![image]()
import fitz # PyMuPDF
import pandas as pd
# 打开PDF文件
pdf_path = '控制之美.pdf' # 请确保替换为正确的文件路径
document = fitz.open(pdf_path)
# 初始化一个列表来存储目录信息
toc_list = []
# 提取目录信息的函数
def extract_toc(toc, level=0):
for item in toc:
# 确保目录项至少包含标题
if len(item) > 1 and item[1]:
title = item[1]
# 确保页码是数字类型
page = item[2] if len(item) > 2 and isinstance(item[2], int) else None
if page is not None:
# 添加条目到列表
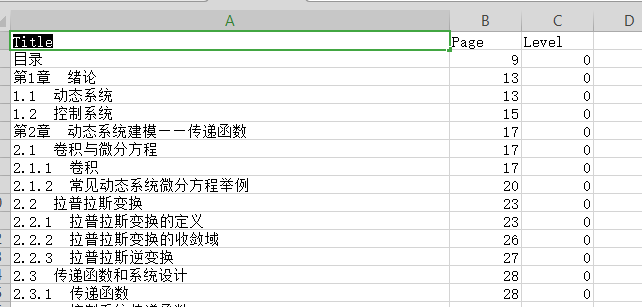
toc_list.append({
'Title': title,
'Page': page,
'Level': level
})
# 如果有子条目,递归提取
if len(item) > 3 and item[3]: # 子条目在索引3
extract_toc(item[3], level + 1)
# 获取PDF的目录
toc = document.get_toc(simple=False)
# 提取目录信息
extract_toc(toc)
# 关闭PDF文件
document.close()
# 将列表转换为DataFrame
toc_df = pd.DataFrame(toc_list)
# 将DataFrame输出到CSV文件
toc_df.to_csv('output.csv', index=False, encoding='utf-8')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号