个人项目-论文查重
个人项目
| 软件工程 | |
|---|---|
| 作业要求 | |
| 作业目标 | 完成论文查重项目的实现后进行测试并按以上要求使用Github进行版本发布及源码和测试用例管理 |
| 个人作业github链接 |
一、PSP表格
二、项目整体流程
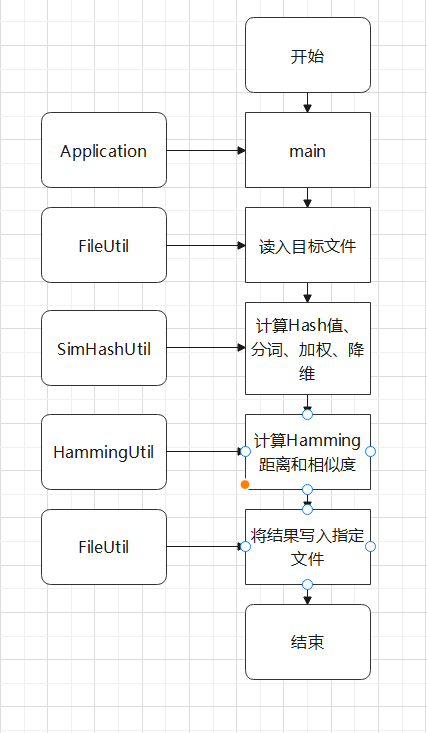
三、项目接口的设计与实现
1、项目结构
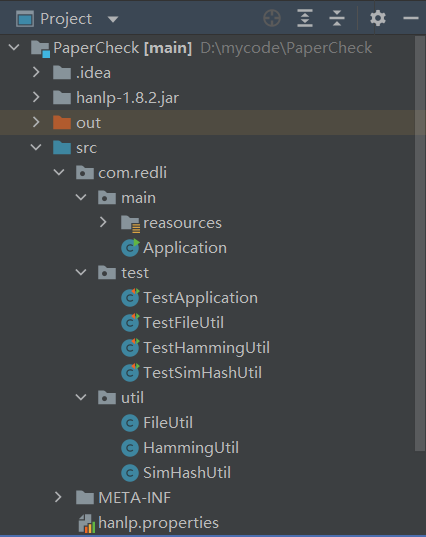
2、主要实现类
主类:
Application类:通过main方法接收三个文件的绝对路径作为参数,并调用其它类方法实现整个查重功能。
功能类:
FileUtil类:实现文件的读入与写出功能。
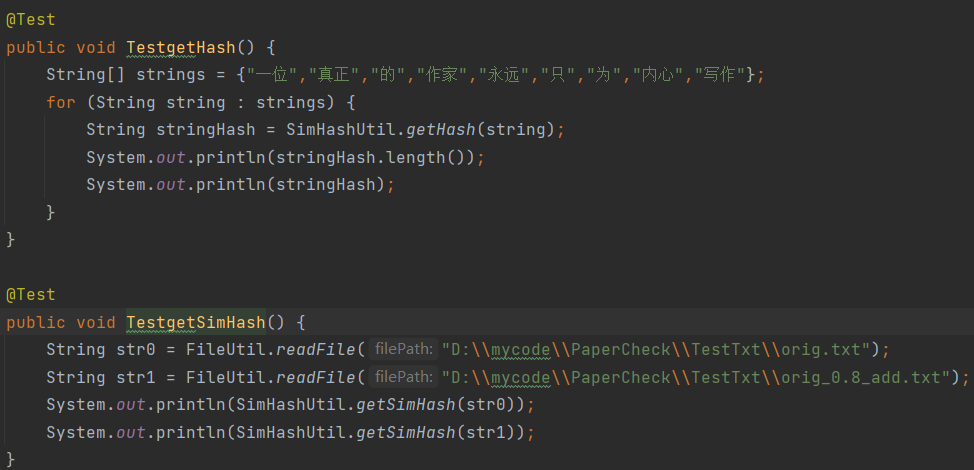
SimHashUtil类:实现计算Hash值、分词、加权、降维的操作。
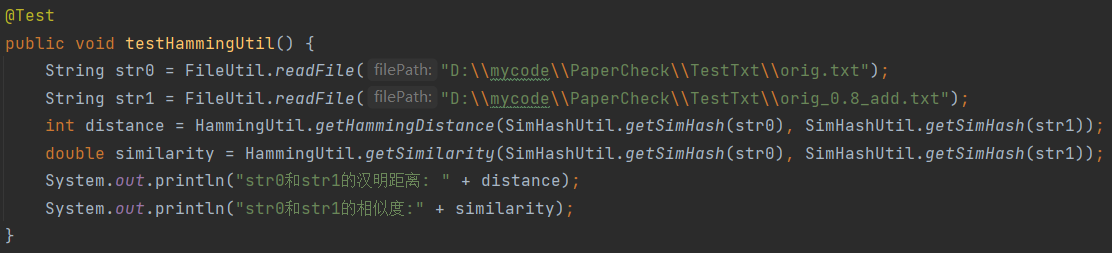
HammingUtil类:实现计算Hamming距离和相似度。
3、关键函数的实现与分析
实现论文查重的关键是SimHash算法
具体参考:使用simhash以及海明距离判断內容相似程度和相似文档查找之simHash简介及其java实现
SimHash算法原理
1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样字符串就变成了一串串数字,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程。
3、加权,通过 2步骤的hash生成结果,按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
来做个测试,两个相差只有一个字符的文本串,“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通过比较差异的位数就可以得到两串文本的差异,差异的位数,称之为“海明距离”,通常认为海明距离<3的是高度相似的文本。
四、模块接口性能部分的性能改进
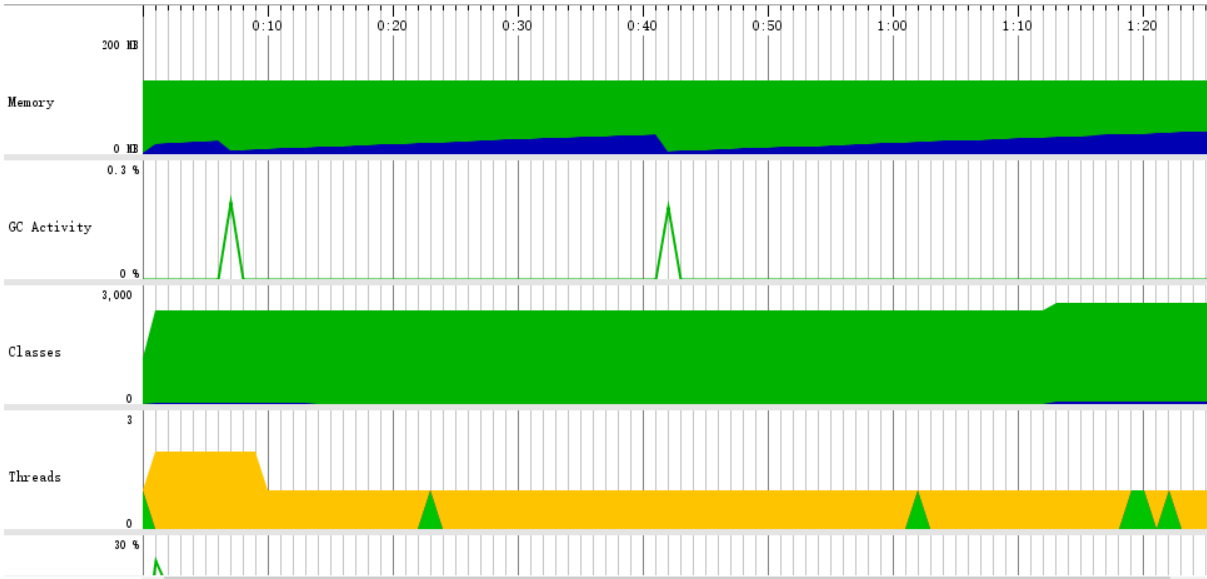
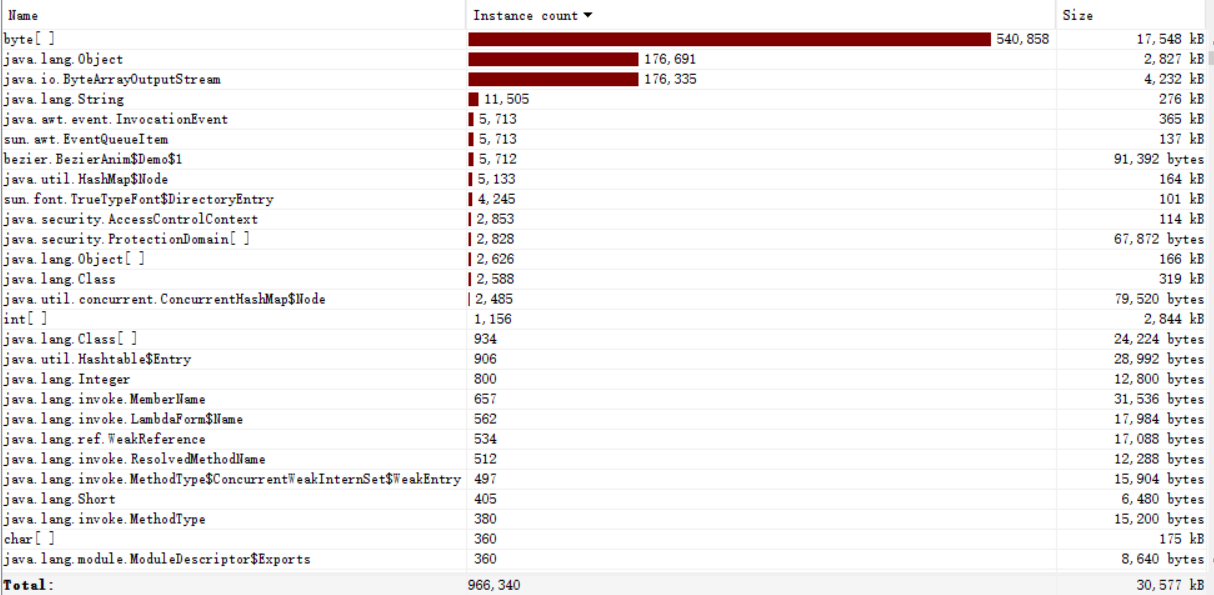
五、模块单元测试展示
Application类:
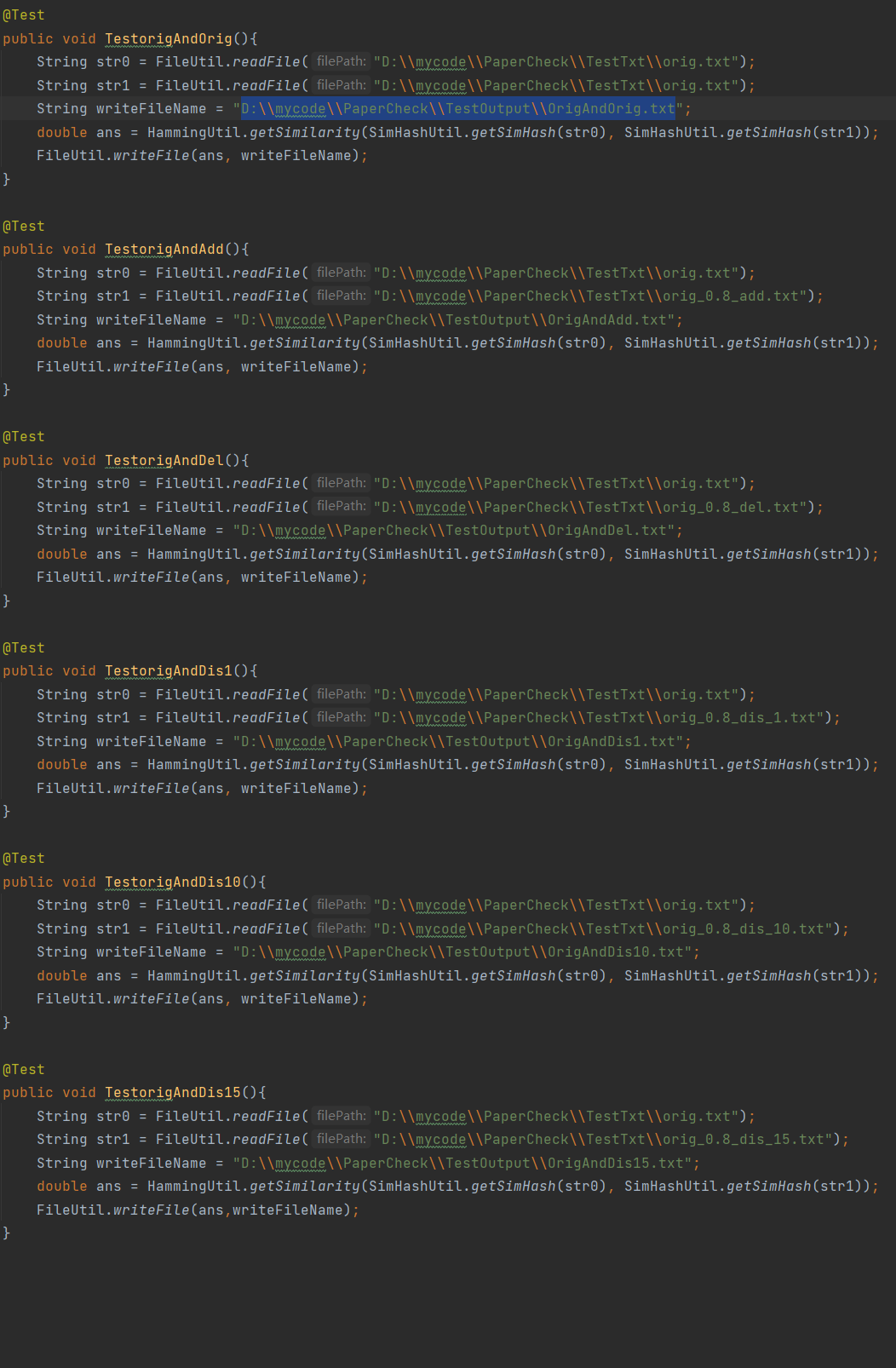
FileUtil类:
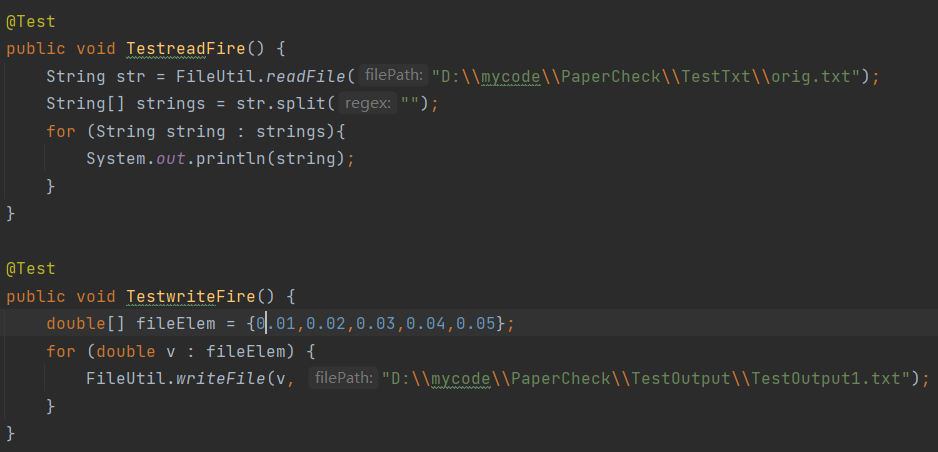
SimHashUtil类:
HammingUtil类:
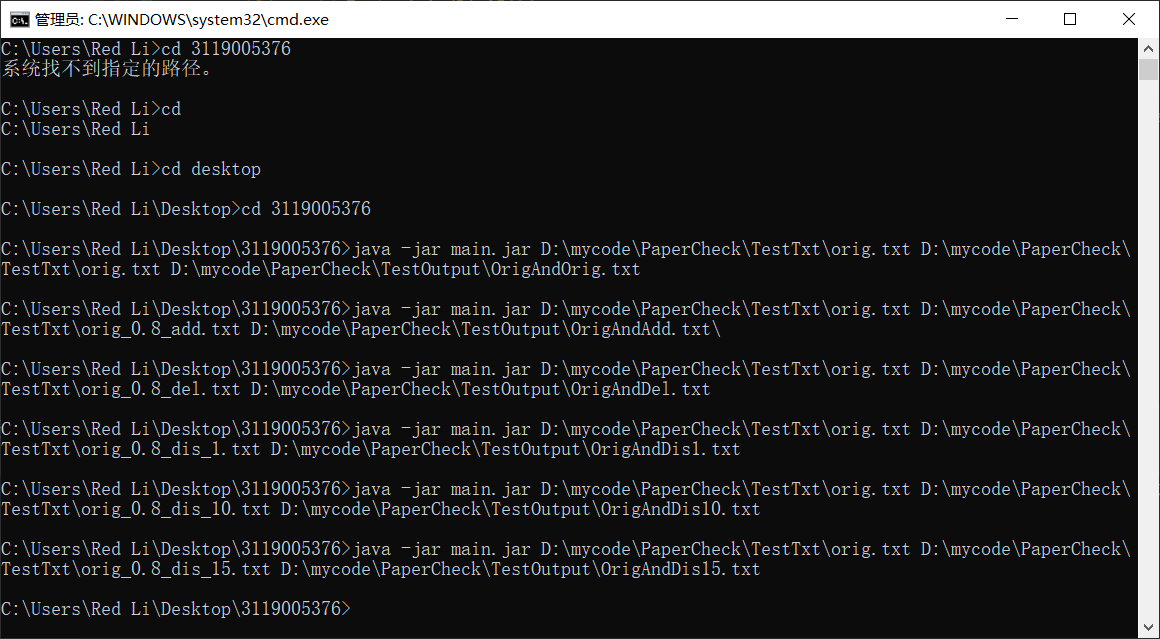
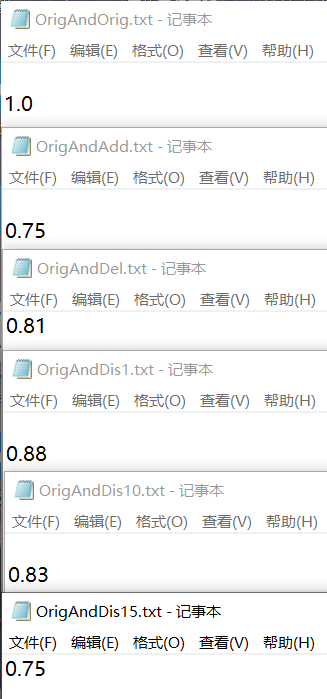
六、项目运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号