

c++ 异常处理
=================================
【C++11】std::runtime_error的使用
一、概要
std::runtime_error:运行时错误异常类,只有在运行时才能检测到的错误,继承于std::exception,它的声明在头文件中。
std::runtime_error也用作几个运行时错误异常的基类,包括std::range_error(生成的结果超出了有意义的值域范围)、overflow_error(上溢)、underflow_error(下溢)、system_error(系统错误)。std::runtime_error类没有默认构造函数,有两个声明为explicit的构造函数,一个接收参数为const char*类型,一个接收参数为const std::string&,这些实参负责提供关于错误的更多信息。std::runtime_error类还有一个继承自std::exception类的what虚函数,返回关于异常的一些文本信息。
以下内容摘自:《C++Primer(Fifth Edition)》
异常是指在程序运行时发生的反常行为,这些行为超出了函数正常功能的范围。典型的异常包括失去数据库连接以及遇到意外输入等。当程序的某部分检测到一个它无法处理的问题时,需要用到异常处理。此时,检测出问题的部分应该发出某种信号以表明程序遇到了故障,无法继续下去了,而且信号的发出方无须知道故障将在何处得到解决。一旦发出异常信号,检测出问题的部分也就完成了任务。
二、相关操作
异常提供了一种转移程序控制权的方式。C++异常处理涉及到三个关键字:try、catch、throw。关于这三个关键字的简单使用可以参考: http://blog.csdn.net/fengbingchun/article/details/65939258
异常处理机制为程序中异常检测和异常处理这两部分的协作提供支持。在C++语言中,异常处理包括:
-
throw表达式(throw expression):异常检测部分使用throw表达式来表示它遇到了无法处理的问题。throw引发(raise)异常。throw表达式包含关键字throw和紧随其后的一个表达式,其中表达式的类型就是抛出的异常类型。throw表达式后面通常紧跟一个分号,从而构成一条表达式语句。抛出异常将终止当前的函数,并把控制权转移给能处理该异常的代码。 -
try语句块(try block):异常处理部分使用try语句块处理异常。try语句块以关键字try开始,并以一个或多个catch子句(catch clause)结束。try语句块中代码抛出的异常通常会被某个catch子句处理。因为catch子句处理异常,所以它们也被称作异常处理代码(exception handler)。catch子句包括三部分:关键字catch、括号内一个(可能未命名的)对象的声明(称作异常声明,exception declaration)以及一个块。当选中了某个catch子句处理异常之后,执行与之对应的块。catch一旦完成,程序跳转到try语句块最后一个catch子句之后的那条语句继续执行。一如往常,try语句块声明的变量在块外部无法访问,特别是在catch子句内也无法访问。如果一段程序没有try语句块且发生了异常,系统会调用terminate函数并终止当前程序的执行。 -
一套异常类(exception class):用于在throw表达式和相关的catch子句之间传递异常的具体信息。
函数在寻找处理代码的过程中退出:寻找处理代码的过程与函数调用链刚好相反。当异常被抛出时,首先搜索抛出该异常的函数。如果没有找到匹配的catch子句,终止该函数,并在调用该函数的函数中继续寻找。如果还是没有找到匹配的catch子句,这个新的函数也被终止,继续搜索调用它的函数。以此类推,沿着程序的执行路径逐层回退,直到找到适当类型的catch子句为止。如果最终还是没能找到任何匹配的catch子句,程序转到名为terminate的标准库函数。该函数的行为与系统有关,一般情况下,执行该函数将导致程序非正常退出。
如果一段程序没有try语句块且发生了异常,系统会调用terminate函数并终止当前程序的执行。
- 1
那些在异常发生期间正确执行了”清理”工作的程序被称作异常安全(exception safe)的代码。编写异常安全的代码非常困难。
- 1
三、 标准异常
标准异常:C++标准库定义了一组类,用于报告标准库函数遇到的问题。这些异常类也可以在用户编写的程序中使用,它们分别定义在4个头文件中:
-
(1)、exception头文件定义了最通常的异常类exception,它只报告异常的发生,不提供任何额外的信息。
-
(2)、stdexcept头文件定义了几种常用的异常类,如下:

-
(3)、
new头文件定义了bad_alloc异常类型。 -
(4)、
type_info头文件定义了bad_cast异常类型。
标准库异常类只定义了几种运算,包括创建或拷贝异常类型的对象,以及为异常类型的对象赋值。我们只能以默认初始化的方式初始化exception、bad_alloc和bad_cast对象,不允许为这些对象提供初始值。其它异常类型的行为则恰恰相反:应该使用string对象或者C风格字符串初始化这些类型的对象,但是不允许使用默认初始化的方式。当创建此类对象时,必须提供初始值,该初始值含有错误相关的信息。
异常类型只定义了一个名为what的成员函数,该函数没有任何参数,返回值是一个指向C风格字符串的const char*。该字符串的目的是提供关于异常的一些文本信息。what函数返回的C风格字符串的内容与异常对象的类型有关。如果异常类型有一个字符串初始值,则what返回该字符串。对于其它无初始值的异常类型来说,what返回的内容由编译器决定。
异常处理(exception handling)机制允许程序中独立开发的部分能够在运行时就出现的问题进行通信并做出相应的处理。异常使得我们能够将问题的检测与解决过程分离开来。程序的一部分负责检测问题的出现,然后解决该问题的任务传递给程序中的另一部分。检测环节无须知道问题处理模块的所有细节,反之亦然。
抛出异常
-
抛出异常:在C++语言中,我们通过抛出(throwing)一条表达式来引发(raised)一个异常。被抛出的表达式的类型以及当前的调用链共同决定了哪段处理代码(handler)将被用来处理该异常。被选中的处理代码是在调用链中与抛出对象类型匹配的最近的处理的代码。其中,根据抛出对象的类型和内容,程序的异常抛出部分将会告知异常处理部分到底发生了什么错误。当执行一个throw时,跟在throw后面的语句将不再被执行,throw语句的用法有点类似于return语句:它通常作为调节语句的一部分或者作为某个函数的最后(或者唯一)一条语句。相反,程序的控制权从throw转移到与之匹配的catch模块。该catch可能是同一个函数中的局部catch,也可能位于直接或间接调用了发生异常的函数的另一个函数中。
当抛出一个异常后,程序暂停当前函数的执行过程并立即开始寻找与异常匹配的catch子句。当throw出现在一个try语句块内时,检查与该try块关联的catch子句。如果找到了匹配的catch,就使用该catch处理异常。如果这一步没找到匹配的catch且该try语句嵌套在其它try块中,则继续检查与外层try匹配的catch子句。如果还是找不到匹配的catch,则退出当前的函数,在调用当前函数的外层函数中继续寻找,依次类推。这一过程被称为栈展开(stack unwinding)过程。栈展开过程沿着嵌套函数的调用链不断查找,直到找到了与异常匹配的catch子句为止:或者也可能一直没找到匹配的catch,则退出主函数后查找过程终止。
假设找到了一个匹配的catch子句,则程序进入该子句并执行其中的代码。当执行完这个catch子句后,找到与try块关联的最后一个catch子句之后的点,并从这里继续执行。如果没找到匹配的catch子句,程序将退出。因为异常通常被认为是妨碍程序正常执行的事件,所以一旦引发了某个异常,就不能对它置之不理。当找不到匹配的catch时,程序将调用标准库函数terminate,terminate负责终止程序的执行过程。
Note:一个异常如果没有被捕获,则它将终止当前的程序。
- 1
-
栈展开过程中对象被自动销毁:在栈展开过程中,位于调用链上的语句块可能会提前退出。通常情况下,程序在这些块中创建了一些局部对象。块退出后它的局部对象也将随之销毁,这条规则对于栈展开过程同样适用。如果在栈展开过程中退出了某个块,编译器将负责确保在这个块中创建的对象能被正确地销毁。如果某个局部对象的类型是类类型,则该对象的析构函数将被自动调用。与往常一样,编译器在销毁内置类型的对象时不需要做任何事情。 -
析构函数与异常:析构函数总是会被执行的。出于栈展开可能使用析构函数的考虑,析构函数不应该抛出不能被它自身处理的异常。换句话说,如果析构函数需要执行某个可能抛出异常的操作,则该操作应该被放置在一个try语句块当中,并且在析构函数内部得到处理。一旦在栈展开的过程中析构函数抛出了异常,并且析构函数自身没能捕获到异常,则程序将被终止。
异常对象(exception object):是一种特殊的对象,编译器使用异常抛出表达式来对异常对象进行拷贝初始化。因此,throw语句中的表达式必须拥有完全类型。而且如果该表达式是类类型的话,则相应的类必须含有一个可访问的析构函数和一个可访问的拷贝或移动构造函数。如果该表达式是数组类型或函数类型,则表达式将被转换成与之对应的指针类型。异常对象位于由编译器管理的空间中,编译器确保无论最终调用的是哪个catch子句都能访问该空间。当异常处理完毕后,异常对象被销毁。如果退出了某个块,则同时释放块中局部对象使用的内存。因此,抛出一个指向局部对象的指针几乎肯定是一种错误的行为。出于同样的原因,从函数中返回指向局部对象的指针也是错误的。当我们抛出一条表达式时,该表达式的静态编译时类型决定了异常对象的类型。如果一条throw表达式解引用一个基类指针,而该指针实际指向的是派生类对象,则抛出的对象将被切掉一部分,只有基类部分被抛出。
捕获异常
-
捕获异常:
catch子句(catch clause)中的异常声明(exception declaration)看起来像是只包含一个形参的函数形参列表。像在形参列表中一样,如果catch无须访问抛出的表达式的话,则我们可以忽略捕获形参的名字。声明的类型决定了处理代码所能捕获的异常类型.这个类型必须是完全类型,它可以是左值引用,但不能是右值引用。当进入一个
catch语句后,通过异常对象初始化异常声明中的参数。和函数的参数类似,如果catch的参数类型是非引用类型,则该参数是异常对象的一个副本,在catch语句内改变参数实际上改变的是局部副本而非异常对象本身;相反,如果参数是引用类型,则和其它引用参数一样,该参数是异常对象的一个别名,此时改变参数也就是改变异常对象。catch的参数还有一个特性也与函数的参数非常类似:如果catch的参数是基类类型,则我们可以使用其派生类类型的异常对象对其进行初始化。此时,如果catch的参数是非引用类型,则异常对象将被切掉一部分,这与将派生类对象以值传递的方式传给一个普通函数差不多。另一方面,如果catch的参数是基类的引用,则该参数将以常规方式绑定到异常对象上。异常声明的静态类型将决定catch语句所能执行的操作。如果catch的参数是基类类型,则catch无法使用派生类特有的任何成员。
通常情况下,如果catch接受的异常与某个继承体系有关,则最好将该catch的参数定义成引用类型。
查找匹配的处理代码:在搜索catch语句的过程中,我们最终找到的catch未必是异常的最佳匹配。相反,挑选出来的应该是第一个与异常匹配的catch语句。因此,越是专门的catch越应该置于整个catch列表的前端。因为catch语句是按照其出现的顺序逐一进行匹配的,所以当程序使用具有继承关系的多个异常时必须对catch语句的顺序进行组织和管理,使得派生类异常的处理代码出现在基类异常的处理代码之前。
与实参和形参的匹配规则相比,异常和catch异常声明的匹配规则受到更多限制。此时,绝大多数类型转换都不被允许,除了一些极细小的差别之外,要求异常的类型和catch声明的类型是精确匹配的:
-
(1)、允许在非常量向常量的类型转换,也就是说,一条非常量对象的throw语句可以匹配一个接受常量引用的catch语句。
-
(2)、允许从派生类向基类的类型转换。
-
(3)、数组被转换成指向数组(元素)类型的指针,函数被转换成指向该函数类型的指针。
除此之外,包括标准算术类型转换和类类型转换在内,其它所有转换规则都不能在匹配catch的过程中使用。
如果在多个catch语句的类型之间存在着继承关系,则我们应该把继承链最低端的类(most derived type)放在前面,而将继承链最顶端的类(least derived type)放在后面。
重新抛出:有时,一个单独的catch语句不能完整地处理某个异常。在执行了某些校正操作之后,当前的catch可能会决定由调用链更上一层的函数接着处理异常。一条catch语句通过重新抛出(rethrowing)的操作将异常传递给另外一个catch语句。这里的重新抛出仍然是一条throw语句,只不过不包含任何表达式:throw;
空的throw语句只能出现在catch语句或catch语句直接或间接调用的函数之内。如果在处理代码之外的区域遇到了空throw语句,编译器将调用terminate。
一个重新抛出语句并不指定新的表达式,而是将当前的异常对象沿着调用链向上传递。
很多时候,catch语句会改变其参数的内容。如果在改变了参数的内容后catch语句重新抛出异常,则只有当catch异常声明是引用类型时我们对参数所做的改变才会被保留并继续传播。
捕获所有异常的处理代码:为了一次性捕获所有异常,我们使用省略号作为异常声明,这样的处理代码称为捕获所有异常(catch-all)的处理代码,形如catch(…)。一条捕获所有异常的语句可以与任意类型的异常匹配。
catch(…)通常与重新抛出语句一起使用,其中catch执行当前局部能完成的工作,随后重新抛出异常。
- 1
catch(…)既能单独出现,也能与其它几个catch语句一起出现。
- 1
如果catch(…)与其它几个catch语句一起出现,则catch(…)必须在最后的位置。出现在捕获所有异常语句后面的catch语句将永远不会被匹配。
- 1
函数try语句块与构造函数:通常情况下,程序执行的任何时刻都可能发生异常,特别是异常可能发生在处理构造函数初始值的过程中。构造函数在进入其函数体之前首先执行初始值列表。因为在初始值列表抛出异常时构造函数体内的try语句块还未生效,所以构造函数体内的catch语句无法处理构造函数初始值列表抛出的异常。要想处理构造函数初始值抛出的异常,我们必须将构造函数写出函数try语句块(也称为函数测试块,function try block)的形式。函数try语句块使得一组catch语句既能处理构造函数体(或析构函数体),也能处理构造函数的初始化过程(或析构函数的析构过程)。
在初始化构造函数的参数时也可能发生异常,这样的异常不属于函数try语句块的一部分。函数try语句块只能处理构造函数开始执行后发生的异常。和其它函数调用一样,如果在参数初始化的过程中发生了异常,则该异常属于调用表达式的一部分,并将在调用者所在的上下文中处理。
处理构造函数初始值异常的唯一方法是将构造函数写成函数try语句块。
- 1
四、noexcept与 异常的关系
noexcept异常说明:在C++11新标准中,我们可以通过提供noexcept说明(noexcept specification)指定某个函数不会抛出异常。其形式是关键字noexcept紧跟在函数的参数列表后面,用以标识该函数不会抛出异常。
对于一个函数来说,noexcept说明要么出现在该函数的所有声明语句和定义语句中,要么一次也不出现。该说明应该在函数的尾置返回类型之前。我们也可以在函数指针的声明和定义中指定noexcept。在typedef或类型别名中则不能出现noexcept。在成员函数中,noexcept说明符需要跟在const及引用限定符之后,而在final、override或虚函数的=0之前。
违反异常说明:如果一个函数在说明了noexcept的同时又含有throw语句或者调用了可能抛出异常的其它函数,编译器将顺利编译通过,并不会因为这种违反异常说明的情况而报错(不排除个别编译器会对这种用法提出警告)。一旦一个noexcept函数抛出了异常,程序就会调用terminate以确保遵守不在运行时抛出异常的承诺。noexcept可以用在两种情况下,一是我们确认函数不会抛出异常;二是我们根本不知道该如何处理异常。
通常情况下,编译器不能也不必在编译时验证异常说明。
如果函数被设计为是throw()的,则意味着该函数将不会抛出异常:void f(int) throw();
异常说明的实参:noexcept说明符接受一个可选的实参,该实参必须能转换为bool类型:如果实参是true,则函数不会抛出异常;如果实参是false,则函数可能抛出异常。
noexcept运算符:noexcept说明符的实参常常与noexcept运算符(noexcept orerator)混合使用。noexcept运算符是一个一元运算符,它的返回值是一个bool类型的右值常量表达式,用于表示给定的表达式是否会抛出异常。和sizeof类似,noexcept也不会求其运算对象的值。
noexcept有两层含义:当跟在函数参数列表后面时它是异常说明符;而当作为noexcept异常说明的bool实参出现时,它是一个运算符。
异常说明与指针、虚函数和拷贝控制:尽管noexcept说明符不属于函数类型的一部分,但是函数的异常说明仍然会影响函数的使用。函数指针及该指针所指的函数必须具有一致的异常说明。也就是说,如果我们为某个指针做了不抛出异常的说明,则该指针将只能指向不抛出异常的函数。相反,如果我们显示或隐式地说明了指针可能抛出异常,则该指针可以指向任何函数,即使是承诺了不抛出异常的函数也可以。
如果一个虚函数承诺了它不会抛出异常,则后续派生出来的虚函数也必须做出同样的承诺;与之相反,如果基类的虚函数允许抛出异常,则派生类的对应函数既可以允许抛出异常,也可以不允许抛出异常。
当编译器合成拷贝控制成员时,同时也生成一个异常说明。如果对所有成员和基类的所有操作都承诺了不会抛出异常,则合成的成员是noexcept的。如果合成成员调用的任意一个函数可能抛出异常,则合成的成员是noexcept(false)。而且,如果我们定义了一个析构函数但是没有为它提供异常说明,则编译器将合成一个。合成的异常说明将与假设由编译器为类合成析构函数时所得的异常说明一致。
异常类层次:标准库异常类构成了下图所示的继承体系: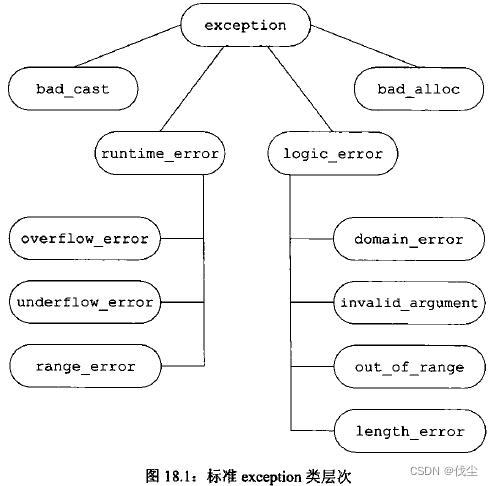
-
类型exception仅仅定义了拷贝构造函数、拷贝赋值运算符、一个虚析构函数和一个名为what的虚成员。其中what函数返回一个const char*,该指针指向一个以null结尾的字符数组,并且确保不会抛出任何异常。 -
类
exception、bad_cast和bad_alloc定义了默认构造函数。类runtime_error和logic_error没有默认构造函数,但是有一个可以接受C风格字符串或者标准库string类型实参的构造函数,这些实参负责提供关于错误的更多信息。在这些类中,what负责返回用于初始化异常对象的信息。因为what是虚函数,所以当我们捕获基类的引用时,对what函数的调用将执行与异常对象动态类型对应的版本。 -
实际的应用程序通常会自定义exception(或者exception的标准库派生类)的派生类以扩展其继承体系。这些面向应用的异常类表示了与应用相关的异常条件。和其它继承体系一样,异常类也可以看作按照层次关系组织的。层次越低,表示的异常情况就越特殊。例如,在异常类继承体系中位于最顶层的通常是exception,exception表示的含义是某处出错了,至于错误的细节则未作描述。
继承体系的第二层将exception划分为两个大的类别:运行时错误和逻辑错误。运行时错误表示的是只有在程序运行时才能检测到的错误;而逻辑错误一般指的是我们可以在程序代码中发现的错误。
下面是从其他文章中copy的std::exception测试代码,详细内容介绍可以参考对应的reference:
#include "runtime_error.hpp"
#include <iostream>
#include <stdexcept>
#include <string>
namespace runtime_error_ {
//
// reference: https://msdn.microsoft.com/en-us/library/tyahh3a9.aspx
int test_runtime_error_1()
{
try {
std::locale loc("test");
} catch (std::exception& e) {
std::cerr << "Caught " << e.what() << std::endl; // Caught bad locale name
std::cerr << "Type " << typeid(e).name() << std::endl; // Type class std::runtime_error
};
return 0;
}
/
// reference: http://www.java2s.com/Tutorial/Cpp/0120__Exceptions/Throwyourownexceptionclassbasedonruntimeerror.htm
class DivideByZeroException : public std::runtime_error {
public:
DivideByZeroException::DivideByZeroException() : runtime_error("attempted to divide by zero") {}
};
static double quotient(int numerator, int denominator)
{
throw DivideByZeroException(); // terminate function
return 0;
}
int test_runtime_error_2()
{
try {
double result = quotient(1, 1);
std::cout << "The quotient is: " << result << std::endl;
} catch (DivideByZeroException& divideByZeroException) {
std::cout << "Exception occurred: " << divideByZeroException.what() << std::endl; // Exception occurred: attempted to divide by zero
}
return 0;
}
class CppBase_RunTime_Exception : public std::runtime_error {
public :
CppBase_RunTime_Exception(int error_code_) : runtime_error(""), error_code(error_code_) {}
CppBase_RunTime_Exception(int error_code_, const std::string& info_) : runtime_error(info_), error_code(error_code_) {}
int get_error_code() const { return error_code; }
private:
int error_code = 0;
};
static int calc(int a)
{
if (a > 0) {
throw CppBase_RunTime_Exception(1, __FUNCTION__);
}
if (a < 0) {
throw CppBase_RunTime_Exception(-1, __FUNCTION__);
}
throw CppBase_RunTime_Exception(0);
return 0;
}
int test_runtime_error_3()
{
const int a{ 2 }, b{ -3 }, c{ 0 };
try {
calc(a);
} catch (const CppBase_RunTime_Exception& e) {
std::cerr << "error fun name: " << e.what() << ", error code: " << e.get_error_code() << std::endl;
}
try {
calc(b);
} catch (const CppBase_RunTime_Exception& e) {
std::cerr << "error fun name: " << e.what() << ", error code: " << e.get_error_code() << std::endl;
}
try {
calc(c);
} catch (const CppBase_RunTime_Exception& e) {
std::cerr << "error fun name: " << e.what() << ", error code: " << e.get_error_code() << std::endl;
}
std::cout << "over" << std::endl;
return 0;
}
} // namespace runtime_error_
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
GitHub: https://github.com/fengbingchun/Messy_Test
来自:https://blog.csdn.net/qq_43331089/article/details/124822150
=========================
C++ 中捕获整数除零错误
继承自 C 的优良传统, C++ 也是一门非常靠近底层的语言, 可是实在是太靠近了, 很多问题语言本身没有提供解决方案, 可执行代码贴近机器, 运行时没有虚拟机来反馈错误, 跑着跑着就毫无征兆地崩溃了, 简直比过山车还刺激.
虽然 C++ 加入了异常机制来处理很多运行时错误, 但是异常机制的功效非常受限, 很多错误还没办法用原生异常手段捕捉, 比如整数除 0 错误. 下面这段代码
#include <iostream>
int main()
{
try {
int x, y;
std::cin >> x >> y;
std::cout << x / y << std::endl;
} catch (...) {
std::cerr << "attempt to divide integer by 0." << std::endl;
}
return 0;
}
输入 "1 0" 则会导致程序挂掉, 而那对 try-catch 还呆在那里好像什么事情都没发生一样. 像 Python 一类有虚拟机环境支持的语言, 都会毫无悬念地捕获除 0 错误.
使用信号
不过, 底层自然有底层的办法, 而且有虚拟机的环境也并非在每个整数除法指令之前都添上一句 if 0 == divisor: raise 之类的挫语句来触发异常. 这得益于硬件体系中的中断机制. 简而言之, 当发生整数除 0 之类的错误时, 硬件会触发中断, 这时操作系统会根据上下文查出是哪个进程不给力了, 然后给这个进程发出一个信号. 某些时候也可以手动给进程发信号, 比如恼怒的用户发现某个程序卡死的时候果断 kill 掉这个进程, 这也是信号的一种.
这次就不是 C 标准了, 而是 POSIX 标准. 它规定了哪些信号进程不处理也不会有太大问题, 有些信号进程想处理也是不行的, 还有一些信号是错误中断, 如果程序处理了它们, 那么程序能继续执行, 否则直接杀掉.
不过, 这些错误处理默认过程都是不存在的, 需要通过调用 signal 函数配置. 方法类似下面这个例子
#include <csignal>
#include <cstdlib>
#include <iostream>
void handle_div_0(int)
{
std::cerr << "attempt to divide integer by 0." << std::endl;
exit(1);
}
int main()
{
if (SIG_ERR == signal(SIGFPE, handle_div_0)) {
std::cerr << "fail to setup handler." << std::endl;
return 1;
}
int x, y;
std::cin >> x >> y;
std::cout << x / y << std::endl;
return 0;
}
可以看出, signal 接受两个参数, 分别是信号编号和信号处理函数. 成功设置了针对 SIGFPE (吐槽: 为什么是浮点异常 FPE 呢?) 的处理函数 handle_div_0, 如果再发生整数除 0 的惨剧, handle_div_0 就会被调用.
handle_div_0 的参数是信号码, 也就是 SIGFPE, 忽略它也行.
底层机制
虽然说 handle_div_0 是异常处理过程, 但毕竟是函数都会有调用栈, 能返回. 假如在 handle_div_0 中不调用exit 自寻死路, 而是选择返回, 那么程序会怎么样呢? 运行一下, 当出现错误时, stderr 会死循环般地刷屏.
实际上, 当错误发生时, 操作系统会在当前错误出现处加载信号处理函数的调用栈帧, 并且把它的返回地址设置为出错的那条指令之前, 这样看起来就像是出错之前的瞬间调用了信号处理函数. 当信号处理函数返回时, 则又会再次执行那条会出错的指令, 除非信号处理函数能通过某些特别的技巧修复指令, 否则退出时会重蹈覆辙.
上面提到的 "修复指令" 指的是修复 CPU 级别的指令码或者操作数. 把除数 y 变成全局变量, 然后在handle_div_0 中设置 y 为 1, 这样做是于事无补的.
使用异常处理机制
修复指令这种事情简直是天方夜谭, 所以选择输出一跳错误语句并退出也算是不错的方法. 在 C 语言时代, 还可以通过 setjmp 和 longjmp 来跳转程序流程. 不过 setjmp 和 longjmp 操作起来太不方便了, 相比之下 try-catch 要好得多.
刚才说过, 错误处理函数的调用栈帧直接位于错误发生处所在函数栈帧之上, 因此, 抛出异常能够被外部设置的 try-catch 捕获. 现在定义一个异常类型, 然后在 handle_div_0 中抛出就行.
#include <csignal>
#include <iostream>
struct div_0_exception {};
void handle_div_0(int)
{
throw div_0_exception();
}
int main()
{
if (SIG_ERR == signal(SIGFPE, handle_div_0)) {
std::cerr << "fail to setup handler." << std::endl;
return 1;
}
try {
int x, y;
std::cin >> x >> y;
std::cout << x / y << std::endl;
} catch (div_0_exception) {
std::cerr << "attempt to divide integer by 0." << std::endl;
}
return 0;
}
更精准的信号处理
上述方法的缺陷在于, 只要发生 SIGFPE 中断, 无论是整数除 0 错误, 还是其它浮点异常, 处理方式是统一的. 不过, POSIX 还规定了一组更精细的信号处理接口, 它们是 sigaction.
呃... 对它们都是 sigaction. 这又是一个雷死人的东西. 在 csignal 中定义了两个同名的东西, 分别是
struct sigaction;
int sigaction(int sig
, struct sigaction const* restrict act
, struct sigaction* restrict old_act);
前面那个结构体在设置信号处理函数时用到, 里面存放了一些标志位和信号处理函数指针. 而后面那个函数就是设置信号处理的入口 (如果函数的第三个参数并非 NULL, 并且之前设置过信号处理结构体, 那么会将之前的处理方法写入第三个参数所指向的结构中, 这一点并不需要, 所以后面的例子中这个参数直接传入 NULL, 详情请见man 3 sigaction).
结构 sigaction 中会有两个函数入口地址, 它们分别是
void (* sa_handler)(int);
void (* sa_sigaction)(int, siginfo_t*, void*);
sa_handler 也就是之前所演示的轻便型信号处理函数; 而 sa_sigaction, 从它接受的参数就能看出, 它能获得更多的上下文信息 (然而, 一看第三个参数的类型是 void* 就知道没有好事, 信息都在第二个参数指向的结构体中).
既然有两个处理函数, 那么如何决定使用哪一个呢? 在 struct sigaction 中有一个标志位成员 sa_flags, 如果为它置上 SA_SIGINFO 位, 那么就使用 sa_sigaction 作为处理函数.
siginfo_t 类型中有一个叫做 si_code 的成员, 它为信号类型提供进一步的细分, 比如在 SIGFPE 信号下,si_code 可能有 FPE_INTOVF (整数溢出), FPE_FLTUND (浮点数下溢), FPE_FLTOVF (浮点数上溢) 等各种相关取值, 当然还有现在最关心的整数除 0 信号码 FPE_INTDIV. 如果陷入 SIGFPE 的窘境中, 而 si_code 又恰好是FPE_INTDIV 那么就要果断抛出 0 异常了.
由于原生的 struct sigaction 居然跟函数重名, 所以下面的例子中会对其包装一下, 提供合适的初始化过程.
#include <csignal>
#include <cstring>
#include <iostream>
struct my_sig_action {
typedef void (* handler_type)(int, siginfo_t*, void*);
explicit my_sig_action(handler_type handler)
{
memset(&_sa, 0, sizeof(struct sigaction));
_sa.sa_sigaction = handler;
_sa.sa_flags = SA_SIGINFO;
}
operator struct sigaction const*() const
{
return &_sa;
}
protected:
struct sigaction _sa;
};
struct div_0_exception {};
void handle_div_0(int sig, siginfo_t* info, void*)
{
if (FPE_INTDIV == info->si_code)
throw div_0_exception();
}
int main()
{
my_sig_action sa(handle_div_0);
if (0 != sigaction(SIGFPE, sa, NULL)) {
std::cerr << "fail to setup handler." << std::endl;
return 1;
}
try {
int x, y;
std::cin >> x >> y;
std::cout << x / y << std::endl;
} catch (div_0_exception) {
std::cerr << "attempt to divide integer by 0." << std::endl;
}
return 0;
}
===============
C++异常使用详解(看这一篇就够了)
一、异常的概念
异常是一种处理错误的方式,当一个函数发现自己无法处理的错误时就可以抛出异常,让函数的直接或间接的调用者处理这个错误。
- throw:当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
- catch: 在你想要处理问题的地方,通过异常处理程序捕获异常,catch 关键字用于捕获异常,可以有多个catch进行捕获。
- try: try 块中的代码标识将被激活的特定异常,它后面通常跟着一个或多个 catch 块。
语法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
try{ // 保护的标识代码}catch( ExceptionName e1 ){ // catch 块}catch( ExceptionName e2 ){ // catch 块}catch( ExceptionName eN ){ // catch 块} |
二、异常的使用
1.异常的抛出和捕获原则
1.异常是通过抛出对象而引发的,该对象的类型决定了应该激活哪个catch的处理代码。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
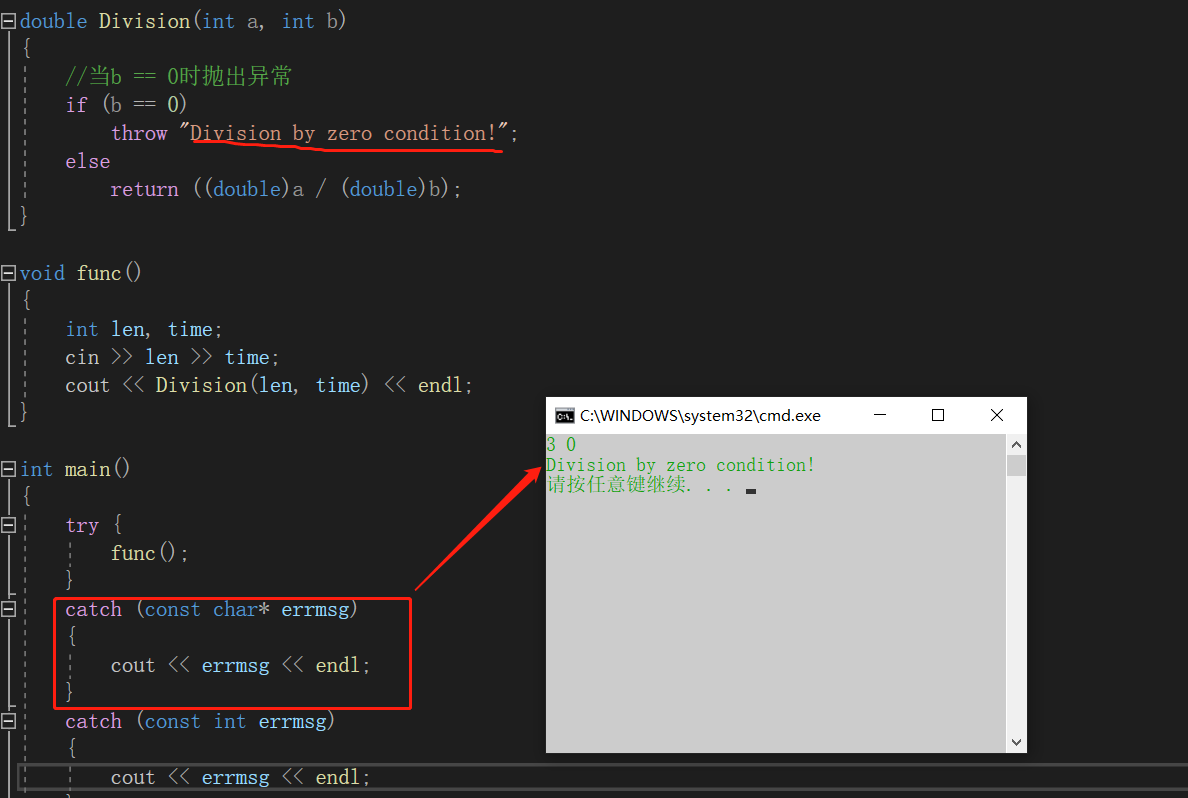
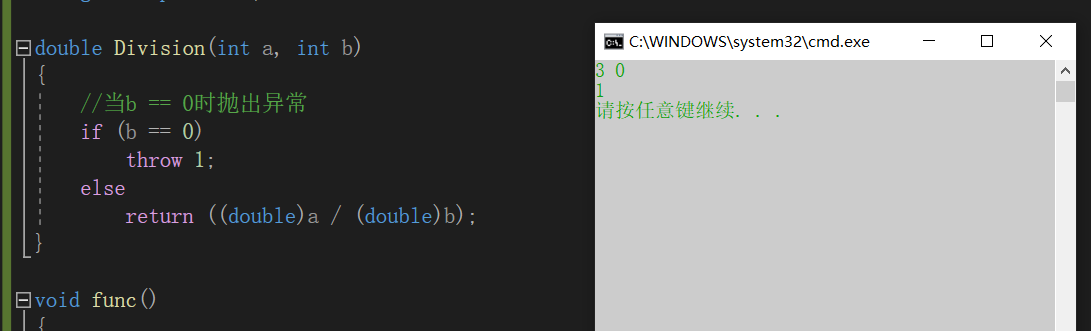
#define _CRT_SECURE_NO_WARNINGS 1#include<iostream>#include<vector>using namespace std;double Division(int a, int b){ //当b == 0时抛出异常 if (b == 0) throw "Division by zero condition!"; //throw 1; else return ((double)a / (double)b);}void func(){ int len, time; cin >> len >> time; cout << Division(len, time) << endl;}int main(){ try { func(); } catch (const char* errmsg) { cout << errmsg << endl; } catch (const int errmsg) { cout << errmsg << endl; } return 0;} |
当抛出的异常时char* 类型时
当抛出异常换成整形时
2.被选中的处理代码是调用链中与该对象类型匹配且离抛出异常位置最近的那一个
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
#define _CRT_SECURE_NO_WARNINGS 1#include<iostream>#include<vector>using namespace std;double Division(int a, int b){ try { //当b == 0时抛出异常 if (b == 0) throw "Division by zero condition!"; else return ((double)a / (double)b); } catch(const char* errmsg) { cout << "Division:" << errmsg << endl; }}void func(){ int len, time; cin >> len >> time; cout << Division(len, time) << endl;}int main(){ try { func(); } catch (const char* errmsg) { cout << errmsg << endl; } catch (const int errmsg) { cout << errmsg << endl; } return 0;} |
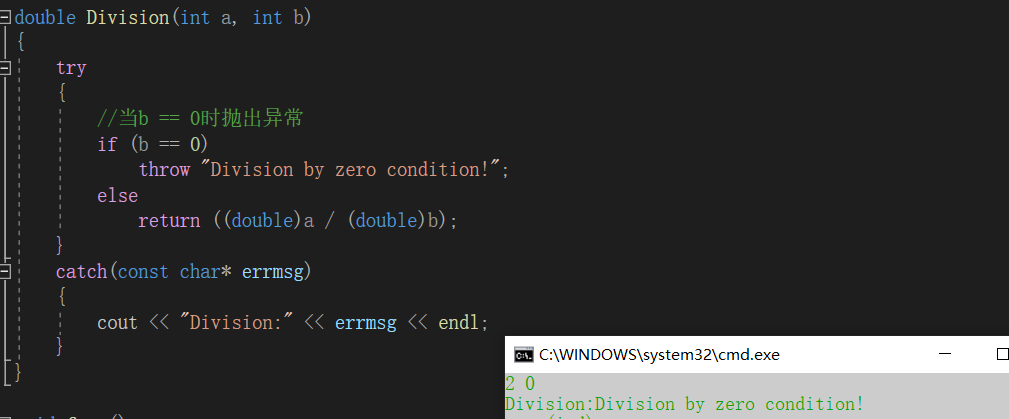
3.抛出异常对象后,会生成一个异常对象的拷贝,因为抛出的异常对象可能是一个临时对象,所以会生成一个拷贝对象,这个拷贝的临时对象会在被catch以后销毁。(这里的处理类似于函数的传值返回)
4.catch(…)可以捕获任意类型的异常,问题是不知道异常错误是什么。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
void fun1(){ throw "错误";}int main(){ try { fun1(); } catch(const int errmsg) { cout << errmsg; } catch (...) { cout << "未知错误" << endl; }} |
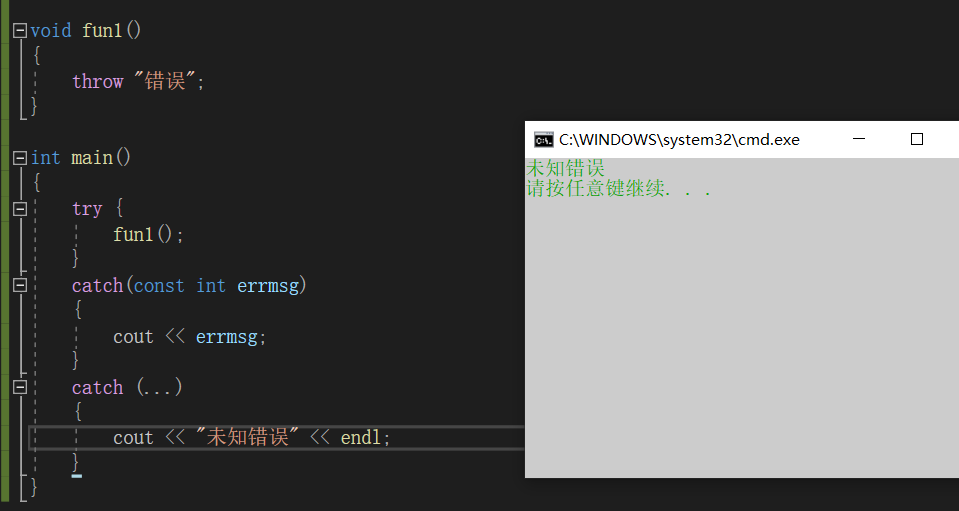
5.实际中抛出和捕获的匹配原则有个例外,并不都是类型完全匹配,可以抛出的派生类对象,使用基类捕获,这个在实际中非常实用,以后主要用到的也是这种方式
2.在函数调用链中异常栈展开匹配原则
1.首先检查throw本身是否在try块内部,如果是再查找匹配的catch语句。如果有匹配的,则调到catch的地方进行处理。
2.没有匹配的catch则退出当前函数栈,继续在调用函数的栈中进行查找匹配的catch。
3.如果到达main函数的栈,依旧没有匹配的,则终止程序。上述这个沿着调用链查找匹配的catch子句的过程称为栈展开。所以实际中我们最后都要加一个catch(…)捕获任意类型的异常,否则当有异常没捕获,程序就会直接终止。
4.找到匹配的catch子句并处理以后,会继续沿着catch子句后面继续执行。
3.异常规范
1.异常规格说明的目的是为了让函数使用者知道该函数可能抛出的异常有哪些。 可以在函数的
后面接throw(类型),列出这个函数可能抛掷的所有异常类型
2.函数的后面接throw(),表示函数不抛异常。
3.若无异常接口声明,则此函数可以抛掷任何类型的异常。
|
1
2
3
4
5
6
7
8
9
|
// 这里表示这个函数会抛出A/B/C/D中的某种类型的异常void fun() throw(A,B,C,D);// 这里表示这个函数只会抛出bad_alloc的异常void* operator new (std::size_t size) throw (std::bad_alloc);// 这里表示这个函数不会抛出异常void* operator new (std::size_t size, void* ptr) throw();// C++11 中新增的noexcept,表示不会抛异常thread() noexcept; |
4.异常安全
- 构造函数完成对象的构造和初始化,最好不要在构造函数中抛出异常,否则可能导致对象不完整或没有完全初始化
- 析构函数主要完成资源的清理,最好不要在析构函数内抛出异常,否则可能导致资源泄漏(内存泄漏、句柄未关闭等)
- C++中异常经常会导致资源泄漏的问题,比如在new和delete中抛出了异常,导致内存泄漏,在lock和unlock之间抛出了异常导致死锁,C++经常使用RAII来解决以上问题。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
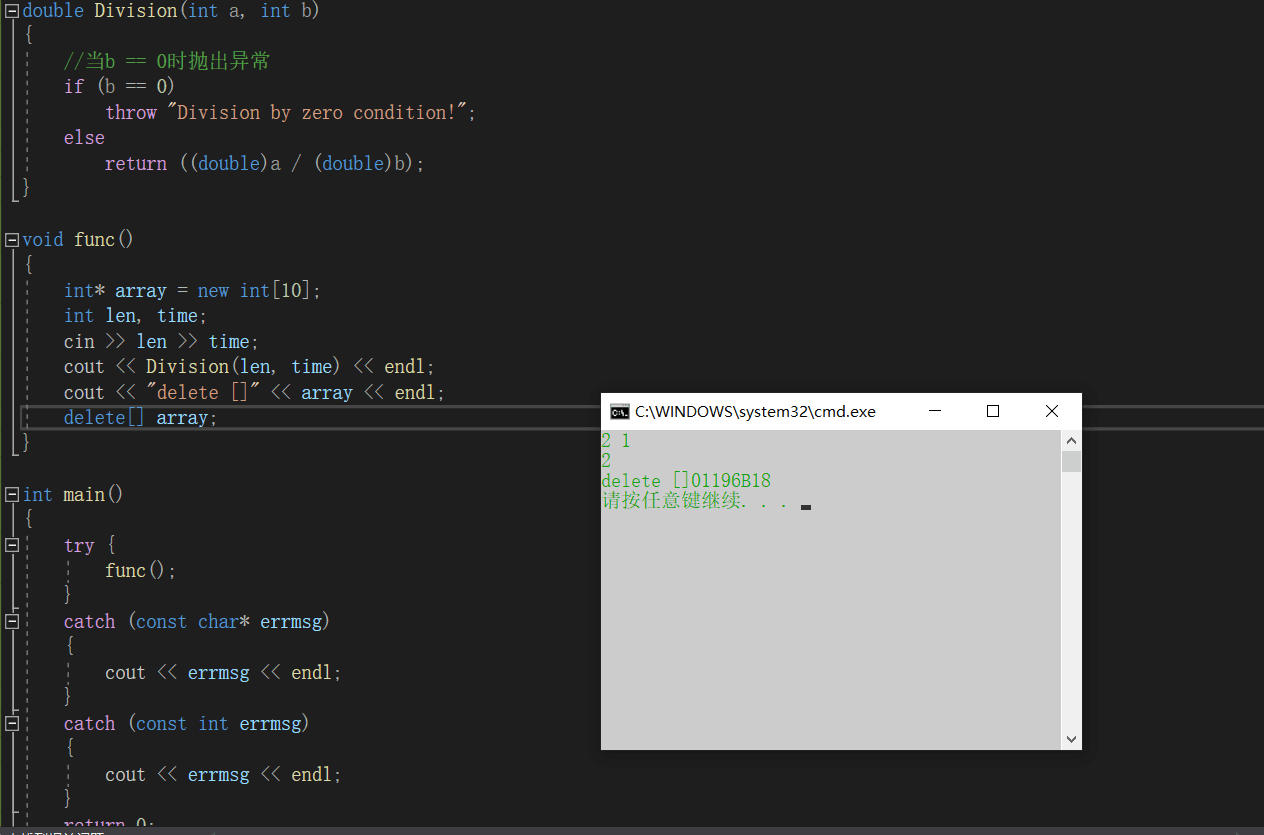
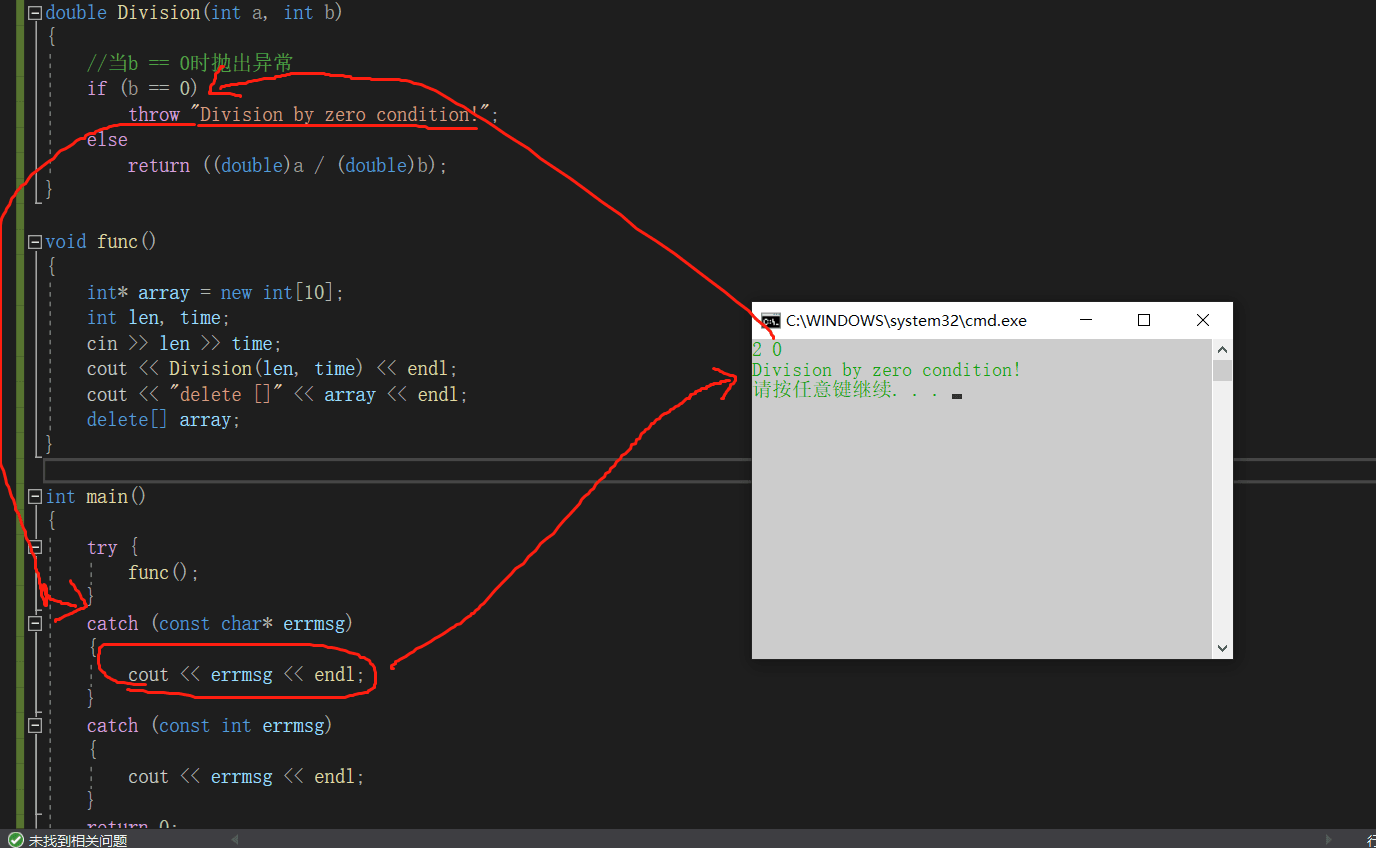
#define _CRT_SECURE_NO_WARNINGS 1#include<iostream>#include<vector>#include<windows.h>using namespace std;double Division(int a, int b){ //当b == 0时抛出异常 if (b == 0) throw "Division by zero condition!"; else return ((double)a / (double)b);}void func(){ int* array = new int[10]; int len, time; cin >> len >> time; cout << Division(len, time) << endl; cout << "delete []" << array << endl; delete[] array;}int main(){ try { func(); } catch (const char* errmsg) { cout << errmsg << endl; } catch (const int errmsg) { cout << errmsg << endl; } return 0;} |
正常情况,没有异常
有异常
如果出现了在new和delete中间抛出异常或者中间的某个函数抛出异常,会导致程序直接跳转到catch的地方而无法实现delete,出现内存泄漏
5.异常的重新抛出
有可能单个的catch不能完全处理一个异常,在进行一些校正处理以后,希望再交给更外层的调用链函数来处理,catch则可以通过重新抛出将异常传递给更上层的函数进行处理。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
double Division(int a, int b){ // 当b == 0时抛出异常 if (b == 0) { throw "Division by zero condition!"; } return (double)a / (double)b;}void Func(){ // 这里可以看到如果发生除0错误抛出异常,另外下面的array没有得到释放。 // 所以这里捕获异常后并不处理异常,异常还是交给外面处理,这里捕获了再重新抛出去。 int* array = new int[10]; try { int len, time; cin >> len >> time; cout << Division(len, time) << endl; } catch (...) { cout << "delete []" << array << endl; delete[] array; throw; // 重新抛出异常,且内容不变 } // ... cout << "delete []" << array << endl; delete[] array;}int main(){ try { Func(); } catch (const char* errmsg) // 捕获Func重新抛出的异常 { cout << errmsg << endl; } return 0;} |
三、异常的优缺点
异常的优点
- 异常对象定义好了,相比错误码的方式可以清晰准确的展示出错误的各种信息,甚至可以包含堆栈调用的信息,这样可以帮助更好的定位程序的bug。
- 返回错误码的传统方式有个很大的问题就是,在函数调用链中,深层的函数返回了错误,那么我们得层层返回错误,最外层才能拿到错误.
- 很多的第三方库都包含异常,比如boost、gtest、gmock等等常用的库,那么我们使用它们也需要使用异常。
- 很多测试框架都使用异常,这样能更好的使用单元测试等进行白盒的测试。
- 部分函数使用异常更好处理,比如构造函数没有返回值,不方便使用错误码方式处理。比如T&operator这样的函数,如果pos越界了只能使用异常或者终止程序处理,没办法通过返回值表示错误。
异常的缺点
- 异常会导致程序的执行流乱跳,并且非常的混乱,并且是运行时出错抛异常就会乱跳。这会导致我们跟踪调试时以及分析程序时,比较困难。
- 异常会有一些性能的开销。当然在现代硬件速度很快的情况下,这个影响基本忽略不计。
- C++没有垃圾回收机制,资源需要自己管理。有了异常非常容易导致内存泄漏、死锁等异常安全问题。这个需要使用RAII来处理资源的管理问题。学习成本较高。
- C++标准库的异常体系定义得不好,导致大家各自定义各自的异常体系,非常的混乱。
- 异常尽量规范使用,否则后果不堪设想,随意抛异常,外层捕获的用户苦不堪言。所以异常规范有两点:一、抛出异常类型都继承自一个基类。二、函数是否抛异常、抛什么异常,都使用 func()throw();的方式规范化。
总结
到此这篇关于C++异常使用的文章就介绍到这了
===============
#include <iostream>
#include <stdexcept> // 包含标准异常类的头文件 不需要
double divide(double a, double b) {
if (b == 0) {
throw std::runtime_error("除数不能为0"); // 抛出一个运行时异常
}
return a / b;
}
int main() {
try {
std::cout << divide(10, 0) << std::endl;
} catch (const std::runtime_error& e) {
std::cerr << "发生错误: " << e.what() << std::endl; // 捕获并处理异常
}
return 0;
}

#include <iostream> using namespace std; int main(){ try{ int a , b, c; a = 5; b = 0; if (b==0){ // throw runtime_error("can not divide"); throw "error"; } c= a / b; cout << "c" << c << endl; } catch (const char* msg){ cerr << "msg:" << msg << endl; } catch (const exception &e){ cout << "execption:" << endl; } catch (const runtime_error &d){ cout << "err:" << d.what() << endl; } cout << "end world!" << endl; return 0; } 输出: msg:error
#include <iostream> using namespace std; int main(){ try{ int a , b, c; a = 5; b = 0; if (b==0){ throw runtime_error("can not divide"); } c= a / b; cout << "c" << c << endl; } catch (const char* msg){ cerr << "msg:" << msg << endl; } catch (const exception &e){ cout << "execption:" << endl; } catch (const runtime_error &d){ cout << "err:" << d.what() << endl; } cout << "end world!" << endl; return 0; }
==================
RAII机制的核心思想是使用对象来管理资源,利用C++构造的对象最终会被对象的析构函数销毁的原则。具体来说,RAII的做法是使用一个对象,在其构造时获取对应的资源,在对象生命期内控制对资源的访问,使之始终保持有效,最后在对象析构的时候,释放构造时获取的资源。这种机制确保了资源的正确释放,避免了因忘记释放资源而导致的内存泄漏问题。
RAII机制适用于管理各种系统资源,如内存、网络套接字、文件句柄等,这些资源在计算机系统中数量有限且对系统正常运行具有重要作用。通过RAII机制,可以简化资源管理,提高代码的可读性和健壮性,即使在面对异常和错误情况时,也能保证资源被正确释放。
RAII机制的实现依赖于对象的生命周期管理。当定义的局部变量的生命结束时,它的析构函数就会自动被调用,从而无需程序员显式地调用释放资源的操作。这种自动化的资源管理方式大大减少了因人为因素导致的资源泄漏问题。
此外,RAII机制与智能指针等C++特性相结合,可以进一步增强资源管理的效率和安全性。例如,使用智能指针(如std::unique_ptr、std::shared_ptr)可以自动管理动态分配的内存,避免内存泄露。当智能指针对象销毁时,它所指向的内存也会被自动释放,这与RAII机制的核心思想相契合,即通过对象的生命周期来管理资源的获取和释放。
==========
C++ 中的异常类似于 C# 和 Java 等语言中的异常。 在 try 块中,如果引发某个异常,类型与该异常的类型匹配的第一个关联 catch 块将捕获该异常。 换言之,执行将从 throw 语句跳转到 catch 语句。 如果未找到可用的 catch 块,则调用 std::terminate 并且程序会退出。 在 C++ 中可以引发任何类型;但是,我们建议引发直接或间接派生自 std::exception 的类型。 在前面的示例中,异常类型 invalid_argument 是在标准库的 <stdexcept> 头文件中定义的。 C++ 既不提供也不需要 finally 块来确保在引发异常时释放所有资源。 资源采集是使用智能指针的初始化 (RAII) 习语,它提供所需的功能来清理资源。 有关详细信息,请参阅如何:针对异常安全性进行设计。 有关 C++ 堆栈展开机制的信息,请参阅异常和堆栈展开。
基本准则
在任何编程语言中实现可靠的错误处理都颇有挑战性。 尽管异常提供多项功能来支持妥善的错误处理,但它们不能代你解决一切问题。 为了实现异常机制的优势,请在设计代码时考虑到异常。
- 使用断言检查应始终为 true 或始终为 false 的条件。 使用异常来检查可能发生的错误,例如公共函数参数的输入验证错误。 有关详细信息,请参阅异常与断言部分。
- 当处理错误的代码与通过一个或多个中间函数调用检测错误的代码分离时,请使用异常。 当处理错误的代码与检测错误的代码紧密耦合时,请考虑是否在性能关键型循环中使用错误代码。
- 对于每个可能引发或传播异常的函数,请提供三项异常保证之一:强保证、基本保证或 nothrow (
noexcept) 保证。 有关详细信息,请参阅如何:针对异常安全性进行设计。 - 通过值引发异常,通过引用捕获异常。 不要捕获无法处理的异常。
- 不要使用 C++11 中已弃用的异常规范。 有关详细信息,请参阅异常规范和
noexcept部分。 - 使用适用的标准库异常类型。 从
exception类层次结构派生自定义的异常类型。 - 不要允许异常从析构函数或内存解除分配函数中逃逸。
异常和性能
如果未引发异常,则异常机制的性能开销极低。 如果引发异常,则堆栈遍历和展开的开销与函数调用的开销大致相当。 进入 try 块后,需要使用其他数据结构来跟踪调用堆栈,如果引发异常,则还需要使用更多指令来展开堆栈。 但是,在大多数情况下,性能和内存占用的开销并不高。 异常对性能的不利影响可能仅在内存受限的系统上才比较明显。 或者,这种影响在性能关键型循环中(其中的错误可能经常发生,并且处理错误的代码与报告错误的代码之间存在紧密耦合)可能比较明显。 无论在哪种情况下,不进行分析和测量就不可能知道异常的实际开销。 即使在开销很高的极少数情况下,也可将这种开销与设计良好的异常策略所提供的更高正确性、更方便的维护性和其他优势进行权衡。
异常与断言
异常和断言是用于检测程序中运行时错误的两种不同机制。 如果所有代码都正确,可以使用 assert 语句来测试开发过程中始终应为 true 或 false 的条件。 使用异常来处理此类错误是没有意义的,因为错误指示的是代码中必须修复的问题。 它并不表示程序在运行时必须从中恢复的状态。 assert 在语句中停止执行,以便可以在调试器中检查程序状态。 异常从第一个适当的 catch 处理程序继续执行。 即使代码正确,也可以使用异常来检查在运行时可能发生的错误状态,例如“找不到文件”或“内存不足”。异常可以处理这些状态,即使恢复只是将消息输出到日志并结束程序。 始终使用异常来检查公共函数的参数。 即使函数没有错误,也可能无法完全控制用户传递给它的参数。
来自:https://learn.microsoft.com/zh-cn/cpp/cpp/errors-and-exception-handling-modern-cpp?view=msvc-170
====
参考:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现