
利用mrunit进行hadoop map/reduce单元测试
Apache MRUnit 团队发布了 MRUnit 0.8.0-incubating 版本,这是 MRUnit 的第二个发行版本。
下载地址:
http://www.apache.org/dyn/closer.cgi/incubator/mrunit/
改进记录:
https://issues.apache.org/jira/browse/MRUNIT/fixforversion/12316359
MRUnit是由Couldera公司开发的专门针对Hadoop中 编写MapReduce单元测试的框架,基本原理是JUnit4和 EasyMock。MR就是Map和Reduce的缩写。MRUnit框架非常精简,其核心的单元测试依赖于JUnit。
而且MRUnit实现了一套 Mock对象来控制OutputCollector/Context的操作,从而可以拦截OutputCollector/Context的输出,和我们的期望结果进行比较,达到自动断言 的目的。mrunit单元测试简单入门
众所周知目前hadoop map/reduce编程调试非常麻烦,开发效率很低下。虽然有社区和公司作了一些开发调试工具,但总体仍然不尽人意。
这是利用mrunit单元测试工具进行的hadoop map/reduce单元测试。
一,编写自己的mapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
public class WordMapper extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text value,Context context)throws InterruptedException,IOException{
String[] line=value.toString().split(":");
context.write(new Text(line[0]),new Text(line[1]));
}
}
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
public class WordMapper extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text value,Context context)throws InterruptedException,IOException{
String[] line=value.toString().split(":");
context.write(new Text(line[0]),new Text(line[1]));
}
}
二,编写自己的reducer
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key,Iterable<Text> values,Context context)throws InterruptedException,IOException {
for(Text value:values){
context.write(value, key);
}
}
}
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key,Iterable<Text> values,Context context)throws InterruptedException,IOException {
for(Text value:values){
context.write(value, key);
}
}
}
三,编写map/reduce测试用例(针对新的map/reduce框架 mapreduce)import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.apache.hadoop.mrunit.mapreduce.ReduceDriver;
import org.junit.Before;
import org.junit.Test;
import org.apache.hadoop.mrunit.types.Pair;
@SuppressWarnings("deprecation")
public class TestExample {
private Mapper<LongWritable, Text, Text, Text> mapper;
private MapDriver<LongWritable, Text, Text, Text> driver1;
private ReduceDriver<Text, Text, Text, Text> driver2;
private Reducer<Text,Text,Text,Text>reducer;
/**
* 测试用例的mapper和reducer初始化。
* **/
@Before
public void setUp() {
mapper = new WordMapper();
reducer=new WordReducer();
driver1 =MapDriver.newMapDriver(mapper);
driver2 =ReduceDriver.newReduceDriver(reducer);
}
/**
* 测试WordMapper输入<1,"foo:aa">,输出是否是<"foo","aa">
* **/
@Test
public void testWordMapper() {
driver1.withInput(new Pair(new LongWritable(1L),new Text("foo:aa")))
.withOutput(new Text("foo"), new Text("aa")).runTest();
}
/**
* 测试WordReducer输入<"key",lst>,输出是否是{<"value1",key>,<"value2",key>}
* **/
@Test
public void testWordReducer(){
List<Text>lst=new ArrayList<Text>();
lst.add(new Text("value1"));
lst.add(new Text("value2"));
driver2.withInput(new Text("key"),lst);
driver2.withOutput(new Text("value1"), new Text("key"));
driver2.withOutput(new Text("value2"), new Text("key"));
driver2.runTest();
}
}
import java.util.List;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.apache.hadoop.mrunit.mapreduce.ReduceDriver;
import org.junit.Before;
import org.junit.Test;
import org.apache.hadoop.mrunit.types.Pair;
@SuppressWarnings("deprecation")
public class TestExample {
private Mapper<LongWritable, Text, Text, Text> mapper;
private MapDriver<LongWritable, Text, Text, Text> driver1;
private ReduceDriver<Text, Text, Text, Text> driver2;
private Reducer<Text,Text,Text,Text>reducer;
/**
* 测试用例的mapper和reducer初始化。
* **/
@Before
public void setUp() {
mapper = new WordMapper();
reducer=new WordReducer();
driver1 =MapDriver.newMapDriver(mapper);
driver2 =ReduceDriver.newReduceDriver(reducer);
}
/**
* 测试WordMapper输入<1,"foo:aa">,输出是否是<"foo","aa">
* **/
@Test
public void testWordMapper() {
driver1.withInput(new Pair(new LongWritable(1L),new Text("foo:aa")))
.withOutput(new Text("foo"), new Text("aa")).runTest();
}
/**
* 测试WordReducer输入<"key",lst>,输出是否是{<"value1",key>,<"value2",key>}
* **/
@Test
public void testWordReducer(){
List<Text>lst=new ArrayList<Text>();
lst.add(new Text("value1"));
lst.add(new Text("value2"));
driver2.withInput(new Text("key"),lst);
driver2.withOutput(new Text("value1"), new Text("key"));
driver2.withOutput(new Text("value2"), new Text("key"));
driver2.runTest();
}
}
四,mrunit进行单元测试时候需要引用的类库: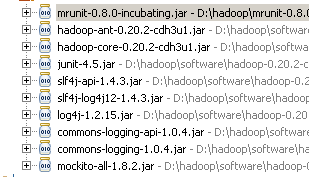
五,对于其他测试在hadoop map/reduce开发中的GroupingCompator,partitioner,combiner等算法以及configuration,都可以利用其进行单元测试,posted on 2012-03-22 08:36 reck for zhou 阅读(949) 评论(1) 编辑 收藏 举报


