apistudy js逆向(ast)
前言
目标网站
https://www.aqistudy.cn/historydata/daydata.php?city=%E6%9D%AD%E5%B7%9E&month=2013-12
爬取内容
页面上的表格中的所有数据
爬取过程
先F12检查吧。没想到一打开控制台,页面就变成这样了。看样子做了反爬。
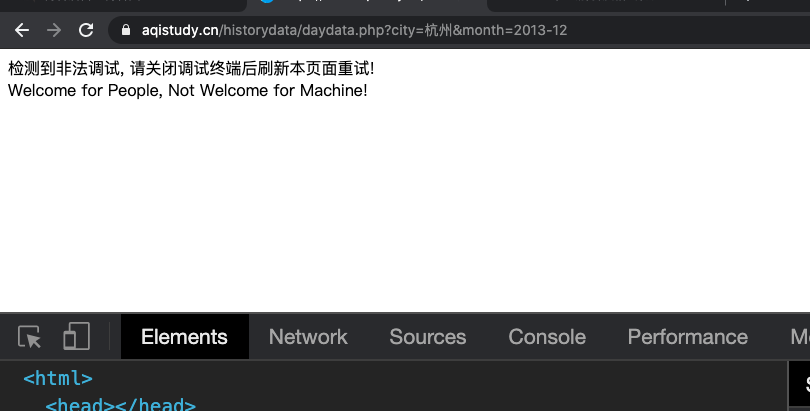
F12检测-解决方法
我所采取的方法是使用 油猴下一个断点。因为油猴的执行时机较早。因此那个时候debugger住,就可以看到这个页面的逻辑
下面便是油猴的代码,其实只有debugger这一行语句。
(function() { 'use strict'; debugger; // Your code here... })();
打开F12,刷新页面,就可以看到页面在断点处停下了
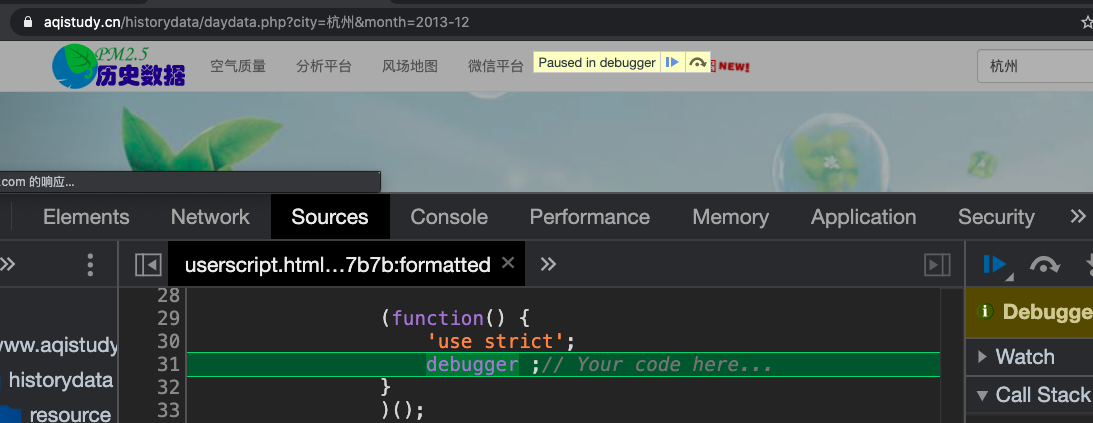
有可能打开页面就并不是上面的样子(2020.8月18日)
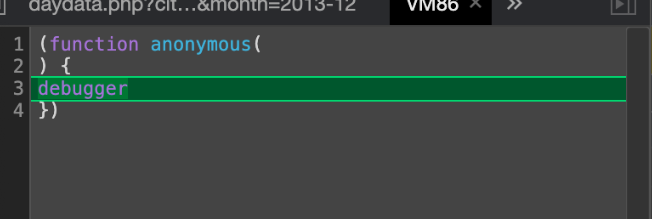
也是这个样子,并且我们的右键啥的都被禁用了。
找到禁用F12的代码处
调整tampermonkey的运行时机,将其调到document-start。这样油猴便是第一个运行的js文件。
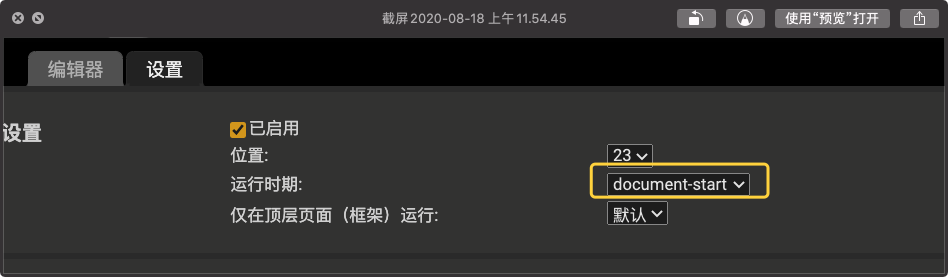
在油猴的脚本处停止后,我们直接在resource面板上找到加载的html文件。
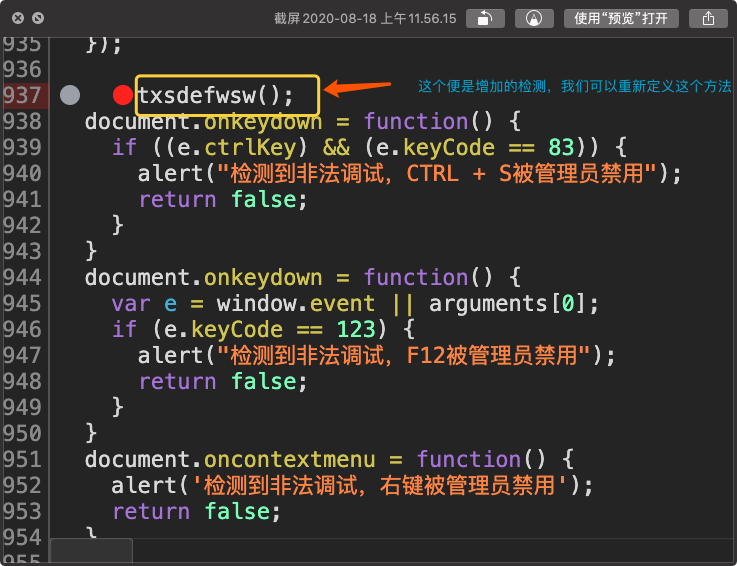
如何重新定义方法呢?
控制台上输入 function txsdefwsw(){} 便可以了。
这时候翻一下页面,发现数据已经被加载出来了。但可喜的是,页面没有出现那个提示了。
这时候去network面板找找所有的请求,会很惊喜的发现,貌似没有找到相关的请求啊。
答案是 并没有发送请求,而是使用了localhost本地存储。
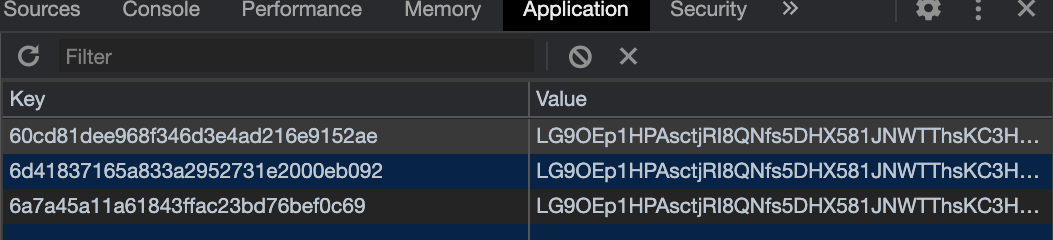
有人可能在想了,这是啥玩意啊。你怎么这么确实就是我们想要的数据呢?
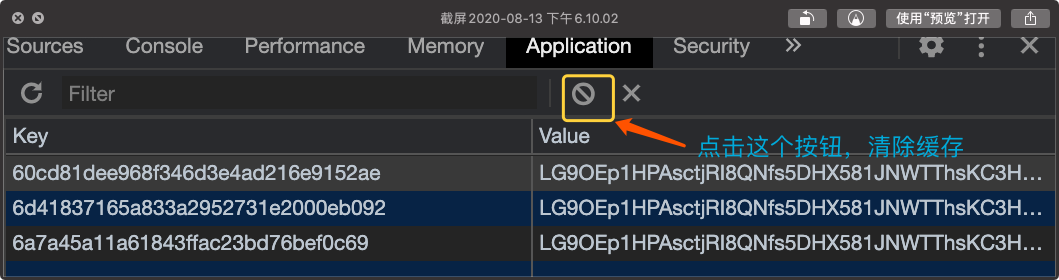
这点等一下我们可以在源码中见到。现在我们需要将localstorage中的缓存全部清掉,这样页面就会发起真正的请求了。
然后还需要下一个XHR断点,因为油猴下的断点其实有些晚了(油猴可以设置脚本的执行时机,可以设置到最早,默认的不是最早的)
然后刷新下页面。
这次的断点就不是那个油猴断点了。熟悉前端的朋友一眼就可以看出这个便是ajax请求。
切换调用栈,我们很快就会找到发送ajax请求的源头
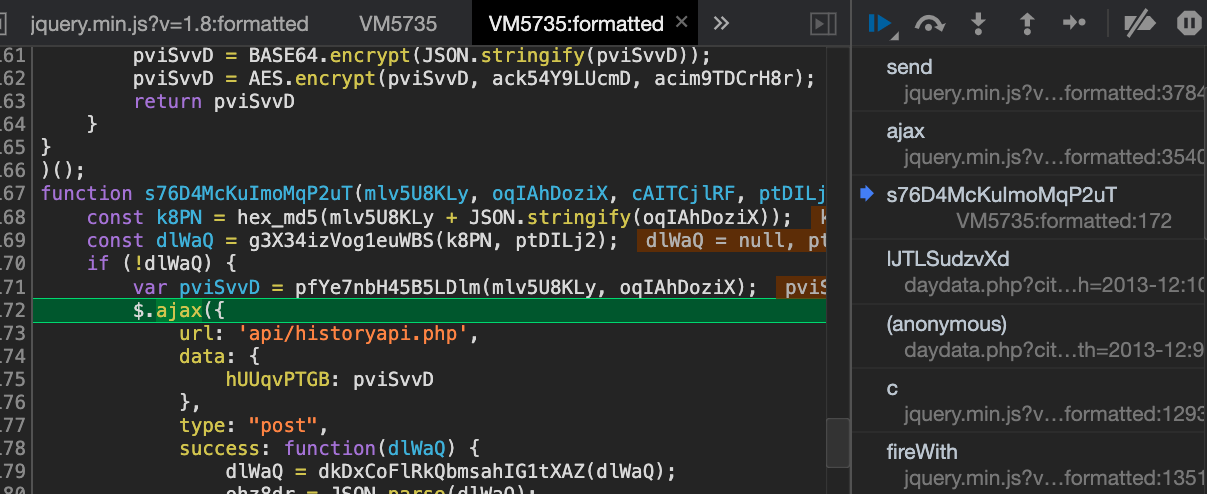
其中这个s76开头的函数的第二个参数便是要请求的参数
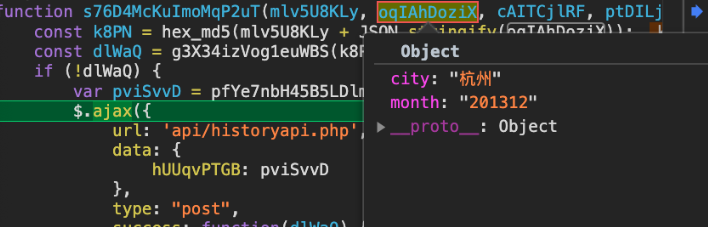
那下一步是不是直接在这个s76函数的第一行代码处打一个断点,然后观察请求就可以了?
并不是的哦。如果你仔细观察的话,就会发现这部分代码并没有啥具体的地址,取而代之的是VM5735之类的东西
这说明了啥?说明了这部分代码是通过eval执行的,动态执行的js代码。因此在此处下断点没用。
我们还得顺着调用栈向上找,找到一处不是在vm中执行的。
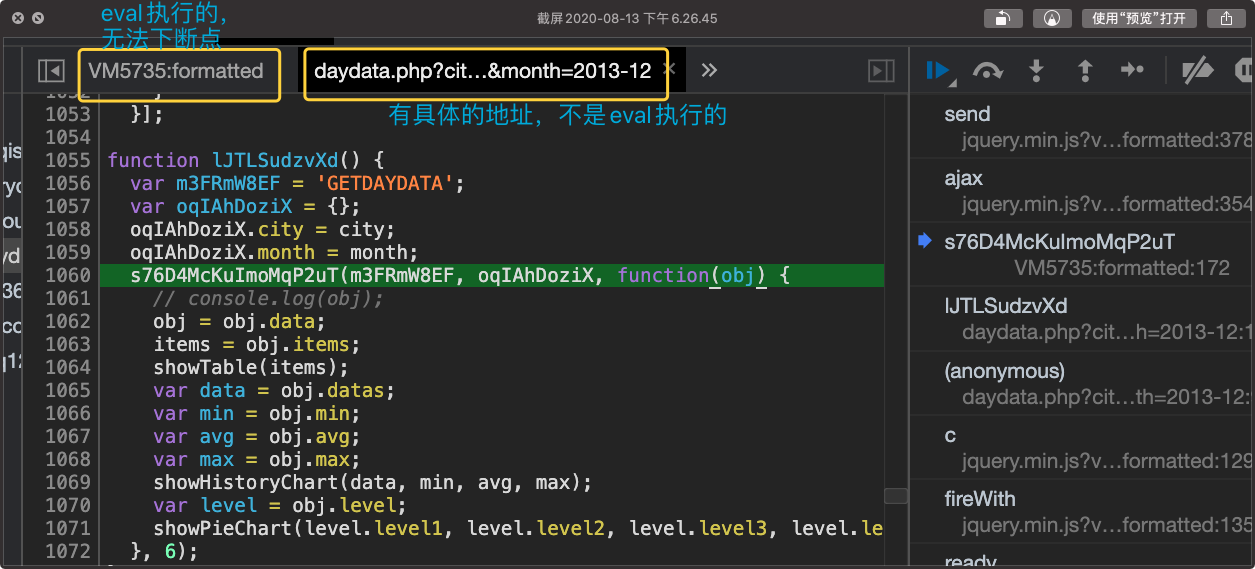
在1056行处下一个断点,再次刷新,然后断点就会在此处停住了。
这个sU开头的函数便是整个的加载逻辑了,第三个是异步回调函数,用于设置数据用的。

我们进入是sU开头函数了,解释下函数的作用
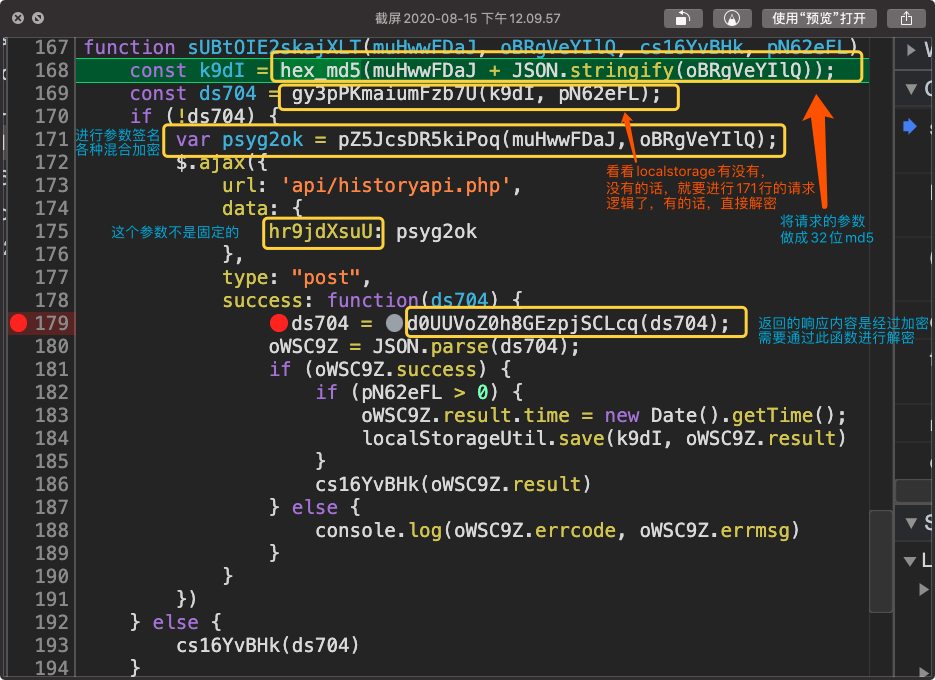
有些人看到这个就会觉得好简单了,我直接把171行的函数和179行的数据解密函数扣下来不就搞定了?
但事实上没那么简单,171行的函数其实是动态生成的(见后面的"关于eval的200行代码")。里面并不是固定死的算法。有些参数的值是变化的
下面两张图中画框的内容便是变化的东西。
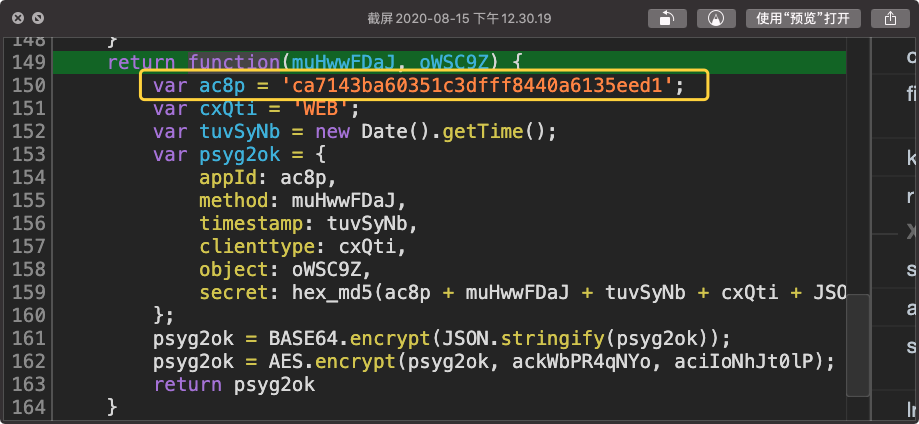
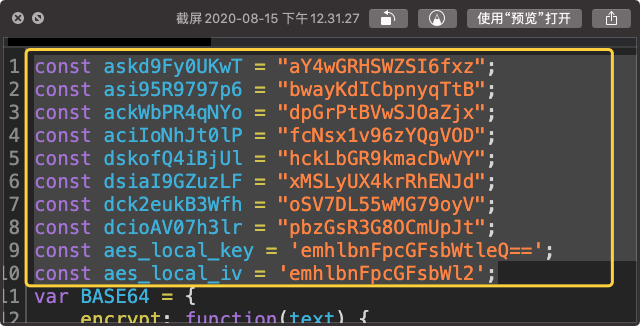
很不幸,不但值在变,变量名也在变。因此如果想要用正则来匹配的话,实际操作难度很大。
我的想法是这个代码肯定是可以运行的,我们大可不必考虑变量名变来变去的。我们只需要修改下sU函数里的东西就可以了。
经过测试,只需要保存下面的几处代码即可在node环境中运行了
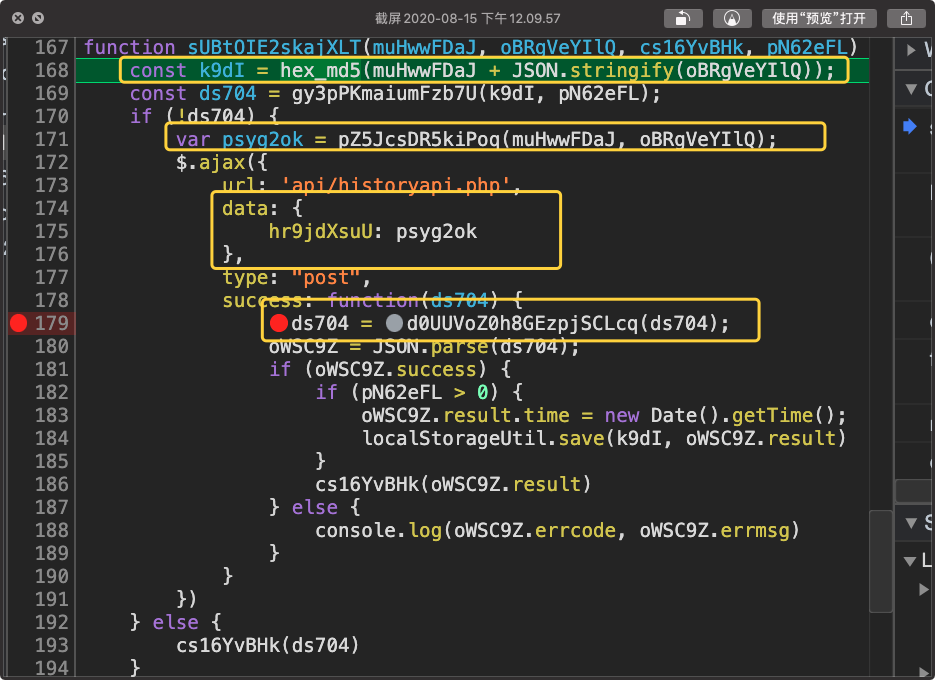
还有个小小的问题,这些函数名都不是固定的,如果想要调用,根本没有办法调用。其实可以做一层映射即可。
function sUBtOIE2skajXLT(muHwwFDaJ, oBRgVeYIlQ, cs16YvBHk, pN62eFL) { const k9dI = hex_md5(muHwwFDaJ + JSON.stringify(oBRgVeYIlQ)); var psyg2ok = pZ5JcsDR5kiPoq(muHwwFDaJ, oBRgVeYIlQ); return ["hr9jdXsuU", psyg2ok]; }
function getParam(obj){ // 以后要调用的话 getParam({city: "杭州", "month": "201312"}) 便可以得到需要post的data了。
return sUBtOIE2skajXLT("GETDAYDATA", obj); // 这里要对应上 上面具体的函数(有工具可以自动解析到)
}
function parseData(input){ // 也是一样的,如果想要解密下响应内容,调用此函数即可。
return d0UUVoZ0h8GEzpjSCLcq(input);
}
你可能会问了,这样写有啥用。下次函数名变了,难道还要手动去改函数名吗?
No,No,No。并不需要。
这里就要引入一个工具了,它叫babel。
干啥用了?
这个工具可以将我们的js代码先变成一个ast语法树,然后我们通过修改或者访问这个树的节点。最终生成的代码就会被我们这样修改掉了。
我拿这个工具举个简单的例子吧。
我们需要在所有的console.log中输出我们所调用的函数名字(经典例子)
function foo(){ console.log(111); } // 变成这个样子 function foo(){ console.log("function foo", 111); }


// 下面的四个依赖包需要npm安装下 const generator = require("@babel/generator"); const parser = require("@babel/parser"); const traverse = require("@babel/traverse"); const types = require("@babel/types"); function compile(code) { const ast = parser.parse(code); // 将代码解析成ast语法树 const visitor = { CallExpression(path) { // 下面的节点名称啥的可以通过 https://astexplorer.net/ 找到 const node = path.node; if ( node.callee.type === "MemberExpression" && node.callee.object.name === 'console' && node.callee.property.name === 'log' ) { // 找到函数的名字 const parentNode = path.findParent(p => types.isFunctionDeclaration(p)) const parentName = parentNode.node.id.name; console.log(parentName); // ast增加一个结构 node.arguments.unshift(types.stringLiteral(`function ${parentName}`)) } // 找到函数中的console.log语句 } } traverse.default(ast, visitor); return generator.default(ast, {}, code); } const code = ` function foo(){ console.log(111); } `; const output = compile(code); console.log(output.code);
那对于这个网站,我也写了个对应的ast来应对。
const generator = require("@babel/generator");
const parser = require("@babel/parser");
const traverse = require("@babel/traverse");
const types = require("@babel/types");
const fs = require("fs");
function compile(code) {
// 1.parse 将代码解析为抽象语法树(AST)
const ast = parser.parse(code);
const visitor = {
FunctionDeclaration(path) {
const node = path.node;
// console.log(node.params)
// 目标函数长这个样子
// function sBAAH3A7LFcJgXe(method, object, callback, period) { }
if (
node.params.length === 4
// && node.params[0].name === "method"
// && node.params[1].name === "object"
// && node.params[2].name === "callback"
// && node.params[3].name === "period"
) {
// 获取此函数名,暴露出接口
const funcName = node.id.name
console.log(funcName);
// 去除第二行的 const data = getDataFromLocalStorage(key, period);
const ifStatement = node.body.body[2];
const addParamExpression = ifStatement.consequent.body[0]
node.body.body.splice(0, 2, addParamExpression);
// 获取post请求中data的key
postDataKey = ifStatement.consequent.body[1].expression.arguments[0].properties[1].value.properties[0].key.name
console.log(postDataKey)
// 解密函数映射
const decFuncName = ifStatement.consequent.body[1].expression.arguments[0].properties[3].value.body.body[0].expression.right.callee.name;
console.log(decFuncName)
// 删除if语句
node.body.body.pop()
// 增加 return [param, postDataKey]
const paramName = node.body.body[0].declarations[0].id.name;
const returnStatement = types.returnStatement(types.ArrayExpression([types.identifier(paramName), types.stringLiteral(postDataKey)]))
node.body.body.push(returnStatement)
// 增加映射
const globalBody = path.findParent(p => {
return true;
})
const funcMappingForGetParam = types.functionDeclaration(
types.identifier("getParam"), [
types.identifier("obj")
], types.blockStatement([
types.returnStatement(
types.callExpression(
types.identifier(funcName),
[
types.stringLiteral("GETDAYDATA"),
types.identifier("obj")
]
)
)
])
)
globalBody.container.program.body.push(funcMappingForGetParam)
// 关于数据解密函数
// function parseData(input) {
// return dA3Gc6OUqeCBgWSh53T(input);
// }
const funcMappingForParseData = types.functionDeclaration(
types.identifier("parseData"), [
types.identifier("input")
], types.blockStatement([
types.returnStatement(
types.callExpression(
types.identifier(decFuncName),
[
types.identifier("input")
]
)
)
])
)
globalBody.container.program.body.push(funcMappingForParseData)
}
}
}
// 2,traverse 转换代码
traverse.default(ast, visitor);
// 3. generator 将 AST 转回成代码
return generator.default(ast, {}, code);
}
// const code = fs.readFileSync("out.js", "utf-8");
// const newCode = compile(code)
// fs.writeFileSync("out2.js", newCode.code, "utf-8")
ast转换
这样便可以实现上面所说的效果了。删除不需要的结构,添加我们所需的结构。
这个需要进行ast转化的js代码其实只有200来行,它依赖多个加密库。因为行数过多,就不在此处展示了。
关于eval的那200行代码
代码具体实现
百度网盘
链接: https://pan.baidu.com/s/1DfMIDDc-SLjd0tVIeyyKOQ 密码: e2ou
具体效果
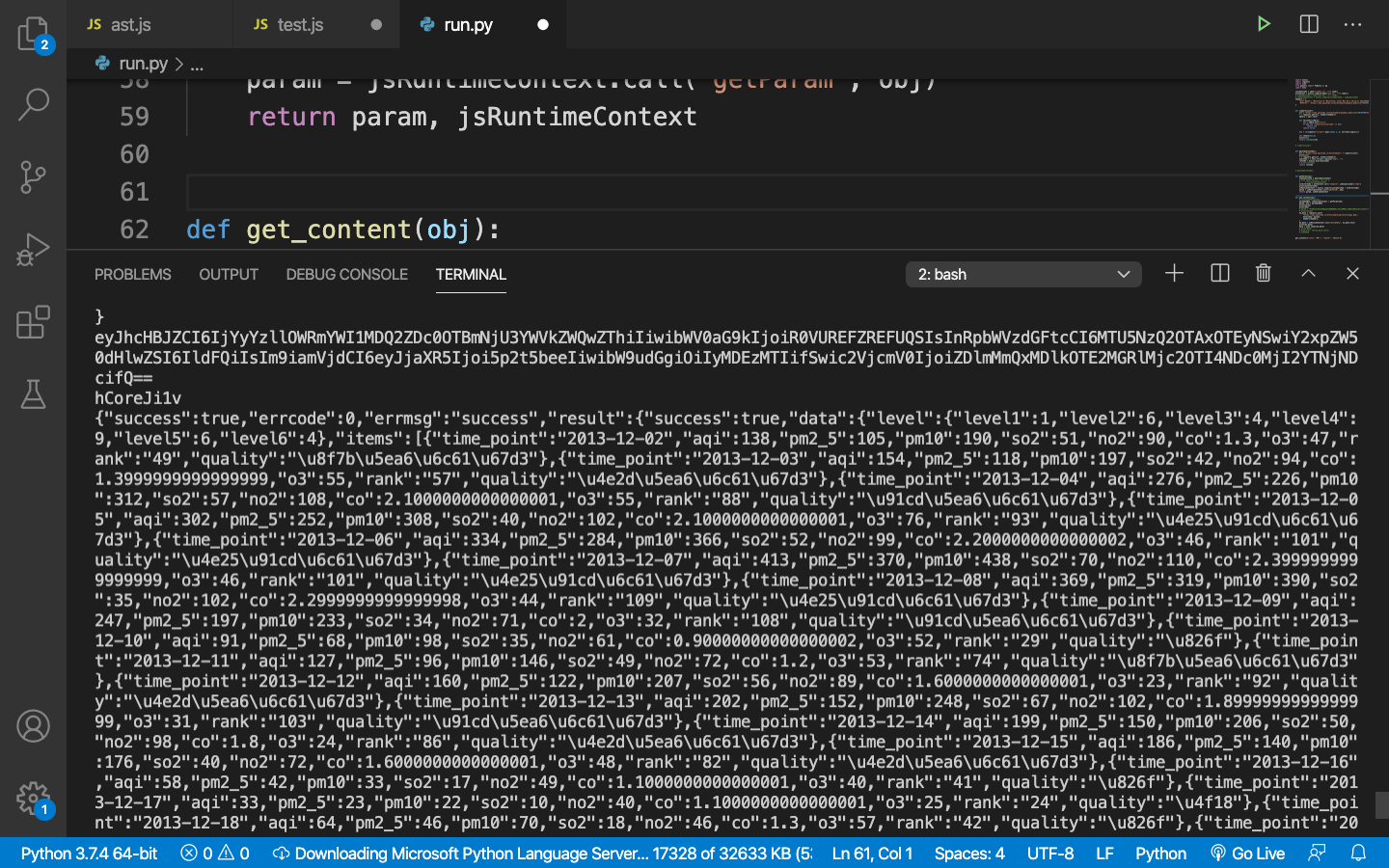
关于execjs执行速度
可能有人觉得获取数据好慢,其实有部分时间花在了babel编译过程中与js代码的运行上(600毫秒到1.2秒)
只是因为execjs是通过纯字符串与解释器通信的,损耗很大。
并且每次都要新生成一个代码,继续编译执行。(算法部分的代码其实是不变的)
如果真的想提升速度的话,不妨将所有的代码都放到node环境里(有一定的风险,因为node可以直接删除文件啥的)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号