
Python list遍历remove()时的一个小BUG
有这样一个列表:
s=list('abcdefg')
现在因为某种原因我们需要从s中踢出一些不需要的元素,方便起见这里直接以踢出所有元素的循环代替:
for e in s:
s.remove(e)
结果却是:
In [3]: s
Out[3]: ['b', 'd', 'f']
多次示例后发现,这种remove方式保持着隔1删1的规律。
那么改一下代码看看出了什么问题:
In [14]: i=0
In [15]: for e in s:
...: print("第"+str(i)+"次循环删前:s=",s)
...: print(e)
...: s.remove(e)
...: print("第"+str(i)+"次循环删后:s=",s)
...: i=i+1
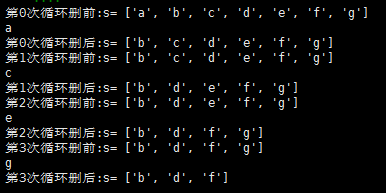
可以看到第1次循环时e的赋值跳过‘b’直接变成了‘c’,这是因为:
第0次for循环后s因为remove了‘a’导致长度减小了1,第1次循环时依然按s[1]给e赋值,可惜此时s=['b','c','d','e','f','g'],导致e=s[1]=‘c’,这样就跳过了‘b’。
这个陷阱在stackoverflow上有较多的讨论,在Python中应避免在遍历序列时直接删除序列的元素,有一个替代的办法是:我们可以遍历s的一个copy:
# s[0:]替换成s.copy()也可以
for e in s[0:]:
s.remove(e)
但是产生copy从效率上讲也不是什么推荐的方式,还有一个办法是直接使用dict来定义一个sequence,只需要把dict的key设置为原list的index即可,这样定义的dict相比list虽然是无序的,但是在很多场景下也是很有用的。
建了一个数据库和编程的交流群,用于交流和提升能力,目前主要专注于Golang/Java/Python以及TiDB数据库,群号:231338927,建群日期:2019.04.26。
如发现博客错误,可直接留言指正,感谢。
