python学习笔记(二)
目录:
一、集合
1.去重
2.关系测试
二、文件操作
1.读写模式
2.文件常用操作
3.文件的修改
4.with语句
三、字符编码与转码
四、函数与函数式编程
1.函数与过程的区别
2.使用函数的好处
3.函数返回值
4.参数
5.局部变量与全局变量
6.递归
7.函数式变成与函数的不同
8.高阶函数
一、集合
1.去重
去重是集合的特性之一,当我们把一个列表(里面有相同的元素)变成集合后,相同的元素就自动变成了一个。
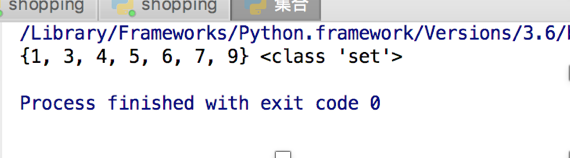
list_1 = [1,4,5,7,3,6,7,9] list_1 = set(list_1)
print(list_1,type(list_1))
打印结果:
2.关系测试:
list_1 = [1,4,5,7,3,6,7,9] list_1 = set(list_1) list_2= set([2,6,0,66,22,8,4]) list_3 = set([1,3,7]) print(list_1,list_2) ''' print(list_1.intersection(list_2)) #取交集 print(list_1.union(list_2)) #取并集 print(list_1.difference(list_2)) #取差集(1有的2没有的) print(list_1.issubset(list_2)) #判断子集,返回False print(list_1.issuperset(list_2))#判断父级 print(list_3.issubset(list_1))#返回True print(list_1.symmetric_difference(list_2)) #对称(反向)差集,把交集的去掉,留下对方都没有的 print('--------------------') list_4 = set([5,6,8]) print(list_3.isdisjoint(list_4)) #没有交集返回True,有交集返回False ''' #运算符 print(list_1 & list_2) #交集 print(list_1 | list_2) #并集 print(list_1 - list_2) #差集 print(list_1 ^ list_2) #对称差集 list_1.add(999) #添加 list_1.update([888,777,555]) print(list_1) list_1 print(list_1.pop()) #随机删除,并返回删除的值 print(list_1.discard('ddd')) #如果删除的元素在集合内,删除元素,不在的话返回None
打印结果:

二、文件操作
1.读写模式
f = open("yesterday",'w',encoding = 'utf-8') #文件句柄 w模式是创建一个文件,所以原来的文件就没了,覆盖之前的 f = open("yesterday2",'r',encoding = 'utf-8') #a代表append,往后追加写入,不覆盖原来的文件 f = open("yesterday2",'r+',encoding = 'utf-8') #读写,可读可写。若文件不存在,报错。写会覆盖原文件 f = open("yesterday2",'w+',encoding = 'utf-8') #写读,可读可写,若文件不存在,创建 f = open("yesterday2",'a+',encoding = 'utf-8') #追加读写,可读可写,不会覆盖原文件 f = open("yesterday2",'rb',encoding = 'utf-8') #以二进制文件来读写
2.文件常用操作
#data = f.read() #读取文件 #data2 = f.read() #print(data) #print('--------------data2--------------',data2) #data2没有打印内容,因为data1指针从开头读到结尾,指针留在结尾,因此data2的指针在最后一行,无法读到内容 #f.write("\nwhen i was young i listen to the radio\n") #for i in range(5): #读取前五行 # print(f.readline()) #print(f.readlines()) #变成列表,每行一个元素 #效率低下的读取方法 '''for index,line in enumerate(f.readlines()): #逐行打印,f.readlines()只适合读小文件,因为存储在内存里 if index == 9: #在第九行打印分割线 print("------我是分割线--------------") continue print(line.strip()) # strip把空格和换行都去掉 ''' #高效率读取方法 '''count = 0 for line in f: #一行行的读,并且内存里只保存1行,效率最高 if count == 9: #在第九行插入分割线 print('--------我是分割线------------') count += 1 continue print(line) count += 1 ''' ''' print(f.tell()) #把文件指针位置打印出来 print(f.read(5)) #只读5个 print(f.readline()) print(f.readline()) print(f.readline()) print(f.tell()) f.seek(0) #指针回到0位置 print(f.readline()) print(f.encoding) #打印文件编码 print(f.fileno()) #返回内存句柄在IO接口的编号,我们读文件是从接口里读的。 print(f.name) #打印文件名字 print(f.readable())#判断文件是否可读,writeable判断文件是否可写 f.flush()# 一般我们写完一行就默认存到硬盘上去了,但我们不一定存在了硬盘上,如果此时突然间断电,/ # 有可能这行没写进去。因为这一行现在还在缓存中。硬盘读取速度慢,如果每写一次都要读一次硬盘,整个程序容易卡住。/ #所以就暂时存在缓存里,只要写入大小达到了值,就往硬盘上存一次。 #flush方法用于强制把内存中的东西刷到硬盘上去 #在终端里可运行 ''' #f.truncate(10) #截断,从文件开始往后留10个字符,后面删掉 f.close() #删除文件 '''
3.文件的修改
f = open("yesterday2","r",encoding='utf-8') f_new = open("yesterday2.bak","w",encoding='utf-8') for line in f: if "肆意的快乐等我享受" in line: line = line.replace("肆意的快乐等我享受","肆意的快乐等Alex享受") f_new.write(line) f.close() f_new.close()
4.with语句
为避免打开文件后忘记关闭,可通过管理上下文,即with实现:
with open("yesterday2","r",encoding="utf-8") as f: for line in f: print(line)
注意:按照编程规范,一行代码不超过80个字符,如果出现打开多个文件,需要换行操作:
with open("yesterday2","r",encoding="utf-8") as f,\ open("yesterday2","r",encoding = "utf-8") as f2: for line in f: print(line)
三、字符转码与编码
详细文章:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.diveintopython3.net/strings.html
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
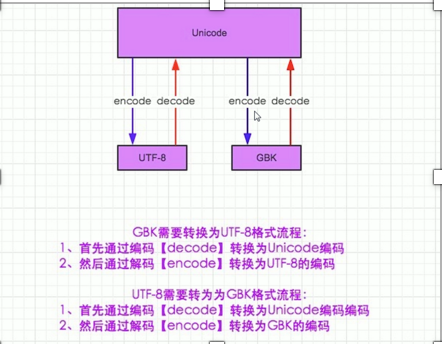
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
#-*- coding:gbk -*- __Author__ = 'Redleafage Zhang' s = "你好" s_gbk= s.encode("gbk") print(s_gbk) print(s.encode()) gbk_to_utf8 = s_gbk.decode("gbk").encode("utf-8") print("utf8",gbk_to_utf8)
打印结果:

四、函数与函数式编程
1.函数与过程的区别
函数:有返回值
过程:无返回值
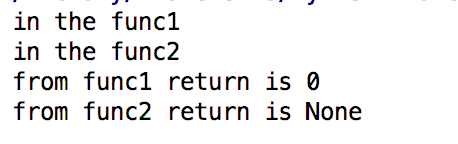
def func1(): #函数 "testing" print("in the func1") return 0 def func2(): #过程 "testing2" print("in the func2") x=func1() y=func2() print('from func1 return is %s' %x) print('from func2 return is %s' %y)
打印结果:
2.使用函数的好处
1.代码重用
2.保持一致性
3.可扩展性
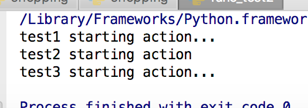
import time def logger(): time_format = '%Y-%m-%d %X' #X代表小时分钟秒 time_current = time.strftime(time_format) #引用上面的时间格式来显示时间 with open('a.txt','a+') as f: f.write('%s end action\n' % time_current) def test1(): print('test1 starting action...') logger() def test2(): print('test2 starting action' ) logger() def test3(): print('test3 starting action...') logger() test1() test2() test3()
打印结果:
文本保存内容:

3.函数返回值
def test1(): print('in the test1') return 0 #遇到返回值就终止当前函数运行 print('test end') #不运行 def test2(): print('in the test2') return 0 def test3(): print('in the test3') return 1,'hello',['alex','wupeiqi'],{'name':'alex'} #都能返回,返回成一个元祖 x=test1() y=test2() z=test3() print(x) print(y) print(z)
打印结果:

4.参数
a.形参与实参
def test(x,y): #positional arguments 形参 print(x) print(y) x=1 y=2 test(x=x,y=y) #等号左边为形参传递参数,右边为实参
打印结果:

b.默认参数
默认参数的特点:调用函数的时候,默认参数非必须传递
def test(x,y=2): print(x) print(y) test(1) #赋值给x,y是默认的
打印结果

__Author__ = 'Redleafage Zhang' #*args:接受N个位置参数,转换成元祖形式 def test(*args): #参数组,有*就行,后面名称随意 print(args) test(1,2,3) #结果放到一个元祖里面 test(*[1,2,4,5,5]) # args = tuple([1,2,3,4,5]) def test1(x,*args): print(x) print(args) test1(1,2,3,4,5,6,7) def test2(**kwargs): #接受N个关键字参数,把N个关键字参数转换成字典的方式 print(kwargs) print(kwargs['name']) print(kwargs['age']) print(kwargs['sex']) test2(name='alex',age = 8,sex = 'F') test2(**{'name':'alex','age':8,'sex':'F'}) def test3(name,**kwargs): print(name) print(kwargs) test3('alex',age = 18 ,sex = 'm') def test4(name,age=18,*args,**kwargs): #参数组往后放,前面的参数不能放参数组后面 print(name) print(age) print(args) print(kwargs) logger('TEST4') def logger(source): print("from %s" % source) test4('alex',age=34,sex='m',hobby='tesla') #age不会赋值给参数组,即使放在后面 #age后出现的直接是关键字参数,*args无法接受,直接变空
打印结果

5.局部变量与全局变量
在子程序中定义的变量称为局部变量,在程序一开始定义的变量称为全局变量。
全局变量的作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
程序从上到下执行,logger在被定义之前执行会报错

school = "Oldboy edu." #全局变量,哪个函数都可以访问 names = ["Alex","jack","Rain"] def change_name(): print(names) names[0] = "金角大王" #只有字符串和单独的整数是不能在函数里去改的,列表、字典、集合、类都可以在局部里直接改全局 print("inside func",names) change_name() print(names) # def change_name(): # global name # name = 'alex' # # change_name() # print(name) # def change_name(name): # global school #我要在函数里去改全局变量 # school = "Mage Linux" # print("before change",name,school) #打印局部变量都school # name = "Alex li" #这个函数就是这个变量的作用域,这个变量只在这个函数里生效 # age = 23 # print("after change",name) # # # name = "alex" # change_name(name) # print(name) # #print('age',age) #会报错,因为age是change_name函数的局部变量 # print("school",school) #打印结果还是全局变量

注意:永远不要在函数里修改或创建全局变量,因为函数总是被调用,你无法知道在哪次函数调用中被修改,无法调试
6.递归
递归特性:
1.必须有一个明确的结束条件
2.每次进入更深一层递归时,问题规模比上次递归都应有所减少。
3.递归效率不高,递归层次过多导致栈溢出(在计算机中,函数调用是通过栈(stack))这种数据结构实现的,每当进入一次函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层
栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出
4.python允许调用递归最大层数为999
def calc(n): print(n) if int(n/2) > 0: return calc(int(n/2)) print("-->",n) calc(10)
打印结果:

7.函数与函数式编程的不同

8.高阶函数
变量可以指向函数,函数的参数能接受变量,那么一个函数就可以接受另一个函数作为参数,这种函数就称之为高阶函数。
def add(a,b,f): return f(a)+f(b) res=add(3,-6,abs) #abs为绝对值函数 print(res) #打印结果为9

 浙公网安备 33010602011771号
浙公网安备 33010602011771号