需求描述:
ucloud的hadoop大数据使用的hive不支持高可用,hive经常出问题,商务和其他业务同事通过hue或者zeeplin查询的时候经常不出结果,重启hive服务后就好了,过一段时间就又不行了,需要反复重启,比较头疼
在网上搜索了一下关于hive的高可用方案:
1.通过zookeeper对hive进行管理(后面测试发现不行,停用其中一台hiveserver2,zookeeper确实能感应到,但是查询依然报错空指针)
2.通过haproxy做代理,后面跟hive集群即可(推荐),不过这时候haproxy成了一个单点,暂时无法解决,只能添加监控进行监测
hive只是一个客户端,实际的数据是从hadoop的hdfs里面来的,具体架构如下
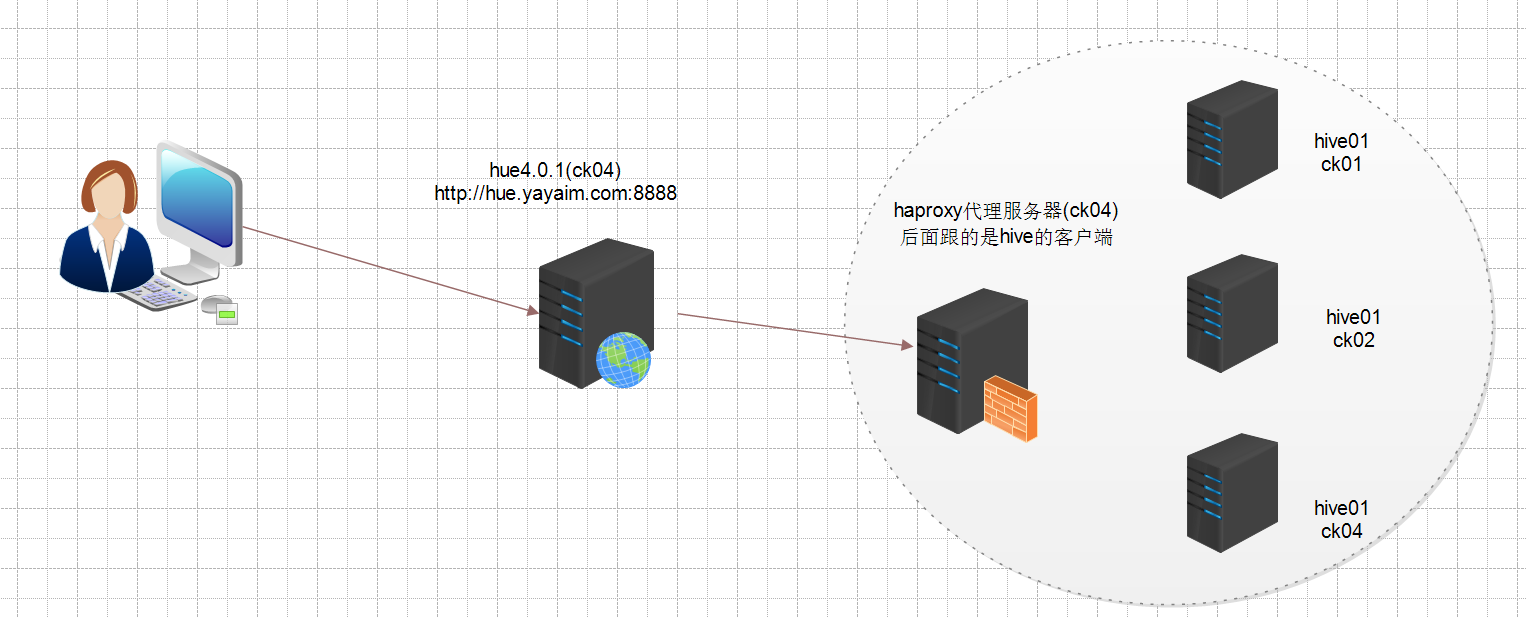 为了不把ucloud的环境弄乱,我重新部署了一套物理隔离的hue+haproxy+hive的环境(避免冲突)
具体如下:
方案一通过zookeeper进行hive的高可用管理(失败案例)
1.配置Hive的环境变量
# Hive environment
export HIVE_HOME=/data/yunva/apache-hive-1.2.2-bin
export PATH=$HIVE_HOME/bin:$HIVE_HOME/conf:$PATH
2.修改配置hive的文件
[root@test6_vedio bin]# cat /data/yunva/apache-hive-1.2.2-bin/conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.10.11.214:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
# 新增加的配置
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value> //两个HiveServer2实例的端口号要一致
</property>
</configuration>
启动一台
在zookeeper里面可以看到
[zk: localhost:2181(CONNECTED) 8] ls /hiveserver2_zk
[serverUri=0.0.0.0:10001;version=1.2.2;sequence=0000000000]
启动另外一台,第二个实例启动后,ZK中可以看到两个都注册上来
[zk: localhost:2181(CONNECTED) 9] ls /hiveserver2_zk
[serverUri=0.0.0.0:10001;version=1.2.2;sequence=0000000000, serverUri=0.0.0.0:10001;version=1.2.2;sequence=0000000001]
JDBC连接
JDBC连接的URL格式为:
jdbc:hive2://<zookeeper quorum>/<dbName>;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
其中:
<zookeeper quorum> 为Zookeeper的集群链接串,如master:2181,slave1:2181,slave2:2181
<dbName> 为Hive数据库,默认为default
serviceDiscoveryMode=zooKeeper 指定模式为zooKeeper
zooKeeperNamespace=hiveserver2 指定ZK中的nameSpace,即参数hive.server2.zookeeper.namespace所定义,我定义为hiveserver2_zk
使用beeline测试连接:
cd $HIVE_HOME/bin
[root@test3 bin]# ./beeline
Beeline version 1.2.2 by Apache Hive
beeline> !connect jdbc:hive2://master:2181,slave1:2181,slave2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk yunva_hive_test01 ""
Connecting to jdbc:hive2://master:2181,slave1:2181,slave2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk
Connected to: Apache Hive (version 1.2.2)
Driver: Hive JDBC (version 1.2.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://master:2181,slave1:2181,slave> show databases;
OK
+----------------+--+
| database_name |
+----------------+--+
| default |
| test |
| yunvatest |
+----------------+--+
3 rows selected (1.839 seconds)
0: jdbc:hive2://master:2181,slave1:2181,slave> use test;
OK
No rows affected (0.051 seconds)
0: jdbc:hive2://master:2181,slave1:2181,slave> show tables;
OK
+-----------+--+
| tab_name |
+-----------+--+
| table2 |
| table3 |
+-----------+--+
2 rows selected (0.052 seconds)
0: jdbc:hive2://master:2181,slave1:2181,slave> select * from table2;
OK
+------------+--------------+--+
| table2.id | table2.name |
+------------+--------------+--+
| 1 | spring |
| 2 | summer |
| 3 | autumn |
| 4 | winter |
+------------+--------------+--+
4 rows selected (0.432 seconds)
0: jdbc:hive2://master:2181,slave1:2181,slave>
可以正常连接
执行一个HQL查询,日志中显示连接到的HiveServer2实例为Node2,停掉Node2中的HiveServer2实例后,需要重新使用!connect命令连接,当关闭第二个hive的时候可以连上,但是当停掉掉beelive在的这台服务器的hive时,zook能感应到,但依然报错
关闭其中一台hiveserver2通过beeline出现空指针,看zookeeper已经剔除掉了第一台,说明这个高可用方案不可行
[zk: localhost:2181(CONNECTED) 61] get /hiveserver2_zk
10.10.125.156
cZxid = 0x3000003f6
ctime = Mon Feb 05 10:21:24 CST 2018
mZxid = 0x3000003f6
mtime = Mon Feb 05 10:21:24 CST 2018
pZxid = 0x300000485
cversion = 19
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 13
numChildren = 1
[zk: localhost:2181(CONNECTED) 62] ls /hiveserver2_zk
[serverUri=test6_vedio:10001;version=1.2.2;sequence=0000000008]
[zk: localhost:2181(CONNECTED) 63] ls /hiveserver2_zk/serverUri=test6_vedio:10001;version=1.2.2;sequence=0000000008
[]
[zk: localhost:2181(CONNECTED) 64] get /hiveserver2_zk/serverUri=test6_vedio:10001;version=1.2.2;sequence=0000000008
test6_vedio:10001
cZxid = 0x300000452
ctime = Mon Feb 05 14:23:54 CST 2018
mZxid = 0x300000452
mtime = Mon Feb 05 14:23:54 CST 2018
pZxid = 0x300000452
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x1608c981022000d
dataLength = 17
numChildren = 0
方案二hue4.0.1+haproxy+hive集群(推荐)
1.配置hive客户端
拷贝hadoop,hive等程序到客户端
①修改环境变量配置文件
export JAVA_HOME=/usr/java/jdk1.8.0_102
export PATH=$JAVA_HOME/bin:$PATH
# hadoop
export HADOOP_HOME_WARN_SUPPRESS=true
export HADOOP_HOME=/root/hadoop-2.6.0
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export YARN_CONF_DIR=$HADOOP_HOME/conf
# Hive
export HIVE_HOME=/root/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf
# HBase
export HBASE_HOME=/root/hbase
export HBASE_CONF_DIR=$HBASE_HOME/conf
# spark
export SPARK_HOME=/root/spark
export SPARK_CONF_DIR=$SPARK_HOME/conf
# pig
export PIG_HOME=/root/pig
export PIG_CONF_DIR=$PIG_HOME/conf
export PIG_CLASSPATH=$HADOOP_HOME/conf
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin:$PIG_HOME/bin:$PATH
umask 022
# Cuda
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:/usr/lib64:/usr/local/cuda/lib64:/usr/local/cuda/lib:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda/bin:$PATH
export HADOOOP_ROOT_LOGGER=DEBUG,console
②修改/etc/hosts
10.19.105.50 u04ck04.yaya.corp
10.19.128.248 uhadoop-bwgkeu-master1
10.19.196.141 uhadoop-bwgkeu-core4
10.19.80.123 uhadoop-bwgkeu-core2
10.19.185.160 uhadoop-bwgkeu-core1
10.19.91.236 uhadoop-bwgkeu-core3
10.19.72.208 uhadoop-bwgkeu-master2
10.19.101.5 uhadoop-bwgkeu-core6
10.19.139.82 uhadoop-bwgkeu-core8
10.19.104.184 uhadoop-bwgkeu-core7
10.19.62.73 uhadoop-bwgkeu-core5
③启动hive客户端程序(3台都需要启动)
cd /root/hive/bin
nohup ./hiveserver2 &
检查10002端口是否正常启动
[root@u04ck01 bin]# ss -tnlp|grep 10002
LISTEN 0 50 *:10002 *:* users:(("java",9920,466))
验证hive是否安装成功
[root@u04ck02 bin]# hive
Logging initialized using configuration in file:/root/hive/conf/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive> show databases;
OK
default
test_hive_ucloud10086
Time taken: 2.02 seconds, Fetched: 2 row(s)
hive> use default;
OK
Time taken: 0.02 seconds
hive> show tables;
OK
dual
t_bin_common_country
t_bin_user_report
t_bin_user_req
t_bin_user_task
t_push_common_city
t_push_common_province
t_push_task_result
t_push_user_app
t_push_user_req
t_script_common_city
t_script_common_province
t_script_user_report
t_script_user_req
...
hive> select * from tbl_voice_live_user_msg limit 1;
OK
1001710 100000 10000 1 2017-09-29 15:36:03.847.+0800 voice:live:msg /voice/live/msg 1506688563847 2017-09-29
Time taken: 0.962 seconds, Fetched: 1 row(s)
2.代理服务器haproxy的配置
[root@u04ck04 hue-4.0.0]# cat /etc/haproxy/haproxy.cfg
global
daemon
nbproc 1
pidfile /var/run/haproxy.pid
defaults
mode tcp #mode { tcp|http|health },tcp 表示4层,http表示7层(对我们没用),health仅作为健康检查使用
retries 2 #尝试2次失败则从集群摘除
option redispatch #如果失效则强制转换其他服务器
option abortonclose #连接数过大自动关闭
maxconn 1024 #最大连接数
timeout connect 1d #连接超时时间,重要,hive查询数据能返回结果的保证
timeout client 1d #同上
timeout server 1d #同上
timeout check 8000 #健康检查时间
log 127.0.0.1 local0 err #[err warning info debug]
listen admin_stats #定义管理界面
bind 0.0.0.0:6080 #管理界面访问IP和端口
mode http #管理界面所使用的协议
maxconn 10 #最大连接数
stats refresh 30s #30秒自动刷新
stats uri / #访问url
stats realm Hive\ Haproxy #验证窗口提示
stats auth admin:haproxyadmin2017 #401验证用户名密码
listen hive #hive后端定义
bind 0.0.0.0:10001 #ha作为proxy所绑定的IP和端口
mode tcp #以4层方式代理,重要
balance leastconn #调度算法 'leastconn' 最少连接数分配,或者 'roundrobin',轮询分配
maxconn 1024 #最大连接数
server hive_01 10.10.125.156:10001 check inter 10000 rise 1 fall 2 #释义:server 主机代名(你自己能看懂就行),IP:端口 每1000毫秒检查一次。
server hive_02 10.10.50.133:10001 check inter 10000 rise 1 fall 2 #同上,另外一台服务器。
3.hue的安装和配置
初始化hue数据库
# 新建数据库,字符集一定要是utf8不能是utf8mb4否则报错
create database hue4db charset=utf8;
授权给hue4db/hue4db所有权限
cd build/env/bin
2.1) bin/hue syncdb # 数据库同步的时候是根据hue.ini配置文件的database部分连接mysql进行初始化的
2.2) bin/hue migrate
直接拷贝生产环境3.1的hue配置,然后修改hue.ini配置:
[beeswax]
hive_server_host=uhadoop-bwgkeu-master2
hive_conf_dir=/root/hive/conf
[hbase]
hbase_conf_dir=/root/hbase/conf
[[database]]
host=10.19.128.248
port=3306
engine=mysql
user=hue4db
password=hue4db
name=hue4db
监控的添加:
1.hue的web监控
2.haproxy的代理端口监控
3.各hive的终端的10002端口监控
为了不把ucloud的环境弄乱,我重新部署了一套物理隔离的hue+haproxy+hive的环境(避免冲突)
具体如下:
方案一通过zookeeper进行hive的高可用管理(失败案例)
1.配置Hive的环境变量
# Hive environment
export HIVE_HOME=/data/yunva/apache-hive-1.2.2-bin
export PATH=$HIVE_HOME/bin:$HIVE_HOME/conf:$PATH
2.修改配置hive的文件
[root@test6_vedio bin]# cat /data/yunva/apache-hive-1.2.2-bin/conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.10.11.214:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
# 新增加的配置
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value> //两个HiveServer2实例的端口号要一致
</property>
</configuration>
启动一台
在zookeeper里面可以看到
[zk: localhost:2181(CONNECTED) 8] ls /hiveserver2_zk
[serverUri=0.0.0.0:10001;version=1.2.2;sequence=0000000000]
启动另外一台,第二个实例启动后,ZK中可以看到两个都注册上来
[zk: localhost:2181(CONNECTED) 9] ls /hiveserver2_zk
[serverUri=0.0.0.0:10001;version=1.2.2;sequence=0000000000, serverUri=0.0.0.0:10001;version=1.2.2;sequence=0000000001]
JDBC连接
JDBC连接的URL格式为:
jdbc:hive2://<zookeeper quorum>/<dbName>;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
其中:
<zookeeper quorum> 为Zookeeper的集群链接串,如master:2181,slave1:2181,slave2:2181
<dbName> 为Hive数据库,默认为default
serviceDiscoveryMode=zooKeeper 指定模式为zooKeeper
zooKeeperNamespace=hiveserver2 指定ZK中的nameSpace,即参数hive.server2.zookeeper.namespace所定义,我定义为hiveserver2_zk
使用beeline测试连接:
cd $HIVE_HOME/bin
[root@test3 bin]# ./beeline
Beeline version 1.2.2 by Apache Hive
beeline> !connect jdbc:hive2://master:2181,slave1:2181,slave2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk yunva_hive_test01 ""
Connecting to jdbc:hive2://master:2181,slave1:2181,slave2:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk
Connected to: Apache Hive (version 1.2.2)
Driver: Hive JDBC (version 1.2.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://master:2181,slave1:2181,slave> show databases;
OK
+----------------+--+
| database_name |
+----------------+--+
| default |
| test |
| yunvatest |
+----------------+--+
3 rows selected (1.839 seconds)
0: jdbc:hive2://master:2181,slave1:2181,slave> use test;
OK
No rows affected (0.051 seconds)
0: jdbc:hive2://master:2181,slave1:2181,slave> show tables;
OK
+-----------+--+
| tab_name |
+-----------+--+
| table2 |
| table3 |
+-----------+--+
2 rows selected (0.052 seconds)
0: jdbc:hive2://master:2181,slave1:2181,slave> select * from table2;
OK
+------------+--------------+--+
| table2.id | table2.name |
+------------+--------------+--+
| 1 | spring |
| 2 | summer |
| 3 | autumn |
| 4 | winter |
+------------+--------------+--+
4 rows selected (0.432 seconds)
0: jdbc:hive2://master:2181,slave1:2181,slave>
可以正常连接
执行一个HQL查询,日志中显示连接到的HiveServer2实例为Node2,停掉Node2中的HiveServer2实例后,需要重新使用!connect命令连接,当关闭第二个hive的时候可以连上,但是当停掉掉beelive在的这台服务器的hive时,zook能感应到,但依然报错
关闭其中一台hiveserver2通过beeline出现空指针,看zookeeper已经剔除掉了第一台,说明这个高可用方案不可行
[zk: localhost:2181(CONNECTED) 61] get /hiveserver2_zk
10.10.125.156
cZxid = 0x3000003f6
ctime = Mon Feb 05 10:21:24 CST 2018
mZxid = 0x3000003f6
mtime = Mon Feb 05 10:21:24 CST 2018
pZxid = 0x300000485
cversion = 19
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 13
numChildren = 1
[zk: localhost:2181(CONNECTED) 62] ls /hiveserver2_zk
[serverUri=test6_vedio:10001;version=1.2.2;sequence=0000000008]
[zk: localhost:2181(CONNECTED) 63] ls /hiveserver2_zk/serverUri=test6_vedio:10001;version=1.2.2;sequence=0000000008
[]
[zk: localhost:2181(CONNECTED) 64] get /hiveserver2_zk/serverUri=test6_vedio:10001;version=1.2.2;sequence=0000000008
test6_vedio:10001
cZxid = 0x300000452
ctime = Mon Feb 05 14:23:54 CST 2018
mZxid = 0x300000452
mtime = Mon Feb 05 14:23:54 CST 2018
pZxid = 0x300000452
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x1608c981022000d
dataLength = 17
numChildren = 0
方案二hue4.0.1+haproxy+hive集群(推荐)
1.配置hive客户端
拷贝hadoop,hive等程序到客户端
①修改环境变量配置文件
export JAVA_HOME=/usr/java/jdk1.8.0_102
export PATH=$JAVA_HOME/bin:$PATH
# hadoop
export HADOOP_HOME_WARN_SUPPRESS=true
export HADOOP_HOME=/root/hadoop-2.6.0
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export YARN_CONF_DIR=$HADOOP_HOME/conf
# Hive
export HIVE_HOME=/root/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf
# HBase
export HBASE_HOME=/root/hbase
export HBASE_CONF_DIR=$HBASE_HOME/conf
# spark
export SPARK_HOME=/root/spark
export SPARK_CONF_DIR=$SPARK_HOME/conf
# pig
export PIG_HOME=/root/pig
export PIG_CONF_DIR=$PIG_HOME/conf
export PIG_CLASSPATH=$HADOOP_HOME/conf
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin:$PIG_HOME/bin:$PATH
umask 022
# Cuda
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:/usr/lib64:/usr/local/cuda/lib64:/usr/local/cuda/lib:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda/bin:$PATH
export HADOOOP_ROOT_LOGGER=DEBUG,console
②修改/etc/hosts
10.19.105.50 u04ck04.yaya.corp
10.19.128.248 uhadoop-bwgkeu-master1
10.19.196.141 uhadoop-bwgkeu-core4
10.19.80.123 uhadoop-bwgkeu-core2
10.19.185.160 uhadoop-bwgkeu-core1
10.19.91.236 uhadoop-bwgkeu-core3
10.19.72.208 uhadoop-bwgkeu-master2
10.19.101.5 uhadoop-bwgkeu-core6
10.19.139.82 uhadoop-bwgkeu-core8
10.19.104.184 uhadoop-bwgkeu-core7
10.19.62.73 uhadoop-bwgkeu-core5
③启动hive客户端程序(3台都需要启动)
cd /root/hive/bin
nohup ./hiveserver2 &
检查10002端口是否正常启动
[root@u04ck01 bin]# ss -tnlp|grep 10002
LISTEN 0 50 *:10002 *:* users:(("java",9920,466))
验证hive是否安装成功
[root@u04ck02 bin]# hive
Logging initialized using configuration in file:/root/hive/conf/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive> show databases;
OK
default
test_hive_ucloud10086
Time taken: 2.02 seconds, Fetched: 2 row(s)
hive> use default;
OK
Time taken: 0.02 seconds
hive> show tables;
OK
dual
t_bin_common_country
t_bin_user_report
t_bin_user_req
t_bin_user_task
t_push_common_city
t_push_common_province
t_push_task_result
t_push_user_app
t_push_user_req
t_script_common_city
t_script_common_province
t_script_user_report
t_script_user_req
...
hive> select * from tbl_voice_live_user_msg limit 1;
OK
1001710 100000 10000 1 2017-09-29 15:36:03.847.+0800 voice:live:msg /voice/live/msg 1506688563847 2017-09-29
Time taken: 0.962 seconds, Fetched: 1 row(s)
2.代理服务器haproxy的配置
[root@u04ck04 hue-4.0.0]# cat /etc/haproxy/haproxy.cfg
global
daemon
nbproc 1
pidfile /var/run/haproxy.pid
defaults
mode tcp #mode { tcp|http|health },tcp 表示4层,http表示7层(对我们没用),health仅作为健康检查使用
retries 2 #尝试2次失败则从集群摘除
option redispatch #如果失效则强制转换其他服务器
option abortonclose #连接数过大自动关闭
maxconn 1024 #最大连接数
timeout connect 1d #连接超时时间,重要,hive查询数据能返回结果的保证
timeout client 1d #同上
timeout server 1d #同上
timeout check 8000 #健康检查时间
log 127.0.0.1 local0 err #[err warning info debug]
listen admin_stats #定义管理界面
bind 0.0.0.0:6080 #管理界面访问IP和端口
mode http #管理界面所使用的协议
maxconn 10 #最大连接数
stats refresh 30s #30秒自动刷新
stats uri / #访问url
stats realm Hive\ Haproxy #验证窗口提示
stats auth admin:haproxyadmin2017 #401验证用户名密码
listen hive #hive后端定义
bind 0.0.0.0:10001 #ha作为proxy所绑定的IP和端口
mode tcp #以4层方式代理,重要
balance leastconn #调度算法 'leastconn' 最少连接数分配,或者 'roundrobin',轮询分配
maxconn 1024 #最大连接数
server hive_01 10.10.125.156:10001 check inter 10000 rise 1 fall 2 #释义:server 主机代名(你自己能看懂就行),IP:端口 每1000毫秒检查一次。
server hive_02 10.10.50.133:10001 check inter 10000 rise 1 fall 2 #同上,另外一台服务器。
3.hue的安装和配置
初始化hue数据库
# 新建数据库,字符集一定要是utf8不能是utf8mb4否则报错
create database hue4db charset=utf8;
授权给hue4db/hue4db所有权限
cd build/env/bin
2.1) bin/hue syncdb # 数据库同步的时候是根据hue.ini配置文件的database部分连接mysql进行初始化的
2.2) bin/hue migrate
直接拷贝生产环境3.1的hue配置,然后修改hue.ini配置:
[beeswax]
hive_server_host=uhadoop-bwgkeu-master2
hive_conf_dir=/root/hive/conf
[hbase]
hbase_conf_dir=/root/hbase/conf
[[database]]
host=10.19.128.248
port=3306
engine=mysql
user=hue4db
password=hue4db
name=hue4db
监控的添加:
1.hue的web监控
2.haproxy的代理端口监控
3.各hive的终端的10002端口监控

 浙公网安备 33010602011771号
浙公网安备 33010602011771号