zepplin0.7.2报错ERROR, exception: null, result: %text java.lang.NullPointerException的处理
zepplin0.7.2报错ERROR, exception: null, result: %text java.lang.NullPointerException的处理
问题描述:
使用zepplin查询业务系统数据时报错空指针,具体如下:
interpreter.remote.RemoteInterpretershared_session736569169
INFO [2018-01-05 14:54:50,040] ({pool-2-thread-5} Paragraph.java[jobRun]:362) - run paragraph 20180105-103927_694288565 using null org.apache.zeppelin.interpreter.LazyOpenInterpreter@1392e985
WARN [2018-01-05 14:55:29,579] ({pool-2-thread-8} NotebookServer.java[afterStatusChange]:2058) - Job 20180105-103053_111827741 is finished, status: ERROR, exception: null, result: %text java.lang.NullPointerException
at org.apache.zeppelin.spark.Utils.invokeMethod(Utils.java:38)
at org.apache.zeppelin.spark.Utils.invokeMethod(Utils.java:33)
at org.apache.zeppelin.spark.SparkInterpreter.createSparkContext_2(SparkInterpreter.java:391)
at org.apache.zeppelin.spark.SparkInterpreter.createSparkContext(SparkInterpreter.java:380)
at org.apache.zeppelin.spark.SparkInterpreter.getSparkContext(SparkInterpreter.java:146)
at org.apache.zeppelin.spark.SparkInterpreter.open(SparkInterpreter.java:828)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.open(LazyOpenInterpreter.java:70)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:491)
at org.apache.zeppelin.scheduler.Job.run(Job.java:175)
at org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:139)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
INFO [2018-01-05 14:55:29,611] ({pool-2-thread-8} SchedulerFactory.java[jobFinished]:137) - Job paragraph_1515119453288_-2049614157 finished by scheduler org.apache.zeppelin.interpreter.remote.RemoteInterpretershared_session736569169
WARN [2018-01-05 14:55:31,227] ({pool-2-thread-5} NotebookServer.java[afterStatusChange]:2058) - Job 20180105-103927_694288565 is finished, status: ERROR, exception: null, result: %text java.lang.OutOfMemoryError: GC overhead limit exceeded
看了下语句:
(hive)
select appid,count(distinct yunvaid) as c1 from t_user_login
where day='20171228'
group by appid
order by c1 desc
分析:
1.在zepplin的这个任务中查询select * from t_user_login limit 10无法查出数据
2.在另外的查询后台hue中是可以查询这条语句的
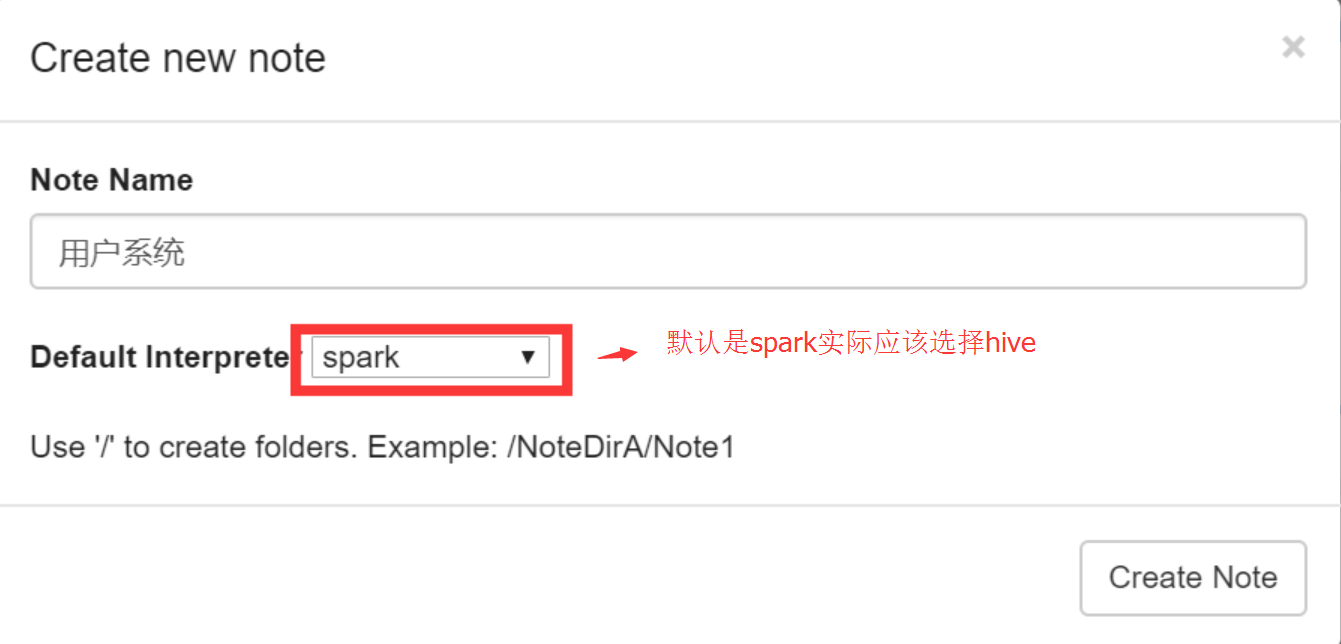
3.新建一个任务hive_tst使用hive类型的,是没问题的
后面直接运行这个任务也可以正常执行
(hive)
select appid,count(distinct yunvaid) as c1 from t_user_login
where day='20171228'
group by appid
order by c1 desc
发现是运营的同事新建任务的时候选择了默认的spark类型所以无法进行查询,我们没有用spark


 浙公网安备 33010602011771号
浙公网安备 33010602011771号