
2概述
设计模块最主要的操作分为: 转换和作业
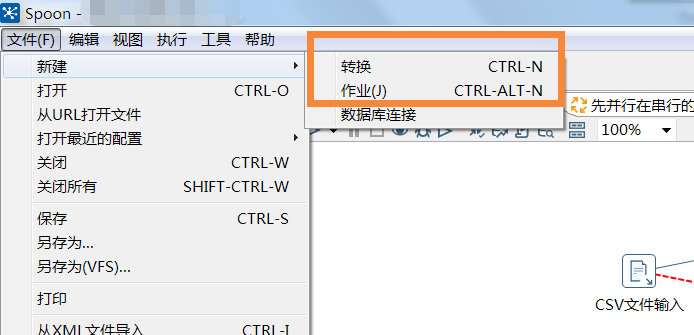
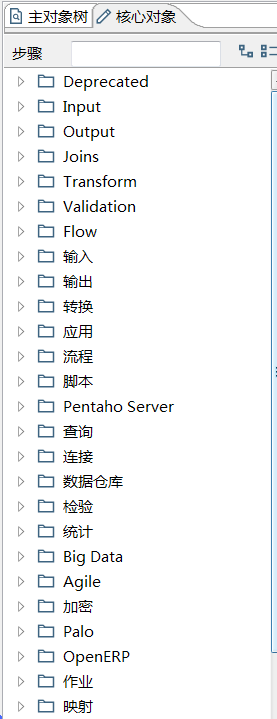
选择转换和作业后就可以选择对应主对象树和核心对象
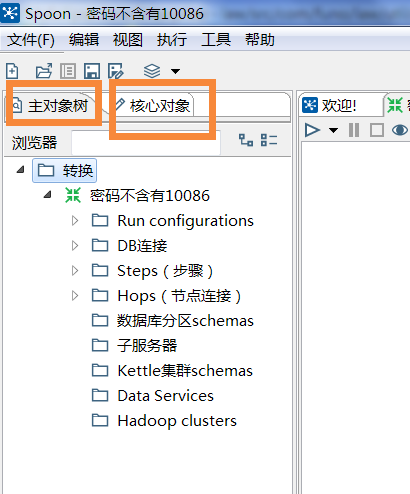
主对象树大同小异
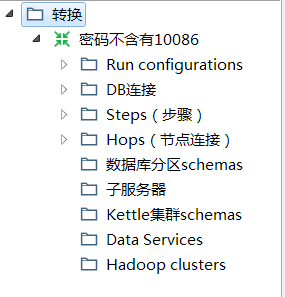
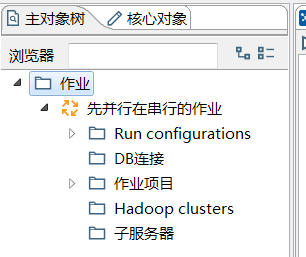
核心对象是不同的
比如转换需要用到的CSV表输入, 表输入等都在这里可以选择
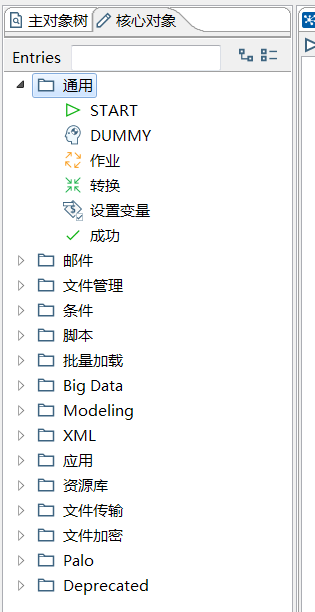
而作业的核心对象是:
2.1 转换
转换是ETL解决方案中最主要的部分, 它处理抽取、转换、加载各阶段各中对数据行的操作。转换1/N个步骤。
如图, 下面是一个转换的过程
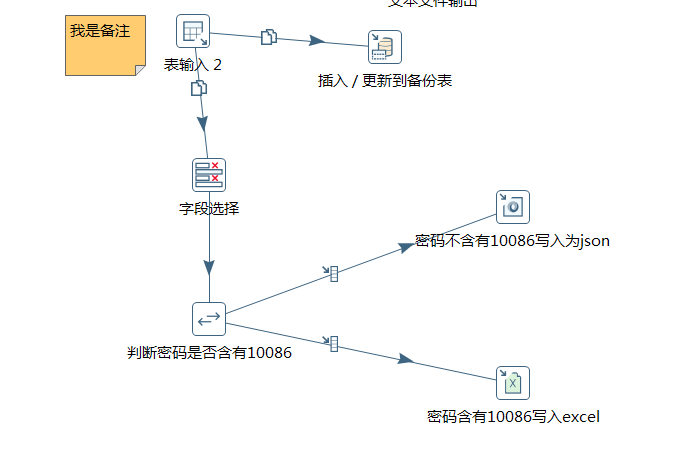
图中每个框都是一个步骤(step),而连接框的线就是所谓的跳(hop). 跳定义了一个单向通道, 允许数据由一个通道向另一个通道移动。在Kettle中数据的单位是行。
步骤
步骤是转换的基本组成部分(图中的框框) 它有以下关键属性:
1 每个步骤都有一个名字,在转换范围内唯一
2 每个步骤都会读,写数据行 (唯一的例外是生成记录的步骤)
3 步骤将数据写到与之相连的一个或多个输出跳, 再传送到跳的另一端的步骤. 对另一端步骤来说, 这个跳就是一个输入 跳, 步骤通过输入跳接受数据
4 大多数的步骤都可以有多个输出跳.
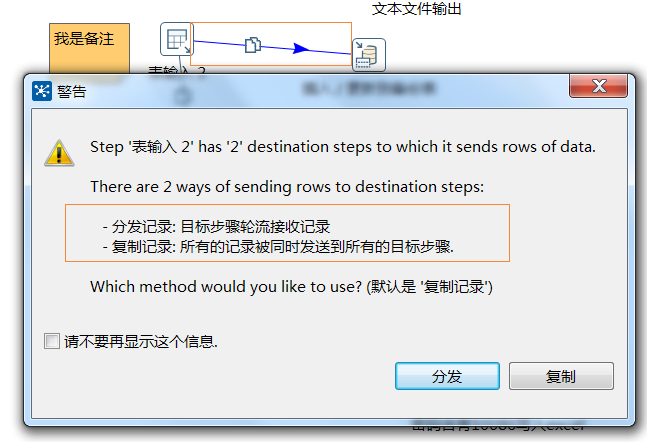
【一个步骤的数据发送(输出)可以设置为轮流发送和复制发送。轮流发送是将数据行依次发给每一个输出跳(每个输出获得的输出合起来才是完整数据),复制发送是将全部数据发给所有输出跳(每个输出都一样,是全部的数据)。】
在创建跳的时候可以选择:
5 运行转换时,一个线程运行一个步骤和步骤的多份copy,所有步骤的线程几乎同时运行,数据行连续地流过步骤之间的跳。
除了上面标准的属性,具体每个步骤根据其类型还有不同的区别。不再赘述。
转换的跳
跳(hop)就是步骤之间带箭头的连线,定义了步骤之间的数据通路。跳实际是两个步骤之间被称为行集的数据行缓存。
当行集满了,向行集写数据的步骤将停止写入,知道行集里又有了空间。当行集空了,从行集读取数据的步骤停止读取,直到行集里有了可读的数据行。
注意,跳在转换里不能循环。
并行
跳的这种基于行集缓存的规则允许每个步骤都由一个独立的线程运行,这样并发程度最高。
这一规则也徐允许数据以最小消耗内存的数据流方式来处理.
对于Kettle不可能定义一个执行顺序。所有步骤都以并发的方式执行:当转换启动后,所有步骤同时启动,从他们的输入跳中读取数据,并把处理过的数据写到输出跳,直到输入跳不再有数据,就中止步骤的运行。直到数据重新进来.
当所有的步骤都中止了,整个转换就中止了.
因为所有步骤都同时执行,从这个意义上来说, 转换是没有起点和终点的. 如果要一个任务沿着指定的顺序执行,就要使用后面说的"作业".
数据行
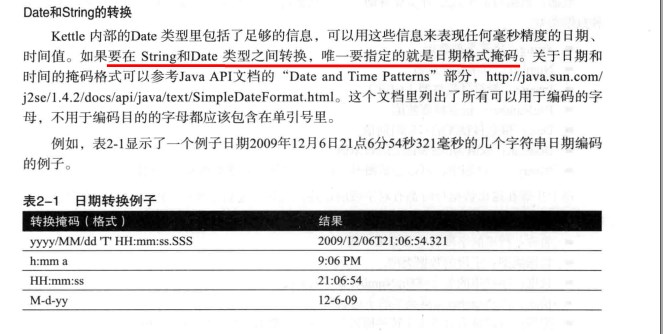
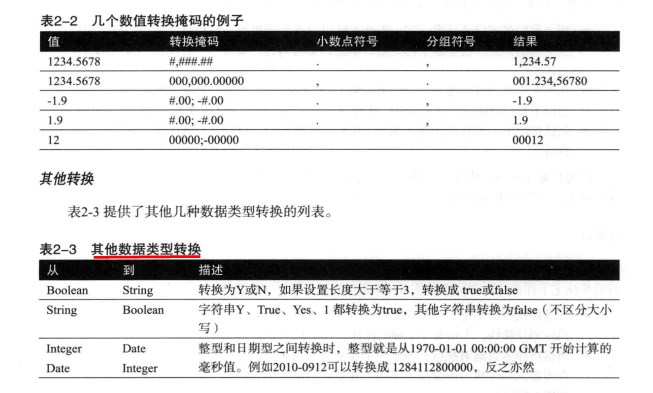
数据以数据行的形式沿着步骤移动。一个数据行是多个字段的集合,字段包括以下几种数据类型。



数据转换
显式数据转换: 在字段选择步骤中选择转换的数据类型.
隐私转换就是将数据类型数据写入数据库的varcahr类型字段.
比如:

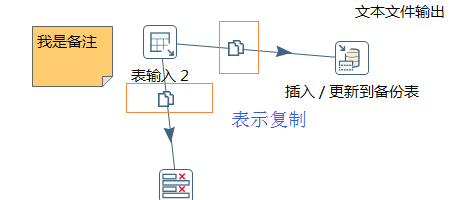
2.2 作业
让一些操作按照一定的顺序完成(如运行中发送错误的应对操作, 如验证库表存在等)
因为转换以并行方式执行, 就需要一个可以串行执行的作业来处理这些操作.
一个作业包括一到多个作业项, 这些作业项以某种顺序来执行. 作业执行顺序由作业项之间的跳和每个作业项执行结果来定.
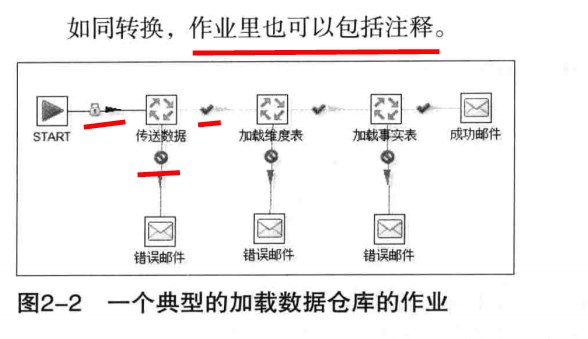
作业项
作业项是作业的基本构成. 如同转换的步骤.
不同之处:
1 新步骤名字是唯一的. 但作业项可以有影子拷贝. 这样就可以把一个作业项放在多个不同的位置. 这些影子拷贝是相同的,修改了其中一份, 其余的都随之改变.
2 作业项传递的是结果对象. 结果对象包含了数据行. 他们不是以流的方式实时传递. 而是等一个作业项执行完毕,再传递给下一个作业项.
3 默认情况,所有作业项都以串行执行. 值在特殊情况下才以并行执行.
因为作业顺序执行作业项, 所以必须定义一个起点(叫做开始的作业项, 并且只能有一个).
作业跳
作业项之间的连接线, 定义了作业的执行路径.
每个作业项的不同运行结果决定了作业后续的不同执行路径.
* 无条件执行: 黑色带锁图标表示. 无论上一个作业项成功与否都执行下一个作业项.
* 为真时执行: 绿色打勾图标表示. 上一个作业项执行为真, 才执行才可以作业项目.(一般需要无错误执行)
* 为假时执行: 红色停止图标表示. 上一个作业项执行为假或者没有成功执行时,执行下一个作业项.
直接点击即可切换类型:
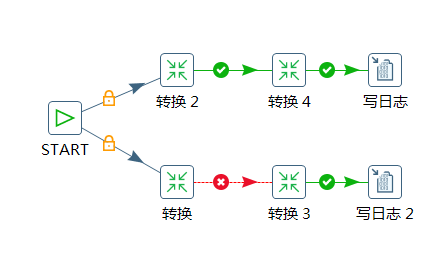
多路径和回溯
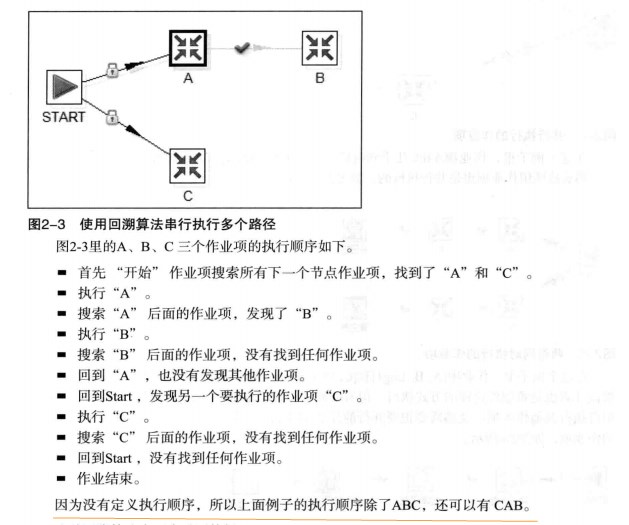
Kette使用一种回溯算法来执行作业里的素有作业项, 而且作业项的执行结果(真/假)也同事决定执行路径.
回溯算法: 假设执行到一条路径的某个节点时, 依次执行这个节点的所有子路径, 直到没有再可以执行的子路径, 就退回该节点的上一个节点, 如此反复.
举例:

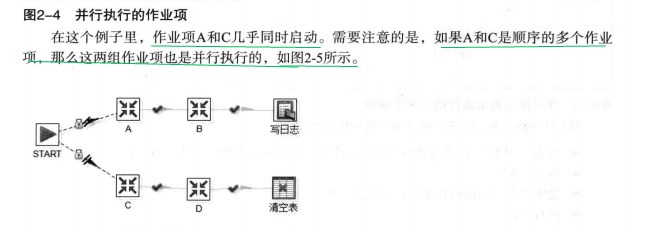
并行执行
一个作业项也可以并发的方式执行后面的所有作业项:

作业项结果
作业项结果包含以下信息:
一组数据行
一组文件名...
错误的行数和数量..
等..
2.3 转换或作业的元数据

2.4 数据库连接, 资源库
略.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号