Solr4.8.0源码分析(12)之Lucene的索引文件(5)
2014-10-20 21:21 追风的蓝宝 阅读(1159) 评论(0) 收藏 举报Solr4.8.0源码分析(12)之Lucene的索引文件(5)
1. 存储域数据文件(.fdt和.fdx)
Solr4.8.0里面使用的fdt和fdx的格式是lucene4.1的。为了提升压缩比,StoredFieldsFormat以16KB为单位对文档进行压缩,使用的压缩算法是LZ4,由于它更着眼于速度而不是压缩比,所以它能快速压缩以及解压。
1.1 存储域数据文件(.fdt)
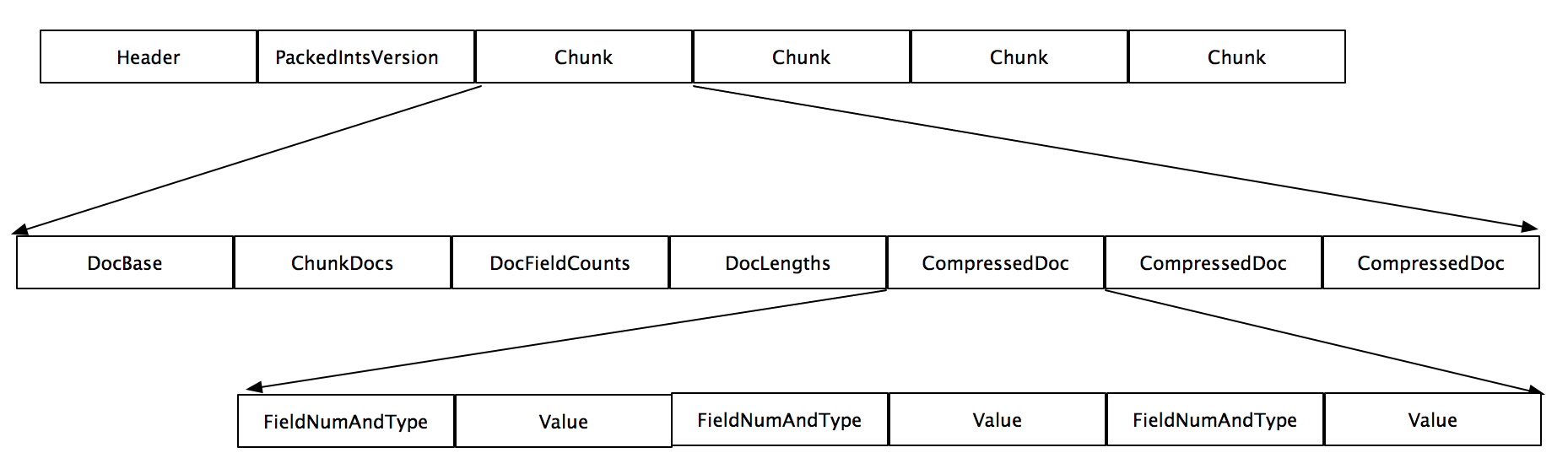
- 真正保存存储域(stored field)信息的是fdt文件,该文件存放了压缩后的文档,按16kb或者更大的模块大小为单位进行压缩。当要写入segment时候,文档会先被存储在内存的buffer里面,当buffer大小大于16kb或者更大时候,这些文档就会被刷入磁盘以LZ4格式压缩存放。
- fdt文件主要由三部分组成,Header信息,PacjedIntsVersion信息,以及多个块chunk。
- fdt是以chunk为单位进行压缩以及解压缩的,一个chunk块内含有一个或者多个document
- chunk内含有第一个document的编号即DocBase,块内document的个数即ChunkDocs,每一个Document的存储的Field的个数即DocFieldCounts,所有在块内的document的长度即DocLengths,以及多个压缩的document。
- CompressedDoc由FieldNumAndType和Value组成。FieldNumAndType是一个Vlong型,它的最低三位表示Type,其他位数表示FieldNum即域号。
- Value对应Type,
- 0: Value is String
- 1: Value is BinaryValue
- 2: Value is Int
- 3: Value is Float
- 4: Value is Long
- 5: Value is Double
- 6, 7: unused
- 如果文档大于16KB,那么chunk只会存在一个文档。因为一个文档的所有域必须全部在同一chunk种
- 如果在chunk块中多个文档较大且使得chunk大于32kb时,那么chunk会被压缩成多个16KB大小的LZ4块。
- 该结构不支持大于(231 - 214) bytes的单个文档
StoredFieldsFormat继承了CompressingStoredFieldsFormat,所以先通过学习CompressingStoredFieldsReader来Solr是怎么解析.fdx和.fdt的
1 public CompressingStoredFieldsReader(Directory d, SegmentInfo si, String segmentSuffix, FieldInfos fn, 2 IOContext context, String formatName, CompressionMode compressionMode) throws IOException { 3 this.compressionMode = compressionMode; 4 final String segment = si.name; 5 boolean success = false; 6 fieldInfos = fn; 7 numDocs = si.getDocCount(); 8 ChecksumIndexInput indexStream = null; 9 try { 10 //打开.fdx名字 11 final String indexStreamFN = IndexFileNames.segmentFileName(segment, segmentSuffix, FIELDS_INDEX_EXTENSION); 12 //打开.fdt名字 13 final String fieldsStreamFN = IndexFileNames.segmentFileName(segment, segmentSuffix, FIELDS_EXTENSION); 14 // Load the index into memory 15 //解析.fdx文件 16 indexStream = d.openChecksumInput(indexStreamFN, context); 17 //获取header 18 final String codecNameIdx = formatName + CODEC_SFX_IDX; 19 version = CodecUtil.checkHeader(indexStream, codecNameIdx, VERSION_START, VERSION_CURRENT); 20 assert CodecUtil.headerLength(codecNameIdx) == indexStream.getFilePointer(); 21 //开始解析blocks 22 indexReader = new CompressingStoredFieldsIndexReader(indexStream, si); 23 24 long maxPointer = -1; 25 26 if (version >= VERSION_CHECKSUM) { 27 maxPointer = indexStream.readVLong(); 28 CodecUtil.checkFooter(indexStream); 29 } else { 30 CodecUtil.checkEOF(indexStream); 31 } 32 indexStream.close(); 33 indexStream = null; 34 35 // Open the data file and read metadata 36 //解析.fdt文件 37 fieldsStream = d.openInput(fieldsStreamFN, context); 38 if (version >= VERSION_CHECKSUM) { 39 if (maxPointer + CodecUtil.footerLength() != fieldsStream.length()) { 40 throw new CorruptIndexException("Invalid fieldsStream maxPointer (file truncated?): maxPointer=" + maxPointer + ", length=" + fieldsStream.length()); 41 } 42 } else { 43 maxPointer = fieldsStream.length(); 44 } 45 this.maxPointer = maxPointer; 46 final String codecNameDat = formatName + CODEC_SFX_DAT; 47 final int fieldsVersion = CodecUtil.checkHeader(fieldsStream, codecNameDat, VERSION_START, VERSION_CURRENT); 48 if (version != fieldsVersion) { 49 throw new CorruptIndexException("Version mismatch between stored fields index and data: " + version + " != " + fieldsVersion); 50 } 51 assert CodecUtil.headerLength(codecNameDat) == fieldsStream.getFilePointer(); 52 53 if (version >= VERSION_BIG_CHUNKS) { 54 chunkSize = fieldsStream.readVInt(); 55 } else { 56 chunkSize = -1; 57 } 58 packedIntsVersion = fieldsStream.readVInt(); 59 //开始解析chunks 60 decompressor = compressionMode.newDecompressor(); 61 this.bytes = new BytesRef(); 62 63 success = true; 64 } finally { 65 if (!success) { 66 IOUtils.closeWhileHandlingException(this, indexStream); 67 } 68 } 69 }
1.2 存储域索引文件(.fdx)
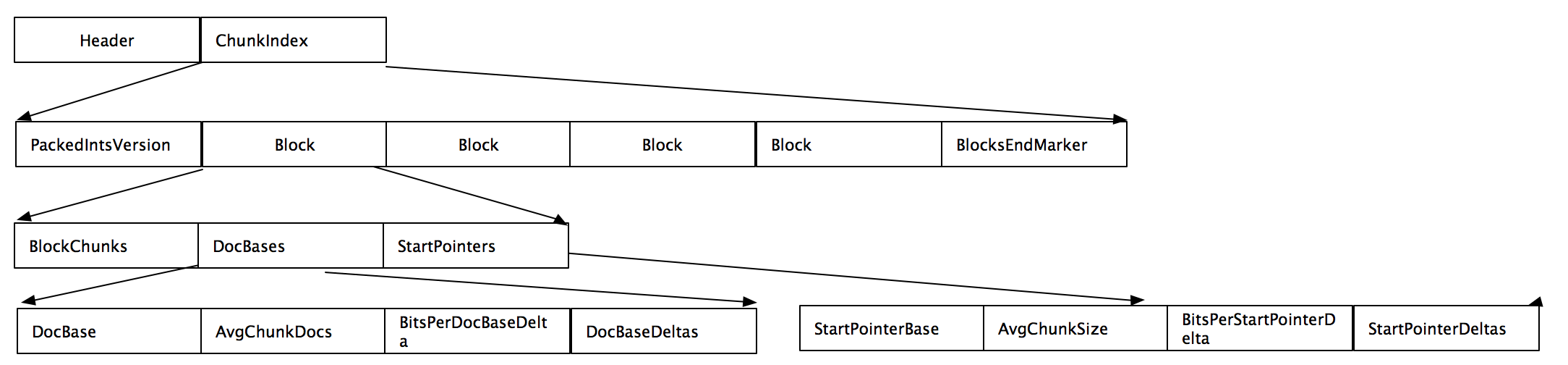
- BlockEndMarker:该值为0,表示后面没有接着Block。因为Block不是以0开始的
- 这里的一个Block包含了多个chunk,chunk对应了.fdt的chunk。所以可以通过.fdx快速的定位到.fdt的chunk。
- Block有三部分组成,BlockChunks表示该block内含有的chunk的数量,DocBases表示了该block的第一个document的ID并可以通过它获取任意一个该block内的chunk的docbase,同理StartPointer表示了该block内所有的chunk在.fdt文件里的位置信息。
- DocBases由DocBase, AvgChunkDocs, BitsPerDocBaseDelta, DocBaseDeltas组成。DocBase是Block内的第一个document ID,AvgChunkDocs是Chunk内document平均个数,BitsPerDocBaseDelta是与AvgChunkDocs的差值,DocBaseDeltas是BlockChunks大小的数组,表示平均的doc base的差值。
- StartPointers由StartPointerBase(block的第一个指针,它对应DocBase),AvgChunkSize(chunk的平均大小,对应AvgChunkDocs), BitPerStartPointerDelta以及StartPointerDeltas组成
- 第N个chunk的起始docbase可以用如下公式计算:
DocBase + AvgChunkDocs * n + DocBaseDeltas[n] - 第N个chunk的起始point可以用如下公式计算:StartPointerBase + AvgChunkSize * n + StartPointerDeltas[n]
- .fdx文件的解析主要用到了 CompressingStoredFieldsFormat,其中以CompressingStoredFieldsIndexReader为例,查看如何读取.fdx文件:
1 // It is the responsibility of the caller to close fieldsIndexIn after this constructor 2 // has been called 3 CompressingStoredFieldsIndexReader(IndexInput fieldsIndexIn, SegmentInfo si) throws IOException { 4 maxDoc = si.getDocCount(); 5 int[] docBases = new int[16]; 6 long[] startPointers = new long[16]; 7 int[] avgChunkDocs = new int[16]; 8 long[] avgChunkSizes = new long[16]; 9 PackedInts.Reader[] docBasesDeltas = new PackedInts.Reader[16]; 10 PackedInts.Reader[] startPointersDeltas = new PackedInts.Reader[16]; 11 //读取packedIntsVersion 12 final int packedIntsVersion = fieldsIndexIn.readVInt(); 13 14 int blockCount = 0; 15 //开始遍历并读取所有block 16 for (;;) { 17 //numChunks即当做BlockChunks,表示一个Block内Chunks的个数;当Block读取完时候会读取一个为0的值即为BlocksEndMarker, 18 //表示已读取完所有 block。 19 final int numChunks = fieldsIndexIn.readVInt(); 20 if (numChunks == 0) { 21 break; 22 } 23 //初始化时候,定义大小为16的数组docBases,startPointers,avgChunkDocs,avgChunkSizes表示16个模块。 24 //当Block大于16时候,会生成新的大小的数组,并将原数据复制过去。 25 if (blockCount == docBases.length) { 26 final int newSize = ArrayUtil.oversize(blockCount + 1, 8); 27 docBases = Arrays.copyOf(docBases, newSize); 28 startPointers = Arrays.copyOf(startPointers, newSize); 29 avgChunkDocs = Arrays.copyOf(avgChunkDocs, newSize); 30 avgChunkSizes = Arrays.copyOf(avgChunkSizes, newSize); 31 docBasesDeltas = Arrays.copyOf(docBasesDeltas, newSize); 32 startPointersDeltas = Arrays.copyOf(startPointersDeltas, newSize); 33 } 34 35 // doc bases 36 //读取block的docBase 37 docBases[blockCount] = fieldsIndexIn.readVInt(); 38 //读取avgChunkDocs,block中chunk内含有平均的document个数 39 avgChunkDocs[blockCount] = fieldsIndexIn.readVInt(); 40 //读取bitsPerDocBase,block中与avgChunkDocs的delta的位数,根据这个位数获取docBasesDeltas数组内具体delta 41 final int bitsPerDocBase = fieldsIndexIn.readVInt(); 42 if (bitsPerDocBase > 32) { 43 throw new CorruptIndexException("Corrupted bitsPerDocBase (resource=" + fieldsIndexIn + ")"); 44 } 45 //获取docBasesDeltas值,docBasesDeltas是一个numChunks大小的数组,存放每一个chunk起始的docbase与avgChunkDocs的差值 46 docBasesDeltas[blockCount] = PackedInts.getReaderNoHeader(fieldsIndexIn, PackedInts.Format.PACKED, packedIntsVersion, numChunks, bitsPerDocBase); 47 48 // start pointers 49 //读取block的startPointers 50 startPointers[blockCount] = fieldsIndexIn.readVLong(); 51 //读取startPointers,chunk的平均大小 52 avgChunkSizes[blockCount] = fieldsIndexIn.readVLong(); 53 //读取bitsPerStartPointer,block中与avgChunkSizes的delta的位数,根据这个位数获取startPointersDeltas数组内具体delta 54 final int bitsPerStartPointer = fieldsIndexIn.readVInt(); 55 if (bitsPerStartPointer > 64) { 56 throw new CorruptIndexException("Corrupted bitsPerStartPointer (resource=" + fieldsIndexIn + ")"); 57 } 58 //获取startPointersDeltas值,startPointersDeltas是一个numChunks大小的数组, 59 //存放每一个chunk起始的startPointer与avgChunkSizes的差值。 60 startPointersDeltas[blockCount] = PackedInts.getReaderNoHeader(fieldsIndexIn, PackedInts.Format.PACKED, packedIntsVersion, numChunks, bitsPerStartPointer); 61 62 //下一个block 63 ++blockCount; 64 } 65 //将遍历完的数据放入全局变量中 66 this.docBases = Arrays.copyOf(docBases, blockCount); 67 this.startPointers = Arrays.copyOf(startPointers, blockCount); 68 this.avgChunkDocs = Arrays.copyOf(avgChunkDocs, blockCount); 69 this.avgChunkSizes = Arrays.copyOf(avgChunkSizes, blockCount); 70 this.docBasesDeltas = Arrays.copyOf(docBasesDeltas, blockCount); 71 this.startPointersDeltas = Arrays.copyOf(startPointersDeltas, blockCount); 72 }
转载请注明地址http://www.cnblogs.com/rcfeng/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号