
shell编程系列19--文本处理三剑客之awk中的字符串函数
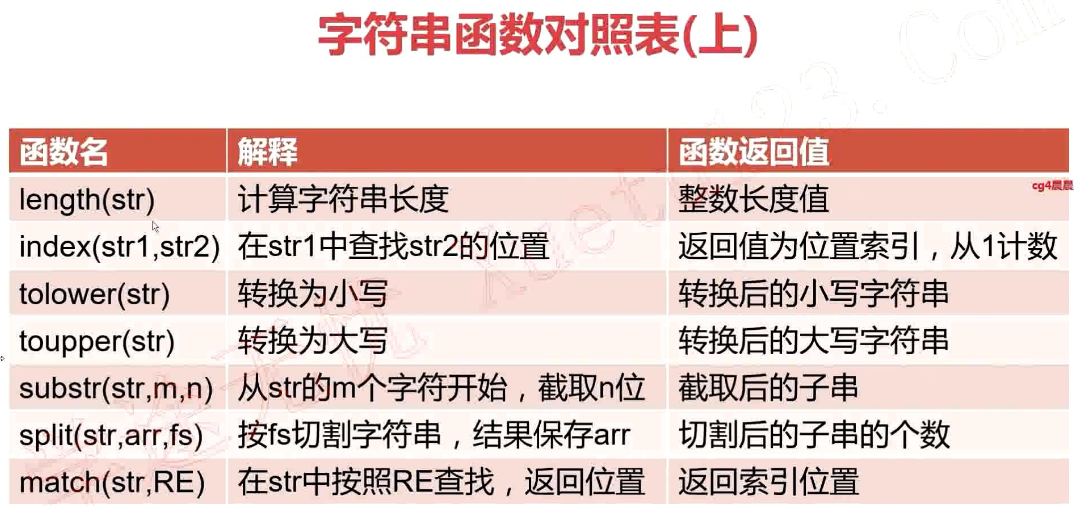
字符串函数对照表(上)
函数名 解释 函数返回值
length(str) 计算字符串长度 整数长度值
index(str1,str2) 在str1中查找str2的位置 返回值为位置索引,从1开始计数
tolower(str) 转换为小写 转换后的小写字符串
toupper(str) 转换为大写 转换后的大写字符串
substr(str,m,n) 从str的m个字符开始,截取n位 截取后的子串
split(str,arr,fs) 按fs切割字符串,结果保存在arr 切割后的子串的个数
match(str,RE) 在str中按照RE查找,返回位置 返回索引位置
字符串函数对照表(下)
函数名 解释 函数返回值
sub(RE,RepStr,str) 在str中搜索符合RE的字串,将其替换为RepStr;只替换第一个 替换的个数
gsub(RE,RepStr,str) 在str中搜索符合RE的字串,将其替换为RepStr;替换所有 替换的个数
 awk中的字符串函数
length(str) 计算长度
index(str1,str2) 返回在str1中查询到的str2的位置
tolower(str) 小写转换
toupper(str) 大写转换
split(str,arr,fs) 分隔字符串,并保持到数组中
match(str,RE) 返回正则表达式匹配到的子串的位置
substr(str,m,n) 截取子串,从m个字符开始,截取n位,n若不指定,则默认
sub(RE,RepStr,str) 替换查找到的第一个子串
gsub(RE,RepStr,str) 替换查找到的所有子串
1、以:为分隔符,返回/etc/passwd中每行中每个字段的长度
[root@localhost shell]# cat len.awk
BEGIN{
FS=":"
}
{
i=1
while(i<=NF)
{
if (i==NF)
{
printf "%d",length($i)
}
else
{
printf "%d:",length($i)
}
i++
}
print ""
}
[root@localhost shell]# awk -f len.awk passwd
4:1:1:1:4:5:9
3:1:1:1:3:4:13
6:1:1:1:6:5:13
3:1:1:1:3:8:13
2:1:1:1:2:14:13
...
2、搜索字符串"I have a dream"中出现"ea"字符串的位置
[root@localhost shell]# awk 'BEGIN{str="I have a gream";printf "%d\n",index(str,"ea")}'
12
3、将字符串"Hadoop is a bigdata Framework"全部转换为小写
[root@localhost shell]# awk 'BEGIN{str="Hadoop is a bigdata Framework";print tolower(str)}'
hadoop is a bigdata framework
4、将字符串"Hadoop is a bigdata Framework"全部转换为大写
[root@localhost shell]# awk 'BEGIN{str="Hadoop is a bigdata Framework";print toupper(str)}'
HADOOP IS A BIGDATA FRAMEWORK
5、将字符串"Hadoop Kafka Spark Storm HDFS YARN Zookeeper",按照空格为分隔符,分隔
[root@localhost shell]# awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr);for (i in arr) print arr[i];}'
Storm
HDFS
YARN
Zookeeper
Hadoop
Kafka
Spark
6、搜索字符串"Transaction 2345 Start:Select * from master"第一个数字出现的位置
[root@localhost shell]# awk 'BEGIN{str="Transaction 2345 Start:Select * from master";print match(str,/[0-9]/)}'
13
7、截取字符串"transaction start"的子串,截取条件从第4个字符开始,截取5位
[root@localhost shell]# awk 'BEGIN{str="transaction start";print substr(str,4,5)}'
nsact
8、替换字符串"Transaction 243 Start,Event ID:9002"中第一个匹配到的数字串替换为$符号
[root@localhost shell]# awk 'BEGIN{str="Transaction 243 Start,Event ID:9002";count=sub(/[0-9]+/,"$",str);print count;print str}'
1
Transaction $ Start,Event ID:9002
# gsub是替换全部匹配到的数字
[root@localhost shell]# awk 'BEGIN{str="Transaction 243 Start,Event ID:9002";count=gsub(/[0-9]+/,"$",str);print count;print str}'
2
Transaction $ Start,Event ID:$
# 在awk中数组下标从1开始
[root@localhost shell]# awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr," ");print arr[0]}'
[root@localhost shell]# awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr," ");print arr[1]}'
Hadoop
[root@localhost shell]# awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr," ");print arr[2]}'
Kafka
[root@localhost shell]# awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr," ");for(i in arr) {print arr[i]}}'
Storm
HDFS
YARN
Zookeeper
Hadoop
Kafka
Spark
awk中的字符串函数
length(str) 计算长度
index(str1,str2) 返回在str1中查询到的str2的位置
tolower(str) 小写转换
toupper(str) 大写转换
split(str,arr,fs) 分隔字符串,并保持到数组中
match(str,RE) 返回正则表达式匹配到的子串的位置
substr(str,m,n) 截取子串,从m个字符开始,截取n位,n若不指定,则默认
sub(RE,RepStr,str) 替换查找到的第一个子串
gsub(RE,RepStr,str) 替换查找到的所有子串
1、以:为分隔符,返回/etc/passwd中每行中每个字段的长度
[root@localhost shell]# cat len.awk
BEGIN{
FS=":"
}
{
i=1
while(i<=NF)
{
if (i==NF)
{
printf "%d",length($i)
}
else
{
printf "%d:",length($i)
}
i++
}
print ""
}
[root@localhost shell]# awk -f len.awk passwd
4:1:1:1:4:5:9
3:1:1:1:3:4:13
6:1:1:1:6:5:13
3:1:1:1:3:8:13
2:1:1:1:2:14:13
...
2、搜索字符串"I have a dream"中出现"ea"字符串的位置
[root@localhost shell]# awk 'BEGIN{str="I have a gream";printf "%d\n",index(str,"ea")}'
12
3、将字符串"Hadoop is a bigdata Framework"全部转换为小写
[root@localhost shell]# awk 'BEGIN{str="Hadoop is a bigdata Framework";print tolower(str)}'
hadoop is a bigdata framework
4、将字符串"Hadoop is a bigdata Framework"全部转换为大写
[root@localhost shell]# awk 'BEGIN{str="Hadoop is a bigdata Framework";print toupper(str)}'
HADOOP IS A BIGDATA FRAMEWORK
5、将字符串"Hadoop Kafka Spark Storm HDFS YARN Zookeeper",按照空格为分隔符,分隔
[root@localhost shell]# awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr);for (i in arr) print arr[i];}'
Storm
HDFS
YARN
Zookeeper
Hadoop
Kafka
Spark
6、搜索字符串"Transaction 2345 Start:Select * from master"第一个数字出现的位置
[root@localhost shell]# awk 'BEGIN{str="Transaction 2345 Start:Select * from master";print match(str,/[0-9]/)}'
13
7、截取字符串"transaction start"的子串,截取条件从第4个字符开始,截取5位
[root@localhost shell]# awk 'BEGIN{str="transaction start";print substr(str,4,5)}'
nsact
8、替换字符串"Transaction 243 Start,Event ID:9002"中第一个匹配到的数字串替换为$符号
[root@localhost shell]# awk 'BEGIN{str="Transaction 243 Start,Event ID:9002";count=sub(/[0-9]+/,"$",str);print count;print str}'
1
Transaction $ Start,Event ID:9002
# gsub是替换全部匹配到的数字
[root@localhost shell]# awk 'BEGIN{str="Transaction 243 Start,Event ID:9002";count=gsub(/[0-9]+/,"$",str);print count;print str}'
2
Transaction $ Start,Event ID:$
# 在awk中数组下标从1开始
[root@localhost shell]# awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr," ");print arr[0]}'
[root@localhost shell]# awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr," ");print arr[1]}'
Hadoop
[root@localhost shell]# awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr," ");print arr[2]}'
Kafka
[root@localhost shell]# awk 'BEGIN{str="Hadoop Kafka Spark Storm HDFS YARN Zookeeper";split(str,arr," ");for(i in arr) {print arr[i]}}'
Storm
HDFS
YARN
Zookeeper
Hadoop
Kafka
Spark




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律