
怎么学习 Linux 内核源码
=============================================================
来自:
https://www.qiyacloud.cn/2021/09/2021-09-13/
为什么 Linux 值得学习?
Linux 已经影响到所有人,安卓手机,嵌入式设备,物联网,服务器,虚拟化,容器 这些都离不开 Linux,Linux 是世界最知名的开源项目,为它贡献代码的人也是最聪明的那一小撮人。
学习理解它,会让程序猿对计算机的理解,对排查定位问题都有巨大的帮助。
奇伢经常分享 Linux 的深度原理,文章经常涉及到 Linux 内核的源码,今天简单讲讲奇伢的内核学习之旅。
不要盲目学习?
很多时候初学的朋友对内核源码真的是有心无力,因为太过巨大了,不知如何下手。
这个涉及到学习方法的问题,Linux 是一个巨大的项目,但也是世界上最优秀的项目,模块化非常好。做到了功能的内聚,往往不需要、看懂所有的代码,只需要看懂一个模块,也能把事情做好。
切记不要盲目扎到 Linux,一定要先确认目标,目光要聚焦,从一个小知识点开始,慢慢向外延伸。
聚焦可以来自很多方向:
- 来自工作中遇到的具体问题,比如 epoll 为啥高效,我总不理解? 那可以把目光聚焦在 fs/eventpoll.c 文件,从这里开始探索;
- 来自自我探索的内驱力,比如文件系统,但总感觉隔了一层面纱,想要彻底揭开它 ?那就去 fs 找具体的文件系统吧;
奇伢是做存储的,所以自然是从 fs 的角度来讲解学习。
下载源码
Linux 的镜像源码在 Github 上就有,下载地址:https://github.com/torvalds/linux ,可以把它 git clone 下来
讲讲层次
先看一眼根目录主要有啥:
tree -L 1
如下(省略了一些):
➜ linux git:(master) ✗ tree -L 1
.
├── Documentation # 内核的文档
├── arch # 具体硬件指令对应的模块
├── block # 块层模块相关代码
├── drivers # 跟硬件驱动相关的代码
├── fs # 文件系统相关代码
├── kernel # kernel 框架核心代码
├── mm # 内存管理模块
├── net # 网络协议栈相关代码
...
22 directories, 7 files
可以看见,都是按照非常内聚的功能划分的,就算从没看过内核的朋友,看一眼名字也大概清楚:
- cpu 指令对应的模块:arch/ ;
- 块层对应的模块:block/ ;
- 丰富多彩的硬件驱动:drivers/ ;
- 文件系统模块:fs/ ;
- 网络系统模块:net/ ;
Linux 是一个非常庞大的项目,一个人是无法把握住所有的细节的,但是按照模块抽象划分之后,理解和开发一个功能无需关注其他模块,只需要理解本模块就好。所以,对于个人来讲,去学习 Linux 是可以的。
其实,奇伢也没有把所有模块看一遍,奇伢是做存储的,所以只对 fs 和 block 感兴趣。
下面从 fs 的角度,来讲一下学习路径。
fs 子系统
奇伢是做存储的,自然是从 fs 开始,来看一下 fs 的目录:
➜ linux git:(master) ✗ tree -L 1 fs
fs
# 目录
├── btrfs # linux 的牛逼哄哄的文件系统
├── ceph # ceph 文件系统内核模块
├── debugfs # 专门调试的机制
├── ext2 # ext2 文件系统
├── ext4 # ext4 文件系统
├── fuse # fuse 文件系统内核模块
├── minix # linux 上最早的文件系统
├── netfs # 对网络的文件封装
├── nfs # nfs 文件系统内核模块
├── overlayfs # 这个有点印象吧,跟 docker 配合
├── proc # proc 文件系统
├── sysfs # sys 文件系统
├── xfs # xfs 文件系统
# 文件
├── open.c # 文件框架类代码(抽象的公共部分)
├── read_write.c
├── readdir.c
├── attr.c
├── stat.c
├── statfs.c
├── super.c
├── sync.c
├── xattr.c
├── fcntl.c
├── file.c
├── inode.c
├── ioctl.c
├── buffer.c
├── eventfd.c # eventfd 句柄实现;
├── eventpoll.c # epoll 机制的实现
├── signalfd.c # signalfd 句柄的实现;
├── select.c # select 机制的实现
├── timerfd.c # timerfd 句柄的实现
├── pipe.c # pipe 的实现
├── anon_inodes.c # 匿名句柄的实现
├── aio.c # aio 句柄的实现
├── userfaultfd.c # userfaultfd 句柄的实现
├── io_uring.c # io_uring 的实现
...
81 directories
目录 fs 下可以大概分为两部分:
- 第一部分是具体的文件系统的实现,比如 ext2,ext4,xfs 等文件系统,其代码都内聚在同名目录下;
- 另一部分是框架的公共代码部分,这个主要是以文件的形式直接在 fs 目录下,比如 open.c ,stat.c 等等;
眼尖的朋友可能会发现 eventpoll.c 这个文件,这就是大名鼎鼎的 epoll 机制。并且还有其他特色句柄的封装,比如 timerfd.c ,eventfd.c 等等。
文件系统怎么入门?
曾经,有个童鞋问过奇伢,他对 ext3,ext4 这类文件系统一直耿耿于怀,想要深究原理,但是苦于代码太多看不懂过,迟迟不的入门,怎么办?
也有朋友提过想系统学习一个文件系统,该从哪个模块入手?
如果是用户态文件系统,可以看试下 fuse ,看着几篇简单的文章:
如果是内核文件系统,奇伢墙裂推荐: minix 模块!
在 fs 目录下有一个叫做 minix 的目录,这是完整的极简文件系统的实现。文件系统只有 8 个 .c 文件,实现非常简单,并且是由 Linus Torvalds 完整编写的,minix 是从 Linux 诞生的以来最早的一个文件系统。
每个 minix 的文件至今还保留着 Linus Torvalds 的注释声明:
- Copyright (C) 1991, 1992 Linus Torvalds
要知道,Linux 发展这么久,Linus Torvalds 很少写代码了,很难找到这样完整由 Linus Torvalds 编写的系统了。
minix 文件系统是和 linux 一起诞生的,linux 上最早的文件系统。
提示:关于 minix 和 linux 的关系,感兴趣的朋友可以网上冲浪查一下。
推荐指数:
爆表
推荐理由:
- 非常简单,适合初学入门;
- 远古保留遗产,linux 出生就在,Linus Torvalds 亲自写的;
早年,奇伢也是从 minix 开始的内核之旅。
源码必须配利器
看 c 代码以前用的多就是 source insight ,但是软件版权不是每家公司都买得起,并且 si ,换了 mac 就用不了了,当前奇伢用的多的还是 vim 和 vscode 这两个工具。
vim
说实话,vim 看代码就够了,有两个重要的功能:
- 符号搜索;
- 函数跳转
主要推荐两个增强插件:ctags 和 cscope ,有了这两个功能,基本上应付常规的阅读问题不大。
如果你想要有目录的管理,那可以安装 NERDTree 插件,当然还有非常多的增强,这里就不列举了。
vscode
vscode 是奇伢现在用的比较多的源码工具,主要优点:
- 开源免费;
- 安装、扩展方便;
- 全平台统一;
安装一些实用插件之后,函数跳转,符号搜索,引用分析 都挺方便的。
不过奇伢还是要提醒一点,对于 Linux 这样的大项目,无论是 vim 还是 vscode 分析整个项目都挺慢的,这个要理解下。
好一点的实践是小模块的分析,比如,有些时候 ctags 只建立 fs 目录下的符号表,这样速度也快点。
总结
- Linux 值得学习,但要确认目标,要聚焦,比如奇伢是做存储的,聚焦在 fs 这个模块;
- 文件系统从 fs 目录入手,各色文件系统,各色句柄封装,epoll,aio,io_uring 都在这里;
- 存储入门,墙裂推荐 minix 模块的学习,极简文件系统实现,Linus Torvalds 编写并保留,linux 的远古遗产,极具象征意义;
- 源码阅读配利器,vim 、vscode 都可以;
=============================================================
https://in1t.top/2020/03/19/linux%E5%86%85%E6%A0%B8%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB-%E5%BC%80%E5%A7%8B%E4%B9%8B%E5%89%8D/
在开始阅读系统引导启动部分的内核代码之前,需要对以下内容进行了解:
- Linux 中断机制
- Linux 内核源码目录结构
- 磁盘结构及 INT 0x13
PS. 这个系列的文章将会对 Linux 0.11 版本的源码进行分析,资源在文末
中断机制
硬件原理
微型计算机通常包括 I/O(输入输出) 设备,处理器向设备提供服务的方式有两种
- 主动:处理器挨个地去询问系统中的设备是否需要服务,这种方式称为 轮询,缺点是太耗费系统资源
- 被动:当设备需要服务时,向处理器提出请求,处理器响应提出的请求为其提供服务
当设备向处理器提出请求,处理器在执行完当前的一条指令后立刻响应设备请求,并转到相应的服务程序去执行。执行完服务程序后,又返回到之前被打断的位置继续执行,这就是 中断(Interrupt),设备向处理器发出的服务请求称为 中断请求(IRQ)
处理器有一个 INT 引脚专门用来接收中断请求,但设备繁多,如果每个设备的中断请求直接给到处理器,当有多个请求同时到达时,处理器不知道该优先为谁提供服务
因此,需要有个大哥来管理这些设备的中断请求,这个大哥名叫 可编程中断控制器(PIC),PIC 会连接到处理器的 INT 引脚。设备的中断请求都会先给到 PIC,由 PIC 来筛选优先级高的中断请求递交给 CPU,如果 CPU 正在为一个设备提供中断服务,PIC 还会将选出的请求与正在执行的服务程序的优先级进行比较,以确定是否嵌套中断
当 PIC 向 INT 引脚发出中断信号后,处理器立即停下手头的工作,询问需要执行什么中断服务,PIC 通过数据总线发送与中断请求对应的 中断号,处理器拿着中断号去中断向量表(或 32 位保护模式下的中断描述符表)中查询服务程序的入口,进而跳去执行服务程序
中断同样可以由软件通过使用 int 指令来调用中断服务程序,PC/AT 系列微机提供 256 个中断的支持,大部分为软件中断或异常,异常 是处理器在处理过程中检测到错误而产生的中断
中断子系统
80X86 组成的微机系统中采用编号为 8259A 的 PIC 芯片,每个芯片可以管理 8 个中断源,通过多片级联的方式可以最多管理 64(8*8) 个中断向量的系统
PC/AT 系列兼容机中使用了两片 8259A 级联,管理 15 级中断向量,结构如图:
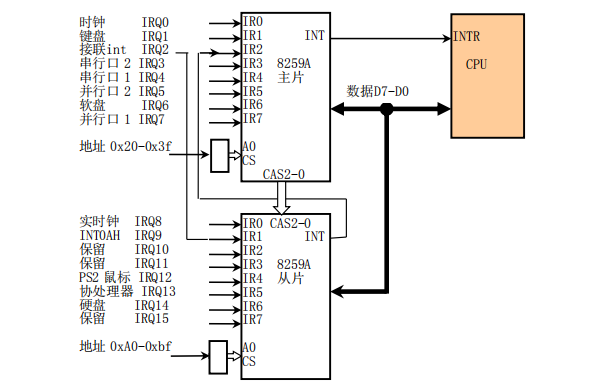
左边两片分别为 8259A 的主片和从片,从片通过自己的 INT 引脚连接到主片的 IR2 引脚。使用 IRQ2 引脚的设备又作为从片 IR1 引脚的输入,表示将使用 IRQ2 的设备的 IRQ2 引脚重定向到 IRQ9 引脚上。同时,主片的端口基址在 0x20,从片在 0xA0
8259A 芯片可分为编程状态和操作状态
- 编程状态下,由处理器使用 IN 或 OUT 指令对其进行初始化编程
- 操作状态下,响应设备中断请求,选出最高优先级中断,并通知处理器外中断的到来,处理器响应后,中断号由数据总线 D7-D0 送出,处理器由此获取中断向量值,执行中断服务程序
中断向量表
当 80X86 微机启动时,BIOS 中的程序会在物理内存起始处(0)初始化中断向量表,该表包含两个 8259A 芯片支持的 16 个硬件中断向量和 BIOS 提供的中断号为 0x10 ~ 0x1F 的中断调用功能向量,每个表项占 4 字节。对于没有使用的向量则填入临时的哑中断服务程序的地址
对于 Linux 而言,除了在开机时加载引导扇区(bootsect.s)及保存重要信息(setup.s)所用到的 BIOS 中断功能,之后 Linux 会在 setup.s 程序中重新初始化 8259A 芯片,并在 head.s 中重新构建一张中断描述符表,将 BIOS 提供的中断向量表覆盖
内核源码目录结构
一切尽在图中:

磁盘结构
关于磁盘,主要弄清楚几个概念:
- 磁头(head)
- 磁道(track)
- 扇区(sector)
- 柱面(cylinder)
如图,这是一个容量为 1.44 MB 的软盘:
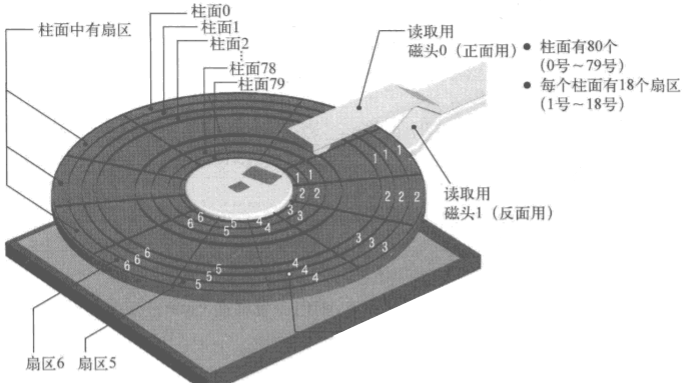
一个磁盘面分正反两面,所以读取用的 磁头 也需要两个。从图中可以看到,盘面中一圈圈灰色同心圆为一条条 磁道,从圆心向外画射线,可以将磁道划分为若干个弧段,每个磁道上一个弧段称为一个 扇区。一个 柱面 包含了所有具有相同编号的磁道(从外向内编号,起始为 0)
一张这样的软盘有 2 个磁头,80 个柱面,每个柱面包含18 个扇区(每个扇区 512 字节),所以它的容量为:
2 * 80 * 18 * 512 = 1, 474, 560 Bytes = 1, 440 KB = 1.44 MB
系统启动时的引导扇区就位于 C0-H0-S1(柱面 0,磁头 0,扇区 1)
若想读写相邻两个磁道的数据,顺序为先读写第一个磁道磁头为 0(正面) 的所有扇区,再读写第一个磁道磁头为 1(反面) 的所有扇区,接着转去第二个磁道按照同样的顺序读写
INT 0X13 指令
该指令使用 BIOS 提供的磁盘操作功能,通过几个通用寄存器来传递参数
功能号:
- AH = 0x02:读盘
- AH = 0x03:写盘
- AH = 0x04:校验
- AH = 0x08:取磁盘参数
- AH = 0x0c:寻道
- AH = 0x15:取磁盘类型
AH 为 2 时:
-
参数:
- AL = 读出的扇区数(只能同时处理连续的扇区)
- CH = 磁道号低八位
- CL = 起始扇区号(0 ~ 5 位),磁道号高两位(6 ~ 7 位)
- DH = 磁头号
- DL = 驱动器号
- ES:BX = 缓冲地址(校验及寻道时不使用)
-
返回值:
- FLAGS.CF = 0:处理时没有发生错误,AH = 0
- FLAGS.CF = 1:发生了错误,错误号存在 AH 中
AH 为 8 时:
- 参数:
- DL = 驱动器号
- 返回值:
- FLAGS.CF = 0:处理时没有发生错误,AH = 0
- FLAGS.CF = 1:发生了错误,错误号存在 AH 中
- AL = 0
- BL = 驱动器类型(AT / PS2)
- CH = 最大磁道号的低8位
- CL = 每磁道最大扇区数(0-5bit),最大磁道号高2位(6-7bit)
- DH = 最大磁头数
- DL = 驱动器数量
- ES:DI:软驱磁盘参数表
AH 为 0x15 时:
- 参数:
- DL = 驱动器号
- 0x80 指第一个硬盘
- 0x81 指第二个硬盘
- DL = 驱动器号
- 返回值:
- AH = 类型码
- 0:没有这个盘,CF 置位
- 1:软驱,没有 change-line 支持
- 2:软驱(或其他可移动设备),有 change-line 支持
- 3:硬盘
- AH = 类型码
资源
提取码:sgd1
=============================================================
https://in1t.top/2020/05/04/minix-1-0-%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F/ minix-1-0-文件系统
https://in1t.top/2020/04/27/linux%E5%86%85%E6%A0%B8%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB-mm/ linux内核源码阅读-mm
https://in1t.top/2020/03/20/linux%E5%86%85%E6%A0%B8%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB-%E5%BC%95%E5%AF%BC%E5%90%AF%E5%8A%A8%E9%83%A8%E5%88%86%EF%BC%88%E4%B8%80%EF%BC%89/ linux内核源码阅读-引导启动部分(一)
https://in1t.top/2020/06/04/linux%E5%86%85%E6%A0%B8%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB-%E5%9D%97%E8%AE%BE%E5%A4%87%E9%A9%B1%E5%8A%A8/ linux内核源码阅读-块设备驱动
https://in1t.top/2020/06/06/linux%E5%86%85%E6%A0%B8%E6%BA%90%E7%A0%81%E9%98%85%E8%AF%BB-fs/ linux内核源码阅读-fs
=============================================================
高速缓冲区的管理方式
整个高速缓冲区被划分为 1024 字节一块的缓冲块,正好与块设备上的磁盘逻辑块大小相同。在高速缓冲区初始化时,初始化程序分别从缓冲区的两端开始,分别同时设置缓冲头和划分出对应的缓冲块,如图所示:
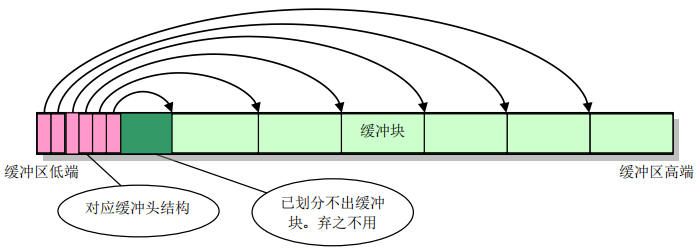
缓冲头是定义在 include/linux/fs.h 中的一个结构体,用于描述对应缓冲块的各种属性,并用于将所用缓冲头连成链表。缓冲块的划分一直持续到缓冲区中没有足够的内存再划分出缓冲块为止
缓冲头的定义:
1
|
// include/linux/fs.h Line 68
|
b_blocknr 与 b_dev 唯一确定了缓冲块中的数据对应的块设备和数据块
b_count 字段表示引用该块的进程数,当其不为 0 时,缓冲管理程序就不能释放该块。程序申请读/写硬盘上的一个块时,会先在高速缓冲中申请一个块,若在 hash 表中能得到指定的块,则该块的 b_count 增加 1,否则表示缓冲块是重新申请得到的,该块的 b_count 置为 1。当程序释放一个块时,该块的 b_count 减 1
b_lock 为锁定标志,当其为 1 时,表示驱动程序正在对该缓冲块内容进行修改。更新缓冲块中的数据时,进程会主动睡眠,此时其他进程就有访问同样缓冲块的机会,因此在睡眠前该缓冲块对应缓冲头的 b_lock 字段被置 1
b_dirt 为修改标志,表示缓冲块中的内容是否与块设备上对应数据块的内容不同。b_uptodate 为数据更新标志,用于说明缓冲块中的数据是否有效。
- 初始化或释放块时,这两个标志均置为 0,表示该缓冲块中的数据无效
- 当数据被写入缓冲块但还没有被写入块设备中时,b_dirt = 1,b_uptodate = 0
- 当数据被写入块设备或刚从块设备中读入缓冲块时,b_dirt = 0,b_uptodate = 1
- 在新申请一个缓冲块时,这两个标志均为 1
b_prev_free 与 b_next_free 字段用于构建空闲缓冲块对应缓冲头的双向链表,如图:

b_prev 与 b_next 字段用于构建 hash 表。buffer.c 中使用具有 307 个缓冲头指针项的 hash 数组表结构,从而达到快速而有效地在缓冲区中寻找请求的数据块是否已经被读入到缓冲区中的目的。这两个字段就是用于 hash 表中国散列在同一项上多个缓冲块之间的双向链接,如图所示:

图中的双箭头实线表示散列在同一 hash 表项中缓冲头结构体之间的双向链接指针。虚线表示缓冲区中所有缓冲块组成的一个双向循环链表(即所谓的空闲链表),实际上这个双向链表是最近最少使用链表(LRU)
读取文件的完整过程
前面也铺垫的差不多了,接下来,通过一个文件从打开(open)、读取(read)到关闭(close)的过程来整体把握文件系统,其中涉及的一些较为底层的函数现在只需知道功能即可
首先修改一下 main.c 的 init 函数
1
|
void init(void)
|
上面的代码实现打开 hello.c 并获取其句柄、读取并输出其内容及关闭文件,运行结果:

open
open 实际上是一个系统调用,在 system_call 中调用 sys_open,参数 filename 为要打开的文件名字符串指针;flag 为打开文件的标志(只读、只写、可读可写等);mode 只有在创建文件时才会被用于指定文件的许可属性(如 0664)
1
|
// fs/open.c Line 138
|
sys_open 函数还没有结束,但这里有必要打断一下,来说说 task_struct 中的 filp 字段与文件表数组 file_table 的关系,及 close_on_exec 字段的含义;之后深入 open_namei 函数去查看其实现细节
-
flip 与 file_table
os 维护着一张元素个数为 64(NR_FILE)的打开文件表,名为 file_table,该数组的元素类型为 file 结构体,记录着所有已被打开的文件的信息;每个进程的 task_struct 结构体中都有一个元素个数为 20(NR_OPEN)的 file 结构体指针数组,如果其中的某一项非空(NULL),其必定指向 file_table 数组中的一个 file 结构体,表示该进程捏着这个文件的句柄,可以对其进行合法的操作
那么现在就好解释为什么标准输入的句柄是 0,标准输出的句柄是 1 了。还记得 init 函数中的操作吗:
(void) open("/dev/tty0",O_RDWR,0);该函数以可读可写模式打开终端设备,此时 1 号进程的 filp 数组为空,故 filp[0] 为 sys_open 中找到的空闲项。在 open 系统调用成功返回后,file_table 中就会有一项 tty0 的 file 结构体,而 1 号进程的 filp[0] 就指向该结构体。之后 init 调用(void) dup(0);复制文件句柄,即使得 filp[1] 也同样指向 tty0 的 file结构体。以此类推,标准错误的句柄在第二次 dup 后应该为 2。你会发现,所谓的文件句柄,其实是进程 task_struct 结构体中 filp 数组的下标 -
close_on_exec
task_struct 中该字段用于确定在调用 execve 时需要关闭的文件句柄,类型为
unsigned long,每一个比特位对应一个打开着的文件描述符。当进程创建出子进程后,往往会调用 execve 加载新的程序,此时若文件句柄在 close_on_exec 中对应的比特位为 1,则执行 do_execve 时,该文件将被关闭。在打开一个文件时,默认情况下文件句柄在子进程中也处于打开状态
下面来研究 open_namei 是如何通过 pathname 来找到文件对应 i 节点的,粗略的过程及目录项结构体的定义在 Minix 1.0 文件系统 一文中有所提及,此时 pathname 为 “/usr/root/hello.c”
1
|
// fs/namei.c Line 337
|
那么根据 “/usr/root/hello.c” 是怎样找到 “/usr/root” 的 i 节点指针的呢?其步骤类似 open_namei 中已知 “/usr/root” 的 i 节点指针(调用完 dir_namei 函数),获取 “hello.c” 的 i 节点指针。现已知根目录 “/“ i 节点指针,通过调用 find_entry,找到 “usr” 对应的目录项,从而得知其 i 节点号,再调用 iget 即可获取 “/usr” 的 i 节点指针;第二次调用 find_entry 在 “/usr” 目录下找到 “root” 对应的目录项,从而得知 “/usr/root” 的 i 节点号,调用 iget 获取 “/usr/root” 的 i 节点指针。理所当然地,能想到应该使用一个 whlie 循环来完成上述操作,下面是 dir_namei 函数的代码,其调用 get_dir 函数,在 get_dir 中通过 while 循环来获取 “/usr/root” 的 i 节点指针
1
|
// fs/namei.c Line 278
|
至此,不再深入,回到 sys_open 函数。之前调用 open_namei 时,返回的 i 节点指针存储在 inode 中,现在要根据 i_mode 字段判断该文件的类型,对于不同类型的文件,需要做一些处理
1
|
// fs/open.c Line 163
|
此时返回的 fd 应该为 3
read
read 也是一个系统调用,处理函数为 sys_read,现在要从已打开的 “/usr/root/hello.c” 中读取 79 个字符
1
|
// fs/read_write.c Line 55
|
因为 “/usr/root/hello.c” 是一个普通文件,所以应该调用 file_read 函数
1
|
// fs/file_dev.c Line 17
|
file_read 还没有结束,先来看看 bread 函数的实现细节,该函数的作用是从指定设备号的设备中读取指定块号的数据到高速缓冲块中,返回值是缓冲块对应的缓冲头
1
|
// fs/buffer.c Line 270 |