集合源码分析04——Set——HashSet源码分析
HashSet源码分析
-
基本说明
- 实现了Set接口
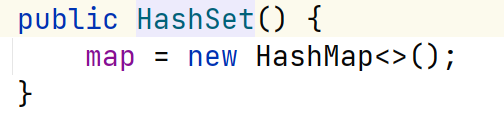
- HashSet实际上是HashMap,这里可以看到HashSet的构造器走的是HashMap
3.可以存放null,但只可以存放一个null
4.HashSet不保证元素的存放顺序和取出顺序一致(可能一致也可能不一致)
5.不能有重复的元素(同Set接口要求一致)
package collection.set.hashset; import java.util.HashSet; import java.util.Set; /** * @author 紫英 * @version 1.0 * @discription */ public class Hashset01 { public static void main(String[] args) { Set set = new HashSet(); System.out.println(set.add("111"));//true System.out.println(set.add("111"));//false
System.out.println(set.add("222"));//true System.out.println(set.add("333"));//true
System.out.println(set.add(new Dog("tom")));//true System.out.println(set.add(new Dog("tom")));//true
System.out.println(set.add(new String("jack")));//true System.out.println(set.add(new String("jack")));//false } } class Dog{ private String name; public Dog(String name) { this.name = name; } }

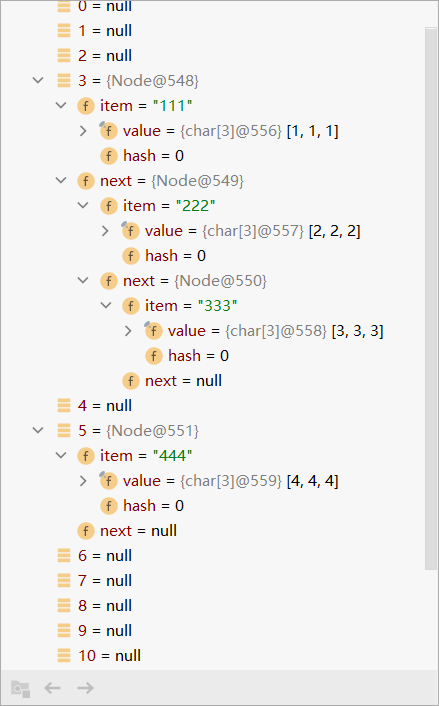
- 这里我们模拟一个简单的数组+链表结构(之所以采用这种模式是因为这样存储效率比单纯的二维数组高得多)
package collection.set.hashset; /** * @author 紫英 * @version 1.0 * @discription 模拟数组+链表 */ public class HashsetStructure { public static void main(String[] args) { //1.创建一个Node型的数组(也成为表) Node[] table = new Node[16]; //2.创建节点 Node node01 = new Node("111",null); Node node02 = new Node("222",null); node01.next=node02;//将node02挂载到node01后面 Node node03 = new Node("333",null); node02.next=node03;//将node03挂载到node02后面 Node node04 = new Node("444",null); table[3]=node01; table[5]=node04; } } class Node{ //节点类,用于存储数据,可以指向下一个节点来形成链表 Object item; //存放数据 Node next; //指向下一个节点 public Node(Object item, Node next) { this.item = item; this.next = next; } }
可以看到整体结构如下图:
-
底层机制说明
- 元素添加:通过equals()+hash()方法实现

这里的equals并不是简单的比较添加的字符串,而是可以由程序员指定,
例如添加两个Student对象,可以自己重写equals()方法来判断怎样才算相同(例如name+age或者只有name)
- 扩容和转换成红黑树的机制


如果树化后一直删除节点导致不满足树化条件会进行剪枝操作——将红黑树还原为链表
下面我们debug一段简单的代码:
public class Hashset02 { public static void main(String[] args) { HashSet hashset = new HashSet(); hashset.add("java"); hashset.add("c++"); hashset.add("java"); System.out.println("hashset = " + hashset); } }
结果:![]()
开始分析:
- 一、第一次添加——hashset.add("java")
1.执行构造器语句

2.执行add()方法,将第一个“java”传递给e

3.执行map.put()方法,可以看到这里的key就是之前传进去的“java”,而value则是上面的PERSENT

这里的PERSENT是HashSet中的一个final类型的属性,创建了一个Object类型的对象,如下图。没有什么实际意义是作为满足map(K,V)定义的占位数据,也就是都使用这个Object类型的对象来作为value

4.执行put中的hash(key) (使用force step into追进去)

这里先判断key是否是null,如果不是的话返回key.hashCode() ^ (h >>> 16) ,主要是为了防止冲突,使不同的key尽量得到不同的hash(),注意这里返回的并不是key真正的hashCode()
位异或运算(^) 运算规则是:两个数转为二进制,然后从高位开始比较,如果相同则为0,不相同则为1。 比如:8^11. 8转为二进制是1000,11转为二进制是1011.从高位开始比较得到的是:0011.然后二进制转为十进制,就是Integer.parseInt("0011",2)=3;
h >>> 16 是将h无符号右移16位
5.进入putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict)方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { //1.这里定义了辅助变量
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, i;
//2.这里的table为HashMap的一个属性,是一个存放节点的Node型数组Node[]
//3.判断一下当前的table是否为null 或者大小是0如果是就进行第一次扩容,到16个空间 // 第一次是确实是空,所以我们接下来进入resize()
if ((tab = table) == null || (n = tab.length) == 0)
//8.这里将刚才返回的newTab赋值给辅助变量tab,并用n存储数组长度
n = (tab = resize()).length; //9. (1)根据刚才用key取得的hash值,来确定该key在table中的索引位置并将该索引位置的值赋值给辅助变量p // (2)判断p是否为null //(2).1 如果p为null,代表该索引位置还没有存放元素,就创建一个Node对象 //(2).2 然后在该位置tab[i] = newNode(hash, key, value, null); if ((p = tab[i = (n - 1) & hash]) == null) //这段代码,其中获取了当前table数组的最大下标(n-1)与hash(key)进行按位与操作 //这里key为真正存放的数据,value就是之前Object类型的对象PERSENT,hash用来比较之后的元素,next为null tab[i] = newNode(hash, key, value, null);//此时已经将“java”放进去了,如图1.1 else { HashMap.Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) //如果该索引位置已经是红黑树则按照红黑树的方法来处理(添加)
e = ((HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount;//每增加一个Node 就++
//这里判断一下当前大小是否已经超过了临界值,如果超过了就再次进行扩容 if (++size > threshold)
//这里判断的的size指的是Node节点的个数 不论加在哪里(不同索引或者同一索引的一条链表上)

resize();
//这里这个方法是HashMap留给它的子类如 LinkedHashSet等去实现 // 来进行形成一个有序链表、挂载双向链表等操作,对于HashMap而言则是一个空方法 //void afterNodeInsertion(boolean evict) { } afterNodeInsertion(evict); return null; //方法的返回值是V,而V是Object类型的,所以可以返回null //10.返回null代表添加成功,返回到上一层的put()方法中 //public V put(K key, V value) { // return putVal(hash(key), key, value, false, true);//null // } //然后在返回给add()方法 //public boolean add(E e) { // return map.put(e, PRESENT)==null; //这里判断null==null为true也就是添加的时候该位置没有元素,到此为止第一次添加成功 // } }
resize()方法
final HashMap.Node<K,V>[] resize() { //4.这里也是定义了一些辅助变量,例如存放老容量的int型数据,记录预先数据的oldTab等 HashMap.Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; //5.第一次会进入到这个else语句 else { // zero initial threshold signifies using defaults //这里的DEFAULT_INITIAL_CAPACITY默认是16 // static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 newCap = DEFAULT_INITIAL_CAPACITY; //这里的newThr是一个临界值 是newCap的0.75倍 到达这个阈值的时候会再次扩容 //防止有大量元素添加造成阻塞 // 加载因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) //6.这里创建了一个newCap也就是16个元素大小的Node型数组,并用newTab来存储 HashMap.Node<K,V>[] newTab = (HashMap.Node<K,V>[])new HashMap.Node[newCap]; //将table指向newTab,此时的table已经有16个null了 table = newTab; //剩下的我们第一次添加先不看,直接看到return if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { HashMap.Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof HashMap.TreeNode) ((HashMap.TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order HashMap.Node<K,V> loHead = null, loTail = null; HashMap.Node<K,V> hiHead = null, hiTail = null; HashMap.Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } //7.最终将创建好的newTab返回 给上面的putVal return newTab; }
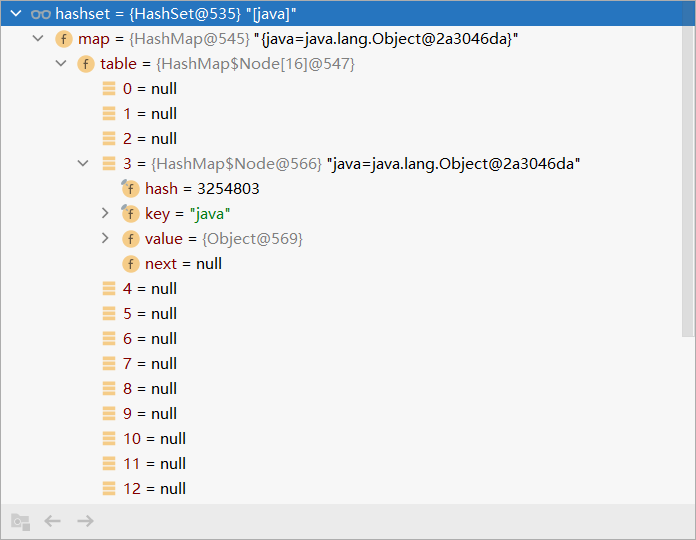
图1.1
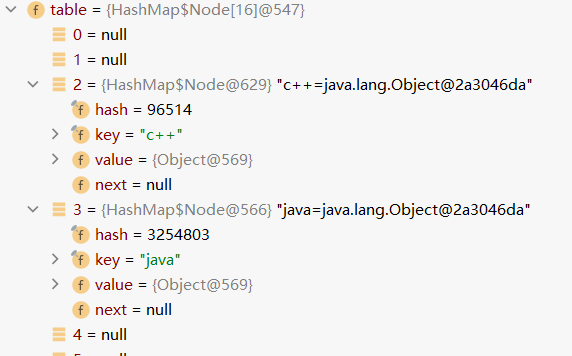
- 二、第二次添加——hashset.add("c++")
1-4步同第一次我们直接进入到putVal()方法
5.putVal(),主要看以下语句
//1.此时的table已经存在数据了(刚才的“java”),所以走这个if if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);
然后同第一次一样逐层返回,看到在索引为3的位置添加了"c++"
- 三、第三次添加——hashset.add("java")
也是直接看putVal()
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //1.此时的该索引已经不为null了所以走下面的else语句 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { //开发小技巧:在需要的时候再去创建对应的局部变量(辅助变量) HashMap.Node<K,V> e; K k; //辅助变量 //HashMap.Node<K,V> p // p = tab[i = (n - 1) & hash] //2. // 如果当前索引位置对应链表的第一个元素和准备添加的key的hash值一样 //并且满足下列条件之一 // (1)准备加入的key和p指向的Node节点的key是同一个对象 // (2)准备加入的key不为空且通过p指向的Node节点的key的equals()方法比较后相同 //则将e指向p if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //如果不满足第一个if则继续判断p是否为一棵红黑树 //如果是一棵红黑树,则调用putTreeVal()方法来进行添加 else if (p instanceof TreeNode) e = ((HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //如果table对应的索引位置已经是一个链表(也就是上面两个条件都不走),则用for循环比较 for (int binCount = 0; ; ++binCount) {//注意这里没有循环边界是一个死循环,只有满足一下两个条件之一才会break if ((e = p.next) == null) { //(1)依次和该链表的每个元素比较后,若都不相同,则加入到链表的最后然后break p.next = newNode(hash, key, value, null); //在将元素添加到链表后,立即判断该链表是否已经达到8个节点 //如果满足的话就调用treeifyBin(tab, hash)对当前链表进行树化(转换成红黑树) //在转换的时候还要进行一次判断 // if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY/*(64)*/) // resize(); // 如果上述条件成立则先使用 resize()对table进行扩容 // 只有table超过64的时候才会进行红黑树的转换 if (binCount >= TREEIFY_THRESHOLD /*(8)*/ - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && //(2)依次和该链表的每个元素比较,如果有相同的情况则直接break跳出 ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key //如果e不为空 V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); //则返回oldValue,也就是PERSENT,返回到add时则会返回一个false,添加失败 因为并没有增加节点此时就不走++modCount了
return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } }
-
小练习
- 练习1

package collection.set.hashset; import java.util.HashSet; import java.util.Iterator; import java.util.Objects; /** * @author 紫英 * @version 1.0 * @discription */ public class Homework01 { public static void main(String[] args) { HashSet set = new HashSet(); set.add(new Employee("jack",15)); set.add(new Employee("jack",15)); set.add(new Employee("jack",16)); set.add(new Employee("marry",15)); Iterator iterator = set.iterator(); while (iterator.hasNext()) { Object next = iterator.next(); System.out.println(next); } } } class Employee{ private String name; private int age; public Employee(String name, int age) { this.name = name; this.age = age; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Employee employee = (Employee) o; return age == employee.age && Objects.equals(name, employee.name); } @Override public int hashCode() { return Objects.hash(name, age); } @Override public String toString() { return "Employee{" + "name='" + name + '\'' + ", age='" + age + '\'' + '}'; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }
- 练习2

package collection.set.hashset; import java.util.HashSet; import java.util.Objects; /** * @author 紫英 * @version 1.0 * @discription */ public class Homework02 { public static void main(String[] args) { HashSet set = new HashSet(); set.add(new Employee02("jack", new MyDate(2000, 12, 26))); set.add(new Employee02("marry", new MyDate(2000, 12, 26))); set.add(new Employee02("jack", new MyDate(2000, 12, 26))); System.out.println(set); } } class Employee02 { private String name; private MyDate birthday; @Override public String toString() { return "name='" + name + '\'' + ", birthday=" + birthday + '}'; } public Employee02(String name, MyDate birthday) { this.name = name; this.birthday = birthday; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Employee02 that = (Employee02) o; return Objects.equals(name, that.name) && Objects.equals(birthday, that.birthday); } @Override public int hashCode() { return Objects.hash(name, birthday); } } class MyDate { int year; int month; int day; @Override public String toString() { return "{" + "year=" + year + ", month=" + month + ", day=" + day + '}'; } public MyDate(int year, int month, int day) { this.year = year; this.month = month; this.day = day; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; MyDate myDate = (MyDate) o; return year == myDate.year && month == myDate.month && day == myDate.day; } @Override public int hashCode() { return Objects.hash(year, month, day); } }
本文来自博客园,作者:紫英626,转载请注明原文链接:https://www.cnblogs.com/recorderM/p/15815360.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号