C语言——基础链表详解
敢于向黑暗宣战的人,心里必须充满光明。

一、链表的构成
1.构成
链表是由一连串的结构(称为结点)组成的。
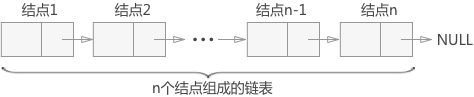
(1)结点的构成:
数据(要储存的数据)+指针(指向下一个结点的指针)
(2)关于几个定义
头结点:链表首结点前的一个结点(不是必须的,但是如果有就可以在解决某些问题时候方便一些,通常可以用来储存链表的长度等信息)
首结点:链表的第一个数据元素
头指针:必须要有的(而头结点可以没有,注意两者一个是指针一个是结点,一个必须有一个可以没有),指向头结点/首节点的指针(永远指向链表的第一个结点)
2.结点类型声明、创建结点
struct node{
int value;
struct node *next;//创建了一个指向一个node类型的指针,用于指向下一个结点
};
//至此声明了一个结点类型
//头指针:
struct node *first = NULL;
//结点创建:
struct node *new_node;
new_node = (struct node *)malloc(sizeof(struct node));//给结点分配内存单元。注意:malloc返回的是void类型的指针,所以可以强制类型转换一下
new_node -> value = 10;//把数据存储到结点中二、在链表开始处插入结点
struct node * first = NULL;
struct node *new_node;
new_node =(struct node *)malloc(sizeof(struct node));
new_node ->value = 10;
//将new_node结点插入链表开始处
new_node->next = first;//new_node指向的node类型的next值为NULL,NULL可作为链表结尾(空指针)
first = new_node;//让first 指向 new_node指向的结点(其实就是刚才malloc出来的结点)
//ok至此,现在就已经有了一个链表,它有一个结点,结点中储存的值是10
new_node = (struct node*)malloc(sizeof(struct node));
new_node ->value = 2;
new_node->next = first;//又新创建了个结点并让next指向第一次创建的结点(因为first是指向第一次创建的结点的)
first = new_node;//可以理解为把头指针重置到头部我们把它封装成函数
对于这样的函数我们传入一个链表list,和一个希望存入链表的数值n
struct node* add_to_list(struct node *list,int n)
{
sturct noed *new_node;
new_node = (struct node*)malloc(sizeof(struct node));
if(new_node == NULL)
{
printf("malloc error\n");
exit(0);
}
new_node->value = n;
new_node->next = list;//把新结点接到链表中
return new_node;
}
first = add_to_list(first,10);
first = add_to_list(first,20);
//需要注意的是add_to_list函数是没有办法修改指针的(因为这个相当于复制了一个指针传进去,能修改它指向的东西,但是没有办法对他本身进赋值存储)
//所以我们返回一个指向新结点的指针,让他作为返回值赋值储存给first需要注意的是add_to_list函数是没有办法修改指针的(因为这个相当于复制了一个指针传进去,能修改它指向的东西,但是没有办法对他本身进赋值存储),所以我们返回一个指向新结点的指针,让他作为返回值赋值储存给first
三、搜索链表
while循环可以用,但是我们都知道for循环是很灵活的。这是一张访问链表中结点的习惯方法:
[惯用方法]
for (p = first; p !=NULL; p = p->next)...
这里可以使用指针变量p来追踪结点,p = p->next 就能实现了让p从一个结点移动到下一个结点
第一种方法:
struct node* search_list(struct node *list,int n)
{
struct node *p;
for(p = list; p != NULL; p = p->next)
{
if(p -> value == n)
return list;
}
return NULL;
}第二种方法:
struct node *search_list(struct node *list,int n)
{
for(;list != NULL;list = list->next)
{
if(list->next == n)
return list;
}
return NULL;
}这里list是原始链表指针的副本,所以在函数中对他改变是没有损害的
四、从链表中删除结点
步骤:
1.定位要删除的结点(搜索链表)
2.改变前一个结点的指向,从而使链表“绕过”希望删除的结点
3.调用free函数收回期望删除的结点占用的内存空间
一种方法:“追踪指针”法,在搜索链表时总是保留一个指向前一个结点的指针(prev)还有一个指向当前指针的结点(cur)。
如下:(list是带搜索链表,n是要删除的整数)
for(cur = list,prev = NULL;cur != NULL && cur->value != n;prev = cur,cur = cur ->next);
prev->next = cur->next;//条件为假,结束循环,让prev指向cur的下一个结点从而完成“绕过”操作注意:表达式3是每次循环中最后一次被执行的操作
然后在free掉cur,让prev指向next
封装成函数:
struct node *delete_list(struct node *list,int n)
{
struct node *prev,*cur;
for(cur = list,prev = NULL;cur != NULL && cur->value != n;prev = cur,cur = cur->next);
//这个for循环只是为了找到希望删除的结点即value等于n的结点
if(cur == NULL)//找到了最后也没找到要删除的结点,不用删除,返回list
return list;
if(prev == NULL)//条件为假,未执行for循环,即首结点为n,直接让list指向下一个结点来绕过即可
list = list->next;//对于删除链表中的首结点是一种特殊情况,需要特殊判断特殊绕过他。
else
prev->next = cur->next;//绕过要删除的结点
free(cur);//释放掉被删除的结点的内存
return list;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号