
利用Github Actions自动同步博客园最新内容到GitHub首页
仓库地址,动手能力强的直接看代码修改即可!
在GitHub上面创建一个同名仓库,比如我的id为zjy4fun,我就创建一个仓库名为zjy4fun的仓库,里面的README会直接在个人Github首页渲染展示。
想让首页自动更新博客园上面的播客链接,可以使用GitHub自带的CI工具GitHub Actions。
总体的思路:
- 用Python爬取博客园的文章链接
- 编写GitHub Actions的配置脚本
编写爬虫
首先分析博客园的网页(以cnblogs.com/realzhaijiayu为例)
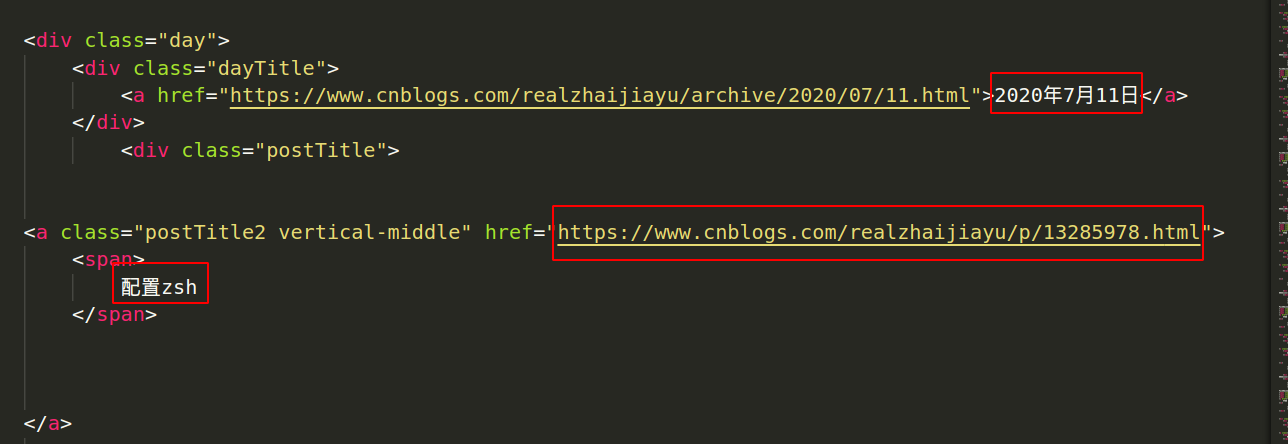
这是一篇文章的HTML结构,上面框里面的内容是我们想要的信息。
借助Python里面的BeautifulSoup库,可以快速地将这些信息提取出来。
'''
爬取博客园某个作者所有文章
'''
from bs4 import BeautifulSoup
import requests
import sys
original_stdout = sys.stdout # Save a reference to the original standard output
def get_bs(author, page=1):
'''
传入作者博客园的id,页数(不传页数则从第一页开始查找)
如果存在下一页按钮,则递归调用自己获取下一页的数据
'''
r = requests.get(f'https://www.cnblogs.com/{author}/default.html?page={page}')
soup = BeautifulSoup(r.content, 'html5lib')
# print(f'第{page}页:')
data_print(soup)
# if soup.select(f'a[href="https://www.cnblogs.com/{author}/default.html?page={page+1}"]'): # 如果有下一页的链接
# get_bs(author, page+1)
def data_print(soup): # 这里可以优化显示文章链接啥的
'''
通过css选择器打印所有日期和文章标题
'''
with open('README.md', 'w') as f:
sys.stdout = f # Change the standard output to the file we created.
for day in soup.select('div.day'):
for date in day.select('div.dayTitle a'):# 每天只有一个日期
for aritle in day.select('a.postTitle2'): # 每天可能有多篇文章
print('- ',date.text, ' ', '[', aritle.get_text().strip(), '](', aritle.get('href'), ')', sep='')
sys.stdout = original_stdout # Reset the standard output to its original value
if __name__ == "__main__":
get_bs('realzhaijiayu')
该脚本可以支持爬取多页内容,我只想要最近的几篇,所以只要第一页的就可以了。
编写Actions配置文件
# This is a basic workflow to help you get started with Actions
name: Refresh
# Controls when the action will run. Triggers the workflow on push or pull request
# events but only for the master branch
on:
push:
schedule:
- cron: '00 * * * *'
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- uses: actions/checkout@v2
- name: Set up Python 3.8
uses: actions/setup-python@v2
with:
python-version: 3.8
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
# Runs a set of commands using the runners shell
- name: run script
run: |
python3 refresh.py
- name: Commit files
run: |
git config --global user.email "zjy4fun@163.com"
git config --global user.name "zjy4fun"
git commit -m "update" -a || exit 0
- name: Push changes
uses: ad-m/github-push-action@master
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
注意的是,该Python脚本需要的三个依赖分别是
requests
bs4
html5lib
需要写在requirements.txt里面。
效果:
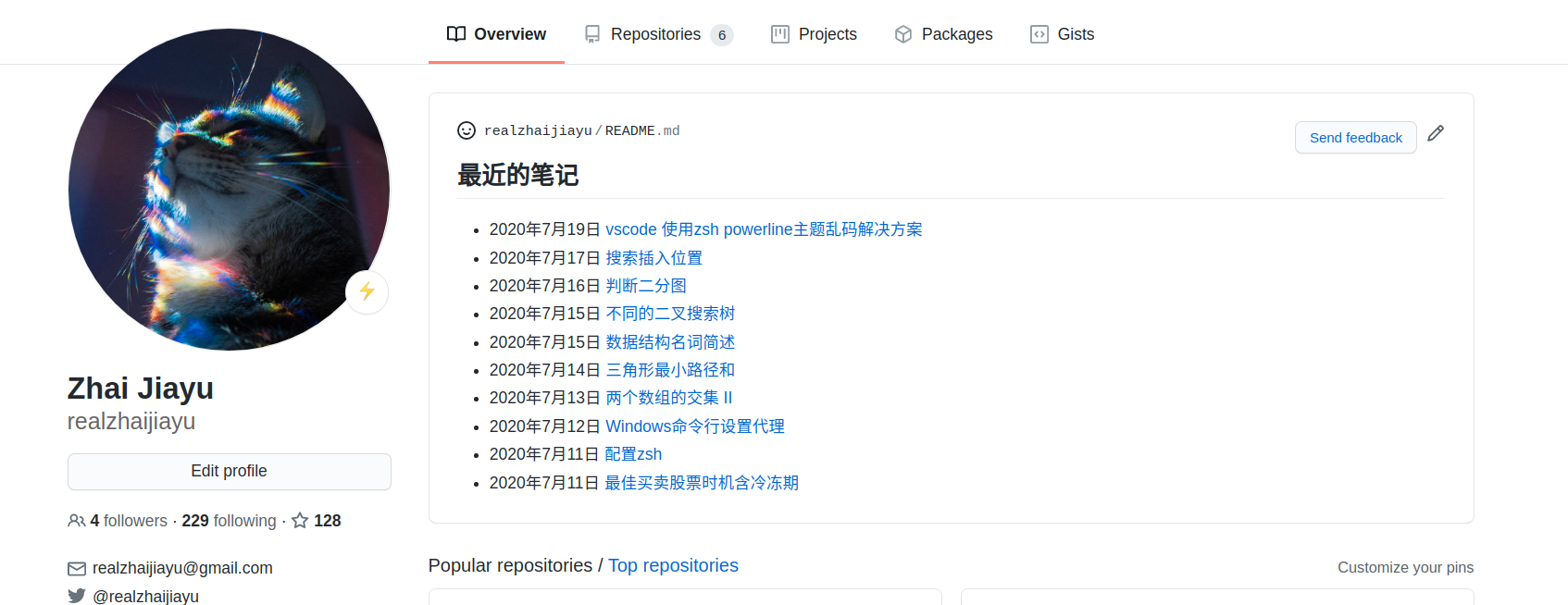
自己动手做
可以直接将仓库clone下来,然后修改部分内容,再上传到自己的同名仓库即可。
需要修改的内容如下:
- 博客园id(refresh.py)
- git配置的邮箱和用户名(.github/workflows/actions.yml)
总结
一开始爬取博客园链接的时候,由于我只会编写shell脚本,导致写起来有点麻烦,光是提取链接就用了很多sed,感觉一点都不优雅。
后面看到别人用Python写的爬虫,代码很简洁,思路非常清晰。对于一个没有学过Python的人,阅读起来也没有任何问题。之所以用Python写这么简单,是因为BeautifulSoup这个库太好用了,不需要i自己动手切割HTML标签,直接指定标签即可,它会自动帮助你提取信息,太爽了!
后面查阅资料,发现好多小工具都是用Python编写的,看来Python有必要学习一下。

