 | 1 |
| "Parser.parseExpression(String)" | 5 | 2 | 3 | 23 | 6 |
| "Parser.parseTerm(String)" | 6 | 4 | 6 | 29 | 8 |
| "Term.Term()" | 0 | 1 | 1 | 3 | 1 |
| "Term.addFactor(FactorType,BigInteger)" | 2 | 2 | 2 | 13 | 3 |
| "Term.computeDerivative()" | 6 | 1 | 9 | 36 | 9 |
| "Term.equals(Object)" | 2 | 3 | 2 | 11 | 4 |
| "Term.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "Term.toString()" | 3 | 2 | 3 | 17 | 4 |
| "WrongFormatException.WrongFormatException(String)" | 0 | 1 | 1 | 3 | 1 |
| Class | CSA | CSO | LOC | OCavg | WMC |
|---|---|---|---|---|---|
| "Constants" | 21 | 12 | 34 | n/a | 0 |
| "Expression" | 1 | 21 | 123 | 2.78 | 25 |
| "FactorType" | 2 | 20 | 72 | 2.50 | 20 |
| "FunctionType" | 6 | 27 | 3 | n/a | 0 |
| "Main" | 0 | 13 | 14 | 1.00 | 1 |
| "Pair" | 2 | 15 | 14 | 1.00 | 3 |
| "Parser" | 0 | 14 | 54 | 6.50 | 13 |
| "Term" | 1 | 18 | 87 | 3.17 | 19 |
| "WrongFormatException" | 6 | 44 | 5 | 1.00 | 1 |
UML类图
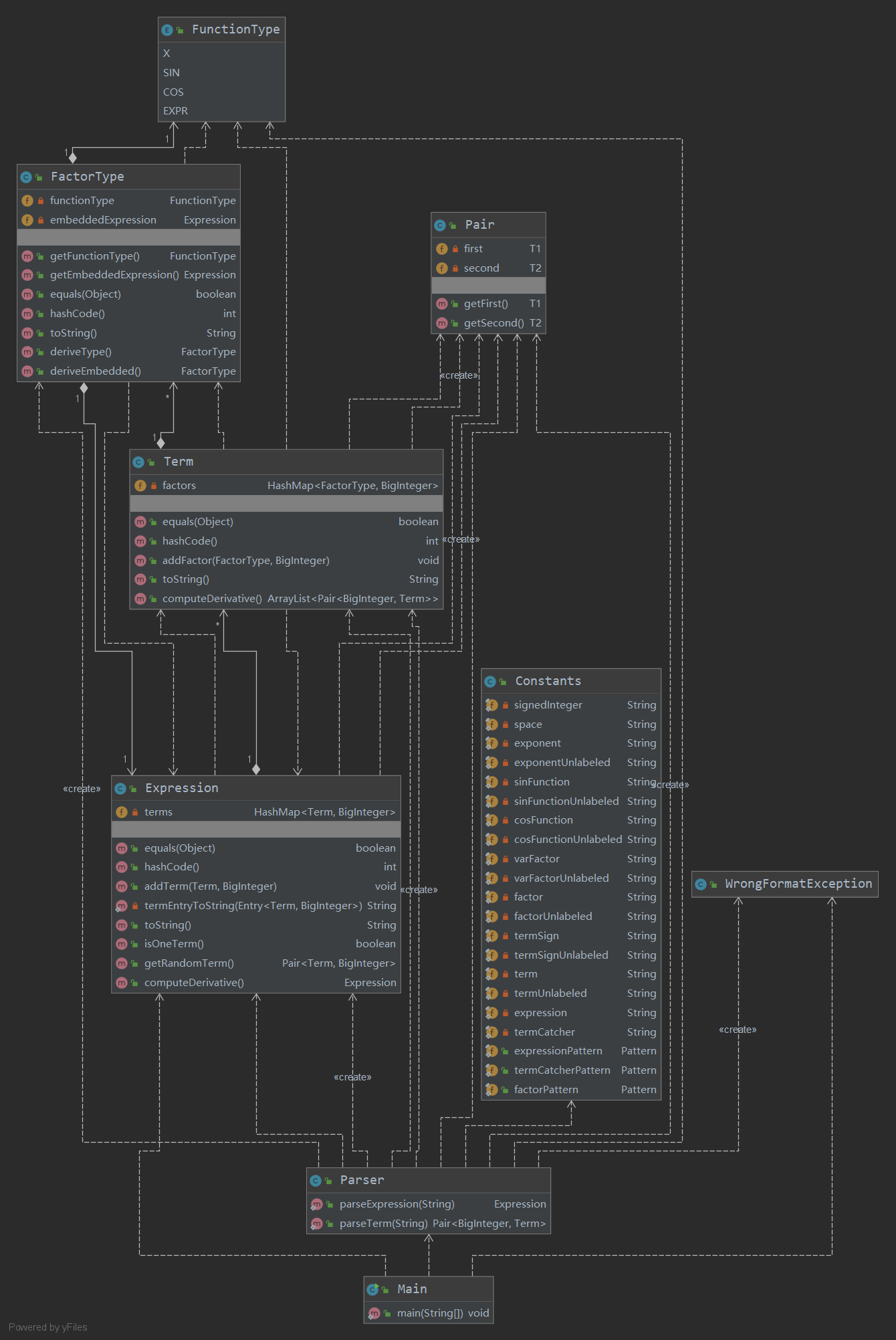
优缺点分析
在本次作业中,我按照求导规则进行建模,分加法、乘法以及将来可能出现的嵌套三级,分别由Expression、Term以及FactorType类进行管理。这些类分别实现了toString()方法以及求导方法。
本次作业复杂度依旧可控,但我对上次的架构进行了重构,并为下次作业留出了大量扩展空间,这使得程序的结构变得相对复杂很多。然而,由于我对下次作业的扩展方向有了比较正确的预判,我的第三次作业的整体架构几乎没有做出任何改动。这一点可以从UML类图中看出,没有增添新的类,各个类的属性和方法也没有大的变动。此外,从度量中也可以看出,方法的长度依旧可控,最大长度甚至低于第一次作业。
但一些方法,如Term.computeDerivative()方法的复杂度和耦合度都较高,它依赖于FactorType类中的每个具体类型执行不同的求导操作,这方面可以进一步改进,如让FactorType类执行这些操作等。
Homework 3
代码度量
| Method | CONTROL | ev(G) | iv(G) | LOC | v(G) |
|---|---|---|---|---|---|
| "Expression.Expression()" | 0 | 1 | 1 | 3 | 1 |
| "Expression.addTerm(Term,BigInteger)" | 2 | 2 | 2 | 11 | 3 |
| "Expression.computeDerivative()" | 4 | 4 | 3 | 13 | 4 |
| "Expression.equals(Object)" | 2 | 3 | 2 | 11 | 4 |
| "Expression.getRandomTerm()" | 0 | 1 | 1 | 4 | 1 |
| "Expression.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "Expression.isOneTerm()" | 0 | 1 | 1 | 3 | 1 |
| "Expression.isSimpleFactor()" | 3 | 4 | 3 | 15 | 4 |
| "Expression.isZero()" | 0 | 1 | 1 | 3 | 1 |
| "Expression.termEntryToString(Entry<Term, BigInteger>)" | 5 | 2 | 6 | 30 | 6 |
| "Expression.toString()" | 4 | 2 | 4 | 22 | 5 |
| "FactorType.FactorType(FunctionType,Expression)" | 0 | 1 | 1 | 4 | 1 |
| "FactorType.deriveEmbedded()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.deriveType()" | 6 | 2 | 2 | 14 | 4 |
| "FactorType.equals(Object)" | 2 | 3 | 3 | 12 | 5 |
| "FactorType.getEmbeddedExpression()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.getFunctionType()" | 0 | 1 | 1 | 3 | 1 |
| "FactorType.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "FactorType.toString()" | 9 | 9 | 5 | 30 | 10 |
| "Main.main(String[])" | 1 | 1 | 2 | 12 | 2 |
| "Pair.Pair(T1,T2)" | 0 | 1 | 1 | 4 | 1 |
| "Pair.getFirst()" | 0 | 1 | 1 | 3 | 1 |
| "Pair.getSecond()" | 0 | 1 | 1 | 3 | 1 |
| "Parser.parseExpression(String)" | 9 | 6 | 6 | 41 | 11 |
| "Parser.parseTerm(String)" | 13 | 8 | 10 | 56 | 14 |
| "Parser.preProcess(String)" | 7 | 4 | 7 | 25 | 9 |
| "Term.Term()" | 0 | 1 | 1 | 3 | 1 |
| "Term.addFactor(FactorType,BigInteger)" | 2 | 2 | 2 | 13 | 3 |
| "Term.computeDerivative()" | 7 | 1 | 9 | 38 | 9 |
| "Term.equals(Object)" | 2 | 3 | 2 | 11 | 4 |
| "Term.getFactors()" | 0 | 1 | 1 | 3 | 1 |
| "Term.hashCode()" | 0 | 1 | 1 | 4 | 1 |
| "Term.isEmpty()" | 0 | 1 | 1 | 3 | 1 |
| "Term.isSimpleFactor()" | 4 | 5 | 2 | 14 | 5 |
| "Term.toString()" | 5 | 2 | 5 | 25 | 6 |
| "WrongFormatException.WrongFormatException(String)" | 0 | 1 | 1 | 3 | 1 |
| Class | CSA | CSO | LOC | OCavg | WMC |
|---|---|---|---|---|---|
| "Constants" | 22 | 12 | 36 | n/a | 0 |
| "Expression" | 1 | 23 | 122 | 2.73 | 30 |
| "FactorType" | 2 | 20 | 77 | 2.62 | 21 |
| "FunctionType" | 6 | 27 | 3 | n/a | 0 |
| "Main" | 0 | 13 | 14 | 1.00 | 1 |
| "Pair" | 2 | 15 | 14 | 1.00 | 3 |
| "Parser" | 0 | 15 | 124 | 10.67 | 32 |
| "Term" | 1 | 21 | 117 | 3.22 | 29 |
| "WrongFormatException" | 6 | 44 | 5 | 1.00 | 1 |
UML类图
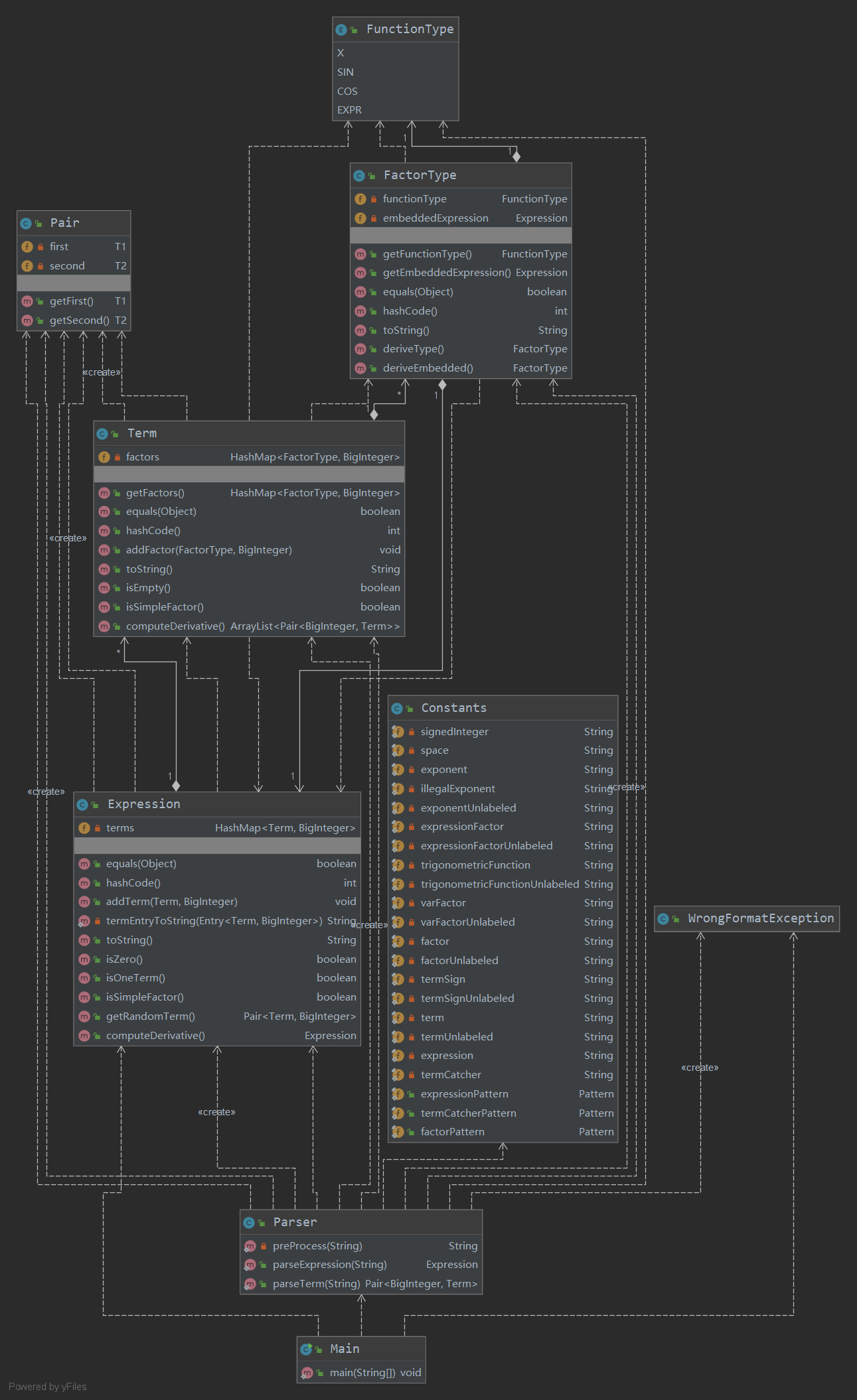
复杂度分析
本次作业的复杂度较前两次有了跃升,主要是因为嵌套规则的出现,使得表达式出现了递归组合的可能。然而,得益于上次良好的架构设计,本次我只对Parser和Constants类做出了比较大的修改。
但是,从度量中可以看出,Parser.parseExpression(String)方法和Parser.parseTerm(String)方法已经变得十分复杂,还可进一步解耦,例如将针对不同因子的判断从中移出,采用其他方法或机制完成。
Bug分析
本单元作业中,我由于对Wrong Format判断不全,在Homework 3的强测中痛失两点。不过,由于程序整体架构尚可,在互测中无任何bug被发现。
Homework 3中的bug发生在Parser类中的parseExpression(String)方法中,由于我对于正则表达式的匹配机制理解不深,忽视了括号中的通配符会将潜在的Wrong Format匹配其中导致整个表达式匹配成功的问题,最终导致了bug的出现。例如sin(x)+++x+cos(x),就会按照sin(.*)进行匹配,而不会失败。
Hack策略分析
由于时间、精力和能力所限,本次的Hack策略仅仅局限在提交手动构造的测试用例以及提交曾经在自己的程序上测出问题的测试用例上,也并未仔细阅读他人代码。当然,效果也十分一般,每次平均只能Hack成功一两个人。
对象创建模式应用分析
在进行表达式的解析时,可以利用工厂模式构建不同的因子。可以为X、SIN、COS、EXPR分别建立因子类,并用统一的因子接口进行管理,用统一的因子工厂进行构造。这样将可以大大简化Parser.parseTerm(String)等方法。
设计问题分析与心得体会
本次作业的设计中存在的问题主要有:
- 对于抽象层次与设计模式的运用不够,主要依赖类的组合和条件判断来解决问题;
- 一些类与方法之间的耦合度较高,修改困难;
- 一些方法过于冗长且内聚性不够。
通过本单元的学习和作业练习,我初步了解了面向对象程序设计的一些基本的思想和方法,并迭代开发了一个最终代码在500行量级的Java面向对象程序。通过3次的迭代开发,我充分认识到了良好的架构和可扩展性的重要性。在庞大的工程面前,规范化以及高内聚低耦合的设计对于迭代开发的顺利进行至关重要。
此外,同学之间的讨论与交流也对于我的开发有着极大的启发和引领作用。尤其是讨论区的一些帖子,能够帮助我迅速找到架构设计的方向、明确处理的细节问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号