Solr In Action 笔记(3) 之 SolrCloud基础
2014-11-07 00:00 追风的蓝宝 阅读(3794) 评论(0) 收藏 举报Solr In Action 笔记(3) 之 SolrCloud基础
在Solr中,一个索引的实例称之为Core,而在SolrCloud中,一个索引的实例称之为Shard;Shard 又分为leader和replica。
1. SolrCloud的特质
作为分布式搜索引擎的SolrCloud具有以下几个特质:
- 可扩展性
所谓的可扩展性就是指可以通过扩大集群的规模来实现性能的提升。有两种方式来实现可扩展性,一种是纵向扩展,即加快CPU速度,增加RAM,提升磁盘I/O性能等,另一种是横向扩展,就是分布式系统中使用的通过增加节点来扩大集群规模。SolrCloud采用的时横向扩展,可以通过两个方式来实现扩展,一种是增加shard,它实现的是将大数据量的index切分成多个小的index,这种方式是从将每个shard的数据量的角度来提升SolrCloud的性能的,另一种是增加replica,即增加shard的备份的数量,这种方式的优点是增加SolrCloud的并发查询能力以及容灾能力,至于原因在接下来会具体阐述。基本上对于SolrCloud来说,它的计算能力随着资源(即shard)的增加成正比。
以下是Solrcloud扩展性具有的限制以及改善方法。
|
Scalability / limitation
|
Mitigation strategy
|
|
Number of documents indexed: Having a large number of documents in an index impacts the performance of faceting, sorting, and constructing filters. Also, we are currently limited to 2.1 billion documents per Lucene index due to the document ID being stored as an integer. |
Split large indexes into multiple smaller indexes using sharding; |
|
Document size and complexity: Having many fields or large text fields requires more memory and faster disk I/O. |
Add more RAM and faster disks. |
|
Indexing throughput: You may need to index thousands of documents per second. |
Distribute indexing operations across multiple nodes using sharding. |
|
Document volatility: If existing documents change frequently, your indexes will be more volatile, requiring constant seg- ment merging. |
Get faster disks to facilitate constant seg- ment merging; |
|
Query volume (typically measured by QPS—queries per second). |
Use replication to increase the number of threads available to execute queries. |
|
Query complexity: This includes facets, grouping, custom sorting impact, and query execution performance. |
Use sharding and replication to parallel- ize complex query computations such as faceting and sorting. |
- 高可用性
高可用性主要还是指SolrCloud的容灾能力,SolrCloud使用leader和replica以及交叉备份的方式实现数据的冗余以实现很好的容灾性能,leader和replica是同一shard的相同数据,存放在不同的主机上。当某台主机宕机时,该主机的数据在另外的主机上具有备份,这样就确保了数据的不丢失,同时SolrCloud在进行查询的时候是只对认准shard而不区分leader和replica,所以即使有一台主机宕机了也不会影响SolrCloud的查询结果,它只是稍微影响了查询性能。
- 一致性
对于一个分布式搜索引擎来说,一致性,性能,以及分割容差是三个主要指标,其中一致性与读写性能是个矛盾的指标,以SolrCloud为例,SolrCloud选择了一致性而适当放弃了写的性能。SolrCloud具有replica时,当有数据建立索引,SolrCloud首先将数据update至leader shard,然后leadershard再将数据进行分发至各个replica shard,leader shard进行分发是个同步的过程,也就是说它会一直等到所以replica shard的数据update成功才会返回成功,中间一旦出现错误就视为失败,这样就充分保证了leader和replica的数据一致性,当然这也就降低了写的速度。这里需要说明的是,当replica是不上线状态时候,SolrCloud的leader是不会分发至这个replica shard的,关于shard 的状态在下文中将会具体介绍。至于为什么SolrCloud对弱一致性的零容忍态度,主要是避免索引的部分成功以及多个shard查询结果的不同。
- 简单性
当有主机recovering失败了,当我们处理完失败的原因后将该主机上线,SolrCloud会自动从leader那进行数据同步。
- 伸缩性
SolrCloud支持将一份shard分成两份小的shard
2. Zookeeper
SolrCloud使用zookeeper主要实现以下三点功能:
- 集中配置存储以及管理
- 集群状态改变时进行监控以及通知
- shard leader选举
关于zookeeper的具体介绍请看《Zookeeper之基础学习》。
2.1 zookeeper 数据类型
Zookeeper的组织结构是类似于文件系统,如下图所示,每一个层是一个Znode,每一个Znode存储了一些元数据例如创建时间,修改时间以及一些小量的数据。这里需要指出,Zookeeper并不支持存放大数据数据,它只支持小于1M大小的数据,这是因为性能原因,Zookeeper将数据存放在内存中。
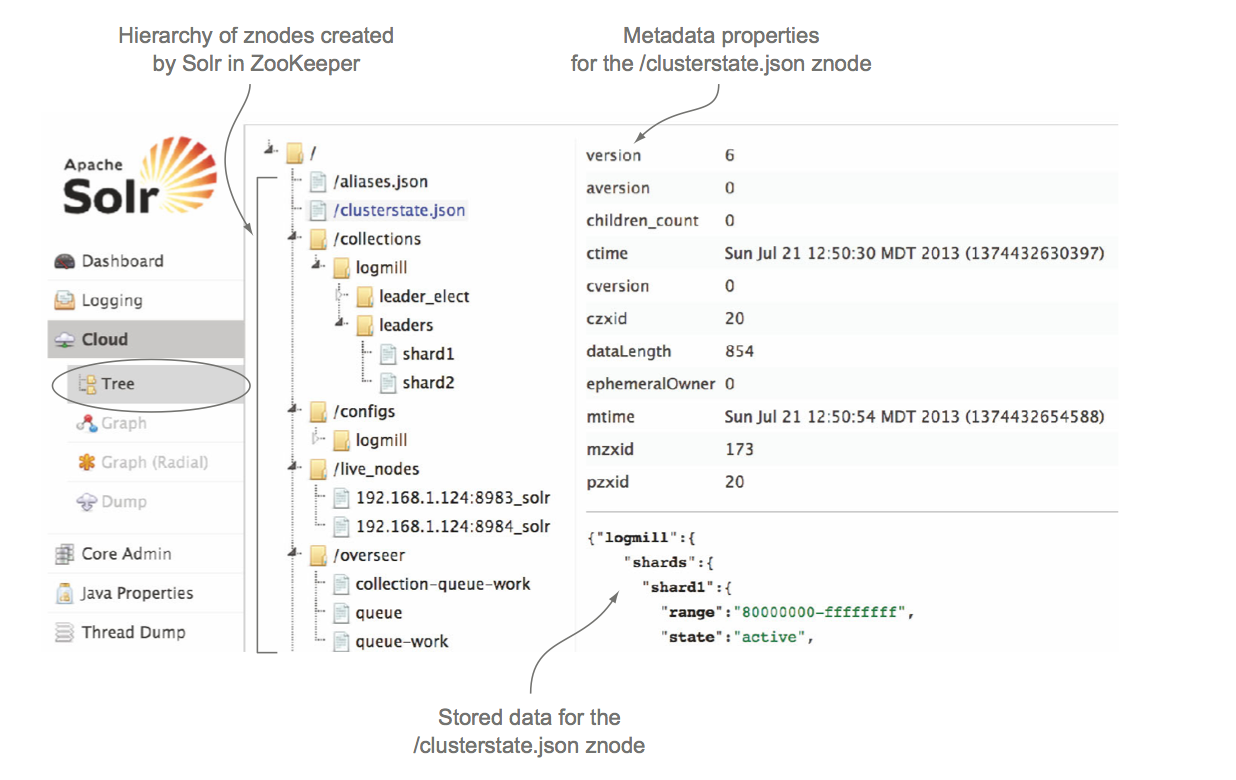
Zookeeper另一个重要的概念是短链接,当Zookeeper客户端与Zookeeper建立一个短连接后会在Zookeeper新建一个Znode,客户端会一直与Zookeeper进行通信并保证这个Znode一直存在。如果当客户端与Zookeeper的短连接断开,这个Znode就会消失。在SolrCloud中,/live_nodes下就会存在所有客户端的短连接,表示现在有哪些Solr组成SolrCloud。
当Solr跟Zookeeper保持短连接时,这些Solr主机就组成了SolrCloud,如果其中一个Solr的短连接断掉了,那么Live_nodes下就少了一个Znode,SolrCloud也就少了一个主机,于是Zookeeper就会告诉其他剩余的Solr有一个Solr挂掉了,等会进行查询以及leader数据分发时候不用再经过刚才那个Solr了。那么Zookeeper是如何知道有Solr挂了呢,这就是下面要讲的watcher
2.2 Znode Watcher
Znode Watcher是Zookeeper一个重要概念和特性,当Znode发生变化时候,Zookeeper会告诉所有在该Znode注册的Watcher这个Znode改变了,从而出发相应的事务。比如SolrCloud的/clusterstate.json Znode,SolrCloud的所有的Solr都会在这里进行注册,如果当有新的replica或者node下线了,所有的watcher就会收到通知,然后每一个Solr就会更新它的clusterstate。这在SolrCloud的shard leader选举过程中将会详细介绍。
2.3 配置
Zookeeper同样是个分布式系统,同样具有容灾能力和扩展能力。首先简要描述下集群的容灾的能力,Zookeeper集群能有效的运行的基本要求是它的实际运行节点的数量大于集群总数量的一半,也就是说如果实际部署的Zookeeper的集群节点个数为5个,那么当出现故障时候,正常的Zookeeper节点个数至少3个才能保证Zookeeper继续正常运行。所有一般情况下,Zookeeper集群的节点个数都为奇数(2N+1,N为至少存活的节点个数)。
Zookeeper被建议独立部署,不要使用SolrCloud的内置zookeeper以及和Solr一起使用。当Zookeeper下线时候,经测试发现,虽然SolrCloud无法正常启动,建索引功能异常,但是由于每一个Solr节点保存了之前zookeeper的状态以及配置信息,我们仍然可以对SolrCloud进行查询,且结果和性能正常。
SolrCloud配置Zookeeper时候,需要在solr.xml内的zkHost加入zookeeper节点配置,如zk1.example.com:2181, zk2.example.com:2181 。
2.4 Zookeeper Client Timeout
当Solr加入集群后,会在Znode上建立短连接,当Solr下线时候,Zookeeper就会删除这个Znode。我们希望Zookeeper能够尽可能快的察觉出SolrCloud的集群状态变化。默认情况下,这个时间是15秒,我们可以设置zkClientTimeout 这个配置来修改他。
请注意,当JVM进行full垃圾回收的时候会暂停所有正在运行的线程,当然也包括zookeeper的线程。如果full垃圾回收所持续的时间大于zkClientTimeout,那么就会出现SolrCloud以为zookeeper已经下线而无法正常工作,所以如果zookeeper出现异常下线,请去查看垃圾回收的日志来排除是否这个引起的。
2.5 Zookeeper的配置存储以及分布式管理
Zookeeper在SolrCloud的一个重要的功能是存储SolrCloud的配置以及对配置进行分布式管理。我们可以将配置信息(比如solrconfig.xml和schmea.xml)上传至Zookeeper,如果这些配置信息发生变化Zookeeper就会将这些新的配置文件更新到集群中每一个Solr节点上,如果有新的Solr加入集群,那么Zookeeper就会传递给他一份配置文件,Zookeeper很好的完成了一个配置文件的存储以及分布式管理的功能。Zookeeper上存储的文件最大为1M,关于Zookeeper的具体介绍请看另外的文章。
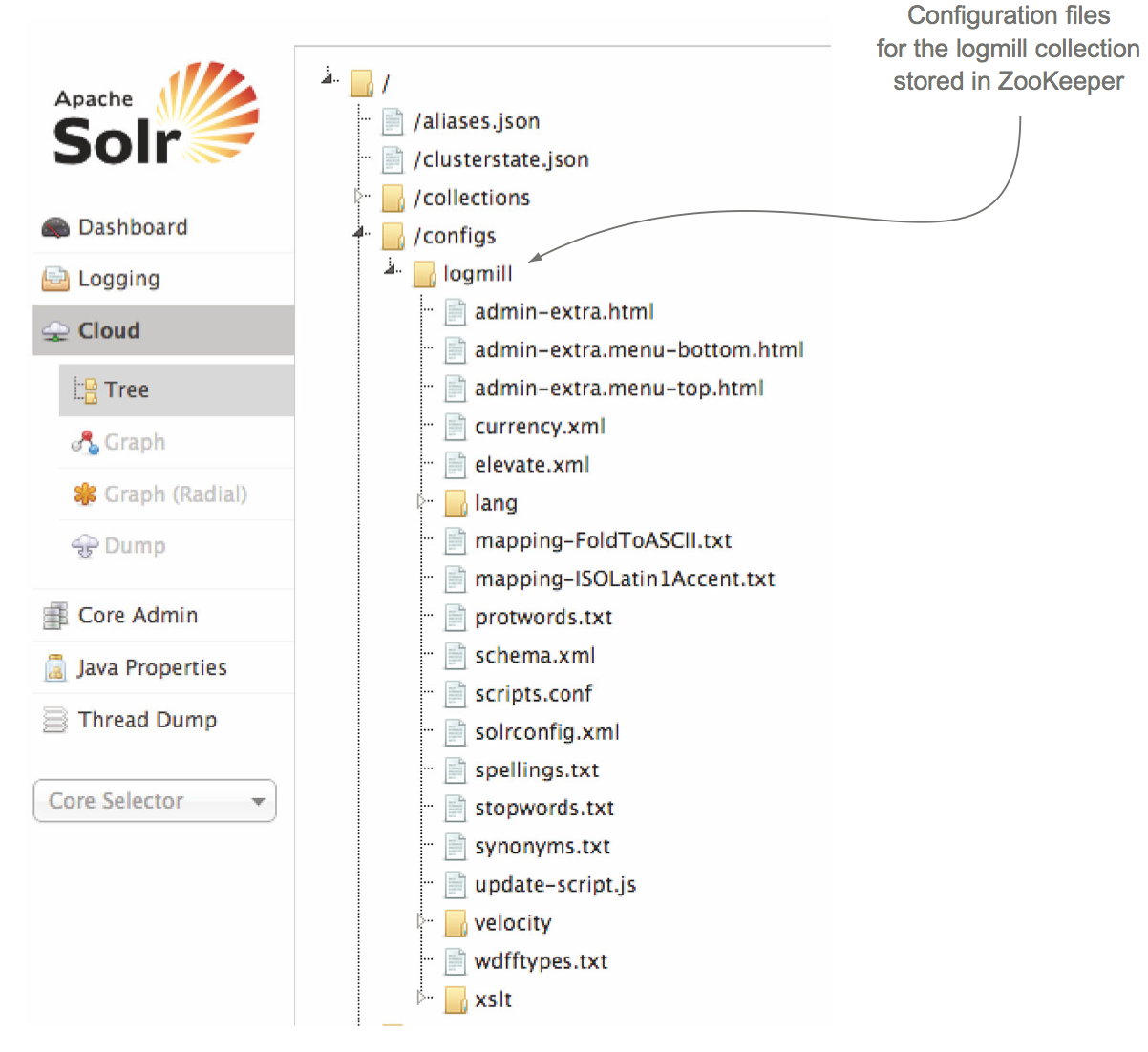
3 Shard 和 Replica
3.1 Shard和Replica的数量
增加Shard和Replica的数量能提升SolrCloud的查询性能和容灾能力,但是我们仍然得根据实际的document的数量,document的大小,以及建索引的并发,查询复杂度,以及索引的增长率来统筹考虑Shard和Replica的数量。
3.2 集群管理
正常的SolrCloud Index 和Query都需要集群的shard 和 replica 都处于active状态, shard leader需要知道它的所有的active Replica才能进行update操作。SolrCloud具有多种状态:
| 状态 | 描述 |
|
Active |
Active nodes are happily serving queries and accepting update requests. Active rep- licas are in sync with their shard leader. A healthy cluster is one in which all nodes are active. |
|
Inactive |
Used during shard splitting to indicate that a Solr instance is no longer participating in the collection. Shards that get split enter this state once the splits are active. |
|
Construction |
Used during shard splitting to indicate that a split is being created. Shards in this state buffer update requests from the parent shard but do not participate in queries. |
|
Recovering |
Recovering instances are running but can’t serve queries. They do accept update requests while recovering so that they don’t continue to fall behind the leader. |
|
Recovery Failed |
The instance attempted to recover but encountered an error. In most cases, you will need to consult the logs and manually resolve the issue preventing the instance from recovering. |
|
Down |
The instance is running and is connected to ZooKeeper but is not in a state in which it can recover, such as when Solr is initializing. A downed instance does not partici- pate in queries or accept updates. The down state is usually temporary, and the node will transition to one of the other states. |
|
Gone |
The instance is not connected to ZooKeeper and has probably crashed. If a node is still running but ZooKeeper thinks it’s gone, the most likely cause is an OutOfMemoryError in the JVM. |
Solr依赖Zookeeper实现集群的管理,在Zookeeper中有一个Znode 是/clusterstate.json ,它存储了当前时刻下整个集群的状态。同时在一个集群中有且只会存在一个overseer,如果当前的overseer fail了那么SolrCloud就会选出新的一个overseer,就跟下文要讲的shard leader 选取类似。
每一个Index 实例,无论是leader还是replica都会在/clusterstate.json上注册一个watcher以便于接受集群状态变更的通知,当有一个新的Solr节点加入Zookeeper时候,overseer就会更新修改/clusterstate.json,一旦/clusterstate.json发生修改,Zookeeper就会通知所有的Index 实例,让他们更新集群信息的缓存。同理其他的集群状态变更。
3.3 Shard leader 选举
Shard leader的选举对于SolrCloud来说还是很重要的过程,虽然Shard leader选举并不直接影响SolrCloud的查询,但是却大大影响了SolrCloud的建索引过程。关于SolrCloud的Index过程将在下一节介绍。Shard leader在index过程中主要起到以下作用:
- 接受shard的update请求
- 在需要的update的document中加入_version_域,并实施 optimistic lock
- 将document写入update log
- 并行发送document到所有的replica,直到replica返回完成相应才结束
首先,任何node 包括replica都可以被自动选举为leader,leader的选举同样依靠Zookeeper。选举过程如下:
启动时候:
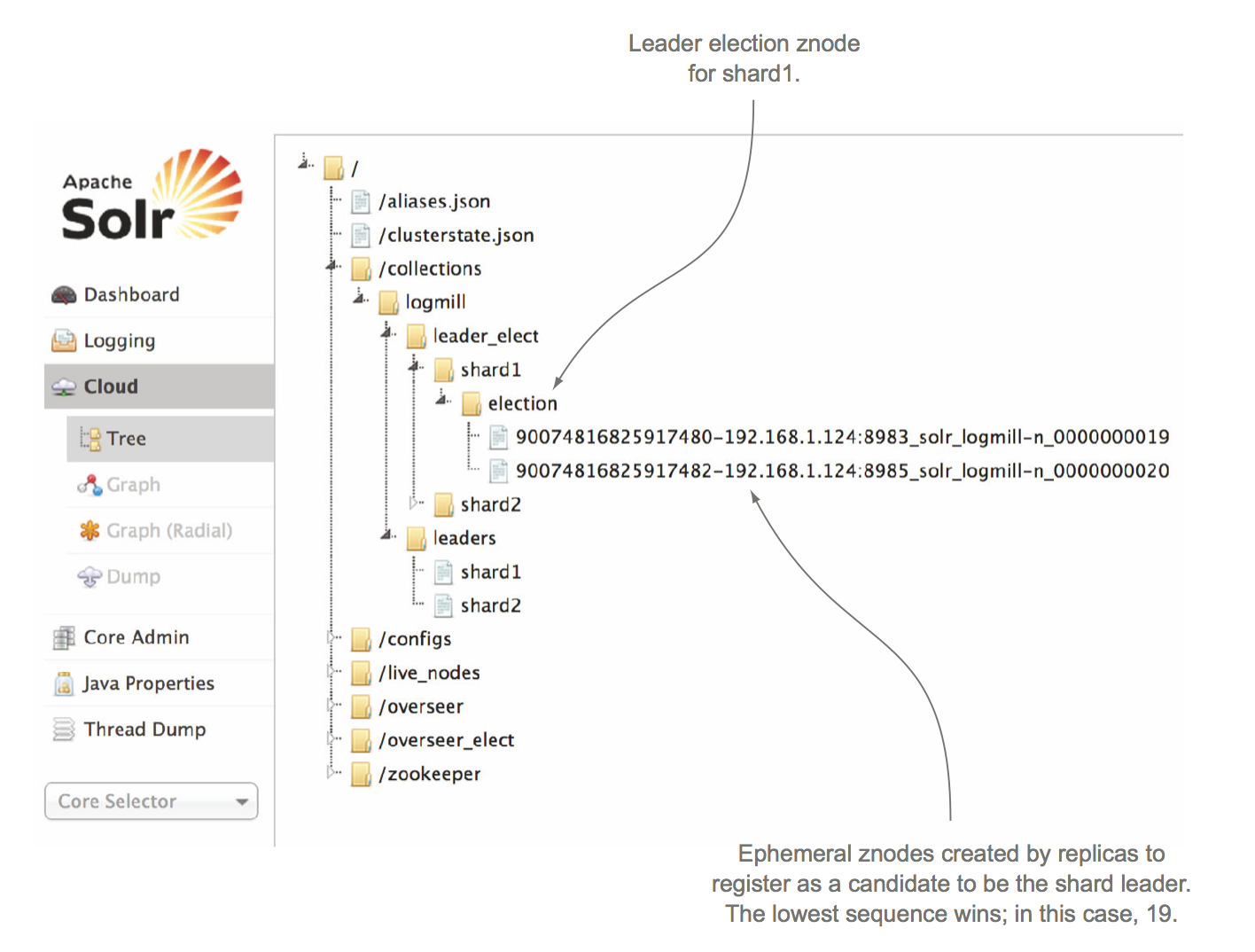
- 当Index实例(shard)上线时,它会尝试短连接至zookeeper,并在Zookeeper创建对应shard的Znode,比如/collections/logmill/leader_select/shard1/election/XXX_node1_0000001,其中logmill表示collection的名字,shard1表示是shard的编号,XXX_node1_0000001表示最终创建的Znode的名字,XXX我们暂时不关心。
- 如果我们设置多个Replica时候,那么一个shard就会有多个Index实例去短连接至zookeeper,并同样在Zookeeper上创建shard的Znode,比如/collections/logmill/leader_select/shard1/election/XXX_node1_0000002。
- Zookeeper的短连接成功后,会给Znode创建一个编号,这个编号是同步自增的,也就是说,多个短连接请求时候Zookeeper会保证处理完一个后再处理另一个,所以不同的短连接生成的Znode编号是递增的且不会重叠的。由于受到节点自身的性能以及网络等影响,不同节点短连接存在先后顺序从而造成Znode编号不同,比如XXX_node1_0000001,XXX_node1_0000002,那么SolrCloud选举Shard Leader的策略很简单,即始终保持leader_select/shard1/目录下编号最小的为leader,其他的为replica,比如XXX_node1_0000001为leader,XXX_node1_0000002为replica。
- 选好leader后,会在/collections/logmill/leader/shard1下生成leader的信息。
- Replica知道自己不是leader后,它会在leader的节点上(比如XXX_node1_0000001)注册一个watcher,该watcher一直监控leader的状态。
上述过程是正常启动SolrCloud的leader选举过程,那么接下来来了解下leader下线触发leader重新选举:
leader重新选举:
- 正常运行的SolrCloud已产生一个leader(Znode编号最小,比如XXX_node1_0000001),后续的Replica后在leader节点上注册Watcher。当Leader下线时候,即短连接断开,那么Zookeeper上的Znode(比如XXX_node1_0000001)就会被删除。
- 此时,所有Replica在Leader节点上的watcher就会监控到这一变化,所有的Replica就会进行leader选举,选举的原则依然是判断自己是不是目前注册在/collections/logmill/leader_select/shard1/election下的Znode编号最小的那位,是的话就是Leader,否则就是Replica
- 如果判断自己是Replica,就会继续在leader的Znode上(这个时候的leader是XXX_node1_0000002)注册watcher,等待leader下线再次触发选举leader。
- 如果这个时候原先下线的leader上线了会怎么样,它就会被当做新的一个Solr节点注册到Zookeeper上,并获取一个比现有Znode更大的编号,在Leader Znode节点上注册watcher,等待它的选举机会。
leader的选举还是蛮简单的,下图是leader选举好的效果图:
leader选举源码
leader选举过程主要在LeaderElector类中。
-
joinElection 主要实现shard节点在Zookeeper上建立短连接,并生产Znode,获取Znode编号。
1 public int joinElection(ElectionContext context, boolean replacement) throws KeeperException, InterruptedException, IOException { 2 context.joinedElectionFired(); 3 //select Znode节点的路径 4 final String shardsElectZkPath = context.electionPath + LeaderElector.ELECTION_NODE; 5 6 long sessionId = zkClient.getSolrZooKeeper().getSessionId(); 7 String id = sessionId + "-" + context.id; 8 String leaderSeqPath = null; 9 boolean cont = true; 10 int tries = 0; 11 while (cont) { 12 try { 13 //在Zookeeper创建短连接,并创建Znode,生成Znode编号 14 leaderSeqPath = zkClient.create(shardsElectZkPath + "/" + id + "-n_", null, 15 CreateMode.EPHEMERAL_SEQUENTIAL, false); 16 //Znode路径 17 context.leaderSeqPath = leaderSeqPath; 18 cont = false; 19 //如果短连接建立失败,进行多次尝试。 20 } catch (ConnectionLossException e) { 21 // we don't know if we made our node or not... 22 List<String> entries = zkClient.getChildren(shardsElectZkPath, null, true); 23 24 boolean foundId = false; 25 for (String entry : entries) { 26 String nodeId = getNodeId(entry); 27 if (id.equals(nodeId)) { 28 // we did create our node... 29 foundId = true; 30 break; 31 } 32 } 33 if (!foundId) { 34 cont = true; 35 if (tries++ > 20) { 36 throw new ZooKeeperException(SolrException.ErrorCode.SERVER_ERROR, 37 "", e); 38 } 39 try { 40 Thread.sleep(50); 41 } catch (InterruptedException e2) { 42 Thread.currentThread().interrupt(); 43 } 44 } 45 46 } catch (KeeperException.NoNodeException e) { 47 // we must have failed in creating the election node - someone else must 48 // be working on it, lets try again 49 if (tries++ > 20) { 50 throw new ZooKeeperException(SolrException.ErrorCode.SERVER_ERROR, 51 "", e); 52 } 53 cont = true; 54 try { 55 Thread.sleep(50); 56 } catch (InterruptedException e2) { 57 Thread.currentThread().interrupt(); 58 } 59 } 60 } 61 //Znode的编号 62 int seq = getSeq(leaderSeqPath); 63 //开始进行leader选举 64 checkIfIamLeader(seq, context, replacement); 65 66 return seq; 67 }
-
checkIfIamLeader 开始真正的leader选举,根据Zookeeper上创建的Znode的编号大小判断自己是否是leader,如果是replica,则在leader的Znode上注册watcher,等到再次进行leader选举
1 private void checkIfIamLeader(final int seq, final ElectionContext context, boolean replacement) throws KeeperException, 2 InterruptedException, IOException { 3 context.checkIfIamLeaderFired(); 4 // get all other numbers... 5 final String holdElectionPath = context.electionPath + ELECTION_NODE; 6 //获取现有的select Znode节点下已注册的所有的Znode 7 List<String> seqs = zkClient.getChildren(holdElectionPath, null, true); 8 //对所有shard的Znode按Znode编号进行从小到大排序 9 sortSeqs(seqs); 10 List<Integer> intSeqs = getSeqs(seqs); 11 if (intSeqs.size() == 0) { 12 log.warn("Our node is no longer in line to be leader"); 13 return; 14 } 15 //如果自己的shard的Znode编号是最小的,那么就进行自己就是leader 16 if (seq <= intSeqs.get(0)) { 17 // first we delete the node advertising the old leader in case the ephem is still there 18 try { 19 zkClient.delete(context.leaderPath, -1, true); 20 } catch(Exception e) { 21 // fine 22 } 23 24 runIamLeaderProcess(context, replacement); 25 } else { 26 //如果自己的shard的Znode编号不是最小的,那么自己就是replica,则在Znode找出谁是leader 27 // I am not the leader - watch the node below me 28 int i = 1; 29 for (; i < intSeqs.size(); i++) { 30 int s = intSeqs.get(i); 31 if (seq < s) { 32 // we found who we come before - watch the guy in front 33 break; 34 } 35 } 36 int index = i - 2; 37 if (index < 0) { 38 log.warn("Our node is no longer in line to be leader"); 39 return; 40 } 41 //找出leader后,在leader的Znode上注册watcher,监视leader状态。 42 try { 43 zkClient.getData(holdElectionPath + "/" + seqs.get(index), watcher = new ElectionWatcher(context.leaderSeqPath , seq, context) , null, true); 44 } catch (KeeperException.SessionExpiredException e) { 45 throw e; 46 } catch (KeeperException e) { 47 log.warn("Failed setting watch", e); 48 // we couldn't set our watch - the node before us may already be down? 49 // we need to check if we are the leader again 50 checkIfIamLeader(seq, context, true); 51 } 52 } 53 }
最后将下SolrCloud的leader策略,一开始一直蛮鄙视SolrCloud的这个leader策略,也曾花了一段时间来重写leader策略,该策略的效果是使得每一个shard的leader均匀分布在每一台服务器上,也就是说每一台服务器只会有一个leader,这样的效果就是无论查询还是建索引,每一台服务器的负载是完全均衡的,而且如果leader挂机再上线后,该leader能马上重新变成leader而不会成为Znode编号最大的Replia。随着对SolrCloud的理解的深入,越来越觉得这个leader策略的妙处以及我的修改的错误,好处在前文已经详细介绍了。所以建议对于这个leader策略没必要还是不要去修改了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号