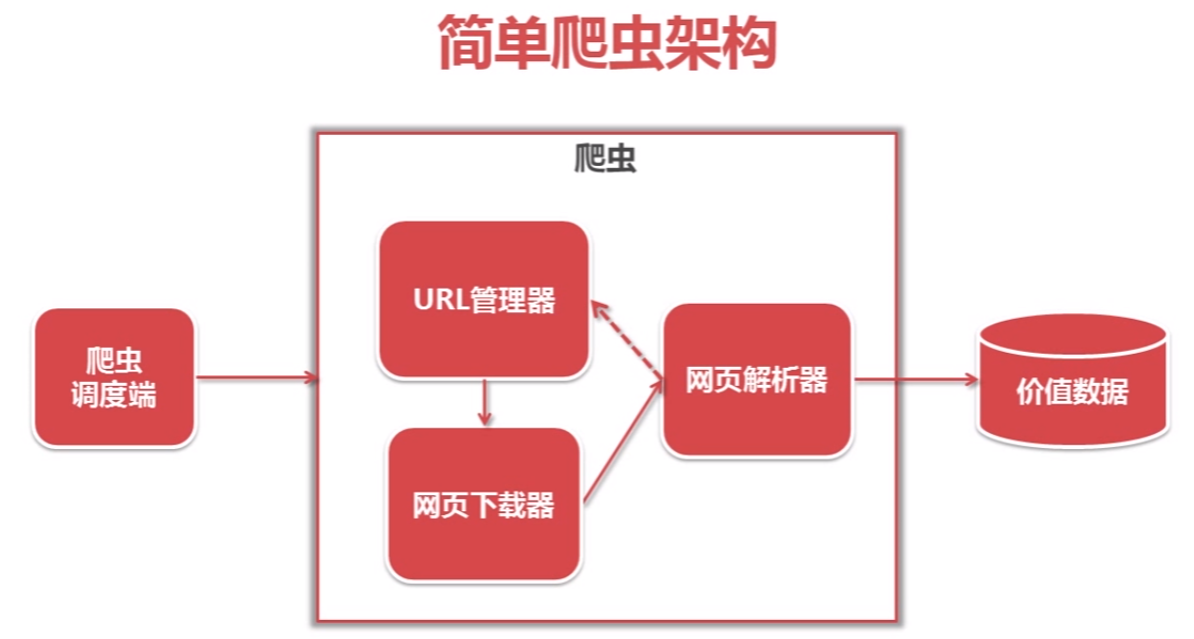
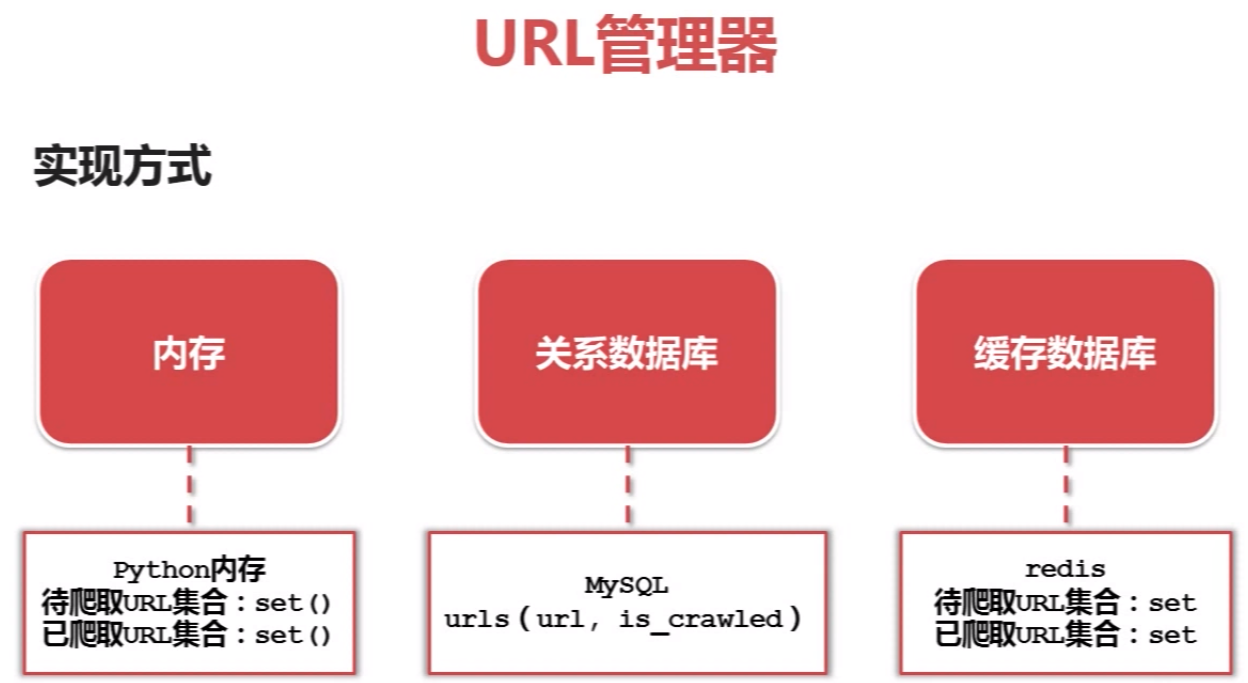
python爬虫简单架构原理及示例


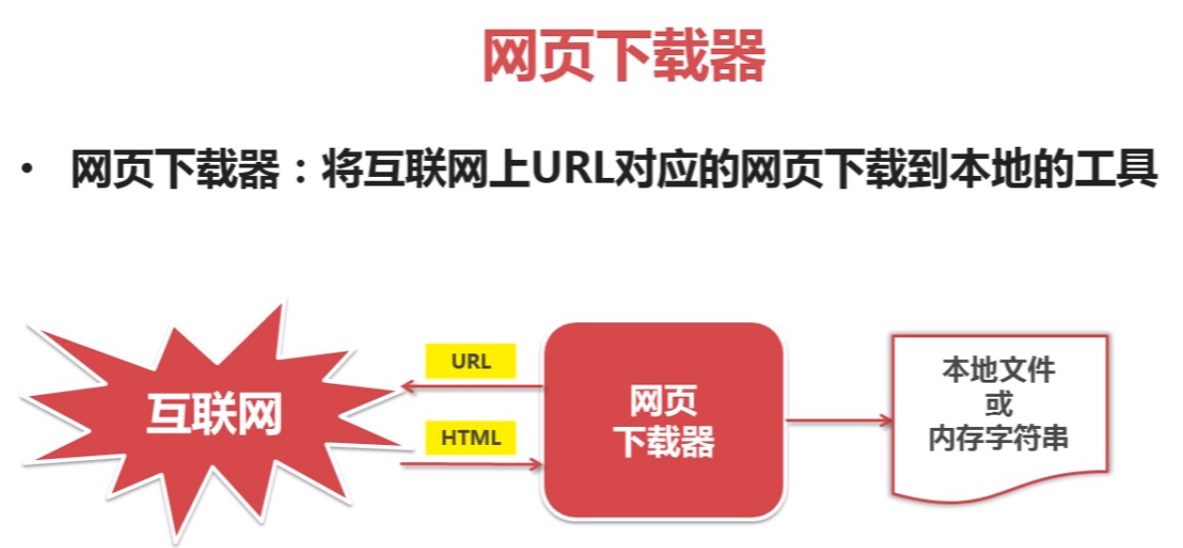

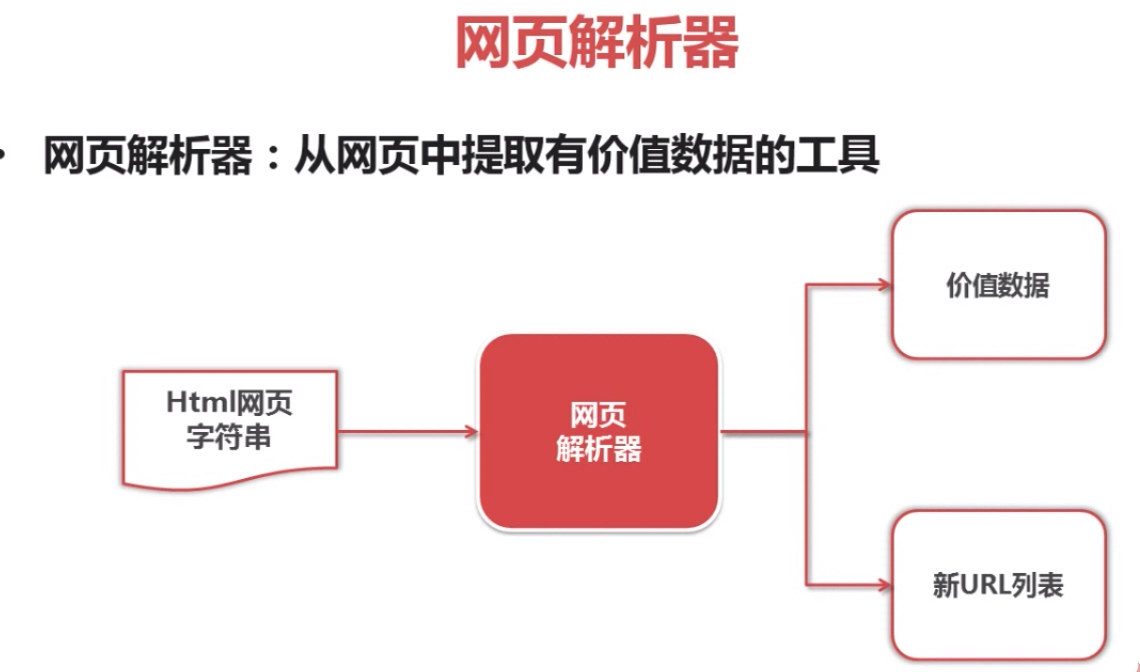
网页下载器示例:
# coding:utf-8 import urllib2 import cookielib url = "http://www.baidu.com" print u"第一种方法" # pip install urllib2 response1 = urllib2.urlopen(url) print response1.getcode() print len(response1.read()) print u"第二种方法" request = urllib2.Request(url) # 把爬虫伪装成浏览器 request.add_header("user-agent", "Mozilla/5.0") response2 = urllib2.urlopen(request) print response2.getcode() print len(response2.read()) print u"第三种方法" # pip install cookielib cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) urllib2.install_opener(opener) response3 = urllib2.urlopen(request) print response3.getcode() print cj print len(response3.read())
# 运行结果


beautifulsoap使用示例
#coding:utf-8 # 安装beautifulsoap4 D:\Python27\Lib>pip install beautifulsoup4 from bs4 import BeautifulSoup import re html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(html_doc, 'html.parser', from_encoding='utf-8') print u'获取所有的链接' links = soup.find_all('a') for link in links: print link.name,link['href'], link.get_text() print u'获取lacie的链接' link_node = soup.find('a', href='http://example.com/lacie') print link_node.name, link_node['href'],link_node.get_text() print u'正则匹配' link_node = soup.find('a', href=re.compile(r"ill")) print link_node.name, link_node['href'],link_node.get_text() print u'获取p段落名字' link_node = soup.find('p', class_="title") print link_node.name, link_node.get_text()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号