
编码总结
1. 基础概念
1.1 字节
字节(Byte)是计算机中存储数据的单元,一个字节等于一个8位的比特,计算机中的所有数据,不论是磁盘文件上的还是网络上传输的数据(文字、图片、视频、音频文件)都是由字节组成的。
1.2 字符
你正在阅读的这篇文章就是由很多个字符(Character)构成的,字符一个信息单位,它是各种文字和符号的统称,比如一个英文字母是一个字符,一个汉字是一个字符,一个标点符号也是一个字符。
1.3 字符集
字符集(Character Set)就是某个范围内字符的集合,不同的字符集规定了字符的个数,比如 ASCII 字符集总共有128个字符,包含了英文字母、阿拉伯数字、标点符号和控制符。而 GB2312 字符集定义了7445个字符,包含了绝大部分汉字字符。常见的字符集有:ASCII及其扩展字符集,GB2312字符集,GBK字符集,UNICODE字符集等
1.4 字符码
字符码(Code Point)指的是字符集中每个字符的数字编号,例如 ASCII 字符集用 0-127 这连续的128个数字分别表示128个字符,"A" 的编号就是65。
1.5 字符编码
字符编码(Character Encoding)是将字符集中的字符码映射为字节流的一种具体实现方案,常见的字符编码有 ASCII 编码、UTF-8 编码、GBK 编码等。某种意义上来说,字符集与字符编码有种对应关系,例如 ASCII 字符集对应 有 ASCII 编码。ASCII 字符编码规定使用单字节中低位的7个比特去编码所有的字符。例如"A" 的编号是65,用单字节表示就是0×41,因此写入存储设备的时候就是b'01000001'。
1.6 编码、解码
编码的过程是将字符转换成字节流,解码的过程是将字节流解析为字符。
理解了这些基本的术语概念后,我们就可以开始讨论计算机的字符编码的演进过程了。
2. ASCII、Unicode和UTF-8的关系
2.1 ASCII(字符集)
我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
最开始ASCII只定义了128个字符编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
2.2 Unicode(字符集)
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,全世界有上百种语言,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,他涵盖了全球所有的文字和二进制的对应关系,每个符号的编码都不一样,这样就不会再有乱码问题了。
Unicode规定如何编码,解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。例如:利用unicode表示“Python”需要12个字节才能表示,比原来ASCII表示增加了1倍。
由于计算机的内存比较大,并且字符串在内容中表示时也不会特别大,所以内容可以使用unicode来处理,但是存储和网络传输时一般数据都会非常多,那么增加1倍将是无法容忍的!!!为了解决存储和网络传输的问题,出现了UTF,我们最常用的就是UTF-8编码。
Unicode编码有不同的实现方式,比如在传输和保存的过程中,“汉”字的Unicode编码是6C49,我可以用4个ascii数字来传输、保存这个编码;也可以用utf-8编码的3个连续的字节E6 B1 89来表示它。只要通信双方都要预定好,正确解析即可。
2.3 UTF-8
UTF 是为unicode编码 设计 的一种 在存储 和传输时节省空间的编码方案。其中UTF-8(Unicode Transformation Format)广泛应用于互联网,它是一种变长的字符编码,可以根据具体情况用1-4个字节来表示一个字符。比如英文字符这些原本就可以用ASCII码表示的字符用UTF-8表示时就只需要一个字节的空间,和ASCII是一样的。
1、如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
2、对于多字节(n个字节)的字符,第一个字节的前n为都设为1,第n+1位设为0,后面字节的前两位都设为10。剩下的二进制位全部用该字符的unicode码填充。
以汉字“好”为例,“好”对应的Unicode是597D,对应的区间是0000 0800--0000 FFFF,因此它用UTF-8表示时需要用3个字节来存储,597D用二进制表示是: 0101100101111101,填充到1110xxxx 10xxxxxx 10xxxxxx得到11100101 10100101 10111101,转换成16进制:e5a5bd,因此“好”的Unicode"597D"对应的UTF-8编码是"E5A5BD"
中文 好
unicode 0101 100101 111101
编码规则 1110xxxx 10xxxxxx 10xxxxxx
--------------------------
utf-8 11100101 10100101 10111101
--------------------------
16进制utf-8 e 5 a 5 b d
3. 计算机系统中的编码
无论以什么编码在内存里显示字符,存到硬盘上都是2进制。
ascii编码(美国):
l 0b1101100
o 0b1101111
v 0b1110110
e 0b1100101
GBK编码(中国):
老 0b11000000 0b11001111
男 0b11000100 0b11010000
孩 0b10111010 0b10100010
Shift_JIS编码(日本):
私 0b10001110 0b10000100
は 0b10000010 0b11001101
ks_c_5601-1987编码(韩国):
나 0b10110011 0b10101010
는 0b10110100 0b11000010
TIS-620编码(泰国):
ฉัน 0b10101001 0b11010001 0b10111001
...
要注意的是,存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读,要不然就乱了。
虽然有了unicode and utf-8 , 但是由于历史问题,各个国家依然在大量使用自己的编码,比如中国的windows,默认编码依然是gbk,而不是utf-8。
基于此,如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有gbk编码。若想让中国的软件可以正常的在 美国人的电脑上显示,只有以下2条路可走:
- 1、让美国人的电脑上都装上gbk编码
- 2、把你的软件编码以utf-8编码
但是这也是有问题
- 1、全世界有几百上千种编码,显然不可能专门为中国安装gbk,第一条方案行不通
- 2、所有软件都以utf-8编码,由于很多软件已经开发出来了,重新编码会花费巨大的精力。
但这并不是没有解决方案,试想一个中国人和一个韩国人沟通,两个人并不会对方的语言,但是两个人都会英语,那么这就简单了,直接用英语沟通就可以了。其实上面已经提到过了unicode字符集,这个字符集所有国家的电脑都能认识,假设中国使用gbk,美国人使用utf-8,只要当我们的代码从硬盘读到内存中的时候,使用正确的解码方式(比如GBK)读取数据,然后将数据转换成unicode存入内存,处理完之后,再使用正确的编码方式(比如utf-8),显示在浏览器上,这样中文就可以正常展示了。
不论是Python3x、Java还是其他编程语言,Unicode编码都成为语言的默认编码格式,而数据最后保存到介质中的时候,不同的介质可有用不同的方式,有些人喜欢用UTF-8,有些人喜欢用GBK,这都无所谓,只要平台统一的编码规范,具体怎么实现并不关心。
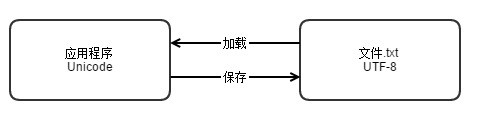
4. python2.x中的编码
注意:以下内容只限于python2.x
4.1 python的解析
Python的诞生时间比Unicode要早很多,Python的默认编码是ASCII
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
所以在Python源代码文件中如果不显示地指定编码的话,将出现语法错误
#test.py
print "学习编码"
运行后会报错
$ python test.py
File "test.py", line 1
SyntaxError: Non-ASCII character '\xe5' in file test.py on line 1, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
为了在源代码中支持非ASCII字符,必须在源文件的第一行或者第二行显示地指定编码格式:
#!/usr/bin/python
# -*- coding: utf-8 -*-
有了上面的配置,当Python解释器读取源代码文件时,会按UTF-8编码读取,我们保存文件的时候也要按照utf-8的格式保存,utf-8是保存和读取的中间桥梁,只有双方遵守这个规则,才能正确的读取和写入。现在的IDE一般会有选项设置保存文件的编码类型,改变声明后同时换成声明的编码保存,但文本编辑器控们需要小心。
4.2 python2.x中字符串
首先我们要理解字符和字节的区别,字符是用来显示的,而字节是存储和传输时使用,网络传输的是字节流,文件存储的也是字节流,而编辑器要显示文件内容,就需要转化为字符来显示,字符和字节之间的关系可以定义如下
encode(字符, 编码方案) -> 字节
decode(字节, 编码方案) -> 字符
可见encode和decode是一对逆向操作,它们都需要指定编码方案,如果编码方案不一致,则会操作失败。
在Python里有两种类型的字符串类型:字节字符串(str)和unicode的字符串,一个字节字符串就是unicode经过编码后的字节组成的序列,有可能是 ascii, gbk, utf-8 等等中的任意一种,str中到底是用的哪一种编码,取决于它所在的场景,跟 locale ,文件编码等有关系。
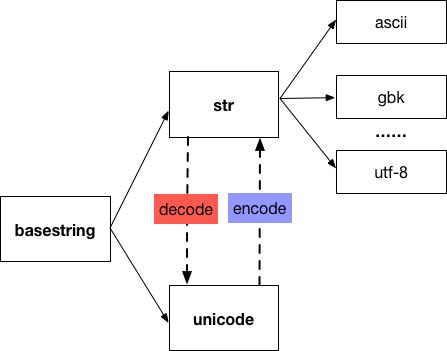
str和unicode都是basestring的子类。unicode可以通过对字节串str使用正确的字符编码进行解码后获得,str也可以通过对unicode的编码得到。
代码
# coding: UTF-8
s = '好'
u = u'好'
print repr(s)
print repr(u)
print s
print u
print repr(s.decode('UTF-8'))
print s == u
print s.decode('UTF-8') == u
结果
'\xe5\xa5\xbd'
u'\u597d'
好
好
u'\u597d'
False
True
文件存储为utf8格式,输出规范的十六进制和ASCII码。
$ hexdump -C test.py
00000000 23 20 63 6f 64 69 6e 67 3a 20 55 54 46 2d 38 0a |# coding: UTF-8.|
00000010 0a 73 20 3d 20 27 e5 a5 bd 27 0a 75 20 3d 20 75 |.s = '...'.u = u|
00000020 27 e5 a5 bd 27 0a 0a 70 72 69 6e 74 20 72 65 70 |'...'..print rep|
00000030 72 28 73 29 0a 70 72 69 6e 74 20 72 65 70 72 28 |r(s).print repr(|
00000040 75 29 0a 70 72 69 6e 74 20 73 0a 70 72 69 6e 74 |u).print s.print|
00000050 20 75 0a 70 72 69 6e 74 20 72 65 70 72 28 73 2e | u.print repr(s.|
00000060 64 65 63 6f 64 65 28 27 55 54 46 2d 38 27 29 29 |decode('UTF-8'))|
00000070 0a 0a 70 72 69 6e 74 20 73 20 3d 3d 20 75 0a 70 |..print s == u.p|
00000080 72 69 6e 74 20 73 2e 64 65 63 6f 64 65 28 27 55 |rint s.decode('U|
00000090 54 46 2d 38 27 29 20 3d 3d 20 75 0a |TF-8') == u.|
0000009c
分析:
- 1、首先文件的存储是字节流,观察上面的第二行和第三行,对照ascii表
第一段:
73 20 3d 20 27 e5 a5 bd 27
分别对照解释
73->s, 20->空格,3d->等号,20->空格,27->单引号,`e5 a5 bd`->中文`好`,27->单引号
所以上面是 s = '好'
第二段:
75 20 3d 20 75 27 e5 a5 bd 27
分别对照解释
73->s, 20->空格,3d->等号,20->空格,75->u, 27->单引号,`e5 a5 bd`->中文`好`,27->单引号
所以上面是 s = '好'
文件保存的时候是utf编码的字节流,我们读取的时候按照utf-8编码读取是可以正确解析的。
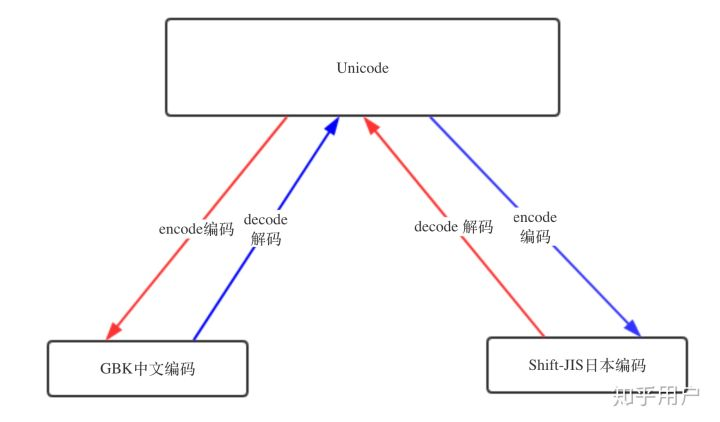
- 2、python2的默认编码是ASCII,想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器以文件头声明的编码去解释你的代码,但是加载到内存后,并不会主动帮你将str字节串转为unicode,也就是说,你的文件编码是utf-8,str字节串加载到内存里仍然为utf-8。Python2并不会自动的把文件编码转为unicode存在内存里,需要你自己人肉转。但是python3自动把文件编码转为unicode必定是调用了什么方法,这个方法就是,decode(解码) 和encode(编码)
UTF-8 --> decode 解码 --> Unicode
Unicode --> encode 编码 --> GBK / UTF-8 ..
- 3、上面的s,实际上是一个16进制(\xe5\xa5\xbd)表示的二进制字节(11100101 10100101 10111101),这样做的目的是可读性更强,这就是字节类型。u的16进制(\u597d)对应的二进制是(0101 100101 111101),两者都读入到内存中,显然是不同的。如果按照
s.decode('UTF-8')对s进行解码得到了unicode,两个对应的二进制相同了,所以返回True。
4.3 如何识别编码
chardet是一个非常优秀的编码识别模块,通过pip 安装:
pip install chardet
使用:
复制代码
>>> from chardet import detect
>>> a = "中文"
>>> detect(a)
{'confidence': 0.682639754276994, 'encoding': 'KOI8-R'}
4.4 读写文件
内置的open()方法打开文件时,read()读取的是str,读取后需要使用正确的编码格式进行decode()。write()写入时,如果参数是unicode,则需要使用你希望写入的编码进行encode(),如果是其他编码格式的str,则需要先用该str的编码进行decode(),转成unicode后再使用写入的编码进行encode()。如果直接将unicode作为参数传入write()方法,Python将先使用源代码文件声明的字符编码进行编码然后写入。
# coding: UTF-8
f = open('test.txt')
s = f.read()
f.close()
print type(s) # <type 'str'>
# 已知是GBK编码,解码成unicode
u = s.decode('GBK')
f = open('test.txt', 'w')
# 编码成UTF-8编码的str
s = u.encode('UTF-8')
f.write(s)
f.close()
另外,模块codecs提供了一个open()方法,可以指定一个编码打开文件,使用这个方法打开的文件读取返回的将是unicode。写入时,如果参数是unicode,则使用open()时指定的编码进行编码后写入;如果是str,则先根据源代码文件声明的字符编码,解码成unicode后再进行前述操作。相对内置的open()来说,这个方法比较不容易在编码上出现问题。
# coding: GBK
import codecs
f = codecs.open('test.txt', encoding='UTF-8')
u = f.read()
f.close()
print type(u) # <type 'unicode'>
f = codecs.open('test.txt', 'a', encoding='UTF-8')
# 写入unicode
f.write(u)
# 写入str,自动进行解码编码操作
# GBK编码的str
s = '汉'
print repr(s) # '\xba\xba'
# 这里会先将GBK编码的str解码为unicode再编码为UTF-8写入
f.write(s)
f.close()
5. 应用
在计算机内存中,统一使用Unicode编码(万国编码),当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
下面介绍一些例子
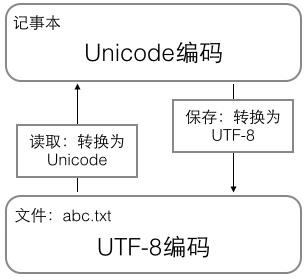
5.1 记事本
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
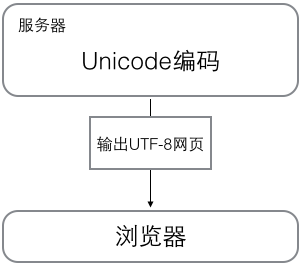
5.2 浏览网页
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
5.3 vim编辑器
Vim 有四个跟字符编码方式有关的选项,encoding、fileencoding、fileencodings、termencoding ,它们的意义如下:
-
encoding: Vim 内部使用的字符编码方式,包括 Vim 的 buffer (缓冲区)、菜单文本、消息文本等。你可以用另外一种编码来编辑和保存文件,如你的vim的encoding为utf-8,所编辑的文件采用cp936编码,vim会自动将读入的文件转成utf-8(vim的能读懂的方式),而当你写入文件时,又会自动转回成cp936(文件的保存编码).
-
fileencoding: Vim 中当前编辑的文件的字符编码方式,Vim 保存文件时也会将文件保存为这种字符编码方式 (不管是否新文件都如此)。
-
fileencodings: Vim自动探测fileencoding的顺序列表, 启动时会按照它所列出的字符编码方式逐一探测即将打开的文件的字符编码方式,并且将 fileencoding 设置为最终探测到的字符编码方式。因此最好将Unicode 编码方式放到这个列表的最前面,将拉丁语系编码方式 latin1 放到最后面。
-
termencoding: Vim 所工作的终端 (或者 Windows 的 Console 窗口) 的字符编码方式。如果vim所在的term与vim编码相同,则无需设置。
我们来看看 Vim的多字符编码方式支持是如何工作的。
-
1、Vim 启动,根据 .vimrc 中设置的 encoding 的值来设置 buffer、菜单文本、消息文的字符编码方式。
-
2、读取需要编辑的文件,根据 fileencodings 中列出的字符编码方式逐一探测该文件编码方式。并设置 fileencoding 为探测到的,看起来是正确的 (注1) 字符编码方式。
-
3、对比 fileencoding 和 encoding 的值,若不同则调用 iconv 将文件内容转换为encoding 所描述的字符编码方式,并且把转换后的内容放到为此文件开辟的 buffer 里,此时我们就可以开始编辑这个文件了。
-
4、编辑完成后保存文件时,再次对比 fileencoding 和 encoding 的值。若不同,再次调用 iconv 将即将保存的 buffer 中的文本转换为 fileencoding 所描述的字符编码方式,并保存到指定的文件中。建议 encoding 的值设置为utf-8。
.vimrc文件参考配置如下:
:set encoding=utf-8
:set fileencodings=utf-8,gbk,big5,cp936,gb18030,gb2312,utf-16
:set fileencoding=utf-8
:set termencoding=utf-8
以上配置,先尝试用utf-8进行解码,如果用utf-8解码到了一半出错(所谓出错的意思是某个地方无法用utf-8正确地解码),那么就从头来用gbk重新尝试解码,如果gbk又出错(注意gbk并不是像utf-8似的规则编码,所以所谓的出错只是说某个编码没有对应的有意义的字,比如0),就尝试用big5,仍然出错就尝试用cp936。这一趟下来,如果中间的某次解码从头到尾都没有出错,那么 vim就认为这个文件是这个编码的,不会再进行后面的尝试了。
参考资料
https://www.cnblogs.com/freewater/archive/2011/08/26/2154602.html
https://blog.csdn.net/jq_ak47/article/details/51769841
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
http://www.cnblogs.com/fnng/p/5008884.html
https://liguangming.com/how-to-use-utf-8-with-python
https://segmentfault.com/a/1190000004625718
https://www.cnblogs.com/huxi/archive/2010/12/05/1897271.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号