模型评估
用在测试集上的测试误差作为泛化误差的近似
测试误差,或者测试集的获得就要依据不同的评估方法
评估方法
留出法
将数据集划分为两个互斥的集合,其中一个集合作为训练集,另一个作为测试集
划分过程中尽可能保持数据分布的一致性,保留类别比例的采样方法称为“分层采样”
交叉验证法
将数据集D划分为k个大小相似的互斥子集,每次用k-1个子集的并集作为训练集,余下的子集作为测试机,这样一共进行k次训练,因此也称为“k折交叉验证”
为了减小因样本划分不同而引入的差别,通常需要用不同的划分重复p次,最终的结果是p次k折交叉验证结果的均值
若k的大小和数据集中样本的个数相同,那么就是留一法,显然留一法并不会受到随机样本划分的影响,但是计算开销较大
自助法
基于自助采样(有放回采样)
给定包含m个样本的数据集D,对其进行如下的采样:每次随机从D中挑选一个样本,并将其拷贝放入数据集\(D'\)中,然后再将该样本放回初始数据集D中,是的该样本在下次采样时仍有可能被采到
这样重复m次后,将能得到一个包含m个和样本的数据集\(D'\),同时有一部分样本可能从未被采样到,可以通过极限估计m次采样都没有被采到的概率为\(\underset{m \to \infty}{lim}(1-\frac{1}{m})^m \to \frac{1}{e} \approx \frac{1}{3}\)
使用m个训练样本,仍有数据总量约\(\frac{1}{3}\)、没在训练集中出现的样本可用于测试
在数据集较小、难以有效划分训练/测试集时很有用,其余情况下可能会借鉴该重采样思想
调参
模型评估与选择中用于评估测试的数据集常成为"验证集"
验证集用于调整模型的超参数和选择最佳模型,测试集用于最终评估模型的性能
测试集只会被使用一次,而验证集会被使用多次,以得到最优的超参数和模型
性能度量
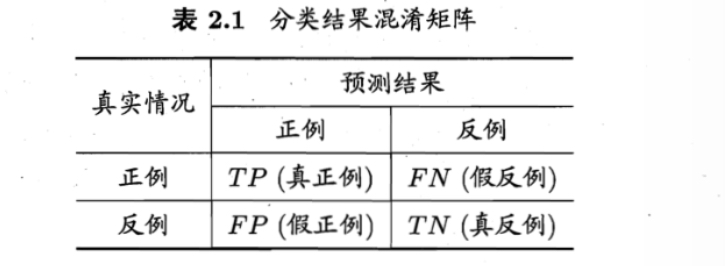
评估学习器f的性能,要把学习器预测结果f(x)与真实标记y进行比较
最常用的均方误差就是基于该思想:\(E(f;D)=\int _{x \sim D} (f(x)-y)^2p(x)dx\)
量化模型的容量使得统计学习理论可以进行量化预测。统计学习理论中最重要 的结论阐述了训练误差和泛化误差之间差异的上界随着模型容量增长而增长, 但随着训练样本增多而下降。
查准率和查全率
positive:分类结果为真,true:对分类结果的判断
查准率:\(P=\frac{TP}{TP+FP}\) 判断为真的数据中,有多少确实为真
查全率:\(R=\frac{TP}{TP+FN}\) 实际为真的数据中,有多少判断为真
查准率和查全率一对相互矛盾的度量,对于同一个学习模型而言,如果想要得到较高的查全率,那么必然需要判断更多的样本,因此查准率自然会有所下降
据此,我们可以绘制P-R曲线:根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,然后每次可以计算出当前的查全率、查准率
例如得到下面的P-R曲线
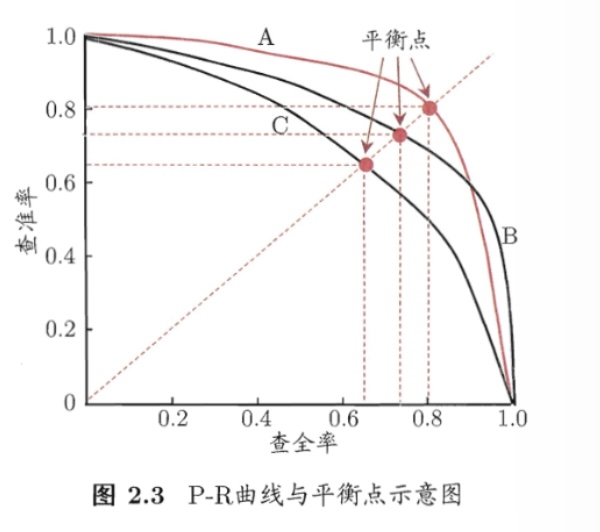
如果一个学习器的P-R曲线被另一个学习器的学习完全包裹,则可断言后者的性能更优,但除此之外的情况就需要一些量化的标准进行比较
例如\(F_\beta\),\(F_\beta\)可以看作是查准率和查全率的加权调和平均,而\(F_1\)就是\(\beta=1\)的调和平均特例,\(F_\beta=\frac{(1+\beta ^2)\times P \times R}{(\beta ^2 \times P)+R}\)
\(\beta > 0\)表征了查全率对查准率的相对重要性
和查准率和查全率类似的还有真正例率和假正例率,以及由此得到的ROC曲线
代价敏感错误率
权衡不同类型错误造成的不同损失,可以为错误赋予"非均等代价"
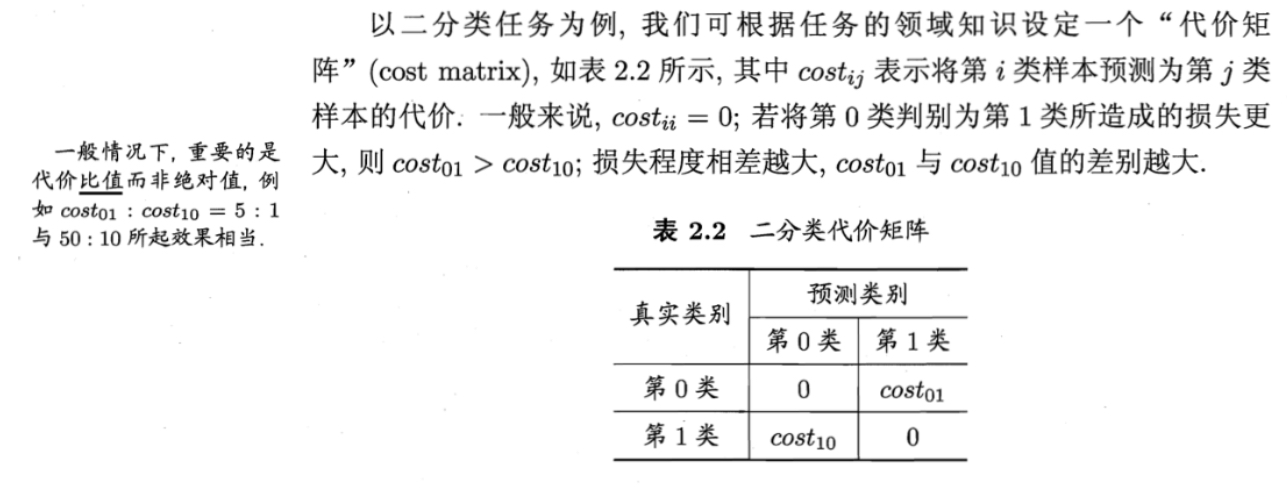
从而代价敏感错误率为\(E(f; D; cost) = \frac{1}{m} \left( \sum_{\boldsymbol{x}_i \in D^+} \mathbb{I}(f(\boldsymbol{x}_i) \neq y_i) \times cost_{01} \right. \\
\left. + \sum_{\boldsymbol{x}_i \in D^-} \mathbb{I}(f(\boldsymbol{x}_i) \neq y_i) \times cost_{10} \right)\)
在非均等代价下,ROC曲线不能反映出学习器的期望总体代价,此时可以使用代价曲线来达到该目的
精度和错误率
错误率 \(E=\frac{a}{m}\),精度=1-错误率
更规范的表示,错误率定义为:\(E(f;D)=\frac{1}{m}\sum\limits_{i=1}^{m}\mathbb{I}(f(x_i)\neq y_i)\)
VC维
VC维度量二元分类器的容量。VC 维定义为该分类器能够分类的训练样本的最大数目。
假设存在 m 个不同 x 点的训练集,分类器可以任意地标记该 m 个不同的 x 点,VC 维被定义为 m 的最大可能值。
偏差和方差
"偏差-方差分解"是解释学习算法泛化性能的一种重要工具
令f(x;D)为训练集D上学得模型f在x上的预测输出
从而使用样本数相同的不同训练集产生的方差为\(\text{var}(x) = \mathbb{E}_D \left[ \left( f(x; D) - \bar{f}(x) \right)^2 \right]\)
噪声为\(\varepsilon^2 = \mathbb{E}_D \left[ \left( y_D - y \right)^2 \right]\)
偏差(期望输出与真实标记的差别)为\(\text{bias}^2(x) = \left( \bar{f}(x) - y \right)^2.\)
泛化误差可以表示为偏差、方差和噪声之和:\(E(f;D)=\text{bias}^2(x)+\text{var}(x)+\varepsilon^2\)
方差度量数据量相同的训练集所导致的学习性能的变化,刻画了数据扰动所造成的影响
噪声表达了学习算法所能到达的期望泛化误差的下界,可以视作学习问题本身的难度,反映了数据本身的随机性和不确定性
偏差度量了学习算法的期望预测与真实结果的偏离程度,刻画了学习算法本身的拟合能力
在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的特性被学习器学到了,则将发生过拟合.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号