
linux内核源码阅读-块设备驱动
来自:
https://in1t.top/2020/06/04/linux%E5%86%85%E6%A0%B8%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB-%E5%9D%97%E8%AE%BE%E5%A4%87%E9%A9%B1%E5%8A%A8/
开始 fs 模块之前,我发现如果对块设备/字符设备的驱动程序不了解的话,读 fs 代码时会困难重重。为了简化问题,本文及之后的 fs 模块都将只记录关于块设备(特指硬盘)的代码,先弄懂一个,剩下的读起来就轻松了。阅读本文或许会一头雾水,但和下篇文章联系起来看就会清楚许多了(x
块设备操作方式(以读数据为例)
提到 I/O 先来看一张图:
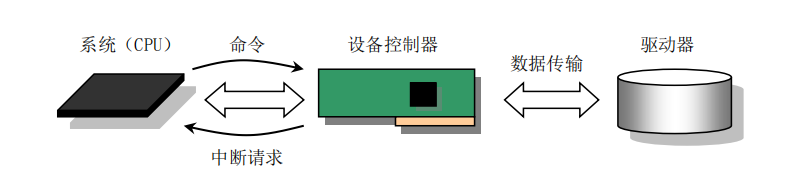
当程序需要从硬盘中读取数据(read 系统调用)时,缓冲区管理程序会先查询该数据块是否已经读入到缓冲区中。如果是,则直接将该缓冲头(涉及高速缓冲的管理方式,下篇文章将会记录)返回并唤醒等待此数据块的进程;否则调用 ll_rw_block 函数,告诉块设备驱动程序(内核代码)现在需要读数据块,该函数就会为其创建一个请求项,并挂入相应设备的请求队列,同时发出请求的进程会被挂起(不可中断睡眠态)。
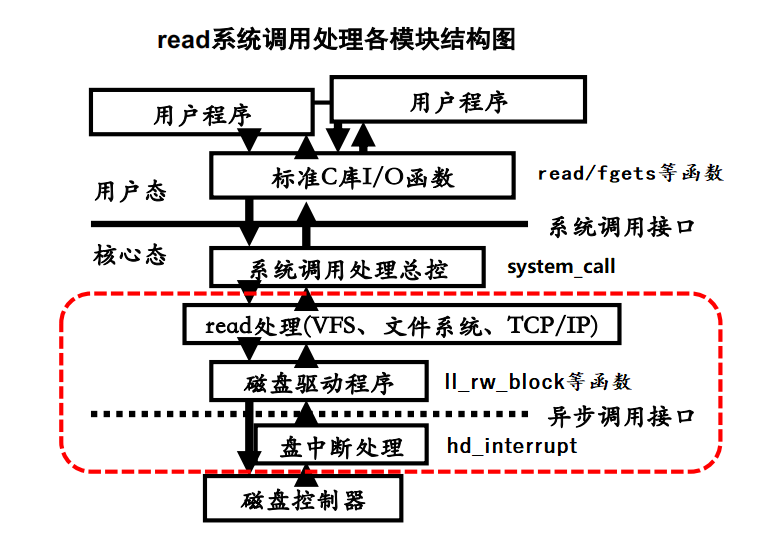
当请求被处理时,设备控制器根据请求项中的参数,向硬盘驱动器发送读指令,硬盘驱动器就会将数据读取到设备控制器的缓冲区中(注意此时原发出读盘请求的进程已被挂起,CPU 正在被其他进程占用)。当设备控制器检测到数据读取完毕,就会产生一个中断请求信号发往 CPU,CPU 在硬盘中断处理程序 hd_interrupt 中调用 read_intr 函数将数据从设备控制器的缓冲区搬到内存的高速缓冲区中,并让设备控制器开始处理下一个请求(如果有的话)。最后内核将高速缓冲中的数据拷贝到调用 read 函数时第二个参数指向的地址中去。用一张图来总结:
请求项与请求队列
请求项
请求项的数据结构如下:
1
|
// kernel/blk_drv/blk.h Line 23
|
为什么请求项已经可以通过 next 指针构成单项链表了,还需要一个数组来维护呢?采用数组加链表结构其实是为了满足两个目的:
- 数组结构使得在搜索空闲请求项的时候可以进行循环操作,搜索访问时间复杂度为常数
- 链表结构是为了满足电梯算法插入请求项的操作
请求队列
对于各种块设备,内核使用块设备表 blk_dev 来管理,每种块设备在块设备表中占有一项,相关数据结构如下:
1
|
// blk.h Line 45
|
再来通过一张图直观地感受这些数据结构之间的关系:
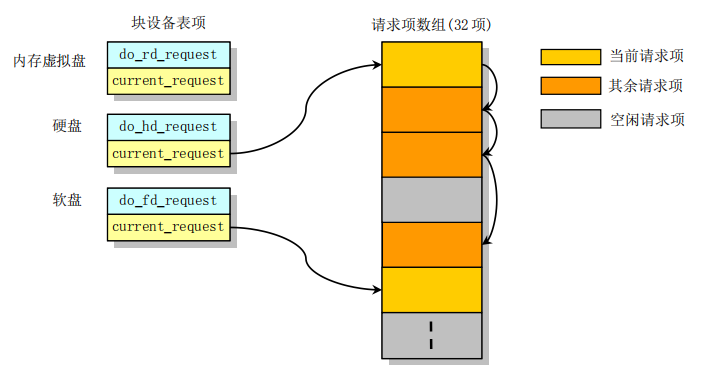
通过之前的描述不难看出,硬盘设备有 4 个请求,软盘设备有 1 个请求,虚拟盘暂无请求。下面正式开始块设备(仅硬盘)驱动程序部分源码的阅读
blk.h
1
|
// Line 1 |