sqlserver 体系结构
对于已经很熟悉T-SQL的读者,或者对于较专业的DBA来说,逻辑的增删改查,或者较复杂的SQL语句,都是非常简单的,不存在任何挑战,不值得一提,那么,SQL的哪些方面是他们的挑战 或者软肋呢?
那就是sql优化。然而,要向成为一个好的Sql优化高手,首先要做的一件事无疑就是了解sql语句在SQL Server中是如何执行的。在这一系列中,我们将开始sqlserver优化系列讲解,本 讲为优化系列的开篇文章,
在本篇文章中,我们将重点讲解SQL Server体系结构
在正式讲解之前,我们先来看看如下问题,你是否遇到过,若你遇到过且成功解决,那么这篇文章,你可以跳过。
为了测试需要,我们先模拟插入5亿3千多万条数据。
SELECT COUNT(1) FROM BigDataTest
(一)查询缓慢问题
*,临时表,表连接,子查询等造成的查询缓慢问题,你能解决吗?
(二)内存泄漏
如下查询了8分2秒,然后内存溢出,你知道问题吗?
SELECT * FROM BigDataTest
(三)经常听说如下概念,你都能解决吗?
事务与锁(请参考我另一篇文章:浅谈SQL Server事务与锁(上篇)),ACID,隔离级别,脏读,分表分库,水平拆分,垂直拆分,高并发等
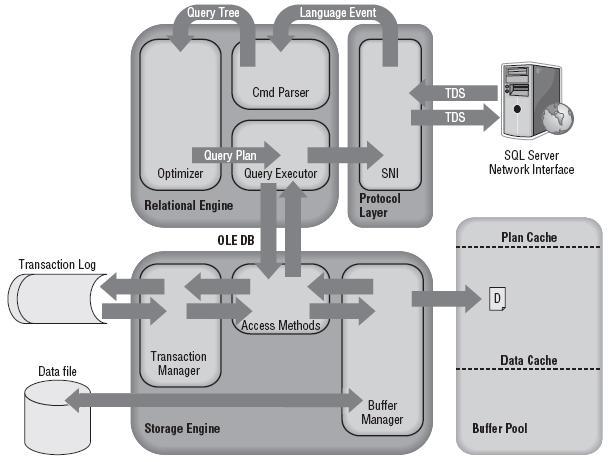
一 SQL Server体系结构抽象
二 SQL Server体系结构概述
SQL Server核心体系结构,大致包括六大部分:客户端访问工具、SQL Server 网络接口(SQL Server Network Interface,SNI)、关系引擎、存储引擎、
磁盘和缓冲池。下图为SQL Server核心体系大致轮廓图。
(一)SQL Server客户端访问工具
SQL Server客户端访问工具,提供了远程访问技术,它与SQL Server服务端基于一定的协议,使其能够远程访问数据库,就像在本地操作数据库一样,如我们经常用的
Microsoft SQL Server Management Studio。
SQL Server客户端访问工具是比较多的,其中比较流行的要数Microsoft SQL Server Management Studio 和Navicat(Navicat在MySQL中也是比较常用的)了,至于其他工具,
本篇文章就不列举了,感兴趣的读者朋友,可以查询一下。
(二)SQL Server网络协议
SQL Server网络协议,又叫SQL Server网络接口(SNI),它是构成客户端和服务端通信的桥梁,它与SQL Server服务端基于一定协议,方可通信,
如我们在客户端输入一条查询语句SELECT * FROM BigDataTest,这条语句,只有客户端和服务端基于一定协议,方可被服务端解析,否则,被视为无
效语句。
SQL Server网络协议,由一组API构成,这些API供SQL Server数据库引擎和SQL Server本地客户端调用,如实现最基本的CRUD通信。
SQL Server 网络接口(SQL Server Network Interface,SNI)只需要在客户端和服务端配置网络协议即可,它支持一下协议:
(1)共享内存
(2)TCP/IP
(3)命名管道
(4)VIA
(三)关系引擎
关系引擎,也叫查询引擎,其主要功能是负责处理SQL语句,其核心组件由三部分组成:命令分析器、查询优化器和查询执行器。
(1)命令分析器:负责解析客户端传递过来的T-SQL语句,如客户端传递一条SQL语句:SELECT * FROM BigDataTest,它会检查该语句的语法结构,若语法
错误,它会将错误返回给协议层,然后协议层将错误返回给客户端;如果语法结构正确,它会根据查询命令生成查询计划或寻找一个已存在的查询计划(先在缓冲池计划缓
存中查找,若找到,则直接给查询执行器执行,若未找到,则会生成基于T-SQL的查询树,然后交给查询优化器优化)
(2)查询优化器:负责优化命令解析器生成的T-SQL查询树(基于资源的优化,而非基于时间的优化),然后将最终优化结果传递给查询执行器执行。查询优化器是基于
“资源开销”的优化器,这种算法评估多种可执行的查询方式,并从中选择开销最低的方案作为优化结果,然后将该结果生成查询计划输出给查询执行器。注意,查询优化器是
“基于资源开销最优”而非“基于方案最优”,也就是,查询优化器的最终优化结果未必是最好的方案,但一定是资源开销最低的方案。
(3)查询执行器:负责执行查询。假若查询执行器接收到命令解析器或查询优化器传递过来的SQL语句:SELECT * FROM BigDataTest,它通过OLE DB接口传递到存储
引擎,再传递到存储引擎的访问方法。
(四)存储引擎
存储引擎,本质就是管理资源存储的,它的核心组件包括三部分:访问方法、事务管理器和缓冲区管理器。
(1)访问方法:访问方法本质是一个接口,供查询执行器调用(该接口提供了所有检索数据的代码,接口的实际执行是由缓冲区管理器来执行的),假若查询执行器传递一条SQL语句:
SELECT * FROM BigDataTest,访问方法接收到该请求命令后,就会调用缓冲区管理器,缓冲区管理器就会调用缓冲池的计划缓存,在计划缓存中寻找到相应的结果集,然后返回给关系
引擎。
(2)缓冲区管理器:供访问方法调用,管理缓冲池,在缓冲池中查询相应资源并返回结果集,供访问方法返回给关系引擎。
(3)事务管理器:主要负责事务的管理(ACID管理)和高并发管理(锁),它包括两个核心组件(日志管理器和锁管理器),锁管理器负责提供并发数据访问,设置隔离级别等;日志管理器负责
记录所有访问方法操作动作,如基本的CRUD。
(五)缓冲池
缓冲池驻于内存中,是磁盘和缓冲区管理器的桥梁SQL Server中,所有资源的查询都是在内存中进行的,即在缓冲池中进行的,假若缓冲池
接收到缓冲区管理器传递过来的的一条SQL语句:SELECT * FROM BigDataTest,缓冲区管理器数据缓存先从磁盘数据库中取满足条件的结果集,
然后放在缓冲池数据缓冲中,然后以结果集的形式返回给缓冲区管理器,供访问方法返回给关系引擎的查询执行器,然后返回给协议层,协议层再
返回给客户端。注意,这里操作的是缓冲池中数据,而不是磁盘DB中的数据,并且操作的缓冲池数据不会立即写入磁盘,因此就会造成查询到结果
与BD中的结果不一致,这就是所谓的脏读。
缓冲池主要包括两部分:计划缓存(生成执行计划是非常耗时耗资源的,计划缓存主要用来存储执行计划,以备后续使用)和数据缓存(通常是缓存池
中容量最大的,消耗内存最大,从磁盘中读取的数据页只要放在这里,方可调用)
(六)磁盘
磁盘主要是用来存储持久化资源的,如日志资源,数据库资源和缓存池持久化支援等。
三 一个查询的完整流程
如下为一个比较完善的查询过程,即第二部分查询语句:SELECT * FROM BigDataTest 整个过程。
四 参考文献
【01】《SQL Server 2012 深入解析与性能优化 第3版》Christian Bolton,Justin Langford,Glenn Berry,Gavin Payne,Amit Banerjee,Rob Farley著
原文:https://www.likecs.com/show-43676.html
Sqlserver体系结构(2005/2008版本)
关于oracle的体系结构,网上可以找到很多,但是关于sqlserver的体系结构,网上确实不多
讲的好的更不好,今天正好看到一篇,分享大家.
- 协议层(Protocols)
- 关系引擎(Relational Engine),也称为查询处理器(Query Processor)
- 存储引擎(Storage Engine)
- SQLOS
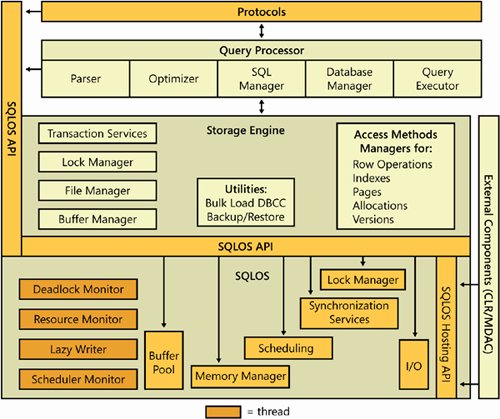
协议层(Protocols)
当应用程序与 SQL Server 数据库通信时,首先需要通过 SNI(SQL Server Network Interface)网络接口选择建立通信连接的协议。可以使用以下协议:
- TCP/IP:应用最广泛的协议;
- Named Pipes:仅为局域网(LAN)提供服务;
- Shared Memory:仅支持在同一台机器上;
- VIA(Virtual Interface Adapter):仅支持高性能 VIA 硬件;(该协议已弃用)
可以对 SQL Server 进行配置,使其可以同时支持多种协议。各种协议在不同的环境中有着不同的性能表现,需要根据性能需求选择合适的协议。如果客户端并未指定使用哪种协议,则可配置逐个地尝试各种协议。
连接建立后,应用程序即可与数据库进行直接的通信。当应用程序准备使用 T-SQL 语句 "select * from TableA" 向数据库查询数据时,查询请求在应用程序侧首先被翻译成 TDS 协议包(TDS:Tabular Data Stream 即表格格式数据流协议),然后通过连接的通信协议信道发送至数据库一端。
SQL Server 协议层接收到请求,并将请求转换成关系引擎(Relational Engine)可以处理的形式。
关系引擎(Relational Engine)
关系引擎(Relational Engine)也称为查询处理器(Query Processor),主要包含 3 个部分:
- 命令解析器(Command Parser)
- 查询优化器(Query Optimizer)
- 查询执行器(Query Executor)
协议层将接收到的 TDS 消息解析回 T-SQL 语句,首先传递给命令解析器(Command Parser)。
命令解析器(Command Parser)检查 T-SQL 语法的正确性,并将 T-SQL 语句转换成可以进行操作的内部格式,即查询树(Query Tree)。
- 查询树(Query Tree)是结构化查询语言 SQL(Structured Query Language)的内部表现形式。
- 数据操纵语言 DML(Data Manipulation Language)是 SQL 语言的子集,包括 INSERT, UPDATE, DELETE 三种核心指令。
- 数据定义语言 DDL(Data Definition Language)管理表和索引结构,包括 CREATE, DROP, ALTER, TRUNCATE 等命令。
- 数据控制语言 DCL(Data Control Language)负责授权用户访问和处理数据,包括 GRANT, REVOKE 等命名。
- T-SQL 即 Transact-SQL 则是在 SQL 基础上扩展了过程化编程语言的功能,如流程控制等。
- SQLCLR(SQL Server Common Language Runtime)使用 .NET 程序集来扩展功能。
查询优化器(Query Optimizer)从命令解析器处得到查询树(Query Tree),判断查询树是否可被优化,然后将从许多可能的方式中确定一种最佳方式,对查询树进行优化。
- 无法优化的语句,包括控制流和 DDL 等,将被编译成内部形式。
- 可优化的语句,例如 DML 等,将被做上标记等待优化。
优化步骤首先进行规范查询(Normalize Query),可以将单个查询分解成多个细粒度的查询,并对细粒度的查询进行优化,这意味着它将为执行查询确定计划,所以查询优化器的结果是产生一个执行计划(Execution Plan)。
查询优化是基于成本的(Cost-based)考量的,也就是说,选择成本效益最高的计划。查询优化器需要根据内部记录的性能指标选择消耗最少的计划。这些内部性能指标包括:Memory 需求、CPU 利用率和 I/O 操作数量等。同时,查询优化还使用启发式算法(Pruning Heuristics),以确保评估优化及查询的时间消耗不会比直接执行未优化查询的时间更长。
在完成查询的规范化和最优化之后,这些过程产生的结果将被编译成执行计划(Execution Plan)数据结构。执行计划中包括查询哪张表、使用哪个索引、检查何种安全性以及哪些条件为何值等信息。
查询执行器(Query Executor)运行查询优化器(Query Optimizer)产生的执行计划,在执行计划中充当所有命令的调度程序,并跟踪每个命令执行的过程。大多数命令需要与存储引擎(Storage Engine)进行交互,以检索或修改数据等。
存储引擎(Storage Engine)
SQL Server 存储引擎中包含负责访问和管理数据的组件,主要包括:
- 访问方法(Access Methods)
- 锁管理器(Lock Manager)
- 事务服务(Transaction Services)
- 实用工具(Controlling Utilities)
访问方法(Access Methods)包含创建、更新和查询数据的具体操作,下面列出了一些访问方法类型:
- 行和索引操作(Row and Index Operations):负责操作和维护磁盘上的数据结构,也就是数据行和 B 树索引。
- 页分配操作(Page Allocation Operations):每个数据库都是 8KB 磁盘页的集合,这些磁盘页分布在多个物理文件中。SQL Server 使用 13 种磁盘页面结构,包括数据页面、索引页面等。
- 版本操作(Versioning Operations):用于维护行变化的版本,以支持快照隔离(Snapshot Isolation)功能等。
访问方法并不直接检索页面,它向缓冲区管理器(Buffer Manager)发送请求,缓冲区管理器在其管理的缓存中扫描页面,或者将页面从磁盘读取到缓存中。在扫描启动时,会使用预测先行(Look-ahead Mechanism)机制对页面中的行或索引进行验证。
锁管理器(Lock Manager)用于控制表、页面、行和系统数据的锁定,负责在多用户环境下解决冲突问题,管理不同类型锁的兼容性,解决死锁问题,以及根据需要提升锁(Escalate Locks)的功能。
事务服务(Transaction Services)用于提供事务的 ACID 属性支持。ACID 属性包括:
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
预写日志(Write-ahead Logging)功能确保在真正发生变化的数据页写入磁盘前,始终先在磁盘中写入日志记录,使得任务回滚成为可能。写入事务日志是同步的,即 SQL Server 必须等它完成。但写入数据页可以是异步的,所以可以在缓存中组织需要写入的数据页进行批量写入,以提高写入性能。

SQL Server 支持两种并发模型来保证事务的 ACID 属性:
- 悲观并发(Pessimistic Concurrency)假设冲突始终会发生,通过锁定数据来确保正确性和并发性。
- 乐观并发(Optimistic Concurrency)假设不会发生冲突,在碰到冲突再进行处理。
在乐观并发模型中,用户读数据时不锁定数据。在执行更新时,系统进行检查,查看另一个用户读过数据后是否更改了数据。如果另一个用户更改了数据,则产生一个错误,接收错误信息的用户将回滚事务。该模型主要用在数据争夺少的环境中,以及锁定数据的成本超过回滚事务的成本时。
SQL Server 提供了 5 中隔离级别(Isolation Level),在处理多用户并发时可以支持不同的并发模型。
- Read Uncommitted:仅支持悲观并发;
- Repeatable Read:仅支持悲观并发;
- Serializable:仅支持悲观并发;
- Snapshot: 支持乐观并发;
- Read Committed:默认隔离级别,依据配置既可支持悲观并发也可支持乐观并发。
实用工具(Controlling Utilities)中包含用于控制存储引擎的工具,如批量加载(Bulk-load)、DBCC 命令、全文本索引管理(Full-text Index Management)、备份和还原命令等。
SQLOS
SQLOS 是一个单独的应用层,位于 SQL Server 引擎的最低层。SQLOS 的主要功能包括:
- 调度(Scheduling)
- 内存管理(Memory Management)
- 同步(Synchronization):提供 Spinlock, Mutex, ReaderWriterLock 等锁机制。
- 内存代理(Memory Broker):提供 Memory Distribution 而不是 Memory Allocation。
- 错误处理(Exception Handling)
- 死锁检测(Deadlock Detection)
- 扩展事件(Extended Events)
- 异步 I/O(Asynchronous IO)
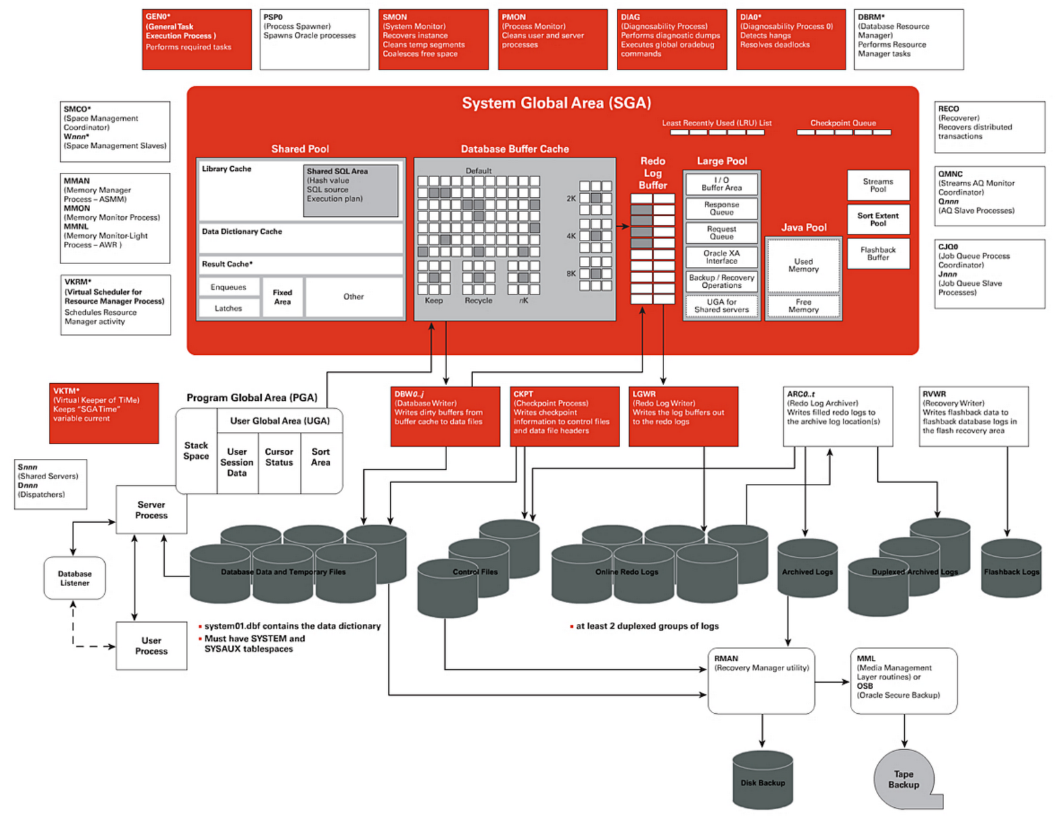
数据库体系结构对比
实际上,如果从体系结构的整体上来比较,各种常见的关系型数据库的体系结构都是差不多的。这也使得我们在了解一种数据库后,可以大体的猜测和快速理解另一种数据库。
下面是 Oracle 数据库的架构图:
下面是 MySQL 数据库的结构图:

MySQL 数据库在存储引擎部分实现了可插拔式设计(Pluggable Storage Engines),可以根据需求不同选择不同类型的存储引擎实现。
甚至在同一个数据库实例中,每张数据表都可以指定使用哪种存储引擎。
CREATE TABLE customers (a INT, b CHAR (20), INDEX (a)) ENGINE=InnoDB;
原文地址:http://www.yanyulin.info/pages/2014/11/931201017896.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号