
马蜂窝逆向
前言
如果想看实现可以跳到最后(python代码)。注: 只是非常简单的逆向js,大佬勿喷。
测试:
2020年5月25号 代码运行正常
2020年8月16号 网站已经修改策略,已经写好了更新 https://www.cnblogs.com/re-is-good/p/mafengwo_version2_ast_cookie.html
虽然下面的代码已经对马蜂窝已经无效了,但这种反爬并不是马蜂窝网站独有的。
网站抓取测试
首先上网址: https://www.mafengwo.cn/i/18252205.html
要是使用正常的python代码(如下)来请求这个网址的话
import requests url = "https://www.mafengwo.cn/i/18252205.html" headers = { "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36", "referer": "https://www.mafengwo.cn/i/18252205.html", } r = requests.get(url, headers=headers) print(r.text) # print(r.status_code)
会返回以下结果

对,没错。返回的竟然是script标签。里面包含着js代码。看js代码的样子也不像是加密的html内容。
我们还可以打印一下状态码
print(r.status_code);
返回的是521,一般情况下都是200。这就非常奇怪了。
这时候我们就要去浏览器中打开这个页面,按F12打开开发者页面(mac是fn+F12)
好了,如果打开了开发者工具。那么就刷新下页面吧。
我们会非常惊喜的发现,在浏览器中 这个url的请求(https://www.mafengwo.cn/i/18252205.html)完全正常,而且状态码还是200
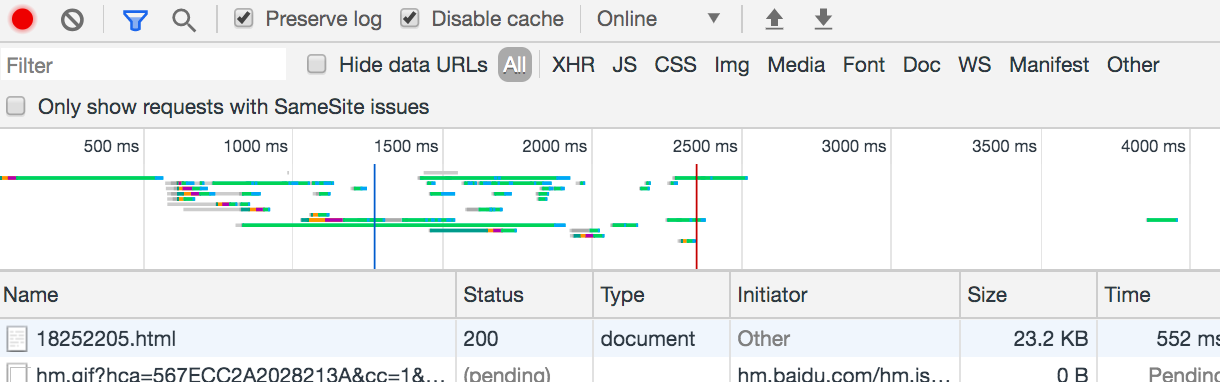
那就去看看在浏览器中这个url请求到底发送了什么?
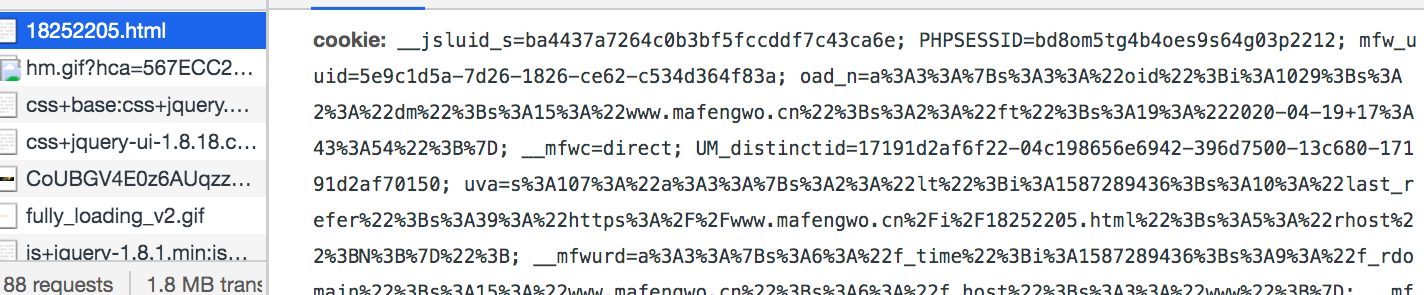
仔细对比的话,就会发现浏览器的请求中有一项cookie,而且cookie内容特别多。
我们可以试着将cookie中的内容放到headers中,然后再发送请求
url = "https://www.mafengwo.cn/i/18252205.html" headers = { "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36", "referer": "https://www.mafengwo.cn/i/18252205.html", "cookie": "_jsluid_s=...;__jsl_clearance=...;", # 浏览器中的cookie部分,因为太长我就没有全部复制了 } r = requests.get(url, headers=headers) print(r.text)
然后就能正常请求了。
我们也可以慢慢删除cookie中的字段,因为服务器不会验证所有的cookie字段。
经过测试,只要 有__jsluid_s 和__jsl_clearance 字段便可以正常请求。
这,这就完了?no no no。
直接拷贝cookie多low啊。
我们要自己生成cookie,其实也就是想办法构造合理的__jsluid_s和__jsl_clearance 字段, 然后想怎么请求就怎么请求。
cookie的生成逻辑
首先啊。我们需要知道怎么清除浏览器的cookie。
为啥子?
因为他的cookie可以重复使用,只有没有cookie或者cookie失效时,才会重新请求。

如上图,在开发者工具中选中 "Application" 工具栏。找到 "Cookie" 侧边栏。右键那个网址,就会有 "clear"选项了。点击 "clear" 就可以清除改网址的所有cookie
做完这件事情后,就可以再次刷新下页面了。
在刷新页面之前,可以清除下之前的网络请求log。不然会新旧请求会跑到一块,不太好辨别
好了,下面是刷新后的网络请求
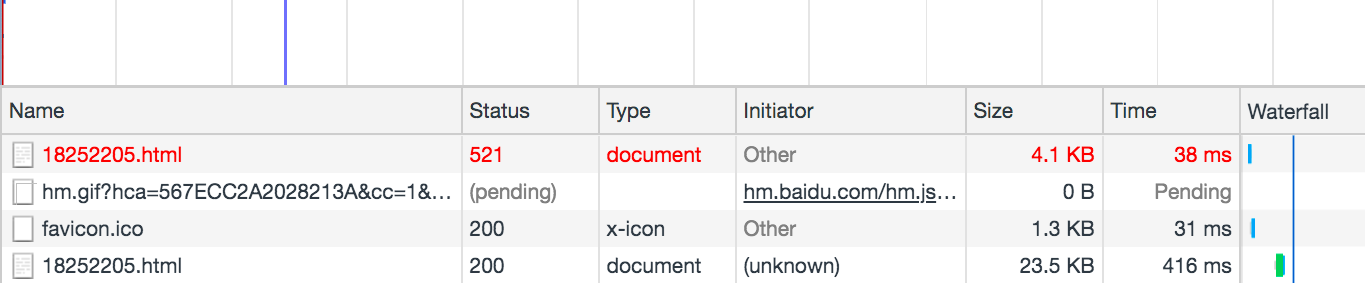
除了那个正常的200请求。我们还会发现还有一个状态码为521的请求(第一个请求)。
这个不就是我们刚开始使用python代码请求后返回的状态码码?
点进去这个请求看看
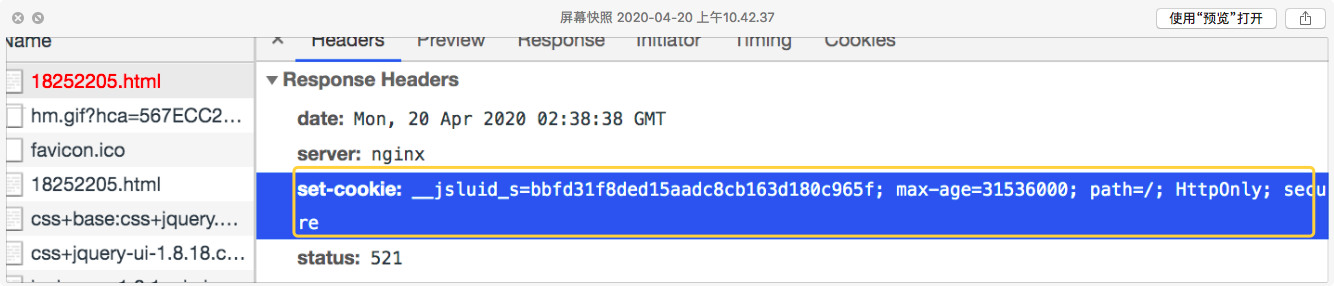
你看,问题解决了一半了。cookie中的 __jsluid_s 字段直接在响应头里了。只要我们搞定 cookie中的 __jsl_clearance 字段便可以发起正常请求了。
下面的代码将获取 __jsluid_s 字段。
import requests url = "https://www.mafengwo.cn/i/18252205.html" headers = { "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36", "referer": "https://www.mafengwo.cn/i/18252205.html", } # 请不要传入cookie,不然浏览器不会在请求头中写入我们需要的字段 r = requests.get(url, headers=headers) print(r.headers) __jsluid_s = r.headers["Set-Cookie"].split(";")[0].split("=")[1] print(__jsluid_s) # 这个便是我们需要的cookie的字段
那剩下的50%,__jsl_clearance 字段怎么弄呢?仔细翻了下响应头,发现毫无 __jsl_clearance 字段的痕迹。
或许 __jsl_clearance 不在这个 状态码为 521 的请求身上?
那我们从第二个请求开始看吧。 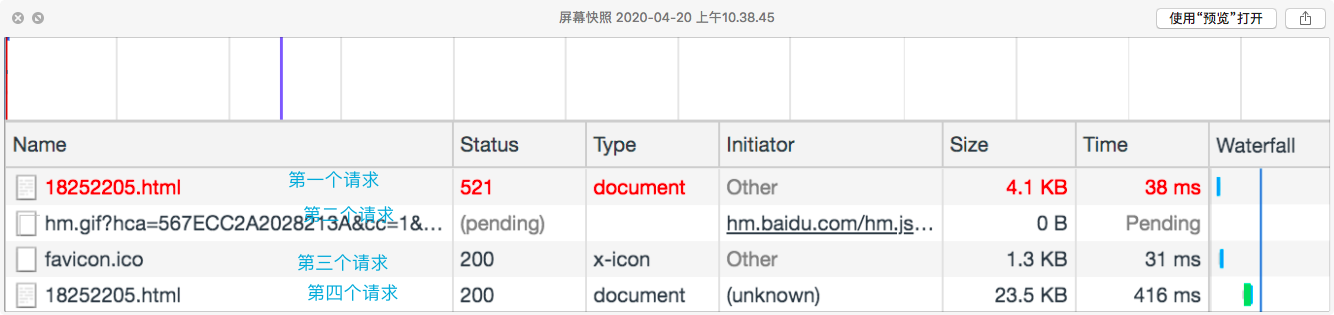
第二个请求

响应头确实有cookie字段,但不是我们想要的
继续看第三个请求

what? 我们需要的cookie字段在这个地方竟然已经被发送出去了。(注意,这里的cookie字段是请求头那里的,而不是响应头那里。
这说明在第三个请求之前, cookie中的__jsl_clearance 字段就已经被设置了。
第二个请求虽然设置了cookie,但不是__jsl_clearance。
那么cookie中的__jsl_clearance 字段只能在第一个请求(状态码为521)里被设置了。
那我们回看一下第一个请求。
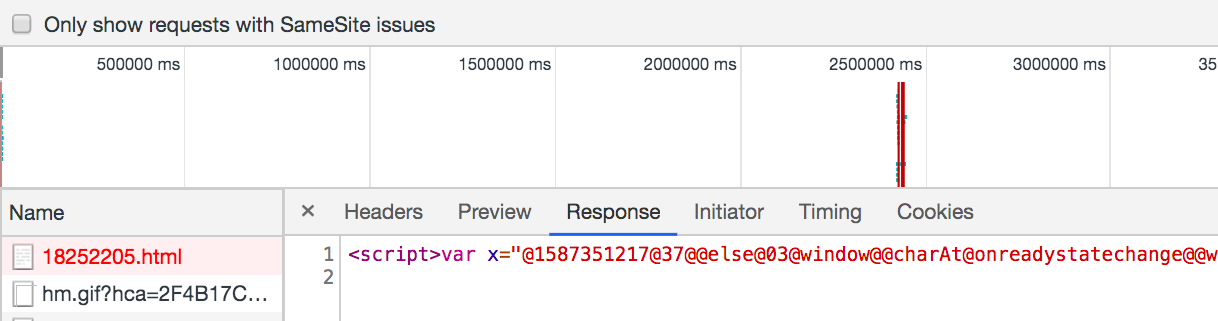
有时候 Response 里不像上图所示的那样,有时会显示 "failed to load response data"。不过没有关系,因为接下来要做的事情与浏览器无关。
如果遇到了 "failed to load response data"。可以直接使用python请求。然后复制了响应内容。(就是上图中的"<script>...")
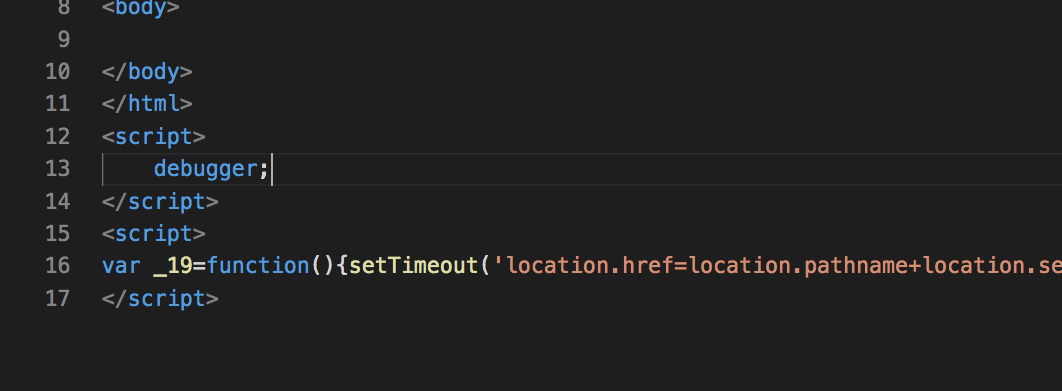
然后选择你最喜欢的一款代码编辑器,新建一个html页面。然后粘贴你之前复制的响应内容。
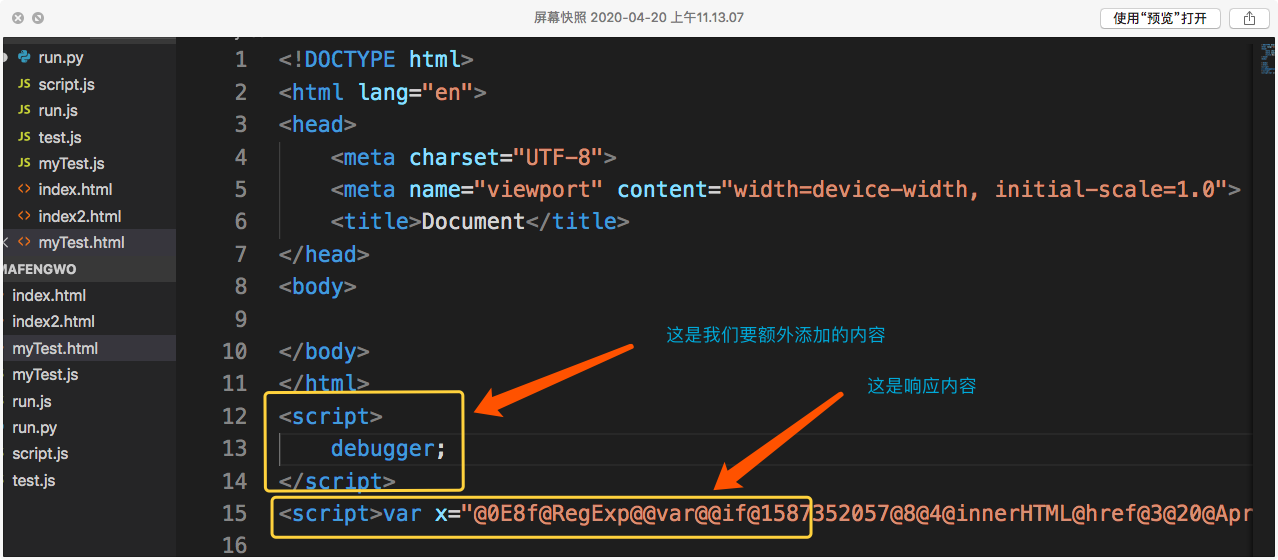
如上图,添加一些东西。debugger的作用是当我们打开开发者工具时,代码能在这里停住,以方便我们调试。
在浏览器中打开。按F12(mac为fn+F12)打开开发者工具
当我们一打开开发者工具,就会直接跳到 Source 选项卡。并在 "debugger"处停住
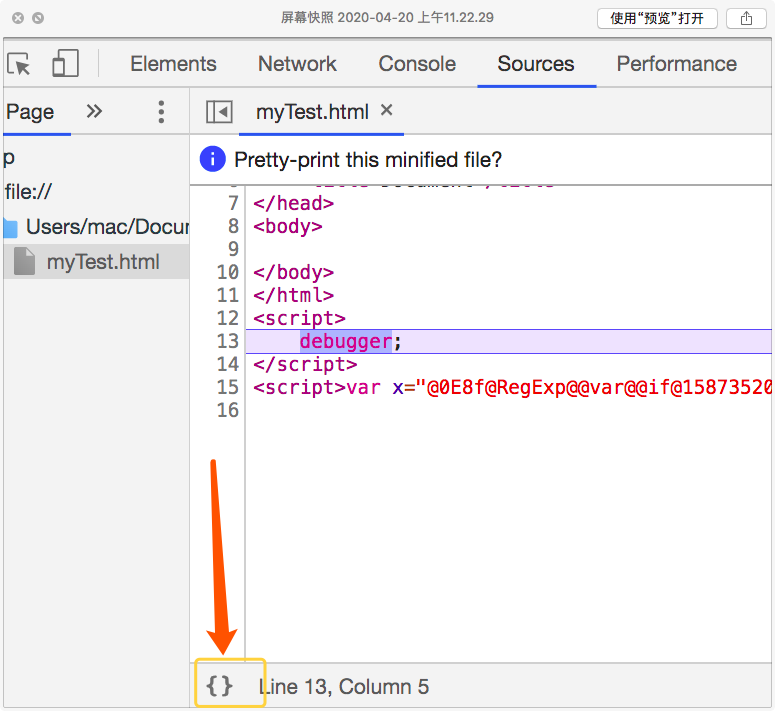
复制下的代码只有一行,非常难以调试。我们只需点击下上图的 "{}" 便可以格式化代码。
格式化后的代码长这个样子
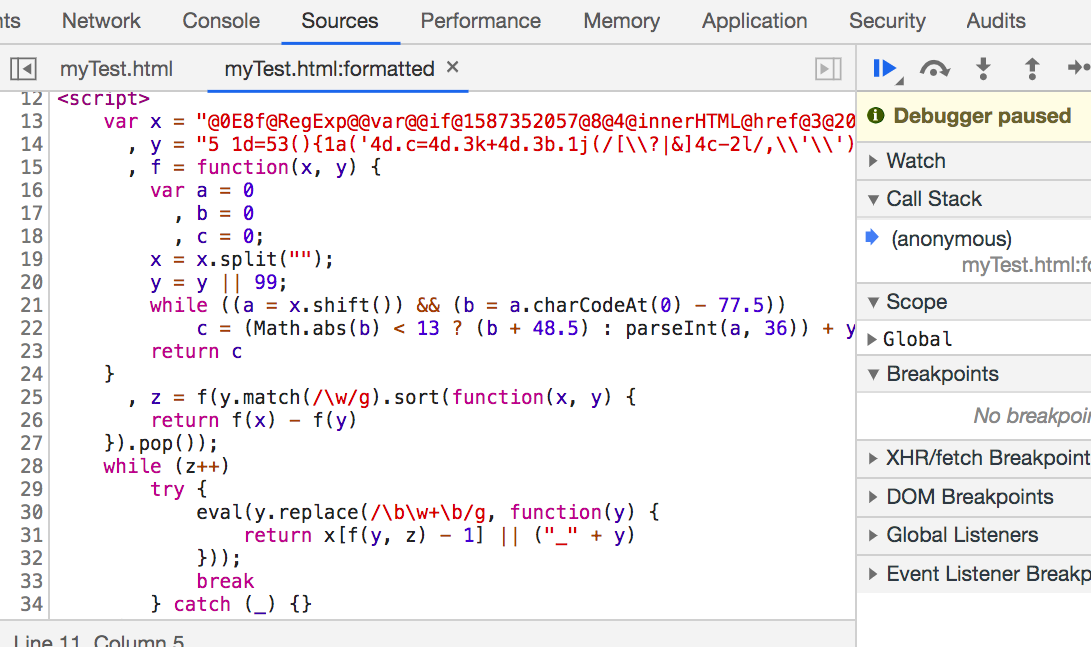
我一眼就看到了第30行的 eval函数。这个函数能执行js字符串。
eval("console.log('hello world')"); // 这样控制台就会输出 "hello world"
eval执行逻辑
因为代码不是很长,我们并没有选择下断点。我们选择复制js代码,然后扔到console选项卡中运行。
首先复制这一部分代码到console选项卡中
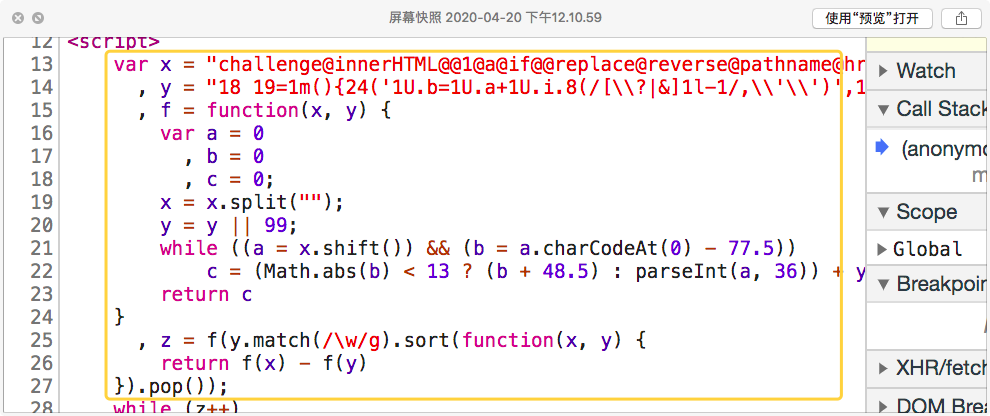
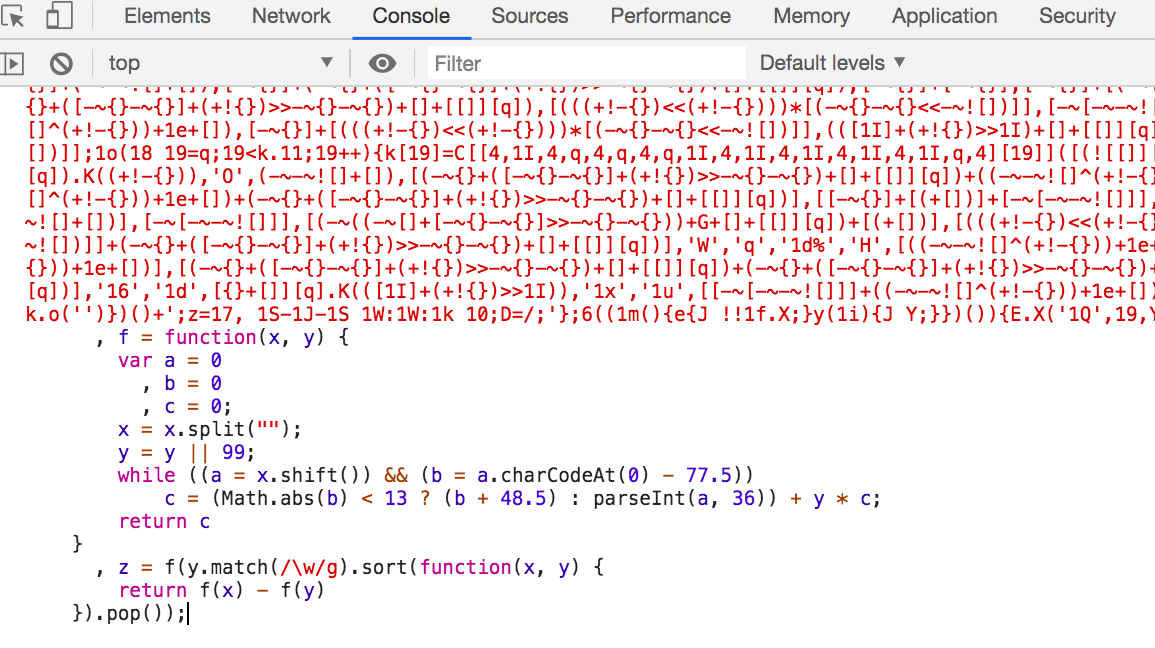
回车运行
第二段要执行的js代码
z++
第三段要执行的js代码
y.replace(/\b\w+\b/g, function(y) { return x[f(y, z) - 1] || ("_" + y) })
然后我们就可以看到eval函数要运行的字符串了

三次快速点击返回的字符串,然后复制一下。选择一个你喜欢的编辑器,再新建一个html文件,将复制的字符串放进去。
记得去除前后的双引号及<script>和</script>。 debugger还是要加的。具体的如下所示。
同样的,在浏览器中打开此html文件。并打开开发者工具,格式化下代码("{}" 符号)
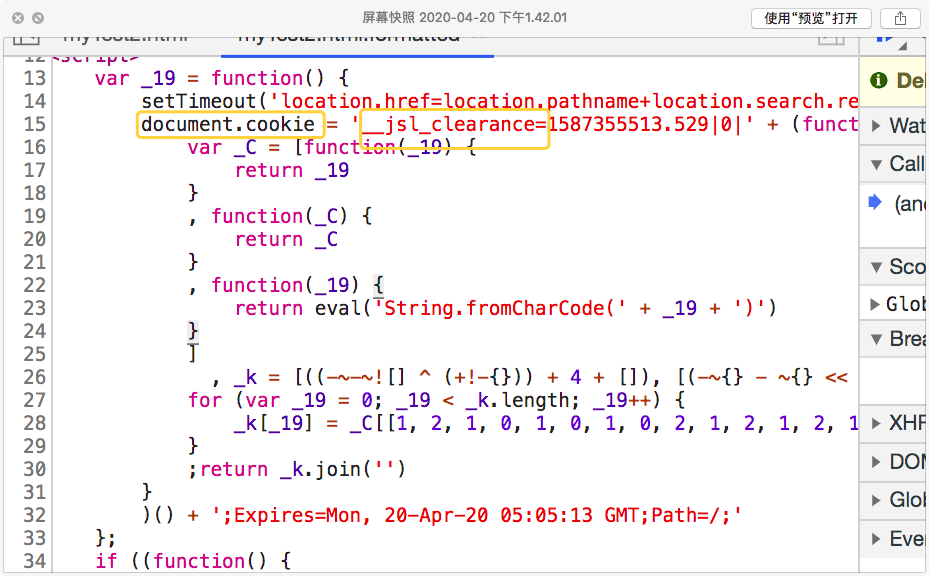
可以看到,cookie中的__jsl_clearance字段生成就在这部分的代码了。
其实我们需要的那部分代码只是这个

复制这部分代码到console中运行。

可以发现返回的结果就是我们要的__jsl_clearance字段
为了保险起见,可以复制__jsl_clearance字段和前面生成好的__jsluid_s字段做个测试。(可自行测试)
python怎么调用js代码?
答案是使用 execjs第三方模块,需要pip安装下。
execjs的简单使用
import execjs jsContext = execjs.compile("var sToken='hello js'; function foo(){return sToken}") # 将字符串编译一下 ret = jsContext.call("foo"); # 调用foo函数 print(ret); # 返回 'hello js'
解释下eval执行的代码
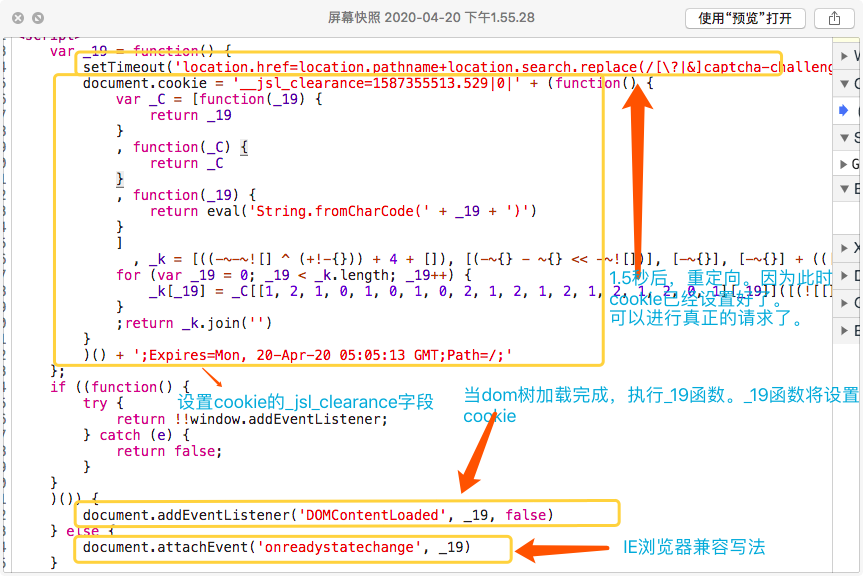
如何动态修改返回的js代码
好了,现在我们就要想办法动态修改返回的js代码。因为直接执行是不行的。因为execjs的环境并不是浏览器环境
首先 eval执行的代码(也就是上图所示的代码), 我们首先只需要设置cookie的那部分代码。
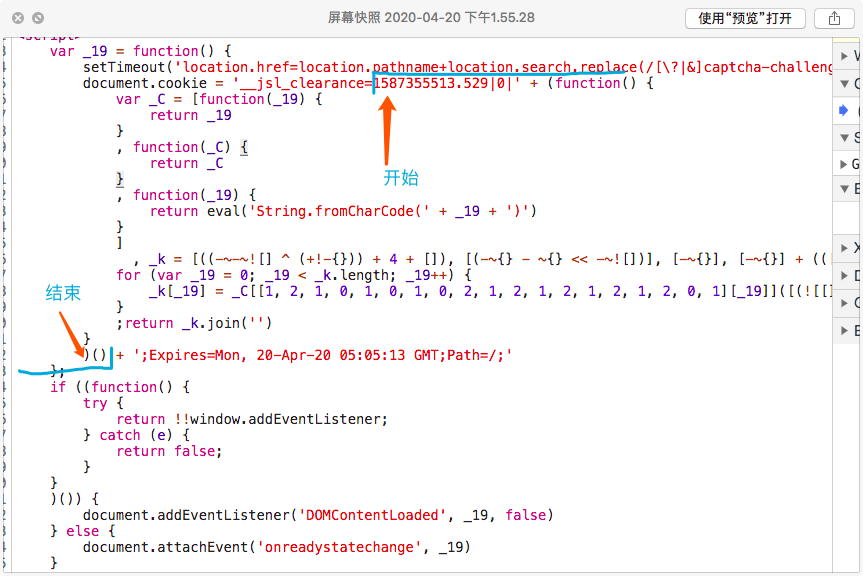
如何去掉不需要的js代码?(注意! eval执行的是一段字符串)
使用js中的正则即可
evalCode.replace(/^[\w\W]+__jsl_clearance=/, '') .replace(/\+';Expires=[\w\W]+$/, '')
这里的正则便可以帮我们去除多余的部分。
这个js正则其实需要动态的插入要执行的js代码(最开始的那个响应内容中的js代码,以<script>开头的那个)
什么意思呢?
这是eval要执行的字符串

我们要给他换成这个样子

这样eval要执行的字符串就会变成这个样子

这时候eval执行下这个字符串,就能得到最后的结果啦。(最好是先不eval这个字符串, 先返回这个要进行eval的字符串,然后再运行一次)。
注意!!!!(2020.4月27日网站逻辑增加)
有时候eval返回的字符串直接执行的话会有问题的。(显示document is not defined), 类似的代码如下

这里的做法比较聪明,因为只有浏览器才有document对象,并且它还调用了document对象的方法
如果不是浏览器环境,不做一定的处理的,就会运行报错。
稍微解释下,那一行代码的含义吧
_4k=document.createElement('div');
// 创建一个div标签。 <div></div>
_4k.innerHTML="<a href=\'/\'>_i</a>";
// \' 是转义。
// 其实就等于_4k.innerHTML="<a href='/'>_i</a>";
// 设置这个div标签的 子内容(会被自动解析为html)
// <div>
// <a href='/'>_i</a>
// </div>
_4k=_4k.firstChild.href;
// 获取div标签的第一个子元素的href属性
// _4k 的结果便是 当前的网址的根路径(即"https://www.mafengwo.cn/")
var_5b=_4k.match(/https?:\/\//[0];
// re正则表达式。_5b的结果是 "https://"
_4k=_4k.substr(_5b.length).toLowerCase();
// substr 用于切割字符串,接受两个参数,第一个参数切割的开始位置。第二个参数是要切多少
// toLowerCase()方法是将字符串中的字母转为小写
// _4k 的结果是 "www.mafengwo.cn/"
貌似这个代码其实是固定的,但变量名是不同的,我们需要定义一下document对象,然后给他一定的方法就可以
var document = { createElement: function(tag){ var innerHTML; return { firstChild: { href: "https://www.mafengwo.cn/" } } } };
上面定义的document便提供eval字符串中所需要的东西,接着我们将这段代码插入到execjs中便可以正常运行了。
具体的代码实现


import requests import re import execjs def changeJsRunTimeCodeAndGetClearance(content): # print(content) insertJsCode = """ .replace(/^[\w\W]+__jsl_clearance=/, '') .replace(/\+';Expires=[\w\W]+$/, '') """ evalJsCode = content.replace('("_"+y)})', '("_"+y)})' + insertJsCode) # 这里本来是要eval下这个js字符串的,但我们这里是返回了这个js字符串 evalJsCode = evalJsCode.replace("<script>", "").replace( "eval(y.replace(/", "return (y.replace(/" ) # print(evalJsCode) # # 这里先找到</script>的位置,是为了把</script>后面的字符串全部清除掉 index = evalJsCode.index("</script>") # # 记得要定义一下window对象。 documentCode = """ var document = { createElement: function(tag){ var innerHTML; return { firstChild: { href: "https://www.mafengwo.cn/" } } } }; """ evalJsCode = ( "var window = {};" + documentCode + "function exec(){" + evalJsCode[0:index] + "}" ) # print(evalJsCode) context = execjs.compile(evalJsCode) # print(context.call("exec")) finalContext = execjs.compile( # context.call("exec")是用来调用前面的exec函数的 "var window={};" + documentCode + "function final(){ return '" + context.call("exec") + "}" ) finalVal = finalContext.call("final") return finalVal def getContent( url, __jsluid_s="", __jsl_clearance="", ): url = "https://www.mafengwo.cn/i/18252205.html" headers = { "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/527.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36", "referer": "https://www.mafengwo.cn/i/18252205.html", } if __jsluid_s != "" and __jsl_clearance != "": cookie = "__jsluid_s=%s; __jsl_clearance=%s;" % (__jsluid_s, __jsl_clearance) headers.update({"cookie": cookie}) r = requests.get(url, headers=headers) print(r.headers) # print(r.text) print(r.status_code) if r.text.startswith("<script>"): # cookie错误 __jsluid_s = r.headers["Set-Cookie"].split(";")[0].split("=")[1] print("__jsluid_s", __jsluid_s) __jsl_clearance = changeJsRunTimeCodeAndGetClearance(r.text) print("__jsl_clearance", __jsl_clearance) # # 再请求一遍 getContent(url, __jsluid_s=__jsluid_s, __jsl_clearance=__jsl_clearance) if not r.text.startswith("<script>"): print(r.text) # content = r.text getContent("https://www.mafengwo.cn/i/18252206.html") # '__jsluid_s=9a91972ada0d6431c85c51308d9ca2d6 # changeJsRunTimeCode(content) # document.createElement('div'); # _4k.innerHTML="<a href=\'/\'>_i</a>"; # _4k=_4k.firstChild.href;
View Code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号