
机器学习基础2--评价回归模型
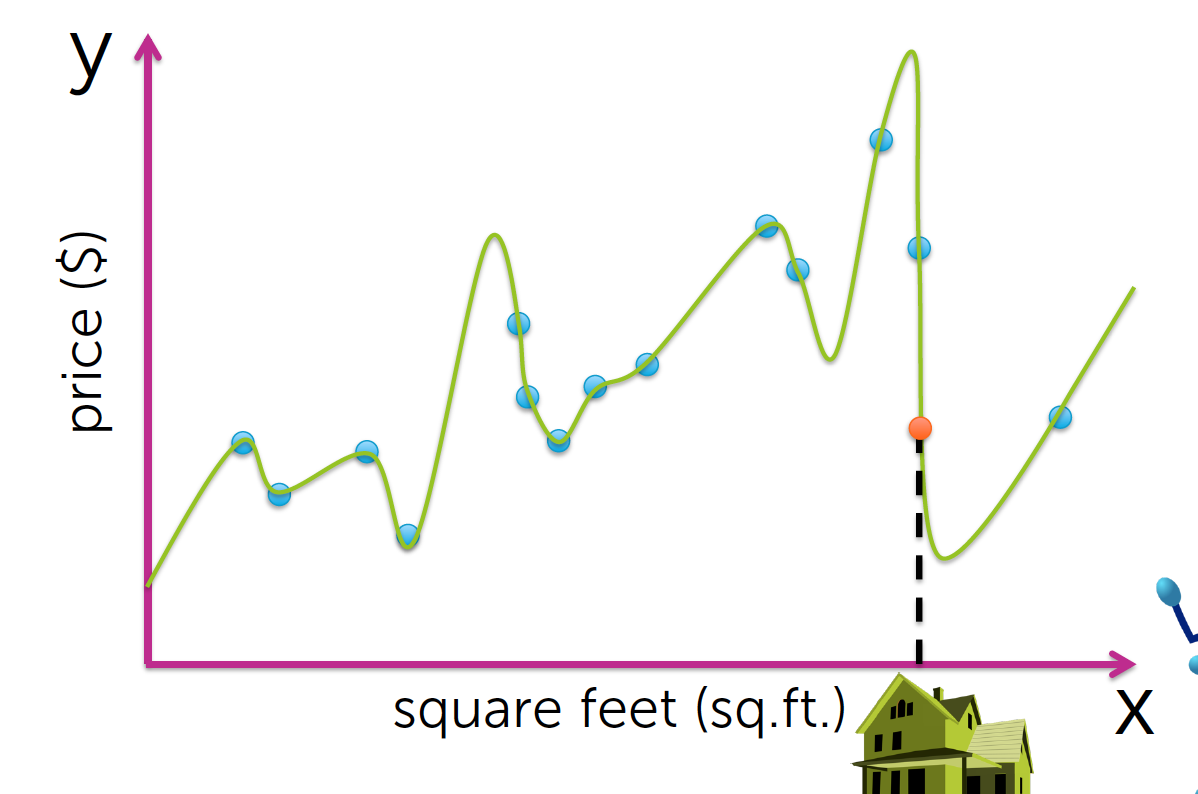
再次回到上一节的13次模型.
这个疯狂的曲线造成了一种现象过拟合.
很明显,你的房子不可能只值这么点价钱,所以看上去,这个13次模型甚至还不如一开始的二次模型.
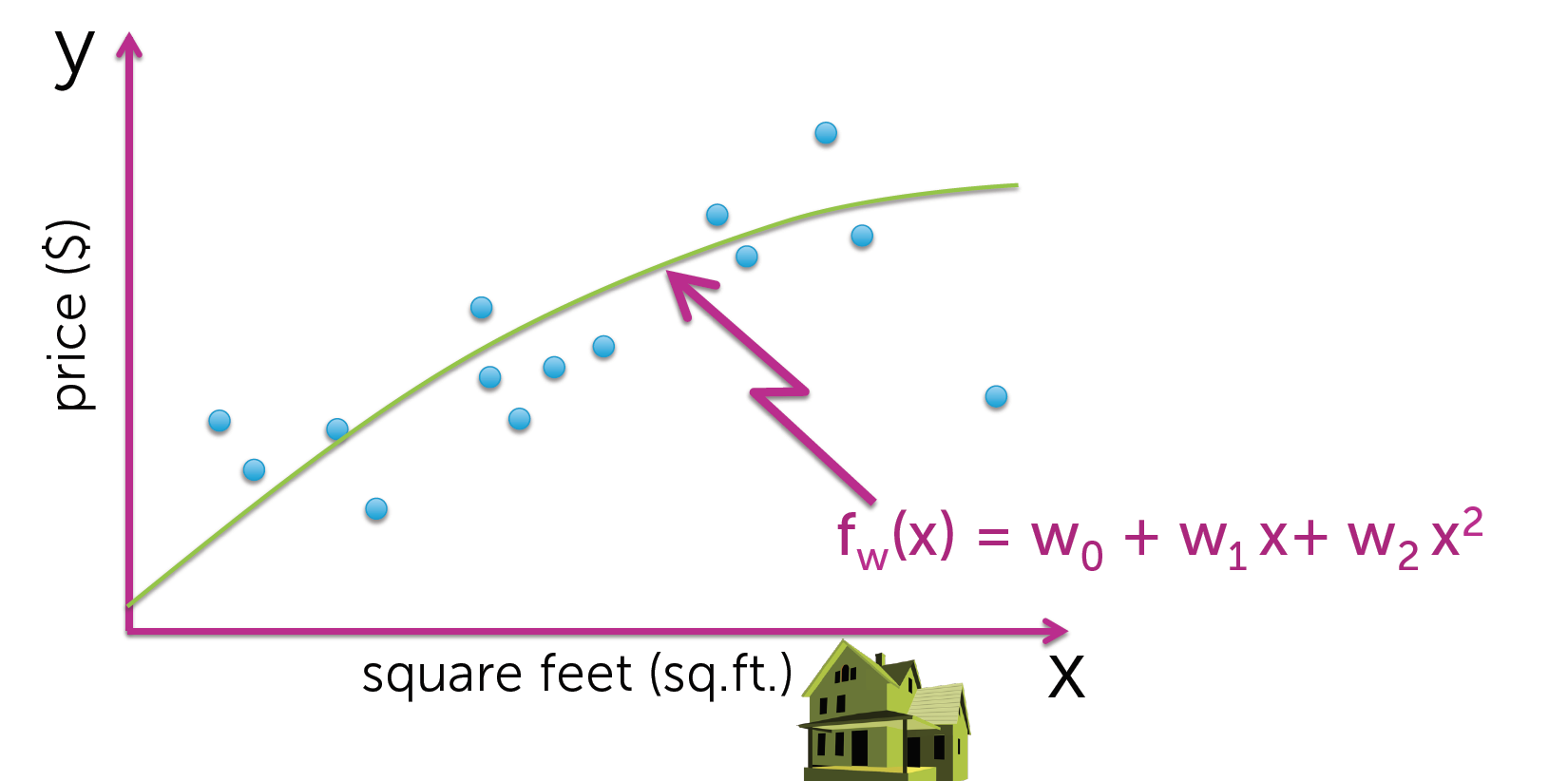
那么现在有个疑问,我们应该怎样去选择最合适的模型?
我们想要准确预测,但是我们无法观测未来.
下面我们模拟一次预测过程:
1.我们随机将一些房子数据排除在外.
2.然后拟合剩下的数据
3.最后进行预测和推断.
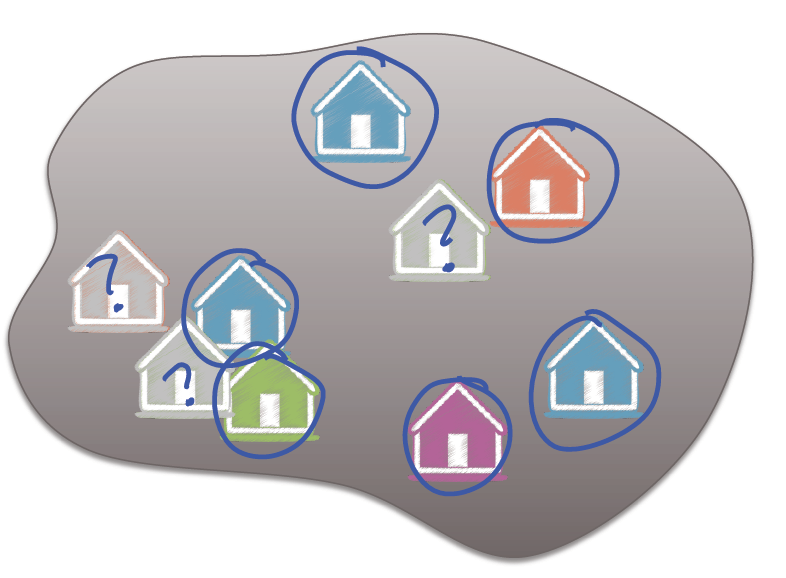
术语:
训练集(training set):用来拟合模型的数据.
测试集(test set):排除出去的数据.
训练损失(training error):训练集上的损失,就是训练集上的残差平方和.

测试损失(test error):测试集上的损失,就是测试集上的残差平方和.
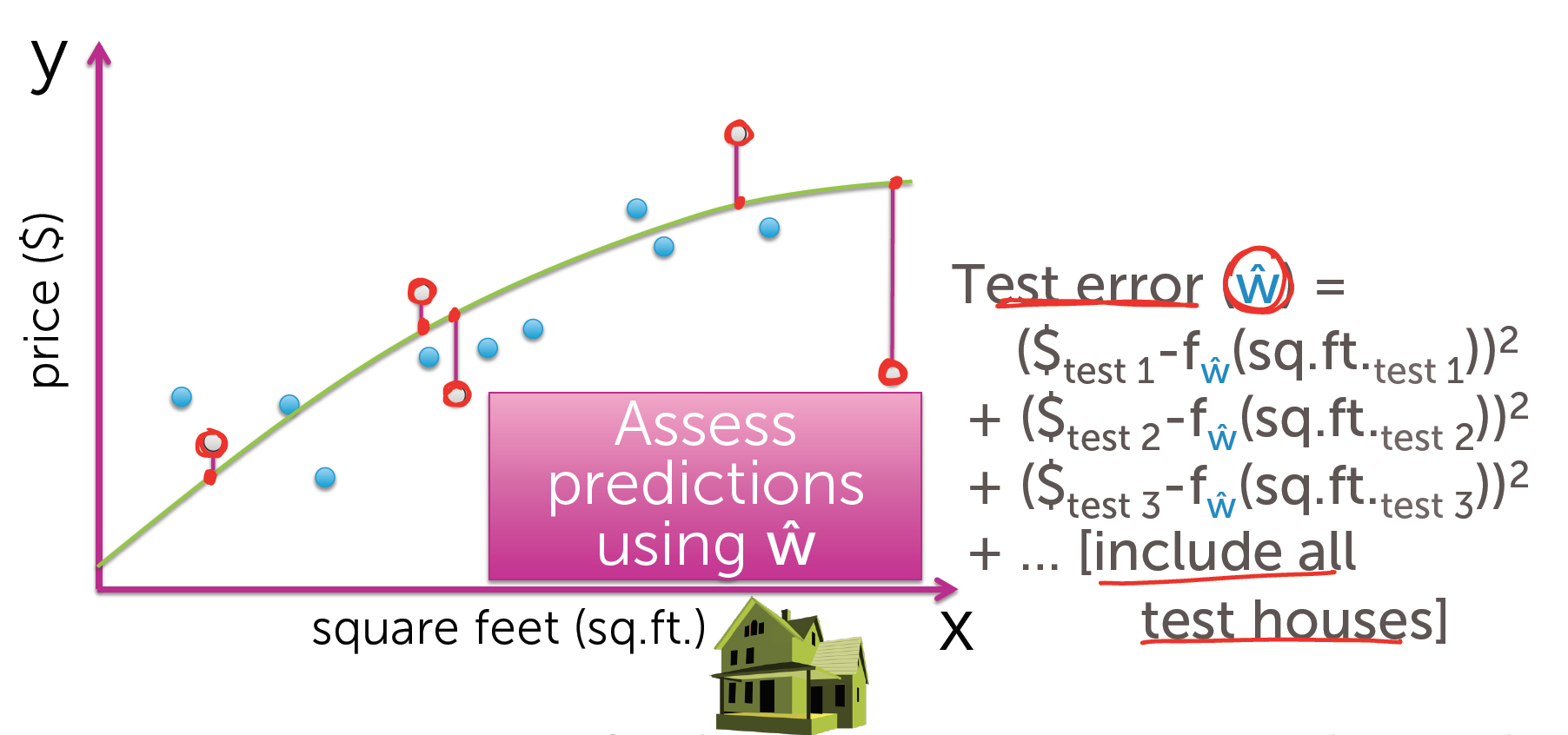
那么这两个ŵ会起到什么作用?
我们以模型(线性模型,二次模型...十三次模型等)为X轴,损失为Y轴,绘制一个二维坐标系.
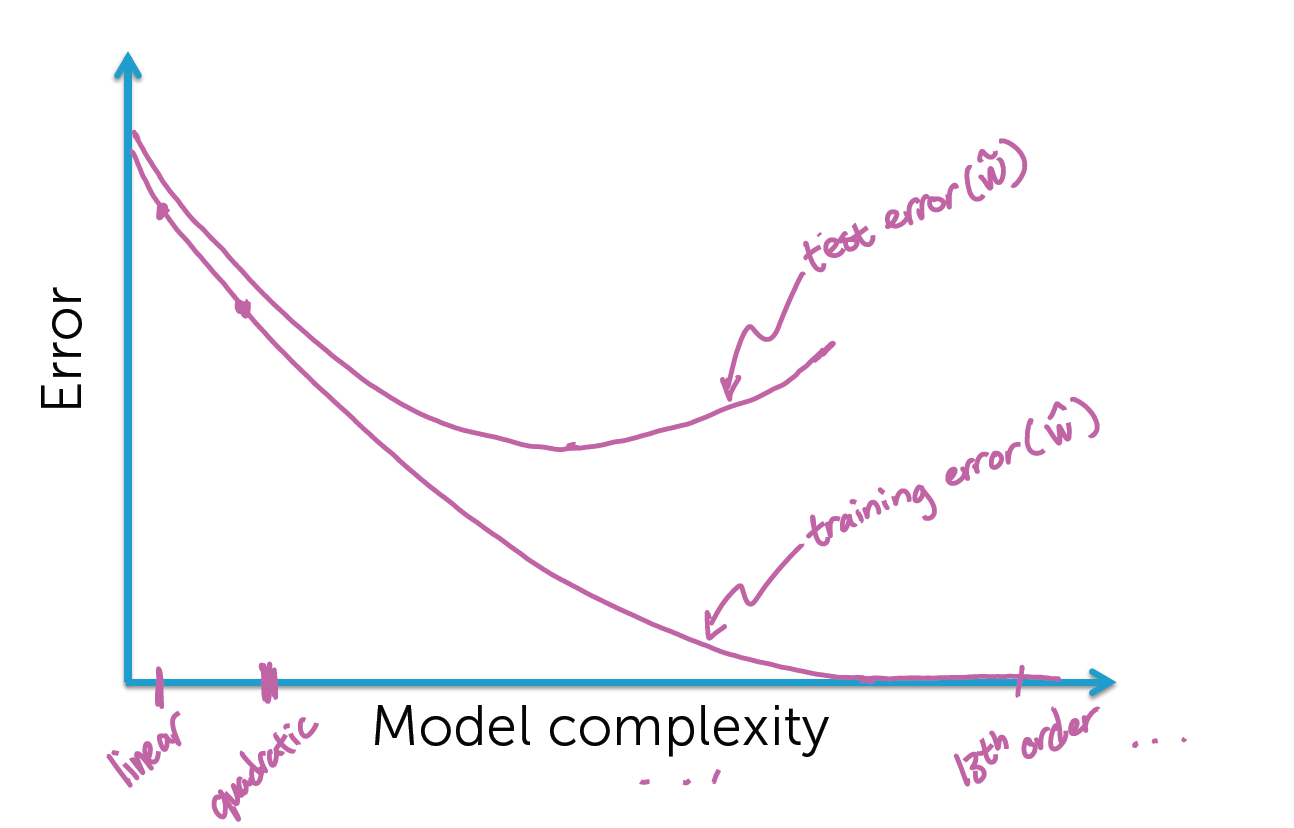
训练损失在不断降低的同时,测试损失竟然在某个点开始升高了!
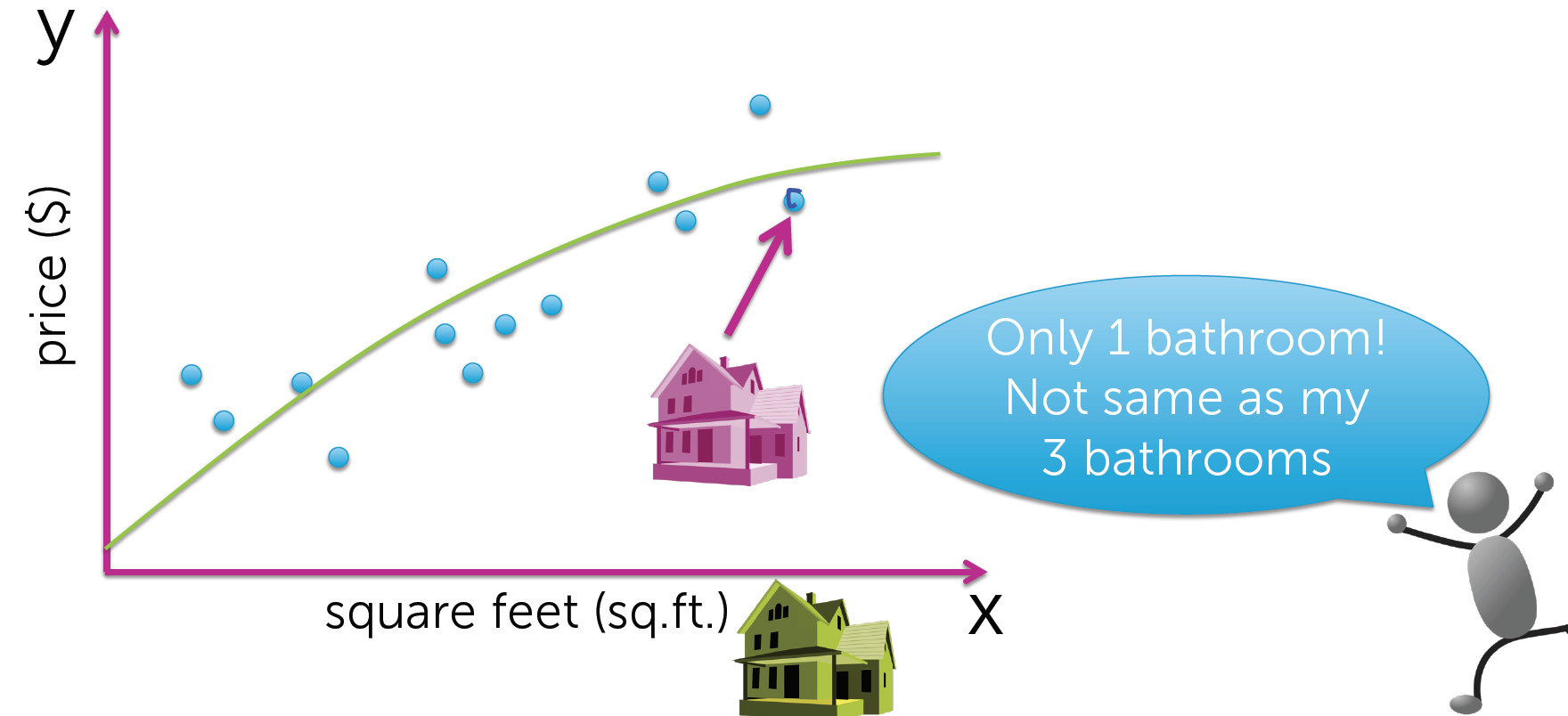
在这个点找到了一个和你房子大小相近的房子,你准备以此为参照.
但是你发现,这个房子只有一个卫生间,而你的房子是有3个的.
很明显,这个房子无法作为参照使用.
那么,我们把卫生间作为另一个特征,加入线性模型.
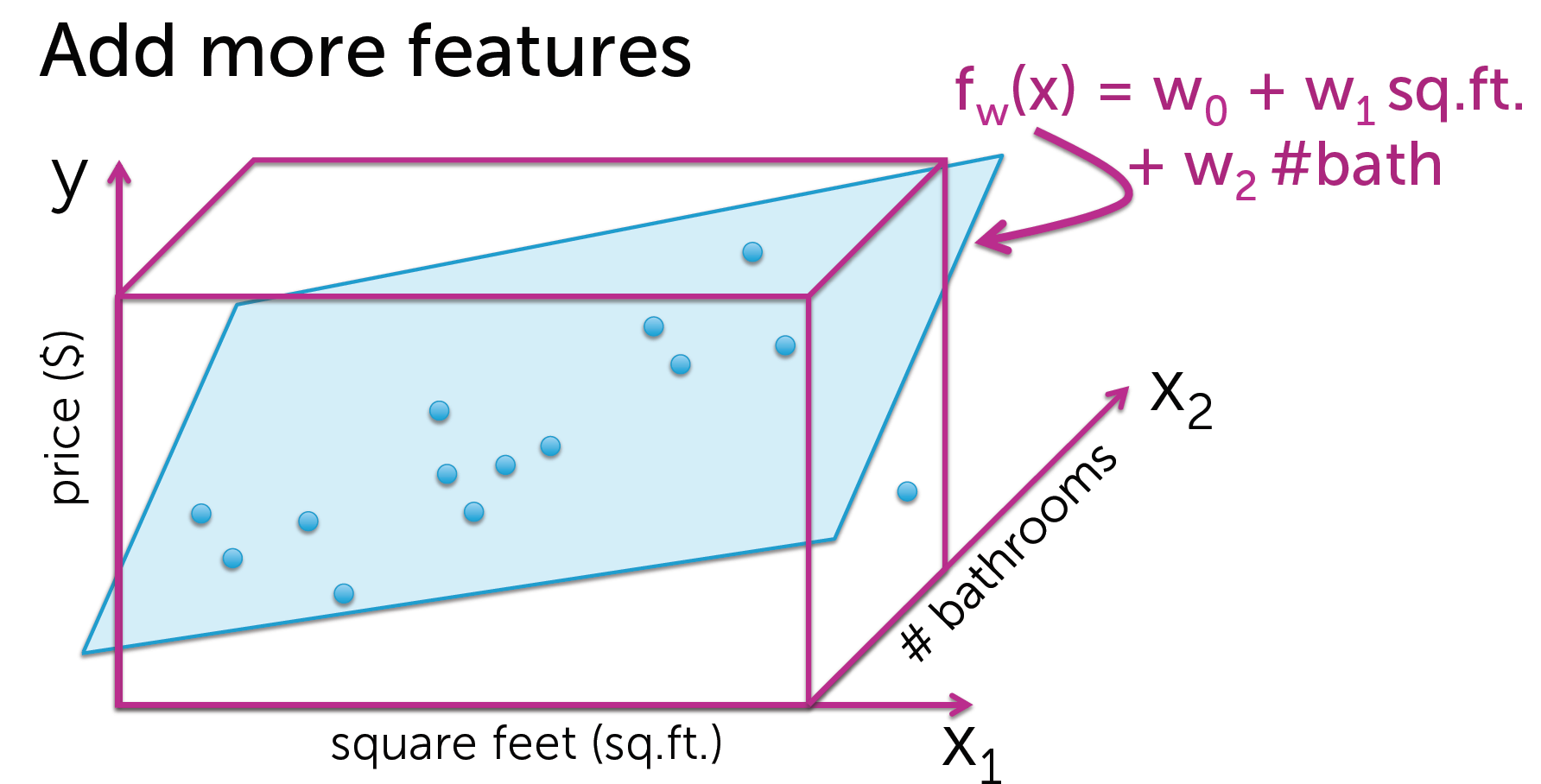
X1为房屋面积,X2为卫生间数量,Y为价格.
那么,另外一些特征呢?
卧室的数量
位置
...
end
课程:机器学习基础:案例研究(华盛顿大学)
视频链接:https://www.coursera.org/learn/ml-foundations/home/welcome
week2 Evaluating regression models
本博客内容都是博主试验通过的方案与方法.
如需交流,请发邮件至qjyyn#qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号