0-基本环境
1-安装Scrapy
pip install Scrapy
2-创建项目
scrapy startproject demo
项目创建好以后,会自动生成一些文件和目录如下:
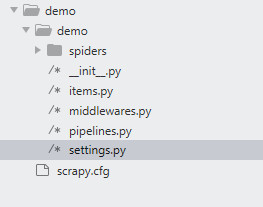
在这里面有一些配置文件和预定义的设置文件,而我们的爬虫代码,可以在 spiders 目录下创建。
这里各个文件的功能描述如下 。
- scrapy.cfg:scrapy 项目配置文件,其内定义了项目的配置文件路径、部署相关信息等内容 。
- items.py:它定义 Item 数据结构,所有的 Item 的定义都可以放这里 。
- pipelines.py:它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放这里。
- settings.py:它定义项目的全局配置。
- middlewares.py:它定义 Spider Middlewares 和 Downloader Middlewares 的实现。
- spiders:其内包含一个个 Spider 的实现,每个Spider 都有一个文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号