centos6.5环境基于corosync+cman+rgmanager实现RHCS及iscsi+gfs2+clvm的文件系统集群
centos6.5环境基于corosync+cman+rgmanager实现RHCS及iscsi+gfs2+clvm文件系统集群
1、在各节点上配置/etc/hosts文件,不使用DNS解析域名
2、时间同步、在ansible服务器配置免密码访问node2、node3、node4
在ansible服务器中添加rhcs组
# vim /etc/ansible/hosts
加入如下内容:
时间同步
4、关闭几台服务器上的防火墙和selinux(避免干扰)
说明:
不支持在集群节点中使用 NetworkManager 。如果已经在集群节点中安装了 NetworkManager, 您应该 删除或者禁用该程序。
RHCS的配置文件/etc/cluster/cluster.conf,其在每个节点上都必须有一份,且内容均相同,其默认不存在,因此需要事先创建,ccs_tool命令可以完成此任务。另外,每个集群通过集群ID来标识自身,因此,在创建集群配置文件时需要为其选定一个集群名称,这里假设其为mycluster。此命令需要在集群中的某个节点上执行。
在其中的一个节点上创建集群mycluster
# ccs_tool create mycluster
# cd /etc/cluster
# ls
cluster.conf cman-notify.d
# vim cluster.conf
可以看到集群的配置文件中没有集群的信息
通过# ccs_tool -h可以查看ccs_tool的命令帮助
添加集群节点node2、node3和node4
票数为1,节点的id分别为1、2、3
可以看到cluster.conf文件中已经有了集群节点的信息
将node2上的配置文件拷贝到node3和Node4上
# scp cluster.conf node3.chinasoft.com:/etc/cluster
# scp cluster.conf node4.chinasoft.com:/etc/cluster
在节点上安装ricci工具启动服务并设置开机自启动
# ansible rhcs -m yum -a "name=ricci state=present"
# ansible rhcs -m service -a "name=ricci state=started enabled=yes"
此时分别在node2、node3、node4上执行启动cman服务
执行ccs_tool lsnode命令可以看到节点已经启动
# yum install -y scsi-target-utils
在target上添加一块硬盘sdb用作客户端的存储,在sdb上添加两个主分区大小都为20G
使分区生效:
配置target服务端
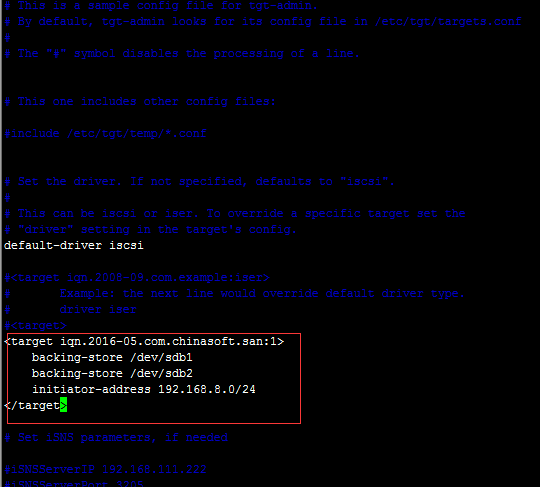
# vim /etc/tgt/targets.conf
<target iqn.2016-05.com.chinasoft.san:1>
backing-store /dev/sdb1
backing-store /dev/sdb2
initiator-address 192.168.8.0/24
</target>
启动tgtd服务
# service tgtd start
Starting SCSI target daemon: [ OK ]
可以看到tgtd服务的3260端口已开启,说明服务正常启动
# ss -tnlp | grep tgtd
LISTEN 0 128 :::3260 :::* users:(("tgtd",1700,5),("tgtd",1701,5))
LISTEN 0 128 *:3260 *:* users:(("tgtd",1700,4),("tgtd",1701,4))
查看配置
在各节点安装iscsi客户端
启动各节点iscsi和iscsid服务,并设置开机自动启动
# ansible rhcs -m service -a "name=iscsi state=started enabled=yes"
# ansible rhcs -m service -a "name=iscsid state=started enabled=yes"
让iscsi客户端发现服务端设备
# ansible rhcs -m shell -a "iscsiadm -m discovery -t sendtargets -p 192.168.8.43"
# ansible rhcs -m shell -a "iscsiadm -m node -T iqn.2016-05.com.chinasoft.san:1 -p 192.168.8.43 -l"
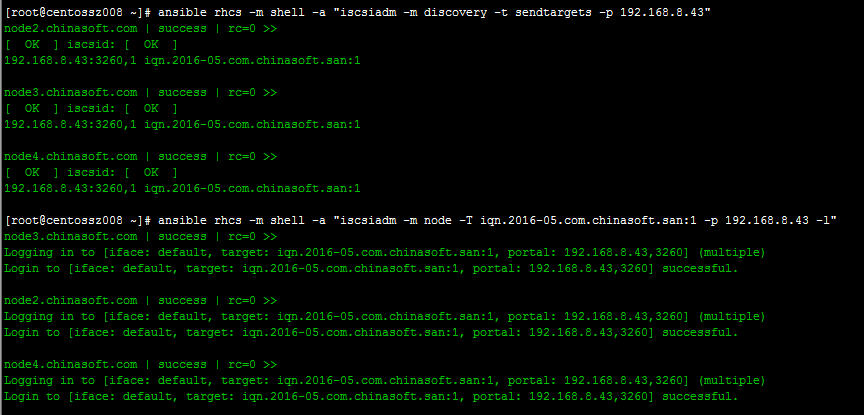
验证是否找到设备
# ansible rhcs -m shell -a "fdisk -l /dev/sd[a-z]"
# ansible rhcs -m yum -a "name=gfs2-utils state=present"
mkfs.gfs2为gfs2文件系统创建工具,其一般常用的选项有:
在其中的节点node2上添加一个10G的主分区
创建sdb1为lock_dlm 分布式文件系统的格式
# mkfs.gfs2 -j 3 -t mycluster:webstore -p lock_dlm /dev/sdb1
This will destroy any data on /dev/sdb1.
It appears to contain: data
Are you sure you want to proceed? [y/n] y
Device: /dev/sdb1
Blocksize: 4096
Device Size 10.00 GB (2621692 blocks)
Filesystem Size: 10.00 GB (2621689 blocks)
Journals: 3
Resource Groups: 41
Locking Protocol: "lock_dlm"
Lock Table: "mycluster:webstore"
UUID: a5a68ae5-4a70-2f52-bd0b-cea491a46475
将/dev/sdb1挂载到mnt上
将fstab拷贝到当前目录
# cp /etc/fstab ./
并编辑fstab加入新内容
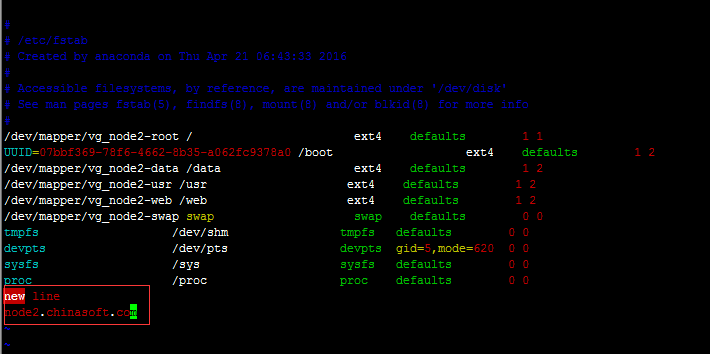
在node3和Node4上分别挂载到/mnt下
# partx -a /dev/sdb
# mount -t gfs2 /dev/sdb1 /mnt
可以看到各节点的fstab文件已经OK
# cat /mnt/fstab
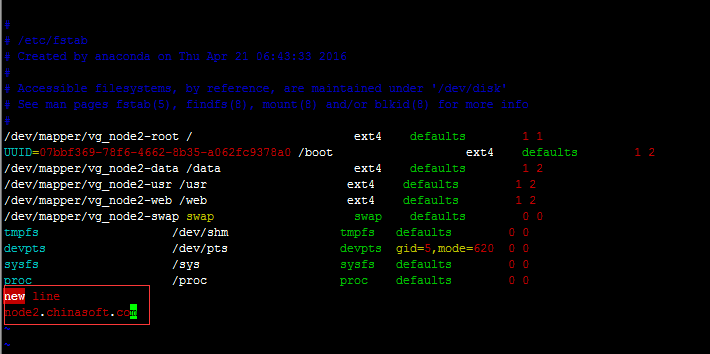
在其中一个节点观察fstab文件
在另外的节点写入内容,其他节点能同步
# echo "hello world" >> /mnt/fstab
# echo "hello world2" >> /mnt/fstab
添加日志
# gfs2_jadd -j 1 /dev/sdb1
Filesystem: /mnt
Old Journals 3
New Journals 4
将文件系统锁住
# gfs2_tool freeze /mnt
文件无法写入内容
# echo "hllo world 3" >> /mnt/fstab
解冻后可以看到顺利写入数据
# gfs2_tool unfreeze /mnt
获取信息
# gfs2_tool gettune /mnt
incore_log_blocks = 8192
log_flush_secs = 60
quota_warn_period = 10
quota_quantum = 60
max_readahead = 262144
complain_secs = 10
statfs_slow = 0
quota_simul_sync = 64
statfs_quantum = 30
quota_scale = 1.0000 (1, 1)
new_files_jdata = 0
将日志的写入时间调整为120秒
# gfs2_tool settune /mnt log_flush_secs 120
获取日志文件的信息
# gfs2_tool journals /mnt
journal2 - 128MB
journal3 - 128MB
journal1 - 128MB
journal0 - 128MB
4 journal(s) found.
在各节点上将文件系统添加到挂载配置中
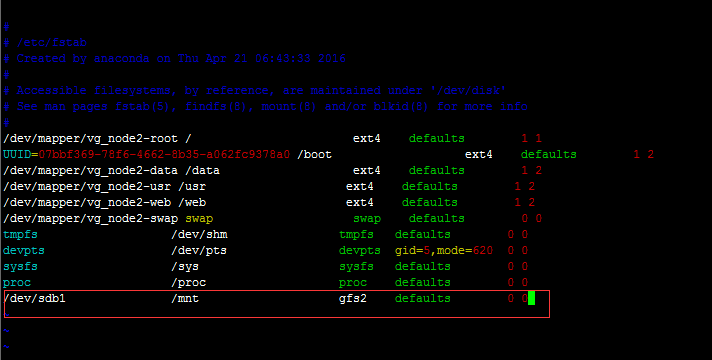
# vim /etc/fstab
/dev/sdb1 /mnt gfs2 defaults 0 0
添加一个10G的分区,并调整为LVM格式
执行两次 partx -a /dev/sdb 让各节点能够识别sdb2
# ansible rhcs -m shell -a "partx -a /dev/sdb"
# ansible rhcs -m yum -a "name=lvm2-cluster state=present"
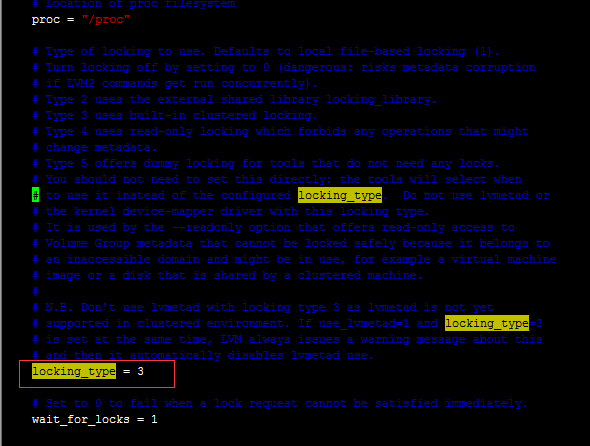
编辑各节点上的/etc/lvm/lvm.conf文件,将locking_type改为3
因为3类型可以用在集群锁中(Type 3 uses built-in clustered locking)
# ansible rhcs -m shell -a 'sed -i "s@^\([[:space:]]*locking_type\).*@\1 = 3@g" /etc/lvm/lvm.conf'
或者执行
# ansible rhcs -m shell -a "lvmconf --enable-cluster"
设置clvmd开机自启动
# ansible rhcs -m service -a "name=clvmd state=started enabled=yes"
在node2节点上配置clvm
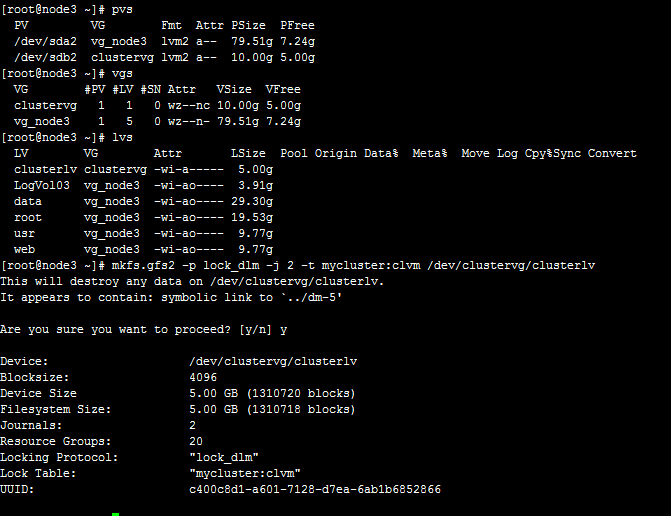
创建卷组和逻辑卷:
# cd
# pvcreate /dev/sdb2
# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 vg_node2 lvm2 a-- 119.51g 22.83g
/dev/sdb2 lvm2 a-- 10.00g 10.00g
# vgcreate clustervg /dev/sdb2
# lvcreate -L 5G -n clusterlv clustervg
-j 2即指定两个日志系统
# mkfs.gfs2 -p lock_dlm -j 2 -t mycluster:clvm /dev/clustervg/clusterlv
在各个节点上执行以下命令进行挂载
# mount /dev/clustervg/clusterlv /media/ -t gfs2
当挂载到第三个节点的时候报错,前面格式化的时候-j 2起到了作用
# mount /dev/clustervg/clusterlv /media
Too many nodes mounting filesystem, no free journals
通过在已经成功挂载的节点上执行添加日志系统,重新挂载成功
# gfs2_jadd -j 1 /dev/clustervg/clusterlv
Filesystem: /media
Old Journals 2
New Journals 3
扩容,将clusterlv增加2G空间
# lvextend -L +2G /dev/clustervg/clusterlv
# gfs2_grow /dev/clustervg/clusterlv
一、环境准备
服务器列表:ansible server : 192.168.8.40 node2.chinasoft.com: 192.168.8.39 node3.chinasoft.com: 192.168.8.41 node4.chinasoft.com: 192.168.8.42 iscsi设备:192.168.8.43
1、在各节点上配置/etc/hosts文件,不使用DNS解析域名
192.168.8.39 node2.chinasoft.com node2 192.168.8.41 node3.chinasoft.com node3 192.168.8.42 node4.chinasoft.com node4
2、时间同步、在ansible服务器配置免密码访问node2、node3、node4
在ansible服务器中添加rhcs组
# vim /etc/ansible/hosts
加入如下内容:
[rhcs] node2.chinasoft.com node3.chinasoft.com node4.chinasoft.com
时间同步
# ansible rhcs -m shell -a "ntpdate -u 192.168.8.102" node2.chinasoft.com | success | rc=0 >> 3 May 09:13:11 ntpdate[1791]: step time server 192.168.8.102 offset 393253.345476 sec node4.chinasoft.com | success | rc=0 >> 3 May 09:13:11 ntpdate[1775]: step time server 192.168.8.102 offset 393211.983109 sec node3.chinasoft.com | success | rc=0 >> 3 May 09:13:12 ntpdate[1803]: step time server 192.168.8.102 offset 339279.739826 sec
4、关闭几台服务器上的防火墙和selinux(避免干扰)
二、安装corosync、cman、rgmanager并配置集群
# ansible rhcs -m yum -a"name=corosync state=present" # ansible rhcs -m yum -a "name=cman state=present" # ansible rhcs -m yum -a "name=rgmanager state=present"
说明:
不支持在集群节点中使用 NetworkManager 。如果已经在集群节点中安装了 NetworkManager, 您应该 删除或者禁用该程序。
RHCS的配置文件/etc/cluster/cluster.conf,其在每个节点上都必须有一份,且内容均相同,其默认不存在,因此需要事先创建,ccs_tool命令可以完成此任务。另外,每个集群通过集群ID来标识自身,因此,在创建集群配置文件时需要为其选定一个集群名称,这里假设其为mycluster。此命令需要在集群中的某个节点上执行。
在其中的一个节点上创建集群mycluster
# ccs_tool create mycluster
# cd /etc/cluster
# ls
cluster.conf cman-notify.d
# vim cluster.conf
可以看到集群的配置文件中没有集群的信息
<?xml version="1.0"?>
<cluster name="mycluster" config_version="1">
<clusternodes>
</clusternodes>
<fencedevices>
</fencedevices>
<rm>
<failoverdomains/>
<resources/>
</rm>
</cluster>通过# ccs_tool -h可以查看ccs_tool的命令帮助
# ccs_tool addnode Usage: ccs_tool addnode [options] <nodename> [<fencearg>=<value>]... -n --nodeid Nodeid (required) -v --votes Number of votes for this node (default 1) -a --altname Alternative name/interface for multihomed hosts -f --fence_type Name reference of fencing to use -c --configfile Name of configuration file (/etc/cluster/cluster.conf) -o --outputfile Name of output file (defaults to same as --configfile) -h --help Display this help text Examples: Add a new node to default configuration file: ccs_tool addnode newnode1 -n 1 -f wti7 port=1 Add a new node and dump config file to stdout rather than save it ccs_tool addnode -o- newnode2 -n 2 -f apc port=1
添加集群节点node2、node3和node4
票数为1,节点的id分别为1、2、3
# ccs_tool addnode node2.chinasoft.com -n 1 -v 1 # ccs_tool addnode node3.chinasoft.com -n 2 -v 1 # ccs_tool addnode node4.chinasoft.com -n 3 -v 1
可以看到cluster.conf文件中已经有了集群节点的信息
<?xml version="1.0"?>
<cluster name="mycluster" config_version="4">
<clusternodes>
<clusternode name="node2.chinasoft.com" votes="1" nodeid="1"/><clusternode name="node3.chinasoft.com" votes="1" nodeid="2"/><clusternode name="node4.chinasoft.com" votes="1" nodeid="3"/></clusternodes>
<fencedevices>
</fencedevices>
<rm>
<failoverdomains/>
<resources/>
</rm>
</cluster>将node2上的配置文件拷贝到node3和Node4上
# scp cluster.conf node3.chinasoft.com:/etc/cluster
# scp cluster.conf node4.chinasoft.com:/etc/cluster
在节点上安装ricci工具启动服务并设置开机自启动
# ansible rhcs -m yum -a "name=ricci state=present"
# ansible rhcs -m service -a "name=ricci state=started enabled=yes"
此时分别在node2、node3、node4上执行启动cman服务
# service cman start Starting cluster: Checking if cluster has been disabled at boot... [ OK ] Checking Network Manager... [ OK ] Global setup... [ OK ] Loading kernel modules... [ OK ] Mounting configfs... [ OK ] Starting cman... [ OK ] Waiting for quorum... [ OK ] Starting fenced... [ OK ] Starting dlm_controld... [ OK ] Tuning DLM kernel config... [ OK ] Starting gfs_controld... [ OK ] Unfencing self... [ OK ] Joining fence domain... [ OK ]
执行ccs_tool lsnode命令可以看到节点已经启动
# ccs_tool lsnode Cluster name: mycluster, config_version: 4 Nodename Votes Nodeid Fencetype node2.chinasoft.com 1 1 node3.chinasoft.com 1 2 node4.chinasoft.com 1 3
三、配置iscsi服务端和客户端
在192.168.8.43节点上安装scsi服务端# yum install -y scsi-target-utils
在target上添加一块硬盘sdb用作客户端的存储,在sdb上添加两个主分区大小都为20G
# fdisk /dev/sdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0x21c2120e.
Changes will remain in memory only, until you decide to write them.
After that, of course, the previous content won't be recoverable.
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-15665, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-15665, default 15665): +20G
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 2
First cylinder (2613-15665, default 2613):
Using default value 2613
Last cylinder, +cylinders or +size{K,M,G} (2613-15665, default 15665): +20G
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.使分区生效:
# partx -a /dev/sdb BLKPG: Device or resource busy error adding partition 1 BLKPG: Device or resource busy error adding partition 2 # cat /proc/partitions major minor #blocks name 8 16 125829120 sdb 8 17 20980858 sdb1 8 18 20980890 sdb2 8 0 83886080 sda 8 1 512000 sda1 8 2 83373056 sda2 253 0 20480000 dm-0 253 1 4096000 dm-1 253 2 15360000 dm-2 253 3 20480000 dm-3 253 4 10240000 dm-4
配置target服务端
# vim /etc/tgt/targets.conf
<target iqn.2016-05.com.chinasoft.san:1>
backing-store /dev/sdb1
backing-store /dev/sdb2
initiator-address 192.168.8.0/24
</target>
启动tgtd服务
# service tgtd start
Starting SCSI target daemon: [ OK ]
可以看到tgtd服务的3260端口已开启,说明服务正常启动
# ss -tnlp | grep tgtd
LISTEN 0 128 :::3260 :::* users:(("tgtd",1700,5),("tgtd",1701,5))
LISTEN 0 128 *:3260 *:* users:(("tgtd",1700,4),("tgtd",1701,4))
查看配置
# tgtadm -L iscsi -o show -m target
Target 1: iqn.2016-05.com.chinasoft.san:1
System information:
Driver: iscsi
State: ready
I_T nexus information:
LUN information:
LUN: 0
Type: controller
SCSI ID: IET 00010000
SCSI SN: beaf10
Size: 0 MB, Block size: 1
Online: Yes
Removable media: No
Prevent removal: No
Readonly: No
Backing store type: null
Backing store path: None
Backing store flags:
LUN: 1
Type: disk
SCSI ID: IET 00010001
SCSI SN: beaf11
Size: 21484 MB, Block size: 512
Online: Yes
Removable media: No
Prevent removal: No
Readonly: No
Backing store type: rdwr
Backing store path: /dev/sdb1
Backing store flags:
LUN: 2
Type: disk
SCSI ID: IET 00010002
SCSI SN: beaf12
Size: 21484 MB, Block size: 512
Online: Yes
Removable media: No
Prevent removal: No
Readonly: No
Backing store type: rdwr
Backing store path: /dev/sdb2
Backing store flags:
Account information:
ACL information:
192.168.8.0/24在各节点安装iscsi客户端
# ansible rhcs -m yum -a "name=iscsi-initiator-utils state=present" # ansible rhcs -m shell -a 'echo "InitiatorName=`iscsi-iname -p iqn.2016-05.com.chinasoft` > /etc/iscsi/initiatorname.iscsi"' node2.chinasoft.com | success | rc=0 >> InitiatorName=iqn.2016-05.com.chinasoft:705b9bd97fc7 > /etc/iscsi/initiatorname.iscsi node3.chinasoft.com | success | rc=0 >> InitiatorName=iqn.2016-05.com.chinasoft:27b437d5e50 > /etc/iscsi/initiatorname.iscsi node4.chinasoft.com | success | rc=0 >> InitiatorName=iqn.2016-05.com.chinasoft:b68414f44a7f > /etc/iscsi/initiatorname.iscsi
启动各节点iscsi和iscsid服务,并设置开机自动启动
# ansible rhcs -m service -a "name=iscsi state=started enabled=yes"
# ansible rhcs -m service -a "name=iscsid state=started enabled=yes"
让iscsi客户端发现服务端设备
# ansible rhcs -m shell -a "iscsiadm -m discovery -t sendtargets -p 192.168.8.43"
# ansible rhcs -m shell -a "iscsiadm -m node -T iqn.2016-05.com.chinasoft.san:1 -p 192.168.8.43 -l"
验证是否找到设备
# ansible rhcs -m shell -a "fdisk -l /dev/sd[a-z]"
四、配置使用gfs2文件系统
在集群节点上安装gfs2-utils# ansible rhcs -m yum -a "name=gfs2-utils state=present"
mkfs.gfs2为gfs2文件系统创建工具,其一般常用的选项有:
-b BlockSize:指定文件系统块大小,最小为512,默认为4096; -J MegaBytes:指定gfs2日志区域大小,默认为128MB,最小值为8MB; -j Number:指定创建gfs2文件系统时所创建的日志区域个数,一般需要为每个挂载的客户端指定一个日志区域; -p LockProtoName:所使用的锁协议名称,通常为lock_dlm或lock_nolock之一; -t LockTableName:锁表名称,一般来说一个集群文件系统需一个锁表名以便让集群节点在施加文件锁时得悉其所关联到的集群文件系统,锁表名称为clustername:fsname,其中的clustername必须跟集群配置文件中的集群名称保持一致,因此,也仅有此集群内的节点可访问此集群文件系统;此外,同一个集群内,每个文件系统的名称必须惟一;
在其中的节点node2上添加一个10G的主分区
# fdisk /dev/sdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0x0a8dee2d.
Changes will remain in memory only, until you decide to write them.
After that, of course, the previous content won't be recoverable.
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-20489, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-20489, default 20489): +10G
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
查看分区是否生效
# cat /proc/partitions
major minor #blocks name
8 0 125829120 sda
8 1 512000 sda1
8 2 125316096 sda2
253 0 30720000 dm-0
253 1 4096000 dm-1
253 2 25600000 dm-2
253 3 30720000 dm-3
253 4 10240000 dm-4
8 16 20980858 sdb
8 17 10486768 sdb1
8 32 20980890 sdc
# cman_tool status
Version: 6.2.0
Config Version: 4
Cluster Name: mycluster
Cluster Id: 65461
Cluster Member: Yes
Cluster Generation: 16
Membership state: Cluster-Member
Nodes: 3
Expected votes: 3
Total votes: 3
Node votes: 1
Quorum: 2
Active subsystems: 7
Flags:
Ports Bound: 0
Node name: node2.chinasoft.com
Node ID: 1
Multicast addresses: 239.192.255.181
Node addresses: 192.168.8.39
创建sdb1为lock_dlm 分布式文件系统的格式
# mkfs.gfs2 -j 3 -t mycluster:webstore -p lock_dlm /dev/sdb1
This will destroy any data on /dev/sdb1.
It appears to contain: data
Are you sure you want to proceed? [y/n] y
Device: /dev/sdb1
Blocksize: 4096
Device Size 10.00 GB (2621692 blocks)
Filesystem Size: 10.00 GB (2621689 blocks)
Journals: 3
Resource Groups: 41
Locking Protocol: "lock_dlm"
Lock Table: "mycluster:webstore"
UUID: a5a68ae5-4a70-2f52-bd0b-cea491a46475
将/dev/sdb1挂载到mnt上
# mount /dev/sdb1 /mnt # cd /mnt # ls # mount /dev/mapper/vg_node2-root on / type ext4 (rw) proc on /proc type proc (rw) sysfs on /sys type sysfs (rw) devpts on /dev/pts type devpts (rw,gid=5,mode=620) tmpfs on /dev/shm type tmpfs (rw) /dev/sda1 on /boot type ext4 (rw) /dev/mapper/vg_node2-data on /data type ext4 (rw) /dev/mapper/vg_node2-usr on /usr type ext4 (rw) /dev/mapper/vg_node2-web on /web type ext4 (rw) none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw) none on /sys/kernel/config type configfs (rw) /dev/sdb1 on /mnt type gfs2 (rw,relatime,hostdata=jid=0)
将fstab拷贝到当前目录
# cp /etc/fstab ./
并编辑fstab加入新内容
在node3和Node4上分别挂载到/mnt下
# partx -a /dev/sdb
# mount -t gfs2 /dev/sdb1 /mnt
可以看到各节点的fstab文件已经OK
# cat /mnt/fstab
在其中一个节点观察fstab文件
# tail -f /mnt/fstab /dev/mapper/vg_node2-data /data ext4 defaults 1 2 /dev/mapper/vg_node2-usr /usr ext4 defaults 1 2 /dev/mapper/vg_node2-web /web ext4 defaults 1 2 /dev/mapper/vg_node2-swap swap swap defaults 0 0 tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 new line node2.chinasoft.com hello world hello world2
在另外的节点写入内容,其他节点能同步
# echo "hello world" >> /mnt/fstab
# echo "hello world2" >> /mnt/fstab
添加日志
# gfs2_jadd -j 1 /dev/sdb1
Filesystem: /mnt
Old Journals 3
New Journals 4
将文件系统锁住
# gfs2_tool freeze /mnt
文件无法写入内容
# echo "hllo world 3" >> /mnt/fstab
解冻后可以看到顺利写入数据
# gfs2_tool unfreeze /mnt
获取信息
# gfs2_tool gettune /mnt
incore_log_blocks = 8192
log_flush_secs = 60
quota_warn_period = 10
quota_quantum = 60
max_readahead = 262144
complain_secs = 10
statfs_slow = 0
quota_simul_sync = 64
statfs_quantum = 30
quota_scale = 1.0000 (1, 1)
new_files_jdata = 0
将日志的写入时间调整为120秒
# gfs2_tool settune /mnt log_flush_secs 120
获取日志文件的信息
# gfs2_tool journals /mnt
journal2 - 128MB
journal3 - 128MB
journal1 - 128MB
journal0 - 128MB
4 journal(s) found.
在各节点上将文件系统添加到挂载配置中
# vim /etc/fstab
/dev/sdb1 /mnt gfs2 defaults 0 0
添加一个10G的分区,并调整为LVM格式
# fdisk /dev/sdb
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 2
First cylinder (10242-20489, default 10242):
Using default value 10242
Last cylinder, +cylinders or +size{K,M,G} (10242-20489, default 20489): +10G
Command (m for help): t
Partition number (1-4): 2
Hex code (type L to list codes): 8e
Changed system type of partition 2 to 8e (Linux LVM)
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.
# partx -a /dev/sdb
BLKPG: Device or resource busy
error adding partition 1
# partx -a /dev/sdb
BLKPG: Device or resource busy
error adding partition 1
BLKPG: Device or resource busy
error adding partition 2执行两次 partx -a /dev/sdb 让各节点能够识别sdb2
# ansible rhcs -m shell -a "partx -a /dev/sdb"
五、配置使用cLVM(集群逻辑卷)
RHCS的核心组件为cman和rgmanager,其中cman为基于openais的“集群基础架构层”,rgmanager为资源管理器。RHCS的集群中资源的配置需要修改其主配置文件/etc/cluster/cluster.xml实现,这对于很多用户来说是比较有挑战性的,因此,RHEL提供了system-config-cluster这个GUI工具,其仅安装在集群中的某一节点上即可,而cman和rgmanager需要分别安装在集群中的每个节点上。这里选择将此三个rpm包分别安装在了集群中的每个节点上,这可以在ansible跳板机上执行如下命令实现:# ansible rhcs -m yum -a "name=lvm2-cluster state=present"
编辑各节点上的/etc/lvm/lvm.conf文件,将locking_type改为3
因为3类型可以用在集群锁中(Type 3 uses built-in clustered locking)
# ansible rhcs -m shell -a 'sed -i "s@^\([[:space:]]*locking_type\).*@\1 = 3@g" /etc/lvm/lvm.conf'
或者执行
# ansible rhcs -m shell -a "lvmconf --enable-cluster"
设置clvmd开机自启动
# ansible rhcs -m service -a "name=clvmd state=started enabled=yes"
在node2节点上配置clvm
创建卷组和逻辑卷:
# cd
# pvcreate /dev/sdb2
# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 vg_node2 lvm2 a-- 119.51g 22.83g
/dev/sdb2 lvm2 a-- 10.00g 10.00g
# vgcreate clustervg /dev/sdb2
# lvcreate -L 5G -n clusterlv clustervg
-j 2即指定两个日志系统
# mkfs.gfs2 -p lock_dlm -j 2 -t mycluster:clvm /dev/clustervg/clusterlv
在各个节点上执行以下命令进行挂载
# mount /dev/clustervg/clusterlv /media/ -t gfs2
当挂载到第三个节点的时候报错,前面格式化的时候-j 2起到了作用
# mount /dev/clustervg/clusterlv /media
Too many nodes mounting filesystem, no free journals
通过在已经成功挂载的节点上执行添加日志系统,重新挂载成功
# gfs2_jadd -j 1 /dev/clustervg/clusterlv
Filesystem: /media
Old Journals 2
New Journals 3
扩容,将clusterlv增加2G空间
# lvextend -L +2G /dev/clustervg/clusterlv
# gfs2_grow /dev/clustervg/clusterlv
至此,基于corosync+cman实现iscsi设备的分布式文件系统配置已完成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号