集合源码分析06——Map——HashMap源码分析

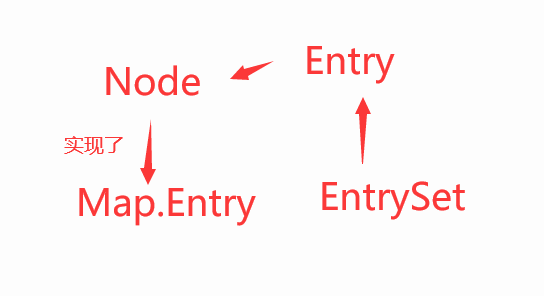
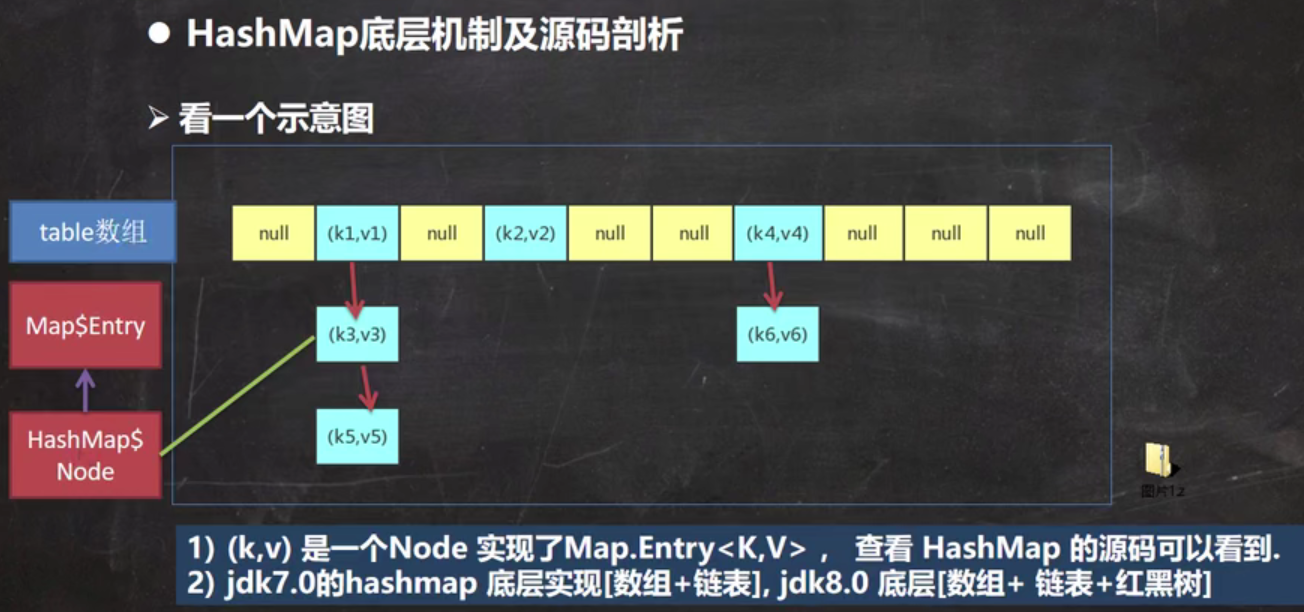


(其实同之前的HashSet的分析差不多,详情可以看之前的)
1.执行构造器语句,初始化加载因子,并且将table表等初始化为null
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted }
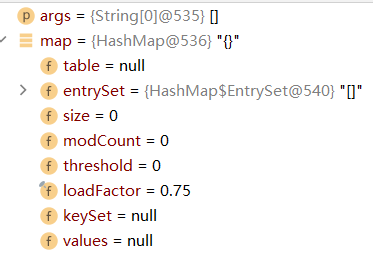
2.执行put方法,因为是基本数据类型所以先进行一个装箱操作
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }

3.
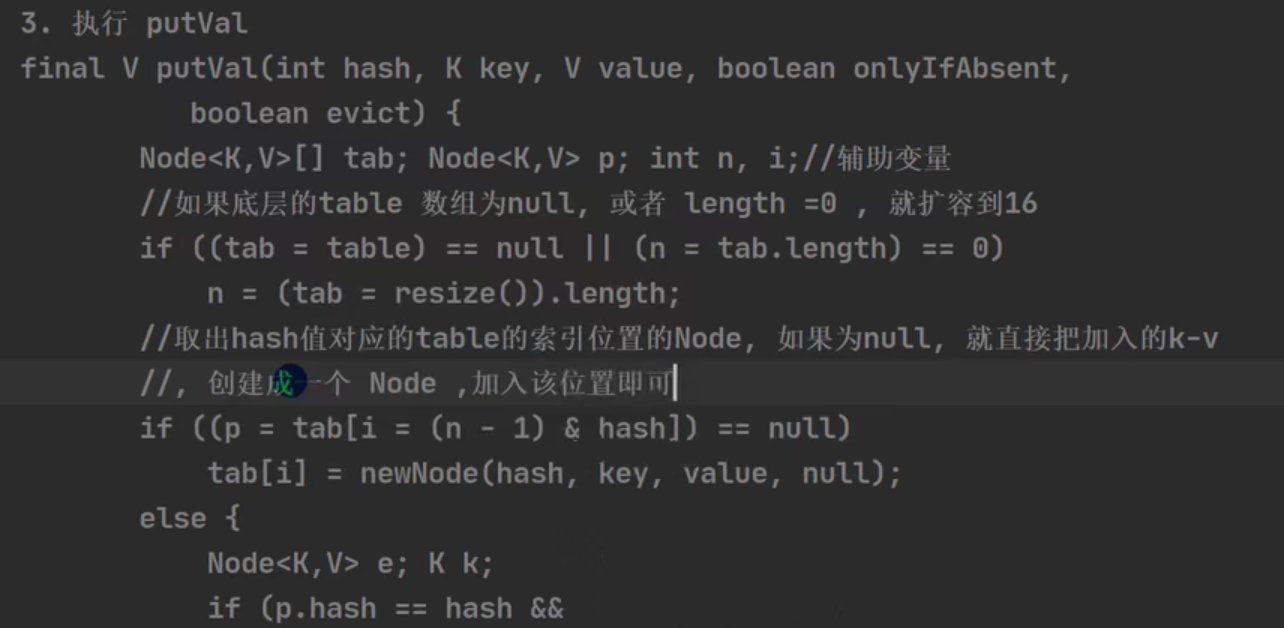
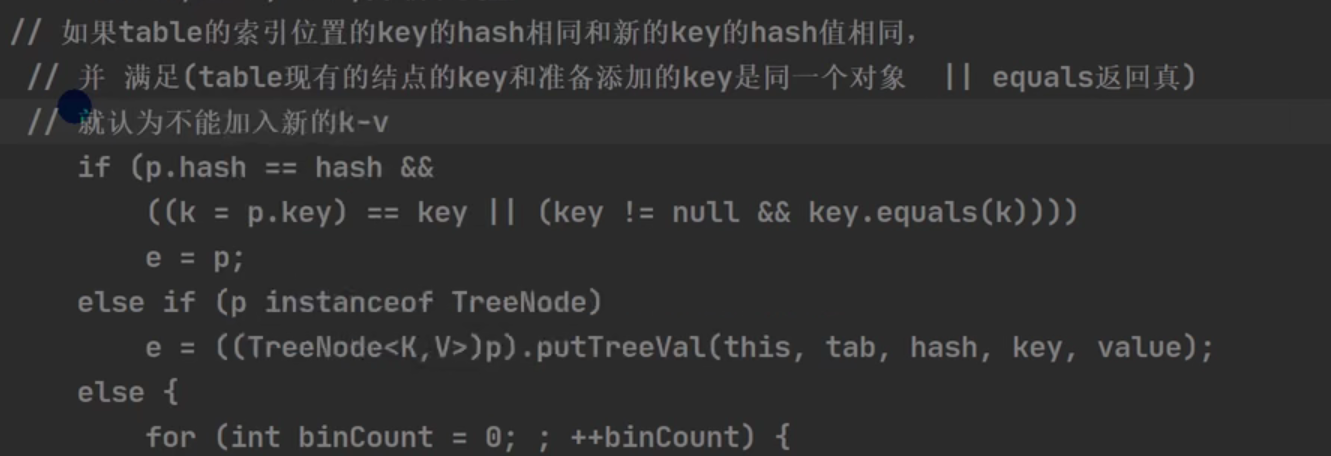
然后计数变量modCount++,return null;第一次结束
4.与HashSet不同之处就是在e被改变不为null(key值相同)的情况下走这条代码块的时候,value是会被改变的(因为HashSet的value统一是PERSENT所以没什么变化),这里直接走了return oldValue也就没有modCount++了。

- HashMap扩容和树化机制模拟触发
package test; import java.util.HashMap; /** * @author 紫英 * @version 1.0 * @discription 随便写 */ public class Test { public static void main(String[] args) { HashMap map = new HashMap(); for (int i = 1; i <= 12; i++) { map.put(new A(i),"666"); } } } class A{ int i; @Override public String toString() { return "A{" + "i=" + i + '}'; } public A(int i) { this.i = i; } //为了保证在同一个位置添加索引我们重写hashcode使之返回一个固定值 @Override public int hashCode() { return 100; } }
之后我们通过debug的方式来看一下具体的树化机制的触发
1.可以看到前8次的时候并没有触发扩容机制

2.第九次的时候满足单条链表超过8个数据进行树化,但是由于table的大小并不满足64所以先进行table的扩容
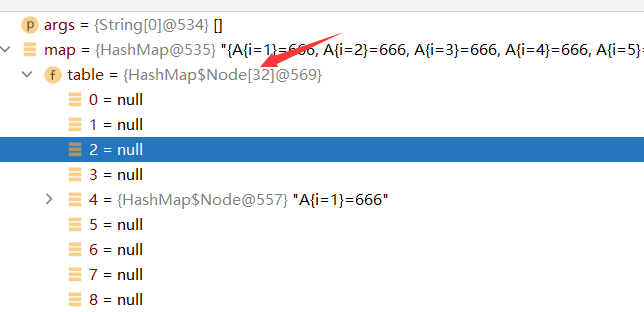
3.第10次再次扩容到64

4.第11次开始树化
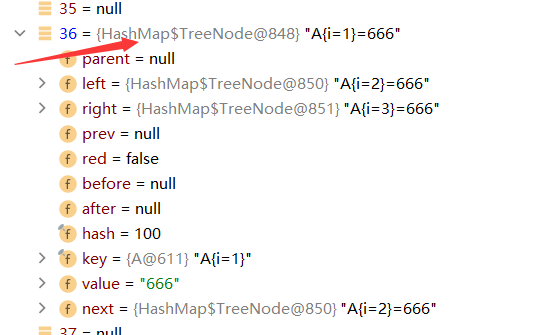
可以看出数组类型从之前的Node变成了TreeNode
5.第12次则通过putTreeVal方法来添加
这里说明一下,虽然++size写在了判断条件内,但是是每次都走的,只要size超过了临界值(12-24-48-96-192)都会触发扩容机制,与是否在同一条链表上无关

临界值是interger的上限 如果节点数超过这个数值(public static final int MAX_VALUE = 2147483647)的话就一直返回原先的表格,即无法再继续添加了
if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; }
本文来自博客园,作者:紫英626,转载请注明原文链接:https://www.cnblogs.com/recorderM/p/15824766.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号