
1.环境信息
整体架构
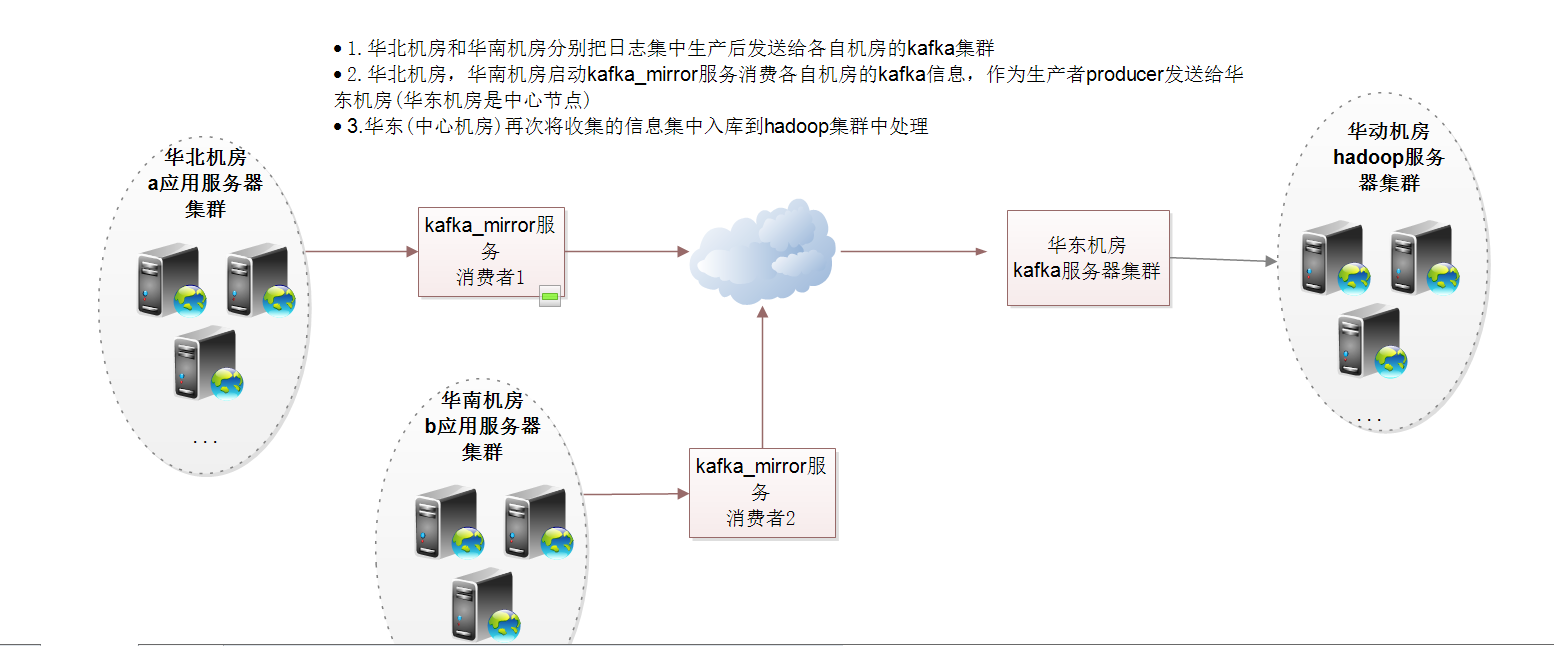 不同的机房的producer向中心节点发送信息,中心节点内部局域网消费信息进入hadoop集群
部署服务器基本信息
外网IP 操作系统 内网IP 安装服务
1.1.1.1_yqmusic01 centos7.2_x86_64 10.19.97.25 kafka,zook
2.2.2.2_yqmusic02 centos7.2_x86_64 10.19.48.131 kafka,zook
3.3.3.3_ck04 centos6.5_x86_64 10.19.105.50 kafka,zook
依赖的jdk1.8.0_111
export JAVA_HOME=/usr/java/jdk1.8.0_111
export PATH=$JAVA_HOME/bin:$PATH
2.安装配置zookeeper3.4.11
Linux服务器一台、三台、五台、(2*n+1),Zookeeper集群的工作是超过半数才能对外提供服务,3台中超过两台超过半数,允许1台挂掉 ,是否可以用偶数,答案是不能
下载地址
https://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz
创建数据和日志目录
mkdir -p /home/yunva/zookeeper-3.4.11/data
mkdir -p /home/yunva/zookeeper-3.4.11/logs
修改配置文件
#zoo_sample.cfg 这个文件是官方给我们的zookeeper的样板文件,给他复制一份命名为zoo.cfg,zoo.cfg是官方指定的文件命名规则
cd /home/yunva/zookeeper-3.4.11
cp zoo_sample.cfg zoo.cfg
# egrep '^[a-Z]' /home/yunva/zookeeper-3.4.11/conf/zoo.cfg
tickTime=6000
initLimit=50
syncLimit=25
snapshot=5000
preAllocSize=1000
dataDir=/home/yunva/zookeeper-3.4.11/data
dataLogDir=/home/yunva/zookeeper-3.4.11/logs
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=10.19.97.25:2888:3888
server.2=10.19.48.131:2888:3888
server.3=10.19.105.50:2888:3888
配置文件解释:
#tickTime:
这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
#initLimit:
这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
#syncLimit:
这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是5*2000=10秒
#dataDir:
快照日志的存储路径
#dataLogDir:
事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir制定的目录,这样会严重影响zk的性能,当zk吞吐量较大的时候,产生的事物日志、快照日志太多
#clientPort:
这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
生成myid
主机(10.19.97.25)
echo "1" >/home/yunva/zookeeper-3.4.11/myid ##生成ID,这里需要注意, myid对应的zoo.cfg的server.ID,比如第二台zookeeper主机对应的myid应该是2
主机(10.19.48.131)
echo "2" >/home/yunva/zookeeper-3.4.11/myid
主机(10.19.105.50)
echo "3" >/home/yunva/zookeeper-3.4.11/myid
# 将配置好的zookeeper程序拷贝到其他2台服务器中
scp -P 28290 -r zookeeper-3.4.11/ 10.19.105.50:/home/yunva/ # 记得有反斜杠,否则就散落在/home/yunva目录了
# 分别启动三台zookeeper服务
[root@u04yq01 zookeeper-3.4.11]# pwd
/home/yunva/zookeeper-3.4.11
[root@u04yq01 zookeeper-3.4.11]# bin/zkServer.sh start
# 查看状态,其中两台为follower,一台为leader
[root@u04yq01 zookeeper-3.4.11]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/yunva/zookeeper-3.4.11/bin/../conf/zoo.cfg
Mode: follower
[root@u04ck04 zookeeper-3.4.11]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/yunva/zookeeper-3.4.11/bin/../conf/zoo.cfg
Mode: leader
查看zook节点相关信息
/home/yunva/zookeeper-3.4.11/bin/zkCli.sh -server 127.0.0.1:2181
3.Kafka集群搭建安装kafka(三台主机上执行)
1、软件环境
1、linux一台或多台,大于等于2
2、已经搭建好的zookeeper集群
3、软件版本kafka_2.11-0.11.0.2.tgz
2、创建目录并下载安装软件
一些基本的概念:
1、消费者:(Consumer):从消息队列中请求消息的客户端应用程序
2、生产者:(Producer) :向broker发布消息的应用程序
3、AMQP服务端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列,便于fafka将生产者发送的消息,动态的添加到磁盘并给每一条消息一个偏移量,所以对于kafka一个broker就是一个应用程序的实例
kafka支持的客户端语言:Kafka客户端支持当前大部分主流语言,包括:C、C++、Erlang、Java、.net、perl、PHP、Python、Ruby、Go、Javascript
可以使用以上任何一种语言和kafka服务器进行通信(即辨析自己的consumer从kafka集群订阅消息也可以自己写producer程序)
4、主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题。
5、分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列。
kafka分区是提高kafka性能的关键所在,当你发现你的集群性能不高时,常用手段就是增加Topic的分区,分区里面的消息是按照从新到老的顺序进行组织,消费者从队列头订阅消息,生产者从队列尾添加消息。
创建kafka数据目录并下载安装软件
mkdir -p /data/kafkadata/kafka-logs
下载二进制文件kafka_2.11-0.11.0.2.tgz
https://archive.apache.org/dist/kafka/0.11.0.1/kafka_2.11-0.11.0.1.tgz
#解压软件
tar zxf kafka_2.11-0.9.0.1.tgz
主要关注:server.properties 这个文件即可,我们可以发现在目录下
这里可以发现有Zookeeper文件,我们可以根据Kafka内带的zk集群来启动,但是建议使用独立的zk集群
修改配置文件:
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
port=9092 #当前kafka对外提供服务的端口默认是9092
listeners=PLAINTEXT://u04yq01.yaya.corp:9092 #这个参数默认是关闭的,配置本机的hostname
num.network.threads=3 #这个是borker进行网络处理的线程数
num.io.threads=8 #这个是borker进行I/O处理的线程数
log.dirs=/data/kafkadata/kafka-logs #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
num.partitions=1 #默认的分区数,一个topic默认1个分区数
log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天
message.max.byte=5242880 #消息保存的最大值5M
default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
replica.fetch.max.bytes=5242880 #取消息的最大直接数
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
zookeeper.connect=10.19.97.25:2181,10.19.48.131:2181,10.19.105.50:2181 #设置zookeeper的连接端口
上面是参数的解释,实际的修改项为:
broker.id=0 每台服务器的broker.id都不能相同
listeners=PLAINTEXT://u04yq01.yaya.corp:9092 # 每台服务器节点都修改为自己的主机名
#在log.retention.hours=168 下面新增下面三项
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
#设置zookeeper集群的连接
zookeeper.connect=192.168.7.100:12181,192.168.7.101:12181,192.168.7.107:12181
配置信息:
节点1:10.19.97.25
[root@u04yq01 config]# egrep '^[a-Z]' server.properties
broker.id=0 # 集群的编号,每个都不一样
listeners=PLAINTEXT://u04yq01.yaya.corp:9092 # 修改为本机hostname,关键配置
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafkadata/kafka-logs # 日志保存路径
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168 # 日志保留时间
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.19.97.25:2181,10.19.48.131:2181,10.19.105.50:2181 # zookeeper集群连接地址
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
节点2:10.19.48.131
[root@u04yq02 kafka_2.11-0.11.0.2]# egrep '^[a-Z]' config/server.properties
broker.id=1
listeners=PLAINTEXT://u04yq02.yaya.corp:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafkadata/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=72
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.19.97.25:2181,10.19.48.131:2181,10.19.105.50:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
节点3:10.19.105.50
[root@u04ck04 config]# egrep '^[a-Z]' server.properties
broker.id=2
listeners=PLAINTEXT://u04ck04.yaya.corp:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafkadata/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=72
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.19.97.25:2181,10.19.48.131:2181,10.19.105.50:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
修改每台主机的/etc/hosts,将集群节点的主机名解析到对应的内网IP中
10.19.97.25 u04yq01.yaya.corp
10.19.48.131 u04yq02.yaya.corp
10.19.105.50 u04ck04.yaya.corp
启动Kafka集群并测试
①启动kafka服务
#从后台启动Kafka集群(3台都需要启动)
cd /home/yunva/kafka_2.11-0.11.0.2 #进入到kafka的bin目录
bin/kafka-server-start.sh -daemon config/server.properties
②检查服务是否启动
#执行命令jps
[root@u04yq01 yunva]# jps
17472 JarLauncher
17926 JarLauncher
17801 Kafka
# 列出topics
[root@u04yq01 ~]# /home/yunva/kafka_2.11-0.11.0.2/bin/kafka-topics.sh --list --zookeeper localhost:2181
SCRIPT-BI-TOPIC
__consumer_offsets
登录zk来查看zk的目录情况
[root@u04yq01 yunva]# zookeeper-3.4.11/bin/zkCli.sh -server
[zk: localhost:2181(CONNECTED) 0] get /brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://u04yq01.yaya.corp:9092"],"jmx_port":-1,"host":"u04yq01.yaya.corp","timestamp":"1515745869088","port":9092,"version":4}
cZxid = 0x10000001e
ctime = Fri Jan 12 16:31:09 CST 2018
mZxid = 0x10000001e
mtime = Fri Jan 12 16:31:09 CST 2018
pZxid = 0x10000001e
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x104df61b4bd0001
dataLength = 204
numChildren = 0
[zk: localhost:2181(CONNECTED) 3] get /brokers/topics/SCRIPT-BI-TOPIC/partitions/0/state
{"controller_epoch":1,"leader":2,"version":1,"leader_epoch":0,"isr":[2,0]}
cZxid = 0x100000033
ctime = Fri Jan 12 16:57:28 CST 2018
mZxid = 0x100000033
mtime = Fri Jan 12 16:57:28 CST 2018
pZxid = 0x100000033
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 74
numChildren = 0
③测试kafka集群是否ok
手动测试方法可以参考:http://www.cnblogs.com/reblue520/p/7853116.html
也可以通过测试脚本来测试:
不同的机房的producer向中心节点发送信息,中心节点内部局域网消费信息进入hadoop集群
部署服务器基本信息
外网IP 操作系统 内网IP 安装服务
1.1.1.1_yqmusic01 centos7.2_x86_64 10.19.97.25 kafka,zook
2.2.2.2_yqmusic02 centos7.2_x86_64 10.19.48.131 kafka,zook
3.3.3.3_ck04 centos6.5_x86_64 10.19.105.50 kafka,zook
依赖的jdk1.8.0_111
export JAVA_HOME=/usr/java/jdk1.8.0_111
export PATH=$JAVA_HOME/bin:$PATH
2.安装配置zookeeper3.4.11
Linux服务器一台、三台、五台、(2*n+1),Zookeeper集群的工作是超过半数才能对外提供服务,3台中超过两台超过半数,允许1台挂掉 ,是否可以用偶数,答案是不能
下载地址
https://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz
创建数据和日志目录
mkdir -p /home/yunva/zookeeper-3.4.11/data
mkdir -p /home/yunva/zookeeper-3.4.11/logs
修改配置文件
#zoo_sample.cfg 这个文件是官方给我们的zookeeper的样板文件,给他复制一份命名为zoo.cfg,zoo.cfg是官方指定的文件命名规则
cd /home/yunva/zookeeper-3.4.11
cp zoo_sample.cfg zoo.cfg
# egrep '^[a-Z]' /home/yunva/zookeeper-3.4.11/conf/zoo.cfg
tickTime=6000
initLimit=50
syncLimit=25
snapshot=5000
preAllocSize=1000
dataDir=/home/yunva/zookeeper-3.4.11/data
dataLogDir=/home/yunva/zookeeper-3.4.11/logs
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=10.19.97.25:2888:3888
server.2=10.19.48.131:2888:3888
server.3=10.19.105.50:2888:3888
配置文件解释:
#tickTime:
这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
#initLimit:
这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
#syncLimit:
这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是5*2000=10秒
#dataDir:
快照日志的存储路径
#dataLogDir:
事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir制定的目录,这样会严重影响zk的性能,当zk吞吐量较大的时候,产生的事物日志、快照日志太多
#clientPort:
这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
生成myid
主机(10.19.97.25)
echo "1" >/home/yunva/zookeeper-3.4.11/myid ##生成ID,这里需要注意, myid对应的zoo.cfg的server.ID,比如第二台zookeeper主机对应的myid应该是2
主机(10.19.48.131)
echo "2" >/home/yunva/zookeeper-3.4.11/myid
主机(10.19.105.50)
echo "3" >/home/yunva/zookeeper-3.4.11/myid
# 将配置好的zookeeper程序拷贝到其他2台服务器中
scp -P 28290 -r zookeeper-3.4.11/ 10.19.105.50:/home/yunva/ # 记得有反斜杠,否则就散落在/home/yunva目录了
# 分别启动三台zookeeper服务
[root@u04yq01 zookeeper-3.4.11]# pwd
/home/yunva/zookeeper-3.4.11
[root@u04yq01 zookeeper-3.4.11]# bin/zkServer.sh start
# 查看状态,其中两台为follower,一台为leader
[root@u04yq01 zookeeper-3.4.11]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/yunva/zookeeper-3.4.11/bin/../conf/zoo.cfg
Mode: follower
[root@u04ck04 zookeeper-3.4.11]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/yunva/zookeeper-3.4.11/bin/../conf/zoo.cfg
Mode: leader
查看zook节点相关信息
/home/yunva/zookeeper-3.4.11/bin/zkCli.sh -server 127.0.0.1:2181
3.Kafka集群搭建安装kafka(三台主机上执行)
1、软件环境
1、linux一台或多台,大于等于2
2、已经搭建好的zookeeper集群
3、软件版本kafka_2.11-0.11.0.2.tgz
2、创建目录并下载安装软件
一些基本的概念:
1、消费者:(Consumer):从消息队列中请求消息的客户端应用程序
2、生产者:(Producer) :向broker发布消息的应用程序
3、AMQP服务端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列,便于fafka将生产者发送的消息,动态的添加到磁盘并给每一条消息一个偏移量,所以对于kafka一个broker就是一个应用程序的实例
kafka支持的客户端语言:Kafka客户端支持当前大部分主流语言,包括:C、C++、Erlang、Java、.net、perl、PHP、Python、Ruby、Go、Javascript
可以使用以上任何一种语言和kafka服务器进行通信(即辨析自己的consumer从kafka集群订阅消息也可以自己写producer程序)
4、主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题。
5、分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列。
kafka分区是提高kafka性能的关键所在,当你发现你的集群性能不高时,常用手段就是增加Topic的分区,分区里面的消息是按照从新到老的顺序进行组织,消费者从队列头订阅消息,生产者从队列尾添加消息。
创建kafka数据目录并下载安装软件
mkdir -p /data/kafkadata/kafka-logs
下载二进制文件kafka_2.11-0.11.0.2.tgz
https://archive.apache.org/dist/kafka/0.11.0.1/kafka_2.11-0.11.0.1.tgz
#解压软件
tar zxf kafka_2.11-0.9.0.1.tgz
主要关注:server.properties 这个文件即可,我们可以发现在目录下
这里可以发现有Zookeeper文件,我们可以根据Kafka内带的zk集群来启动,但是建议使用独立的zk集群
修改配置文件:
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
port=9092 #当前kafka对外提供服务的端口默认是9092
listeners=PLAINTEXT://u04yq01.yaya.corp:9092 #这个参数默认是关闭的,配置本机的hostname
num.network.threads=3 #这个是borker进行网络处理的线程数
num.io.threads=8 #这个是borker进行I/O处理的线程数
log.dirs=/data/kafkadata/kafka-logs #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
num.partitions=1 #默认的分区数,一个topic默认1个分区数
log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天
message.max.byte=5242880 #消息保存的最大值5M
default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
replica.fetch.max.bytes=5242880 #取消息的最大直接数
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
zookeeper.connect=10.19.97.25:2181,10.19.48.131:2181,10.19.105.50:2181 #设置zookeeper的连接端口
上面是参数的解释,实际的修改项为:
broker.id=0 每台服务器的broker.id都不能相同
listeners=PLAINTEXT://u04yq01.yaya.corp:9092 # 每台服务器节点都修改为自己的主机名
#在log.retention.hours=168 下面新增下面三项
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
#设置zookeeper集群的连接
zookeeper.connect=192.168.7.100:12181,192.168.7.101:12181,192.168.7.107:12181
配置信息:
节点1:10.19.97.25
[root@u04yq01 config]# egrep '^[a-Z]' server.properties
broker.id=0 # 集群的编号,每个都不一样
listeners=PLAINTEXT://u04yq01.yaya.corp:9092 # 修改为本机hostname,关键配置
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafkadata/kafka-logs # 日志保存路径
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168 # 日志保留时间
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.19.97.25:2181,10.19.48.131:2181,10.19.105.50:2181 # zookeeper集群连接地址
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
节点2:10.19.48.131
[root@u04yq02 kafka_2.11-0.11.0.2]# egrep '^[a-Z]' config/server.properties
broker.id=1
listeners=PLAINTEXT://u04yq02.yaya.corp:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafkadata/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=72
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.19.97.25:2181,10.19.48.131:2181,10.19.105.50:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
节点3:10.19.105.50
[root@u04ck04 config]# egrep '^[a-Z]' server.properties
broker.id=2
listeners=PLAINTEXT://u04ck04.yaya.corp:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafkadata/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=72
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.19.97.25:2181,10.19.48.131:2181,10.19.105.50:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
修改每台主机的/etc/hosts,将集群节点的主机名解析到对应的内网IP中
10.19.97.25 u04yq01.yaya.corp
10.19.48.131 u04yq02.yaya.corp
10.19.105.50 u04ck04.yaya.corp
启动Kafka集群并测试
①启动kafka服务
#从后台启动Kafka集群(3台都需要启动)
cd /home/yunva/kafka_2.11-0.11.0.2 #进入到kafka的bin目录
bin/kafka-server-start.sh -daemon config/server.properties
②检查服务是否启动
#执行命令jps
[root@u04yq01 yunva]# jps
17472 JarLauncher
17926 JarLauncher
17801 Kafka
# 列出topics
[root@u04yq01 ~]# /home/yunva/kafka_2.11-0.11.0.2/bin/kafka-topics.sh --list --zookeeper localhost:2181
SCRIPT-BI-TOPIC
__consumer_offsets
登录zk来查看zk的目录情况
[root@u04yq01 yunva]# zookeeper-3.4.11/bin/zkCli.sh -server
[zk: localhost:2181(CONNECTED) 0] get /brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://u04yq01.yaya.corp:9092"],"jmx_port":-1,"host":"u04yq01.yaya.corp","timestamp":"1515745869088","port":9092,"version":4}
cZxid = 0x10000001e
ctime = Fri Jan 12 16:31:09 CST 2018
mZxid = 0x10000001e
mtime = Fri Jan 12 16:31:09 CST 2018
pZxid = 0x10000001e
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x104df61b4bd0001
dataLength = 204
numChildren = 0
[zk: localhost:2181(CONNECTED) 3] get /brokers/topics/SCRIPT-BI-TOPIC/partitions/0/state
{"controller_epoch":1,"leader":2,"version":1,"leader_epoch":0,"isr":[2,0]}
cZxid = 0x100000033
ctime = Fri Jan 12 16:57:28 CST 2018
mZxid = 0x100000033
mtime = Fri Jan 12 16:57:28 CST 2018
pZxid = 0x100000033
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 74
numChildren = 0
③测试kafka集群是否ok
手动测试方法可以参考:http://www.cnblogs.com/reblue520/p/7853116.html
也可以通过测试脚本来测试:
脚本测试架构
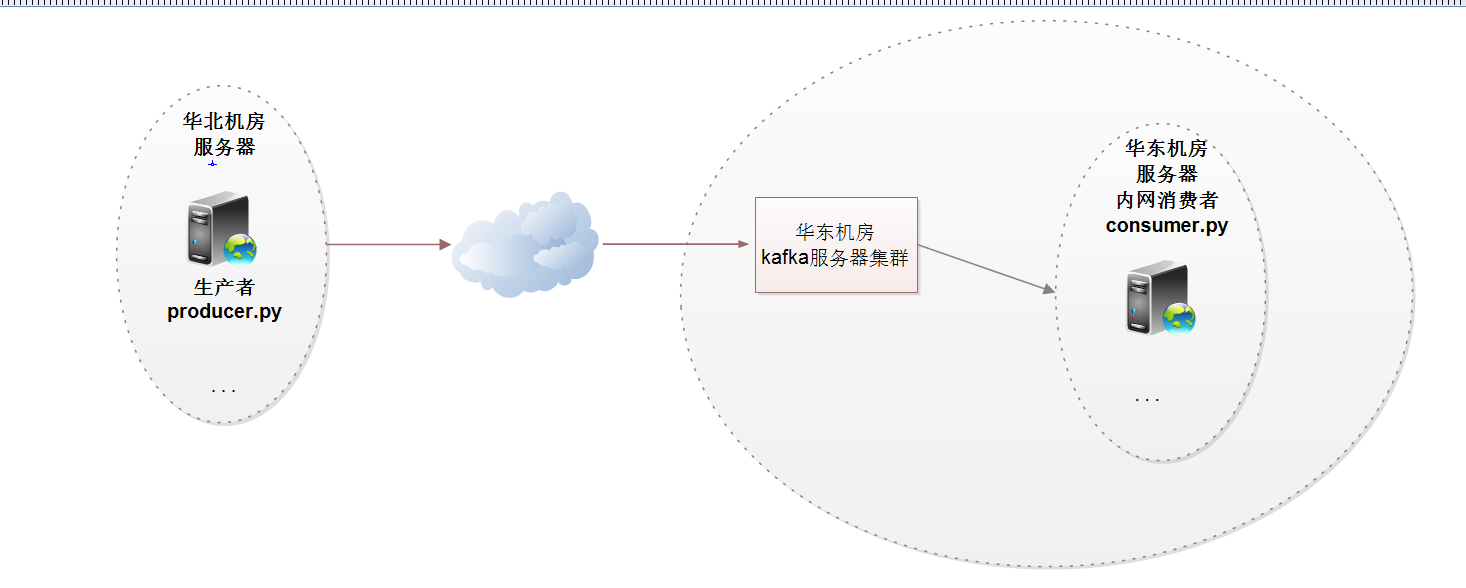 ①机房A的producer生产者
# cat kafka_test.py
# -*- coding: utf-8 -*-
'''''
使用kafka-Python 1.3.3模块
'''
import sys
import time
import json
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
KAFAKA_HOST = "1.1.1.1,2.2.2.2,3.3.3.3"
KAFAKA_PORT = 9092
KAFAKA_TOPIC = "SCRIPT-BI-TOPIC"
class Kafka_producer():
'''''
生产模块:根据不同的key,区分消息
'''
def __init__(self, kafkahost,kafkaport, kafkatopic, key):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.key = key
print("producer:h,p,t,k",kafkahost,kafkaport,kafkatopic,key)
bootstrap_servers = '{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort
)
print("boot svr:",bootstrap_servers)
self.producer = KafkaProducer(bootstrap_servers = bootstrap_servers
)
def sendjsondata(self, params):
try:
parmas_message = json.dumps(params,ensure_ascii=False)
producer = self.producer
print(parmas_message)
v = parmas_message.encode('utf-8')
k = key.encode('utf-8')
print("send msg:(k,v)",k,v)
producer.send(self.kafkatopic, key=k, value= v)
producer.flush()
except KafkaError as e:
print (e)
class Kafka_consumer():
'''''
消费模块: 通过不同groupid消费topic里面的消息
'''
def __init__(self, kafkahost, kafkaport, kafkatopic, groupid):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.groupid = groupid
self.key = key
self.consumer = KafkaConsumer(self.kafkatopic, group_id = self.groupid,
bootstrap_servers = '{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort )
)
def consume_data(self):
try:
for message in self.consumer:
yield message
except KeyboardInterrupt as e:
print (e)
def main(xtype, group, key):
'''''
测试consumer和producer
'''
if xtype == "p":
# 生产模块
producer = Kafka_producer(KAFAKA_HOST, KAFAKA_PORT, KAFAKA_TOPIC, key)
print ("===========> producer:", producer)
for _id in range(1000):
params = '{"msg" : "%s"}' % str(_id)
params=[{"msg0" :_id},{"msg1" :_id}]
producer.sendjsondata(params)
time.sleep(1)
if xtype == 'c':
# 消费模块
consumer = Kafka_consumer(KAFAKA_HOST, KAFAKA_PORT, KAFAKA_TOPIC, group)
print ("===========> consumer:", consumer)
message = consumer.consume_data()
for msg in message:
print ('msg---------------->k,v', msg.key,msg.value)
print ('offset---------------->', msg.offset)
if __name__ == '__main__':
xtype = sys.argv[1]
group = sys.argv[2]
key = sys.argv[3]
main(xtype, group, key)
外网机房A消费者,需要配置/etc/hosts,把kafka集群的外网ip指向他们的hostname
[kafka_producer]# cat /etc/hosts
1.1.1.1 u04yq01.yaya.corp
2.2.2.2 u04yq02.yaya.corp
3.3.3.3 u04ck04.yaya.corp
②中心机房同一内网消费者配置(代码相同部分就省略掉了)
# -*- coding: utf-8 -*-
'''''
使用kafka-Python 1.3.3模块
'''
import sys
import time
import json
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
KAFAKA_HOST = "10.19.97.25,10.19.48.131,10.19.105.50"
KAFAKA_PORT = 9092
KAFAKA_TOPIC = "SCRIPT-BI-TOPIC"
.......
内网消费者/etc/hosts配置
10.19.97.25 u04yq01.yaya.corp
10.19.48.131 u04yq02.yaya.corp
10.19.105.50 u04ck04.yaya.corp
脚本使用方法:
producer生产者
python kafka_test p g v
consumer消费者
python kafka_test c g v
①机房A的producer生产者
# cat kafka_test.py
# -*- coding: utf-8 -*-
'''''
使用kafka-Python 1.3.3模块
'''
import sys
import time
import json
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
KAFAKA_HOST = "1.1.1.1,2.2.2.2,3.3.3.3"
KAFAKA_PORT = 9092
KAFAKA_TOPIC = "SCRIPT-BI-TOPIC"
class Kafka_producer():
'''''
生产模块:根据不同的key,区分消息
'''
def __init__(self, kafkahost,kafkaport, kafkatopic, key):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.key = key
print("producer:h,p,t,k",kafkahost,kafkaport,kafkatopic,key)
bootstrap_servers = '{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort
)
print("boot svr:",bootstrap_servers)
self.producer = KafkaProducer(bootstrap_servers = bootstrap_servers
)
def sendjsondata(self, params):
try:
parmas_message = json.dumps(params,ensure_ascii=False)
producer = self.producer
print(parmas_message)
v = parmas_message.encode('utf-8')
k = key.encode('utf-8')
print("send msg:(k,v)",k,v)
producer.send(self.kafkatopic, key=k, value= v)
producer.flush()
except KafkaError as e:
print (e)
class Kafka_consumer():
'''''
消费模块: 通过不同groupid消费topic里面的消息
'''
def __init__(self, kafkahost, kafkaport, kafkatopic, groupid):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.groupid = groupid
self.key = key
self.consumer = KafkaConsumer(self.kafkatopic, group_id = self.groupid,
bootstrap_servers = '{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort )
)
def consume_data(self):
try:
for message in self.consumer:
yield message
except KeyboardInterrupt as e:
print (e)
def main(xtype, group, key):
'''''
测试consumer和producer
'''
if xtype == "p":
# 生产模块
producer = Kafka_producer(KAFAKA_HOST, KAFAKA_PORT, KAFAKA_TOPIC, key)
print ("===========> producer:", producer)
for _id in range(1000):
params = '{"msg" : "%s"}' % str(_id)
params=[{"msg0" :_id},{"msg1" :_id}]
producer.sendjsondata(params)
time.sleep(1)
if xtype == 'c':
# 消费模块
consumer = Kafka_consumer(KAFAKA_HOST, KAFAKA_PORT, KAFAKA_TOPIC, group)
print ("===========> consumer:", consumer)
message = consumer.consume_data()
for msg in message:
print ('msg---------------->k,v', msg.key,msg.value)
print ('offset---------------->', msg.offset)
if __name__ == '__main__':
xtype = sys.argv[1]
group = sys.argv[2]
key = sys.argv[3]
main(xtype, group, key)
外网机房A消费者,需要配置/etc/hosts,把kafka集群的外网ip指向他们的hostname
[kafka_producer]# cat /etc/hosts
1.1.1.1 u04yq01.yaya.corp
2.2.2.2 u04yq02.yaya.corp
3.3.3.3 u04ck04.yaya.corp
②中心机房同一内网消费者配置(代码相同部分就省略掉了)
# -*- coding: utf-8 -*-
'''''
使用kafka-Python 1.3.3模块
'''
import sys
import time
import json
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
KAFAKA_HOST = "10.19.97.25,10.19.48.131,10.19.105.50"
KAFAKA_PORT = 9092
KAFAKA_TOPIC = "SCRIPT-BI-TOPIC"
.......
内网消费者/etc/hosts配置
10.19.97.25 u04yq01.yaya.corp
10.19.48.131 u04yq02.yaya.corp
10.19.105.50 u04ck04.yaya.corp
脚本使用方法:
producer生产者
python kafka_test p g v
consumer消费者
python kafka_test c g v




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2017-01-13 zabbix通过简单shell命令监控elasticsearch集群状态
2017-01-13 zabbix通过简单命令监控elasticsearch集群状态