从0开始学爬虫11之使用requests库下载图片
从0开始学爬虫11之使用requests库下载图片
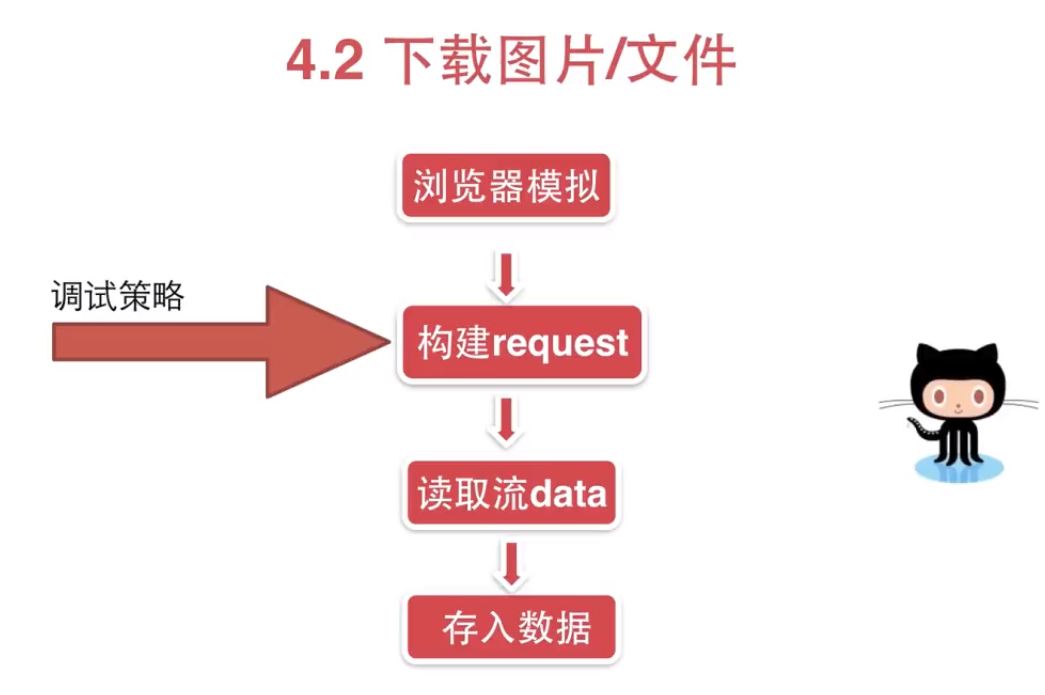
# coding=utf-8 import requests def download_imgage(): ''' demo: 下载图片 ''' headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"} url = "https://ss0.bdstatic.com/94oJfD_bAAcT8t7mm9GUKT-xh_/timg?image&quality=100&size=b4000_4000&sec=1563595148&di=1239a9121c930e1ab892faa7cd0b8f8a&src=http://m.360buyimg.com/pop/jfs/t23434/230/1763906670/10667/55866a07/5b697898N78cd1466.jpg" response = requests.get(url,headers=headers, stream=True) with open('demo.jpg', 'wb') as fd: for chunk in response.iter_content(128): fd.write(chunk) print response.content def download_image_improved(): # 伪造headers信息 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"} # 限定url url = "https://ss0.bdstatic.com/94oJfD_bAAcT8t7mm9GUKT-xh_/timg?image&quality=100&size=b4000_4000&sec=1563595148&di=1239a9121c930e1ab892faa7cd0b8f8a&src=http://m.360buyimg.com/pop/jfs/t23434/230/1763906670/10667/55866a07/5b697898N78cd1466.jpg" response = requests.get(url, headers=headers, stream=True) # contextlib 管理上下文信息 from contextlib import closing # 可以关闭文件流 with closing(requests.get(url, headers=headers, stream=True)) as response: # 打开文件 with open('demo1.jpg', 'wb') as fd: # 每128字节写入一次 for chunk in response.iter_content(128): fd.write(chunk) if __name__ == '__main__': # download_imgage() download_image_improved()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号