OO——求导作业总结
OO——求导作业总结
程序结构的分析
第一次作业
1.设计思路
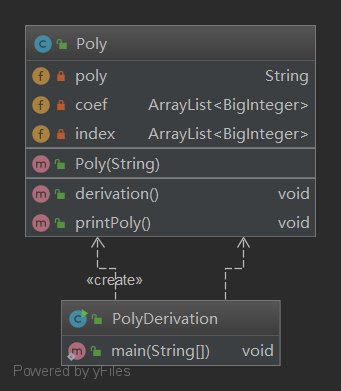
在第一次作业中,我设计了两个类:PolyDerivation(主类)、Poly。main(String[])函数存在于PolyDerivation类中,作为程序的入口。PolyDerivation是一个主要控制类,负责多项式合法性的判断、调用求导函数、调用打印函数,职责上类似一个控制单元。Poly类是多项式类,负责多项式的存储、求导函数的实现、打印多项式函数的实现。整体的架构图如下:
2.度量分析
首先,我们来看一下每个类的属性数,如下图:
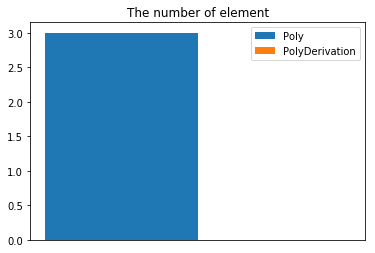
PolyDerivation类由于是主类,其中只有一个main(String[])入口,所以类中没有属性。Poly类中的三个属性分别是poly、coef、index。其中poly是一个String类型的私有变量,用来保存最后输出的求导完毕的表达式。coef和index是两个ArrayList类型的变量,分别用来保存多项式每一项的系数和指数。由于第一次作业的多项式项只有可能是幂函数,所以采取此种方式。
接着,我们来看一下每一个类的方法统计,如下图:
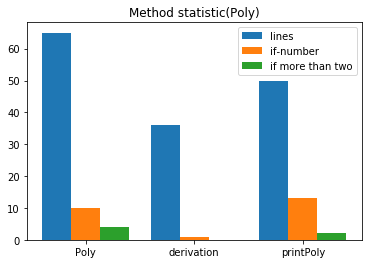
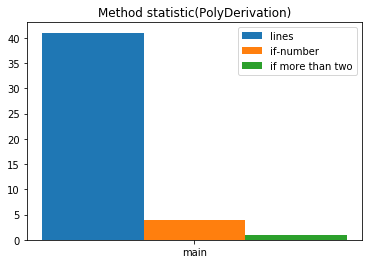
对于PolyDerivation类,我们可以从图中看到行数超过了40。作为一个入口类,依据面向对象的模块化思想,不应该出现这么多行。主要原因是我将多项式输入合法性的判断放在了main(String[])中,并且其中的if分支较多,增加了出错的可能性。我认为对于第一次的作业,我应该将多项式的读取单独建立一个类,这样能大大减少作为入口类的PolyDerivation的规模。
对于Poly类,每个方法的规模在合理的范围内。但是,Poly构造方法和printPoly打印方法内的if分支过多,并且其中有超过4个嵌套if分支,这大大提高了程序的bug出现几率,并且增大了测试的难度。
对于每个类的行数的统计如下图:
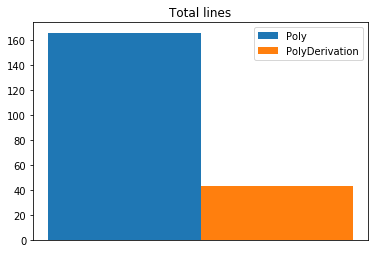
整体来看,在第一次的作业中,由于面向对象的学习不够深入,还不知道继承和多态的思想,程序总体上还是偏向面向过程,只不过用类来代替了原来C语言中的函数而已。但这间接导致了本次作业中程序的内聚性较好。虽然最终程序的正确性没有什么问题,但是过多的if分支导致了在编写过程中调试的复杂程度程指数性提高,浪费了大量的时间。并且我没有建立将读入多项式并判断合法性的类,这不仅增大了main函数的负担,也降低了程序的鲁棒性。一旦输入要求发生更改,就要对程序进行大幅度的调整,甚至重构。
第二次作业
1.设计思路
在第二次作业中,我设计了7个类。Main类是程序的主类,main(String[])位于其中,这个类起到一个控制的作用,通过调用其他类的方法来进行正确的多项式求导的要求。PolyGet类用来读取多项式并且判断多项式的合法性。Poly类用来对多项式字符串进行解析,将每一项的系数、指数、变量保存下来。Term类是项的类,PolyUnit是因子的类。Derivation类用来对多项式进行求导。PolyOut类将求导之后的多项式按照正确的格式输出。整体的架构图如下:
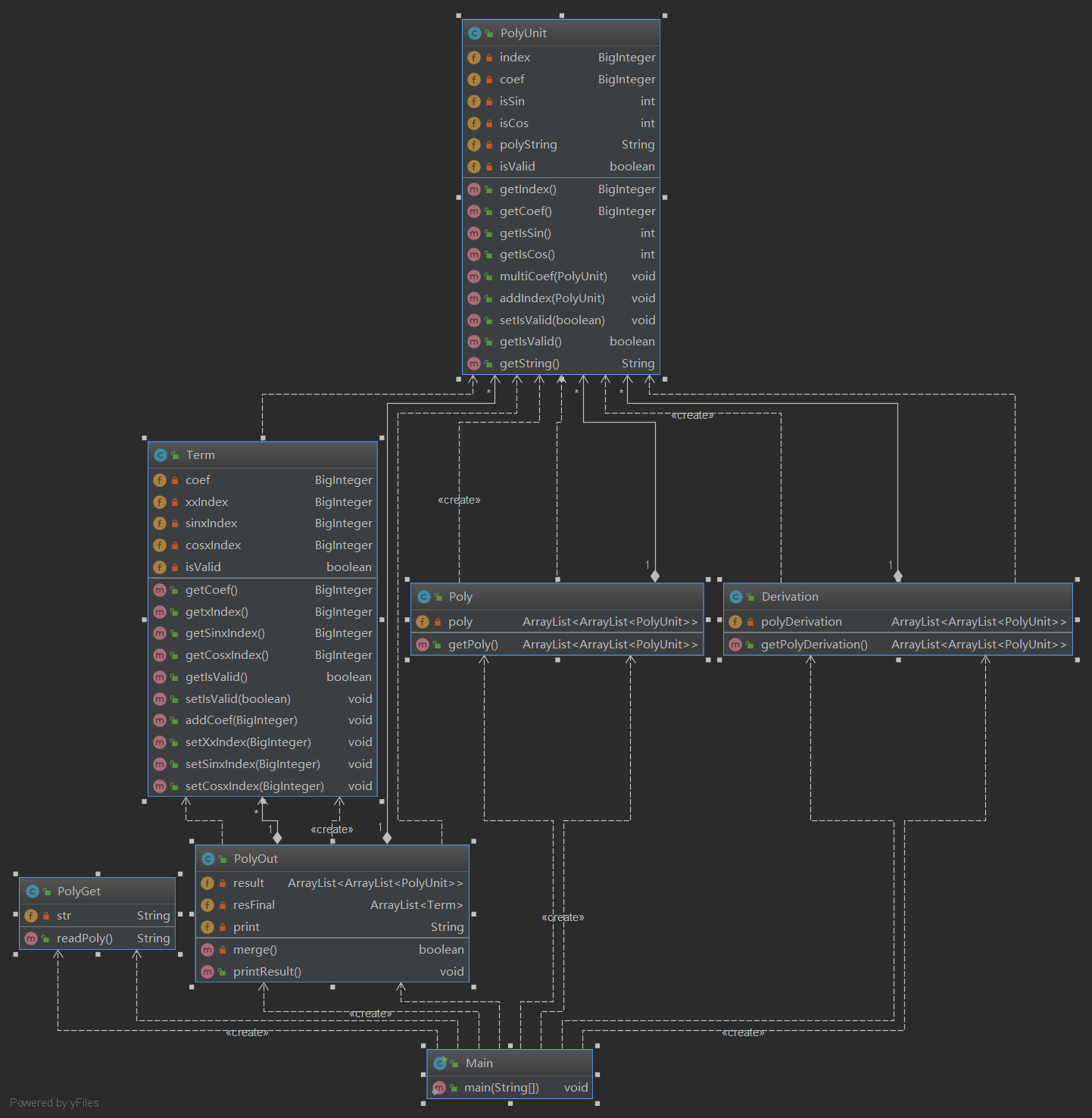
2.度量分析
首先,我们来看一下每一个类的属性数:
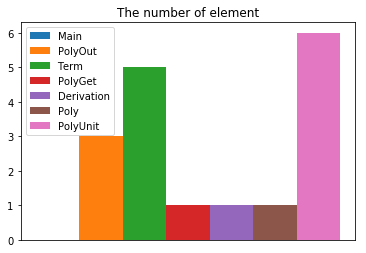
我们可以看到,其中PolyOut和Term两个类的属性明显多于其他类,究其原因,是因为我将三种不同的因子x、sin(x)、cos(x)都用一个类来进行处理,因此在类中会有判断变量是哪一种情况的属性,比如isSin和isCos。这大大提高了程序的耦合度,因为正确的方式,是应该将x、sin(x)、cos(x)这三种情况分开进行处理,用一个Power类和一个Triangle类来保存不同的因子。
接着,我们来看一下不同类中方法统计,如下图:

其中,有个别的类中有大量的getter和setter方法,这些方法我没有在图上绘制。但是本次作业我没有使用继承和接口,在这种情况下,大量的访问私有变量说明了不同的类之间有很强的关联性,不符合低耦合的模式。从图中我们可以看到PolyOut和Derivation两个类的构造方法的行数过长,应该采用更加符合模块化的方式,用多个模块来消除冗长的代码。
另外,图中有将近一半的方法中的if分支数达到将近20,并且其中有大量的嵌套情况出现。相比于第一次作业,这不仅没有得到一个很好的解决,反而产生了更大的问题。这种指数增长的测试需求,无疑在很大程度上增加了测试的负担。
总结第二次作业,通过对面向对象思想的学习,我对类的使用有了进一步的认识。通过将不同功能的处理交给不同的类,以增加类的方式来减少每一个类的规模。这样的分工,可以使得每一个类的功能明确,符合高内聚低耦合的原则。但是,从前面的分析中可以知道,此次作业并不是所有的类的设计都合理,部分类的分工不是那么的明确,倒更像是面向过程调用函数的思想。此外,本次作业中没有体现出继承和接口的思想,还不是一个很好的面向对象的程序。
第三次作业
1.设计思路
在第三次作业中,我采用了继承的思想。常数类Constant、幂函数类Power、三角函数类Triangle都继承父类Function。加法规则Add、乘法规则Multi、嵌套规则Nest都继承父类Rule。在本次设计中,本来是想弄一个求导接口derivation,但是在实际代码的编写过程中,出现调用函数不存在的情况,后来发现是因为对接口的意义理解不清楚,比如Function类型的ArrayList,对里面的元素无法调用接口函数,而应该是接口类型的ArrayList。所以在最终的设计中我将dev求导方法放在了两个父类中。其余的部分分别是一个InputHandler类来处理多项式的输入,Analysis类来对多项式进行解析。整体的架构图如下:
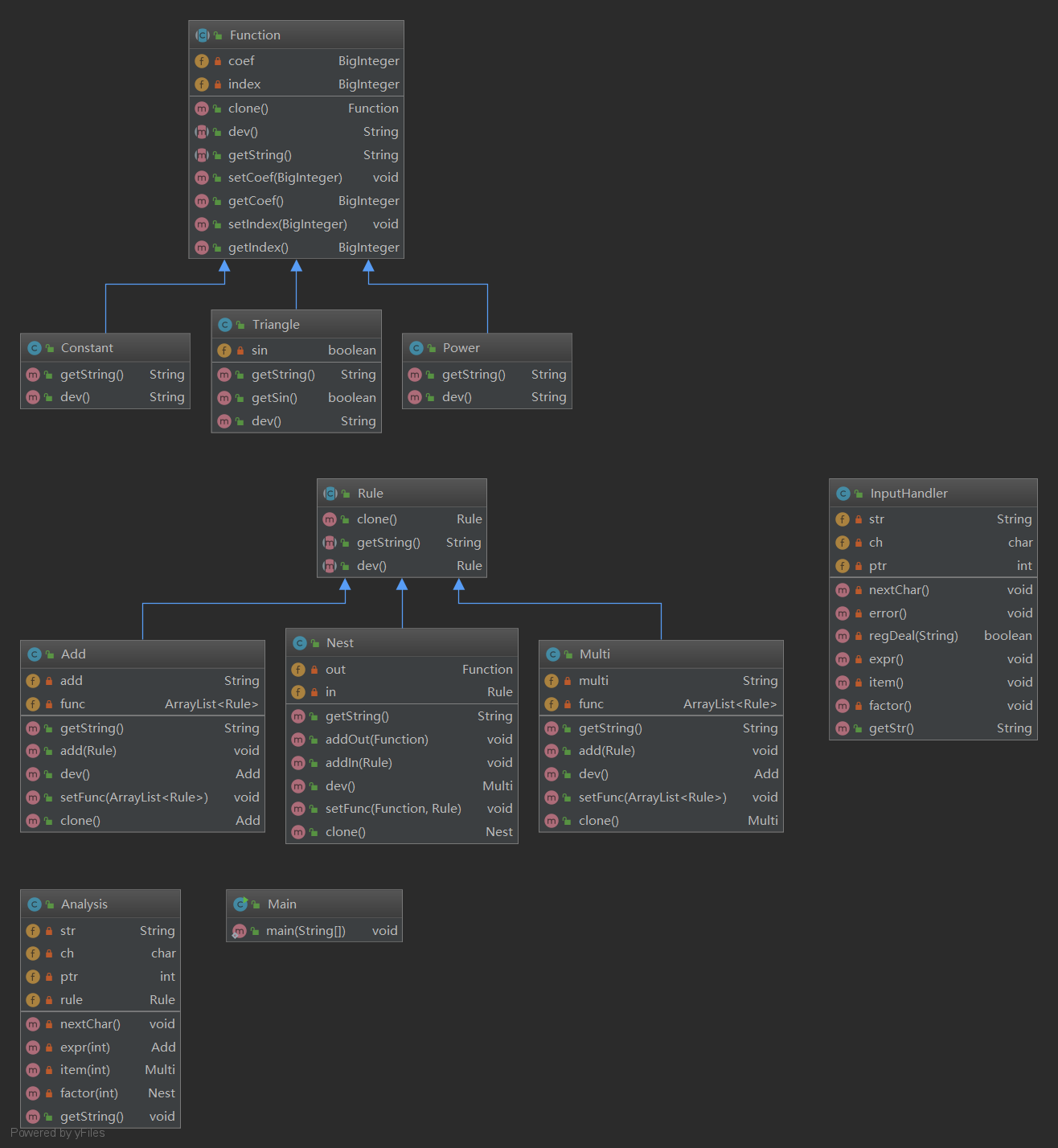
2.度量分析
首先,我们来看一下每一个类的属性数:
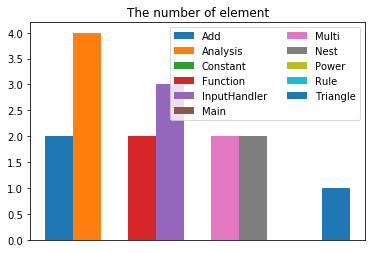
明显的,相比前两次作业,每一个类的属性数都处于一个比较低的水平,最高的也只有4个属性。这是因为分工越来越细的缘故,每个类的分工越来越明确,因此类内的属性就会相应的减少。
接着,我们来看一下方法统计:
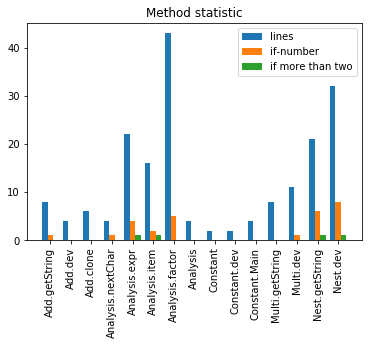
同样的,相对于前两次作业,每个方法的行数处于一个比较低的水平,并且每一个类的行数也最大100行左右。这说明了在每一个类中,将原来冗长的代码通过私有方法的方式来进行模块化,提高了程序的内聚性。并且,这次的程序中if分支的数量大大的减小,降低了调试的负担。
在第三次作业中,我采用了继承的思想。将Function和Rule分别设计了两个继承树,虽然每一个树只有一层,但相比前两此作业的程序,类之间的耦合性大大降低,每个继承树的功能交集大大降低。这样在debug的过程中,当定位到bug的所在类,就可以放心在该类或者该类的继承树中寻找bug,降低了debug的难度。
对多项式合法性判断的讨论
在这三次作业中,有一个共同需要解决的问题,就是多项式WRONG FORMAT!的判断。
在第一次作业中,我采用了正则表达式的方式。一开始,我采了对整个表达式进行匹配的模式,但是,在测试中发现这样的方法会陷入爆栈的危险,所以后来我采用了逐项匹配的方式,代码如下:
String pattern1 = "[+-]?\\s*((([+-]?\\d+\\s*\\*\\s*x\\s*"
+ "(\\^\\s*[+-]?\\d+)?))|"
+ "([+-]?\\s*x\\s*(\\^\\s*[+-]?\\d+)?)|"
+ "([+-]?\\d+))";
String pattern2 = "^\\s*[+-]\\s*(([+-]?\\d+\\s*\\*\\s*x\\s*"
+ "(\\^\\s*[+-]?\\d+)?)|"
+ "([+-]?\\s*x\\s*(\\^\\s*[+-]?\\d+)?)|"
+ "([+-]?\\d+))";
现在再来看第一次作业的正则,实在是惨不忍睹。其中pattern1是为了匹配第一项,pattern2是为了匹配后面的项。(别问我当时为什么这样写,估计是脑子坏了...)
在第二次作业中,我依然采用了正则表达式逐项匹配的方式,但是我这次采用了类似模块化的思想,模式如下:
String num = "([+-]?\\d+)";
String var = "(x|(sin\\s*\\(\\s*x\\s*\\))|(cos\\s*\\(\\s*x\\s*\\)))";
String factor = "(" + var + "(\\s*\\^\\s*" + num + ")?)";
String term = "(([+-]\\s*" + factor
+ ")|(" + factor + "|([+-]?\\s*" + num + ")))"
+ "(\\s*\\*\\s*" + "(" + factor + "|" + num + "))*+";
这次的模式不仅比第一次的好看许多,更关键的是易懂,最起码我现在再看这个模式,我知道要匹配的正确形式的多项式是什么样子。但这样的多项式就是万能的吗?答案显然是否定的,第三次作业就会教你做人。
没错,第三次作业中允许了多项式嵌套,呦吼,完蛋!不会多项式递归的我瞬间就傻眼了,于是,我走上了递归下降的道路。没错,重构是必然的,不重构是不存在的,这三次作业让我深刻的理解了深谋远虑的重要性......
首先,我先自己在纸上做了一个语法分析,大致如下:
Num = [+-]?\\d+
Factor = Num | x(\\^Num)? | sin(Factor)(\\^Num)? | cos(Factor)(\\^Num) | (Expr)
Item = [+-]?Factor(*Factor)
Expr = [+-]?Item([+-]Item)
然后根据上述分析,完成递归下降的代码:
private void nextChar() {
if (ptr == str.length()) {
ch = '\0';
} else {
ch = str.toCharArray()[ptr++];
}
}
private void error() {
System.out.println("WRONG FORMAT!");
System.exit(0);
}
private boolean regDeal(String rule) {
String s = rule;
Pattern p = Pattern.compile(s);
Matcher m = p.matcher(str.substring(ptr));
boolean judge = m.find();
if (!judge) {
return false;
} else {
ptr += m.end();
return true;
}
}
private void expr() {
this.regDeal("^[+-]?\\s*");
this.item();
while (this.regDeal("^\\s*[-+]\\s*")) {
this.item();
}
}
private void item() {
this.regDeal("^[+-]?\\s*");
this.factor();
while (this.regDeal("^\\s*\\*\\s*")) {
this.factor();
}
}
private void factor() {
if (regDeal("^[-+]?\\d+")) {
return;
} else if (regDeal("^x(\\s*\\^\\s*[-+]?\\d+)?")) {
return;
} else if (regDeal("^sin\\s*\\(") || regDeal("^cos\\s*\\(")) {
this.regDeal("^\\s*");
this.factor();
this.regDeal("^\\s*");
this.nextChar();
if (ch != ')') {
this.error();
}
regDeal("^(\\s*\\^\\s*[-+]?\\d+)?");
return;
} else if (regDeal("^\\(\\s*")) {
this.expr();
this.regDeal("^\\s*");
this.nextChar();
if (ch != ')') {
this.error();
}
return;
} else {
this.error();
}
}
虽然,我因为自己的规划设计的失败,重构了三次,但是,每一次的重构都学习到了新的方法。总结一句话,一时重构一时爽,一直重构一直爽。
程序bug的分析
未通过的互测bug
这三次作业中,我在强测阶段均没有bug,在互测阶段,只有第一次作业的时候有一个bug,然而被无情的刀了10多次......
第一次作业中的bug是'\f'和'\v'字符。题目中的要求是,输入的空白字符只能是空格和'\t',所以按照题意,'\f'和'\v'是不合法的字符,但我的程序中并没有对此进行判断。并且,我对trim()函数的使用产生了误解,我以为其只能去除首位的空格,但经过源代码的阅读,我发现它去掉的是首尾的所有ASCII吗小于空格的空白字符,所以说'\f'也会被去掉。这个问题发生在我第一次作业的PolyDerivation类里面。
bug的位置与程序结构的关系
对于每次发现的bug,我寻找的方式都是通过逐步调试,来定位bug发生的具体的代码。在经过无数次的调试之后,我发现虽然第三次作业的程序最复杂,但是调试起来却是最简单的。我觉得主要是高内聚低耦合的缘故。在前两次的作业中,我的程序的类与类之间有很多的交集,这就导致了一个bug的发生可能牵扯到好几个类的改动,但是第三次作业经过优化,我的不同类之间的交集少了很多,这也可以从前面的架构图中发现。这样一来,在第三次作业中如果时求导的bug,我就只需要去定位每个类的dev函数,而不用从头进行单步调试。
继承和接口的使用
由于以前没有面向对象编程的基础,我在第三次作业的时候才使用了继承和多态,虽然这对我的程序的整体架构起到了很大的优化作用,但是我也发现了很多问题。其中最大的问题就是接口使用的失败。起初,我认为接口只是一个抽象类,用来为不同的类提供相同的函数抽象。但是,我在实际的使用中,却忽视了这一点。比如我在Add类中的私有变量func,它是Rule类型的ArrayList,我把Rule的三个子类都使用了dev接口。但是,在实际使用的过程中,我发现编译器会报错,说在类中找不到这个函数。后来经过向大佬们的询问,我发现解决方式是将其定义成接口类型的ArrayList。我这才意识到接口实际上是忽略了继承关系的存在,它存在的意义就是使需要这个接口内部方法的类来继承并使用。
互测
在这三次的互测过程中,我主要采用了手动构造测试样例和对拍器自动评测的方式。
手动构造样例
在第一次和第二次作业的互测阶段,我采用了收到构造测试样例的方式。因为首先第一次和第二次程序的多项式求导结果不是特别的复杂,最主要的是我那时候根本不会对拍器......但是,手动构造样例有手动构造样例的好处,那就是先看病,再治病。
首先,我在自己课下编写程序的过程中,会对自己的程序进行测试,我采用的方式就是一种覆盖式检查小病,随机检查大病。对于每一项,我会将所有的可能全部列出来,对单项的多项式的输入进行覆盖式的检查,然后再对复杂的多项式进行随机抽样。这样一来,在互测阶段,我就会首先将这一堆样例用在每一个人的程序上。
随后,我会大致阅读每个人的多项式判别和求导两部分的代码。来看会不会有什么可能的疏漏。比如在正则表达式的使用上,我发现了一个同学的代码在第一项的时候没有考虑到前面可能出现的负号,所以就构造了一个小样例,就成功了。
对拍器评测
在第三次作业的时候,由于多项式嵌套的复杂性,以及众多同学的不优化(包括我)行为,导致了输出根本无法用肉眼来判断是否正确,手动构造样例也顶多能弄一个WF,然后互测阶段又不让用WF的样例,这谁顶得住啊......所以我果断选择了对拍器评测的方式。我将每个人的输出使用python里面的sympy包进行化简,然后进行化简后结果比对,如果有不一样的就记录下来。
采用对拍器的方式我就没有去阅读每个人的代码,而是直接治病,不管有没有。
两种评测方式的优缺点
我认为手动构造样例的优点就是能够对症下药,通过对其程序的代码进行分析,可以精心构造样例,达到很高的准确率。但缺点就是使用大量的时间,尤其是自己所在房间内的各位的bug很少的情况下。而对拍器的优点就是不需要人去执行,就运行之后放在那里让他自己跑。但缺点就是如果数据生成器编写的不得当,就会导致不能产生有效的测试用例,哪怕跑一天都不会发现bug。
Applying Creational Pattern
通过这三次作业,在我的能力范围内,我能想到的最好的构思如下:
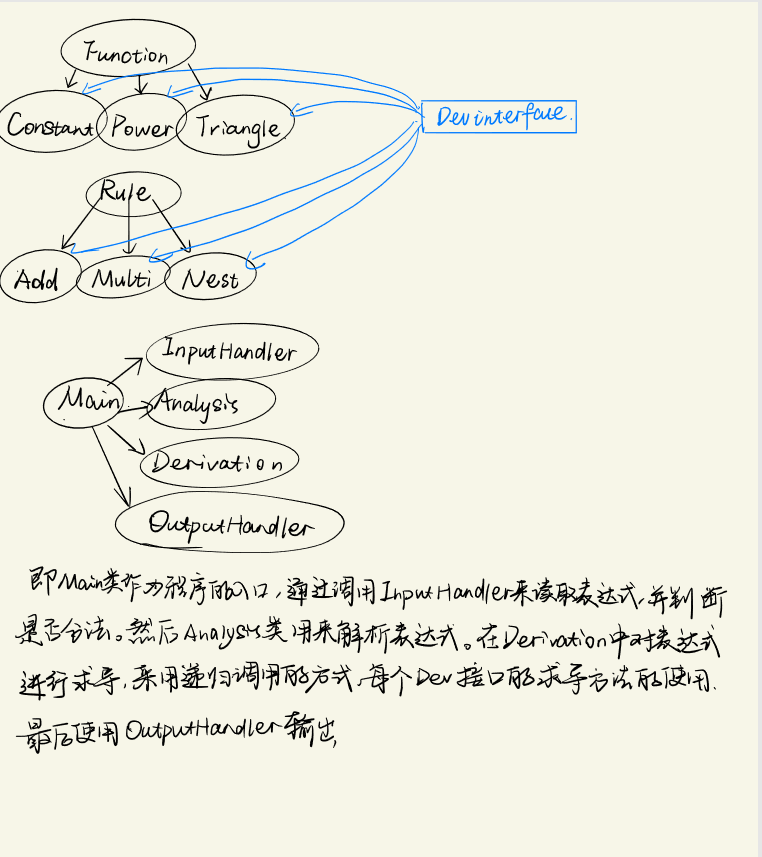
总结
虽然这三次作业让我以后不再怎么想去求导,但是真的收获很大。
第一,我了解了代码编写的规范,每一次的CheckStyle都是对自己的一次提高,从一开始的一片错误到现在盲写都不怎么会出错,提高了很多,看着自己的代码,也不会产生厌恶感。最重要的是,设计规范并不只是为了你的程序好看,它在很大程度上是帮你减少了程序犯错的可能性。像方法不得超过60行的这种规定,缩短了你的方法的篇幅,降低了出错的可能性。虽然现在接触到的设计规范只是很少的一部分,但相信在以后的工作中这个东西会一直伴随着我们。
第二,我认识到了设计程序的重要性。一个好的设计,将会大大提高你的变成效率。第一次作业的时候,我没有进行很好的设计,就开始了代码的编写,这样不仅进度慢,而且会被其中的bug很深深的折磨,并且,还导致了后面的作业的重构。一个好的程序设计方式,应该是先进行一个很好的规划,比如先考虑要用到哪些类、这些类之间有没有继承的关系等等。
第三,这三次作业提高了我的工程的能力。这三次作业的代码量比起原来的C语言,是大大提高了的,通过作业的完成和程序的不断地调试,让我对工程化方法理解的更加深入。
第四,我对面向对象的思想有了进一步的认识。面向对象,这四个字虽然一直在耳边回想,但原先我一直不知道真正的内涵,直到这几次作业和实验课亲身的去编写了面向对象的程序,才开始发现其中的奥秘。哪些类需要继承、哪些类需要接口、类中的变量的类型选择等等,在作业进行中遇到的种种问题,都需要资料的查询和同学之间的讨论。
总之,这一阶段已经结束,电梯马上就要来了......希望大家一起努力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号