
mongodb 数据库
一、简介
MongoDB 是一款流行的开源文档型数据库,从它的命名来看,确实是有一定野心的。
MongoDB 的原名一开始来自于 英文单词"Humongous", 中文含义是指"庞大",即命名者的意图是可以处理大规模的数据。
但笔者更喜欢称呼它为 "芒果"数据库,除了译音更加相近之外,原因还来自于这几年使用 MongoDB 的两层感觉:
第一层感受是"爽",使用这个文档数据库的特点是几乎不受什么限制,一方面 Json 文档式的结构更容易理解,而无 Schema 约束也让 DDL 管理更加简单,一切都可以很快速的进行。
第二层感受是"酸爽",这点相信干运维或是支撑性工作的兄弟感受会比较深刻,MongoDB 由于入门体验"太过于友好",导致一些团队认为用好这个数据库是个很简单的事情,所以开发兄弟在存量系统上埋一些坑也是正常的事情。
所谓交付一时爽,维护火葬场… 当然了,这句话可能有些过。 但这里的潜台词是:与传统的 RDBMS 数据库一样,MongoDB 在使用上也需要认真的考量和看护,不然的化,会遇到更多的坑。
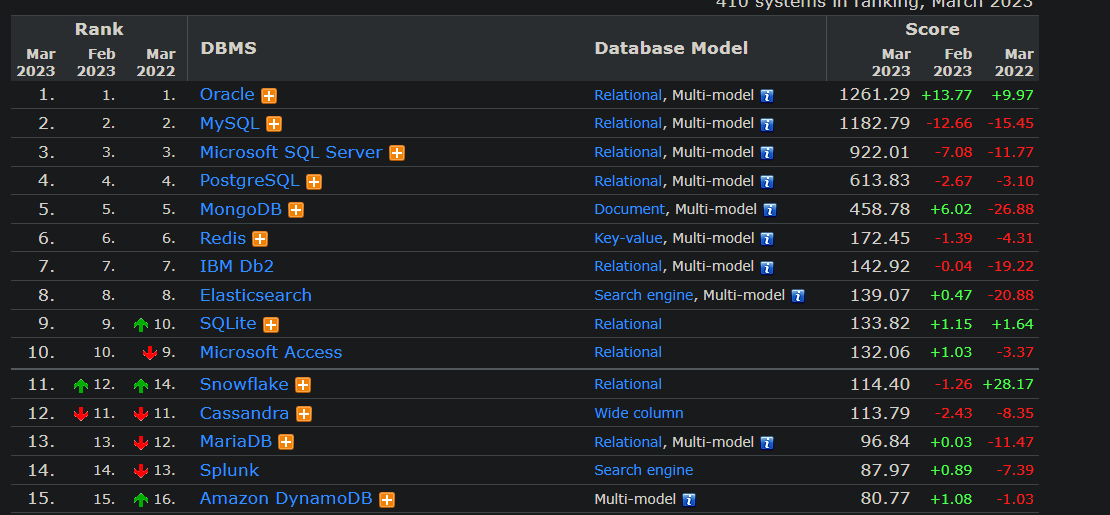
那么,尽管文档数据库在选型上会让一些团队望而却步,仍然不阻碍该数据库所获得的一些支持,比如 DB-Engine 上的排名:
MongoDB 中字段的类型是固定的、区分大小写、并且文档中的字段也是有序的。 另外,SQL 还有一些其他的概念,对应关系如下: _id 主键,MongoDB 默认使用一个_id 字段来保证文档的唯一性
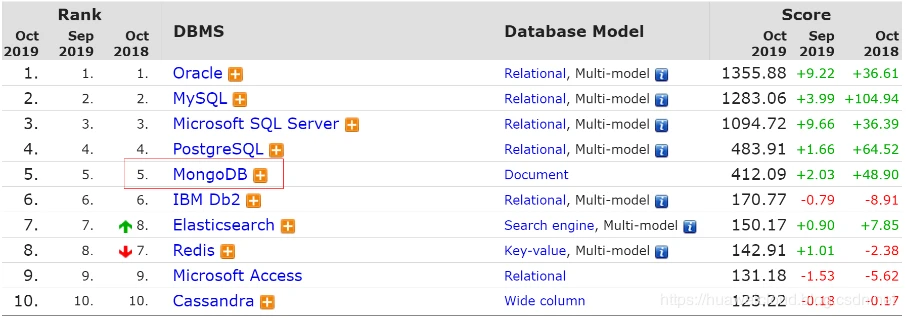
图-DBEngine 排名
在全部的排名中,MongoDB 长期排在第 5 位(文档数据库排名第 1 位),同时也是最受欢迎的 NoSQL 数据库。
另外,MongoDB 的社区一直比较活跃,加上商业上的驱动(MongoDB 于 2017 年在纳斯达克上市),这些因素都推动了该开源数据库的发展。
如果对于 MongoDB 的发展史感兴趣,可以参考下没有一个技术天生完美,MongoDB 十年发展全纪录这篇文章。
MongoDB 数据库的一些特性:
面向文档存储,基于 JSON/BSON 可表示灵活的数据结构
动态 DDL 能力,没有强 Schema 约束,支持快速迭代
高性能计算,提供基于内存的快速数据查询
容易扩展,利用数据分片可以支持海量数据存储
丰富的功能集,支持二级索引、强大的聚合管道功能,为开发者量身定做的功能,如数据自动老化、固定集合等等。
跨平台版本、支持多语言 SDK…
假定你是初次了解 MongoDB,下面的内容将能帮助你对该数据库技术的全貌产生一定的了解。
二、基本模型
数据结构对于一个软件来说是至关重要的,MongoDB 在概念模型上参考了 SQL 数据库,但并非完全相同。
关于这点,也有人说,MongoDB 是 NoSQL 中最像 SQL 的数据库…
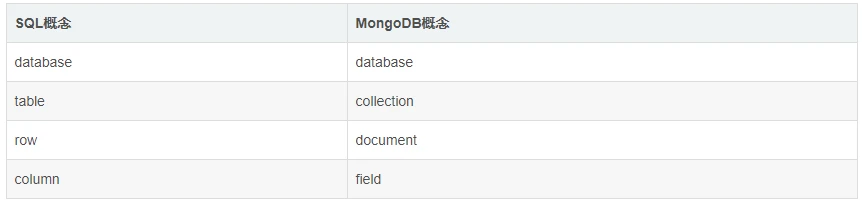
如下表所示:
-
database 数据库,与 SQL 的数据库(database)概念相同,一个数据库包含多个集合(表)
-
collection 集合,相当于 SQL 中的表(table),一个集合可以存放多个文档(行)。 不同之处就在于集合的结构(schema)是动态的,不需要预先声明一个严格的表结构。更重要的是,默认情况下 MongoDB 并不会对写入的数据做任何 schema 的校验。
-
document 文档,相当于 SQL 中的行(row),一个文档由多个字段(列)组成,并采用 bson(json)格式表示。
-
field 字段,相当于 SQL 中的列(column),相比普通 column 的差别在于 field 的类型可以更加灵活,比如支持嵌套的文档、数组。
-
此外,MongoDB 中字段的类型是固定的、区分大小写、并且文档中的字段也是有序的。
-
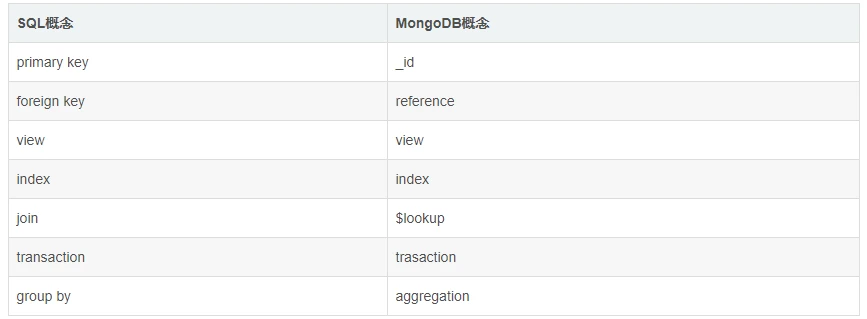
另外,SQL 还有一些其他的概念,对应关系如下:
-
_id 主键,MongoDB 默认使用一个_id 字段来保证文档的唯一性。
-
reference 引用,勉强可以对应于 外键(foreign key) 的概念,之所以是勉强是因为 reference 并没有实现任何外键的约束,而只是由客户端(driver)自动进行关联查询、转换的一个特殊类型。
-
view 视图,MongoDB 3.4 开始支持视图,和 SQL 的视图没有什么差异,视图是基于表/集合之上进行动态查询的一层对象,可以是虚拟的,也可以是物理的(物化视图)。
-
index 索引,与 SQL 的索引相同。
-
$lookup,这是一个聚合操作符,可以用于实现类似 SQL-join 连接的功能
-
transaction 事务,从 MongoDB 4.0 版本开始,提供了对于事务的支持
-
aggregation 聚合,MongoDB 提供了强大的聚合计算框架,group by 是其中的一类聚合操作。
曾经,JSON 的出现及流行让 Web 2.0 的数据传输变得非常简单,所以使用 JSON 语法是非常容易让开发者接受的。
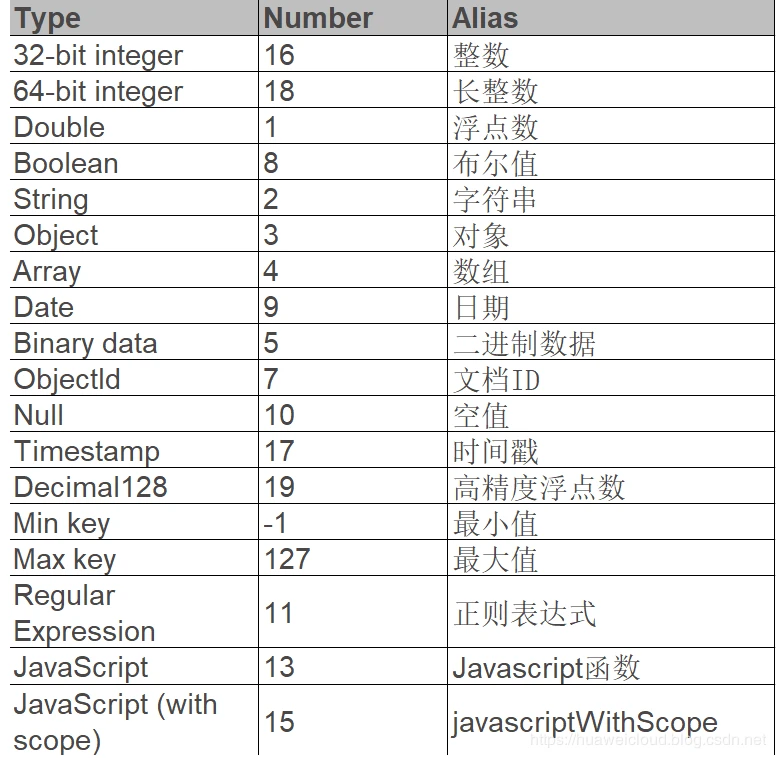
但是 JSON 也有自己的短板,比如无法支持像日期这样的特定数据类型,因此 MongoDB 实际上使用的是一种扩展式的 JSON,叫 BSON(Binary JSON)。
BSON 所支持的数据类型包括:

分布式 ID
在单机时代,大多数应用可以使用数据库自增式 ID 来作为主键。 传统的 RDBMS 也都支持这种方式,比如 mysql 可以通过声明 auto_increment 来实现自增的主键。 但一旦数据实现了分布式存储,这种方式就不再适用了,原因就在于无法保证多个节点上的主键不出现重复。
为了实现分布式数据 ID 的唯一性保证,应用开发者提出了自己的方案,而大多数方案中都会将 ID 分段生成,如著名的 snowflake 算法中就同时使用了时间戳、机器号、进程号以及随机数来保证唯一性。
MongoDB 采用 ObjectId 来表示主键的类型,数据库中每个文档都拥有一个_id 字段表示主键。
_id 的生成规则如下:
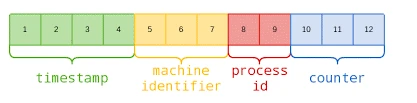
图-ObjecteID
其中包括:
4-byte Unix 时间戳
3-byte 机器 ID
2-byte 进程 ID
3-byte 计数器(初始化随机)
值得一提的是 _id 的生成实质上是由客户端(Driver)生成的,这样可以获得更好的随机性,同时降低服务端的负载。
https://db-engines.com/en/ranking
db
MongoDB 是免费使用的(MongoDB分社区版[在所有环境下都免费] 和企业版[在开发环境免费,生产环境收费]两个版本)。 MongoDB 数据库具有可伸缩性和灵活性,可帮助你快速查询和索引你需要数据。
MongoDB是免费的吗?
- MongoDB有两个发布版本:社区版和企业版
- 社区办基于SSPL,一种和AGPL基本类似的开源协议
- 企业版是基于商业协议,需要付费使用
CouchDB 是一个开源的面向文档的数据库管理系统,可以通过 RESTful JavaScript Object Notation (JSON) API 访问。术语 “Couch” 是 “Cluster Of Unreliable Commodity Hardware” 的首字母缩写,它反映了 CouchDB 的目标具有高度可伸缩性,提供了高可用性和高可靠性,即使运行在容易出现故障的硬件上也是如此。CouchDB 最初是用 C++ 编写的,但在 2008 年 4 月,这个项目转移到 Erlang OTP 平台进行容错测试
CouchDB和MongoDB的比较
|
特性 |
CouchDB |
MongoDB |
|---|---|---|
|
数据模型 |
它遵循面向文档的模型,数据以JSON格式表示。 |
它遵循面向文档的模型,但数据以BSON格式表示 |
|
接口 |
CouchDB使用基于HTTP/ REST的接口。它非常直观,设计非常好。 |
MongoDB在TCP/IP上使用二进制协议和自定义协议。 |
|
对象存储 |
在CouchDB中,数据库包含文档。 |
在MongoDB中,数据库包含集合,而集合包含文档。 |
|
速度 |
它的读取速度是关键的数据库,MongoDB比CouchDB快 |
MongoDB提供了更快的读取速度。 |
|
手机支持 |
CouchDB可以运行在苹果iOS和Android设备上,为移动设备提供支持。 |
没有提供移动支援 |
|
大小 |
数据库可以随着CouchDB而增长;当结构从一开始就没有明确定义时,MongoDB更适合快速增长。 |
如果我们有一个快速增长的数据库,MongoDB是更好的选择。 |
|
查询方法 |
查询使用map-reduce函数。虽然它可能是一种优雅的解决方案,但对于具有传统SQL经验的人来说,学习它可能更加困难。 |
MongoDB采用Map/Reduce (JavaScript)创建基于集合+对象的查询语言。对于有SQL知识的用户,MongoDB更容易学习,因为它更接近语法。 |
|
复制 |
CouchDB支持使用自定义冲突解决功能的主-主复制。 |
MongoDB支持主从复制。 |
|
并发性 |
它遵循MVCC(多版本并发控制)。 |
就地更新。 |
|
首选项 |
CouchDB支持可用性。 |
MongoDB支持一致性 |
|
性能的一致性 |
CouchDB比MongoDB更安全 |
|
|
一致性 |
CouchDB最终是一致的。 |
MongoDB是强一致性的。 |
|
编写语言 |
Erlang |
C++. |
|
分析 |
如果我们需要一个在移动设备上运行的数据库,需要主-主复制或单服务器持久性,那么CouchDB是一个很好的选择。 |
如果我们正在寻找最大的吞吐量,或者有一个快速增长的数据库,MongoDB是最好的选择。 |
RocksDB简介 RocksDB是基于C++语言编写的嵌入式KV存储引擎,它不是一个分布式的DB,而是一个高效、高性能、单点的数据库引擎。RocksDB 是一个来自 facebook 的可嵌入式的支持持久化的 key-value 存储系统,也可作为 C/S 模式下的存储数据库,但主要目的还是嵌入式。RocksDB 基于 LevelDB 构建。
RocksDB 有很多核心场景需要分配内存的,包括但不限于 Memtable、 Cache、Iterator 等,高效优质的内存分配器就显得尤为重要。一个优秀的通用内存分配器需要具备以下特性:
- 尽量避免内存碎片;
- 并发分配性能好;
- 额外的空间损耗尽量少;
- 兼具通用性、兼容性、可移植性且易调试。
CAP:
-
数据库事务一致性需求 很多web实时系统并不要求严格的数据库事务,对读一致性的要求很低,有些场合对写一致性要求并不高。允许实现最终一致性。
-
数据库的写实时性和读实时性需求 对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出来这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比方说发一条消息之 后,过几秒乃至十几秒之后,我的订阅者才看到这条动态是完全可以接受的。
-
对复杂的SQL查询,特别是多表关联查询的需求 任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的报表查询,特别是SNS类型的网站,从需求以及产品设计角 度,就避免了这种情况的产生。往往更多的只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能被极大的弱化了。
当负载过大时mongodb的主从同步存在明显延迟,导致有时候读取不到最新的数据。
正常使用场景这种延迟几乎是感知不到的,但是如果写入负载特别大的情况下可能就会出现较为明显的延迟。关于这一点也不是mongodb的问题,因为CAP理论决定了一致性、可用性和分区容忍性只能3取2,对于大多数据分布式数据库来说都是选择A(可用性)和P(分区容忍性)放弃C(一致性),转而追求要求不那么高的最终一致性。
注:CAP理论中的C(一致性)指的是线性一致性(强一致性),与之对应的是最终一致性(弱一致性)。
也就是说无论负载如何,延迟都是一定存在的,只是时间长短的问题。如果你的业务非常强依赖这里的一致性,那么一定要在逻辑上进行保证而不是把希望寄托于“运气”或负载高低之上。
原文链接:https://blog.csdn.net/mijichui2153/article/details/119852738
mongodb:存储引擎
存储引擎是MongoDB的核心组件,负责管理数据如何存储在硬盘和内存上。从MongoDB 3.2 版本开始,MongoDB 支持多数据存储引擎,MongoDB支持的存储引擎有:WiredTiger,MMAPv1和In-Memory。从mongodb3.2开始默认的存储引擎是WiredTiger,3.3版本之前的默认存储引擎是MMAPv1,mongodb4.x版本不再支持MMAPv1存储引擎。线上服务的MongoDB版本为3.2。
MMAPV1:
直到2.6版本MMAPV1都是采用读-写 [1] 锁进行并发控制,即允许并发读访问一个数据库,但是对于相同库的单个写操作之间只能是排他性的【库级别锁】。这就意味着当有一个读锁存在的时候,任意其他读操作也能共用该读锁。而当一个单个写操作持有写锁的时候,其他任何读或写操作都不能共用该写锁,故只能等待。
从3.0版本开始,MMAPv1存储引擎采用集合级别锁,这也是对早期版本的改进,早期版本中,库锁是最细粒度的锁。
WiredTiger:
支持文档级别锁,对于大多数读写操作,WiredTiger使用乐观并发控制。即WiredTiger只在全局、数据库和集合级别使用意向锁。
一、数据压缩
MMAPV1:
因为是基于内存映射文件,所以MMAPV1不支持压缩。如果所有数据都能放入内存那么它将变的非常高效。MMAPV1善于处理大量插入、删除及更新的工作场景。
WiredTiger:
支持snappy和zlib两种压缩模式。因此与MMAP相比,使用WiredTiger的MongoDB占用的磁盘空间要小很多。并且WiredTiger引擎本身有自己的写缓存(可配置)同时也能使用文件系统缓存。
Snappy: 默认压缩策略,兼顾高效计算机合理的压缩。
Zlib: 高压缩比但是同时对cpu消耗也比较大。
二、Journal日志
MMAPV1:
对于该引擎Journal可确保写入的”原子”性,即当某些修改在提交到数据文件之前MongoDB发生了崩溃,此时MongoDB可以使用journal日志在下次启动的时候应用对应修改操作到数据文件以保持数据一致性。
WiredTiger:
对于该引擎journal日志可以确保两个检查点之间所有数据修改的持久化。因此任何数据库的崩溃只需要最后一次检查点后的journal日志即可。大多数情况下对于引擎来说journal日志是不必要的,只有你想确保能恢复到崩溃之前最后一次成功的时候才需要使用journal日志。否则,MongoDB通常可以从最后一个有效checkpoint进行恢复,默认情况下MongoDB每分钟做一次checkpoint。
三、锁和并发控制
MMAPV1:
直到2.6版本MMAPV1都是采用读-写 [1] 锁进行并发控制,即允许并发读访问一个数据库,但是对于相同库的单个写操作之间只能是排他性的【库级别锁】。这就意味着当有一个读锁存在的时候,任意其他读操作也能共用该读锁。而当一个单个写操作持有写锁的时候,其他任何读或写操作都不能共用该写锁,故只能等待。
从3.0版本开始,MMAPv1存储引擎采用集合级别锁,这也是对早期版本的改进,早期版本中,库锁是最细粒度的锁。
WiredTiger:
支持文档级别锁,对于大多数读写操作,WiredTiger使用乐观并发控制。即WiredTiger只在全局、数据库和集合级别使用意向锁。
在性能调优方面,可以通过设置不同的内部缓存大小cache,size,读写并发控制read/wrire tickets。检查点触发的时间间隔设置。
综上在多核系统中可以有效的提升性能。
四、内存使用
MMAPV1:
该引擎下MongoDB将会使用机器所有的空闲内存作为自己的缓存。系统资源监控会显示MongoDB使用了大量的内存,但是这样的使用是动态的。假如有一个其他的进程突然想申请机器一半的内存,此时MonoDB将会让出自己的缓存内存给该进程使用。
从技术层面讲,MMAPV1引擎下的MongoDB内存由操作系统的虚拟内存子系统来管理。这就意味着MongoDB将使用尽可能多的空闲内存,并根据需要交换到磁盘。故给MongoDB足以覆盖所有热数据的内存容量将会使得MongoDB获得最佳的性能。
WiredTiger:
该引擎会同时使用引擎内部缓存和操作系统缓存资源。对于文件系统缓存,MongoDB将会自动使用WiredTiger缓存外及其他进程不使用的所有空闲内存。
从3.4版本开始WiredTiger引擎将默认使用如下两者中最大的那个缓存大小:
50% of (RAM – 1 GB)
256 MB
以上来自:https://zhuanlan.zhihu.com/p/387876849?utm_id=0
参考:
https://www.infoq.cn/article/hr3fclptdbxf9j8epo9o
https://cloud.tencent.com/developer/news/713601
https://ost.51cto.com/posts/11671

