
kerberos
1第一章 Kerberos原理
1.1数据安全防护
用户在访问大数据集群数据时会有如下几个维度的安全防护方式来保证访问数据的安全:


- 边界安全(Perimeter Security):如设置防火墙、安全组控制端口。
- 认证(Authentication):大数据集群中组件服务开启身份认证功能,只有用户提供了合法的身份信息才有可能访问服务,它是后续授权的基础,没有身份认证的授权是有漏洞容易被冒充的。例如:任意连接到HDFS系统的用户都可以查看HDFS 中的数据,设置是可以操作HDFS中的数据,存在安全问题。
- 授权(Authorization):通过身份认证的用户并不能访问服务所有的资源,需要通过授权机制对用户访问服务中实际的资源进行控制。例如通过ranger对访问Hive的用户进行授权限制用户访问Hive表中的哪些数据。
- 审计(Audit):用户对服务资源的访问,需要利用审计日志进行监控/跟踪,便于问题/风险的排查。
- 加密(Encrypt):涉及数据传输加密/数据存储加密,防止数据被窃取/窃取后被破解等。
以上边界安全主要是针对企业大数据集群节点的防火墙和安全组端口控制,避免非法访问和操作集群数据,边界安全假设"坏人"在外面,这通常是一个非常糟糕的假设,大多数真正具有破坏性的计算机犯罪事件都是内部人员所为,所以对于可以访问集群节点的人员还需进一步认证;认证主要是针对通过边界安全维度后进行用户身份的确认,认证有很多形式,如服务组件自身提供了简单的用户名/密码认证方式、通过Kerberos认证服务对用户身份进行认证;为了更好细粒度控制通过认证用户访问的资源可以通过对用户授权方式来决定用户操作资源的权限,这就是授权;最终操作集群资源时可以对数据进行加密传输,所有操作都会通过审计日志进行记录,便于风险排查。
针对认证(Authorization)部分,目前大数据企业比较通用的是使用Kerberos协议,集群上启动的多个服务组件可以通过使用同一个第三方的Kerberos认证服务,对用户进行身份认证,例如大数据中HDFS默认安全认证的方式就采用的是Kerberos认证协议。
1.2什么是Kerberos
Kerberos 是一种网络身份验证协议,Kerberos协议通过使用密钥加密为Client/Server应用程序提供强大的身份验证。不同于其他网络安全协议的保证整个通信过程的传输安全,Kerberos侧重于通信前双方身份的认定工作,帮助客户端以及服务端验证是真正的自己并非他人,从而使得通信两端能够完全信任对方的身份,在一个不安全的网络中完成一次安全的身份认证继而进行安全的通信。
Kerberos由麻省理工学院(MIT)研发实现,官网地址为:https://web.mit.edu/kerberos/,Kerberos一词来源于古希腊神话中的 Cerberus —— 守护地狱之门的三头犬,下图是 Kerberos 的 LOGO:

在大数据开发中,很多大数据组件都支持Kerberos身份认证,例如:HDFS、Yarn、Hive、HBase、Spark、Kafka等。
1.3Kerberos认证原理
1.3.1加密
为了更好理解Kerberos认证原理,需要首先对加密和数字证书概念进行理解。互联网通信中 为了保证信息传输过程中 数据的机密性可以对数据进行加密,加密又分为对称加密和非对称加密。
- 对称加密 :
对称加密是指加密和解密使用相同的密钥。发送方使用该密钥将明文转换为密文,接收方使用相同的密钥将密文还原为明文。这种方法的优点是加密和解密速度快,适用于大量数据的加密,但缺点是需要保护好密钥,因为密钥一旦泄露,所有的加密信息都将暴露。在Kerberos中信息加密方式默认就是对称加密。
常见的对称加密算法有:DES、AES、3DES等。
- 非对称加密 :
非对称加密指的是:加密和解密使用不同的秘钥,一把作为公开的公钥,另一把作为私钥。 公钥加密的信息,只有私钥才能解密。私钥加密的信息,只有公钥才能解密。例如:发送方使用接收方的公钥加密明文,接收方使用自己的私钥解密密文。这种方法的优势就是即使密文和公钥被拦截,但是由于无法获取到私钥,也就无法破译到密文,但缺点是加密和解密速度相对较慢,不适用于大量数据的加密。
常见的非对称加密算法有:RSA、ECC等。
1.3.2Kerberos认证流程
整个Kerberos认证流程中涉及到三种角色:客户端Client、服务端Server、密钥分发中心KDC(Key Distribution Center)。
- 客户端 (Client):发送请求的一方。
- 服务端 (Server):接收请求的一方。
- 密钥分发中心 (Key Distribution Center , KDC):KDC是一个网络服务,提供ticket和临时会话密钥。由三个部分组成:认证服务器(Authentication Server,AS)、票证授予服务器(Ticket Grantion Server,TGS)、Kerberos数据库。
- 认证服务器 AS :认证服务器。负责认证客户端的身份并发放客户端访问TGS的TGT(Ticket Grantion Ticket,票据授予票据)。
- 票证授予服务器TGS:票据授予服务器。用来发放客户端访问服务端所需的服务授予票据(ticket)。
- Kerberos 数据库:客户端和服务端添加进keberos系统时有对应的密钥,数据负责存储这些密钥,并保存客户端和服务端的基本信息,如:用户名、用户IP地址、服务端IP、服务端名称等。
Kerberos认证流程图如下:


Kerberos认证过程总体流程为: 客户端向 KDC 请求要访问的目标服务器的服务授予票据( ticket ) , 然后客户端拿着从 KDC 获取的服务授予票据( ticket )访问服务端。 在以上这个过程中,需要保证客户端和服务端为正确的客户端和服务端,整个Keberos认证流程共有三次交互,如下:
- 客户端向KDC AS 获取 TGT
为了获取访问服务端的服务授予票据,客户端首先向KDC中AS获取TGT(票据授予票据),客户端需要使用TGT去KDC中的TGS(票据授予中心)获取访问服务端所需的Ticket(服务授予票据)才能进一步的与服务端通信。


客户端首先向KDC以明文方式发起请求,该请求中携带了访问KDC的用户名、主机IP、当前时间戳。由于客户端是第一次访问KDC,KDC中AS(认证服务器)接收请求后,去Kerberos数据库中验证是否存在访问的用户名,这个过程不会判断身份的可靠性。如果没有该用户名,认证失败;如果存在该用户名,AS会返回两部分信息给客户端:
- 第一部分信息为票据授予票据(TGT),TGT包含该客户端的名称、IP、当前时间戳、客户端即将访问TGS的名称、TGT的有效时间以及客户端与TGS之间通信的session_key(后续简称CT_SK),该key后续会用来对客户端向TGS发送的消息加密。
整个TGT使用TGS公钥加密,客户端是解密不了,后续客户端需要使用TGT去KDC中的TGS(票据授予中心)获取访问服务端所需的Ticket(服务授予票据)。
- 第二部分信息是使用客户端公钥加密的信息,该信息包含客户端和TGS通信的session_key(CT_SK)、客户端将要访问TGS的名称、TGT的有效时间以及当前时间戳。该部分内容由于是使用客户端密钥进行加密,所以客户端拿到该部分内容可以使用自己私钥进行解密,如果这时数据被劫持到一个假的客户端,由于真正客户端的私钥没有在网络中传输过,所以假的客户端无法对这部分信息进行解密,认证流程就会中断。只有正确的客户端才能对这部分信息进行解密,这个过程相当于是对客户端进行认证。
- 客户端向 KDC TGS 获取目标服务器的服务授予票据 ticket
客户端收到了来自KDC AS 返回的两部分信息后,对第二部分信息进行解密,可以获取与TGS通信的session_key(CT_SK)、将要访问TGS的名称、时间戳。首先会检查时间戳是否与自己返送数据的时间戳相差5分钟,如果大于5分钟则认为该AS是假的,认证中断。如果时延合理,客户端便向TGS发起请求去获取要访问目标服务端的服务授予票据ticket。


客户端向KDC TGS请求的信息包括三部分:
- 客户端将要访问的服务端名称
- 客户端从KDC AS中获取的第一部分信息,即:使用TGS密钥加密的TGT,通过TGT客户端可以从TGS中获取访问服务器的服务授予票据ticket。
- 使用CT_SK加密的信息,包括客户端名称、IP、时间戳。
当KDC中的TGS收到了客户端的请求后,首先去Kerberos数据库中查询是否存在该服务端,如果不存在认证失败。如果存在,TGS会使用自己的私钥对TGT进行解密,从而获取到经过KDC AS 认证过的客户端信息、CT_SK、时间戳信息,TGS会根据时间戳判断此次通信是否超出时间延迟,如果正常,TGS会对客户端发送过来的加密信息(使用CT_SK加密的信息)进行解密,获取客户端名称、IP信息,如果这部分信息与TGT中的客户端信息一致,那么就确认客户端的身份正确,否则中断认证。
KDC TGS通过确认是对的客户端后,会将如下两部分信息返回给客户端:
- 第一部分信息:客户端需要访问服务端需要的Server Ticket(服务授予票据,后续简称ST),该Ticket通过Server公钥进行加密,其中包括客户端名称、IP、需要访问的服务端的IP、ST有效时间、时间戳、用于客户端与服务端之间通信的session_key(后续简称CS_SK)。
- 第二部分信息:使用CT_SK加密的内容,这些加密内容包括:CS_SK、时间戳、ST有效时间,由于客户端与AS通信时,AS已经将CT_SK私钥通过客户端公钥加密交给了客户端,客户端缓存了CT_SK,并能对该部分内容进行解密。
- 客户端向服务端发送通信请求
当客户端收到来自KDC TGS的响应后,对第二部分内容进行解密,获取CS_SK、时间戳、ST有效时间,检查时间戳在时间延迟范围内,向服务端进行请求。
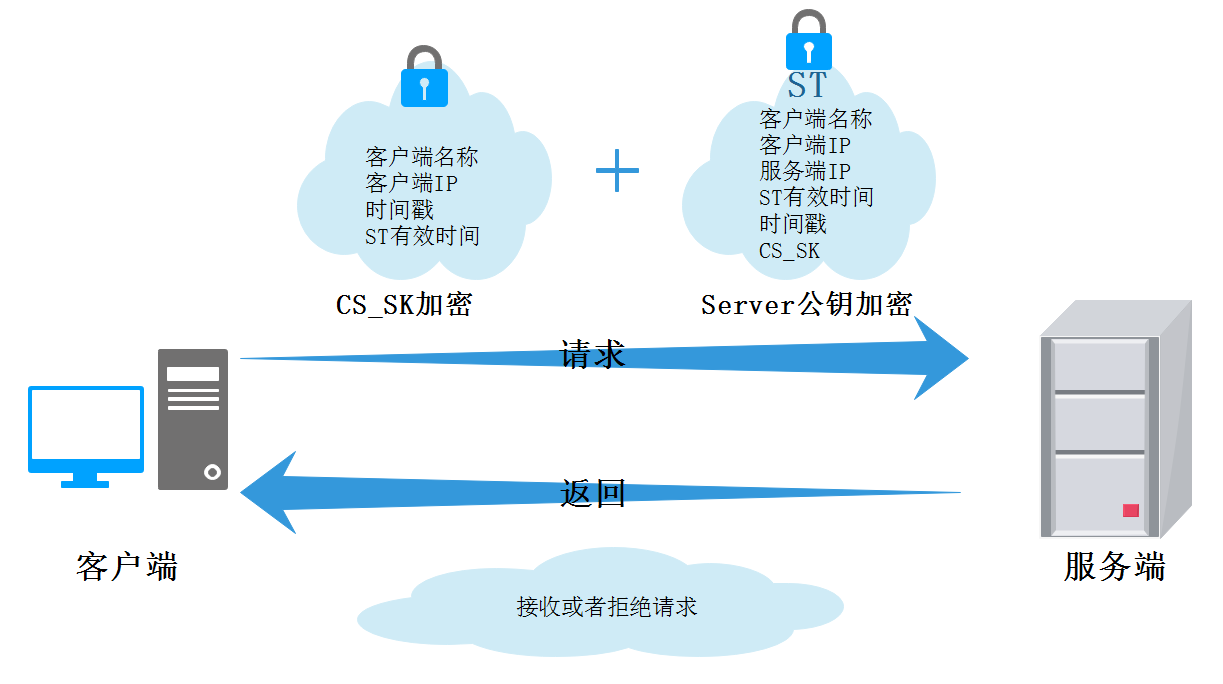

客户端会通过CS_SK将客户端名称、时间戳进行加密发送给服务端,此外还会将服务授予票据ST发送给服务端。
服务端收到来自客户端的请求,会使用自己私钥对ST进行解密获取信息(客户端名称、IP、需要访问的服务端的IP、ST有效时间、时间戳、用于客户端与服务端之间通信的CS_SK),将CS_SK取出对客户端发来的通过CS_SK加密的内容进行解密获取信息(客户端名称、时间戳),如果客户端信息一致说明该客户端是通过KDC认证的客户端,可以进一步提供服务,这时服务端返回通过CS_SK加密的接收请求信息给客户端,客户端接收到该请求后,使用缓存在客户端的CS_SK解密后,也确认了服务端身份,这个过程服务端还会通过数字证书证明自己身份。
以上3个步骤代表了整个kerberos认证的流程,通信的客户端和服务端都确认了双方的身份信息。这个过程使用了各方的密钥,且密钥的种类一直变化,为了防止网络拦截密钥,这些密钥都是临时生成的Session key,即它们只在一次Session会话中起作用,即使密钥被劫持,等到密钥被破解可能这次会话都早已结束,这为整个Kerberos认证过程保证了较高的安全性。
1.4Kerberos优势
Kerberos具备如下三点优势:
- 密码无需进行网络传输。基于 Ticket 实现身份认证,保障密钥安全性。
- 双向认证。整个认证过程中,不仅需要客户端进行认证,待访问的服务也需要进行身份认证。
- 高性能。密钥采用对称加密方式,相比于SSL的密钥操作快几个数量级。一旦Client获得用过访问某个Server的Ticket,该Server就能根据这个Ticket实现对Client的验证,而无须KDC的再次参与。
2第二章 Kerberos安装及使用
2.1Kerberos术语
通过Kerberos认证原理介绍,我们已经了解到Kerberos的一些术语,还有一些术语可以更好的帮助我们学习Kerberos,如下:
- realm :领域,身份验证管理域,领域确定了管理边界,所有主体均属于特定的Kerberos域。
- principal :主体,Principal主体用于标识身份,每个参与Kerberos认证协议的用户和服务都需要一个主体来唯一标识自己。Principal由三部分组成:名字(name)、实例(instance)、域(realm),例如一个标准的Kerberos用户/服务表示为:name/instance@REALM。
- name :表示用户名。
- instance :对name的进一步描述,例如name所在的主机名或name的类型等。可以省略,与第一部分使用"/"分割
- realm :就是前面说的领域,表示Kerberos在管理上的划分,在 KDC 中所负责的一个域数据库称作为 Realm。这个数据库中存放有该网络范围内的所有 Principal 和它们的密钥,Realm一般都是大写。
用户principal的命名类似:zhangsan/admin@EXAMPLE.COM,形式是用户名/角色/realm域。
服务principal的命名类似:ftp/site.example.com@EXAMPLE.COM,形式是服务名/地址/realm域。
- keytab :Kerberos认证有两种方式——通过密码或者密钥文件进行认证。这里说的keytab就是密钥文件,该文件包含Principal主体的用户名及密码,客户端可以通过Keytab密钥文件进行身份验证。
- kadmin :即Kerberos administration server,运行在主kerberos节点。负责存储KDC数据库,管理principal信息。
2.2Kerberos安装
Kerberos架构是客户端/服务端架构方式,安装kerberos涉及到3个安装包:krb5-server、krb5-workstation、krb5-libs:
- krb5-server:Kerberos服务端程序,KDC所在节点。
- krb5-workstation:包含基本的Kerberos程序,如:kinit、klist、kdestroy、kpasswd,所有kerberos节点需要部署。
- krb5-libs:包含Kerberos程序的各种支持类库,所有节点部署。
这里搭建Kerberos选择一台节点当做Kerberos服务端,其他节点为Kerberos客户端,节点分布如下:
| 节点IP | 节点名称 | Kerberos 服务端 | Kerberos 客户端 |
|---|---|---|---|
| 192.168.179.4 | node1 | ★ | ★ |
| 192.168.179.5 | node2 | ★ | |
| 192.168.179.6 | node3 | ★ | |
| 192.168.179.7 | node4 | ★ | |
| 192.168.179.8 | node5 | ★ |
Kerberos安装步骤如下:
- 安装 Kerberos 服务端
在node1节点上安装kerberos服务端:
[root@node1 ~]# yum install -y krb5-server
以上安装完成后会在KDC主机上生成配置文件:/var/kerberos/krb5kdc/kdc.conf。
- 安装 kerberos 客户端
在node1~node5节点安装Kerberos客户端:
[root@node1 ~]# yum install -y krb5-workstation krb5-libs
[root@node2 ~]# yum install -y krb5-workstation krb5-libs
[root@node3 ~]# yum install -y krb5-workstation krb5-libs
[root@node4 ~]# yum install -y krb5-workstation krb5-libs
[root@node5 ~]# yum install -y krb5-workstation krb5-libs
以上安装完成后会在客户端生成配置文件/etc/krb5.conf。
- 配置服务端 kdc.conf 文件
kdc.conf文件位于node1服务端/var/kerberos/krb5kdc/路径中,可以通过配置改文件来增加realm域信息。
#vim /var/kerberos/krb5kdc/kdc.conf
[kdcdefaults]
kdc_ports = 88
kdc_tcp_ports = 88
[realms]
EXAMPLE.COM = {
#master_key_type = aes256-cts
acl_file = /var/kerberos/krb5kdc/kadm5.acl
dict_file = /usr/share/dict/words
admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab
supported_enctypes = aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal camellia256-cts:normal camellia128-cts:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal }
该配置文件中的各个配置项可以参考:https://web.mit.edu/kerberos/krb5-1.20/doc/admin/conf_files/kdc_conf.html#kdc-conf-5,以上针对各个配置说明:
- kdc_ports:KDC服务监听的端口。
- EXAMPLE.COM:设定的realms,名字随意。Kerberos可以支持多个realms,一般为大写。
- master_key_type:指定Kerberos主密钥加密算法类型,默认使用aes256-cts。
- acl_file:ACL文件路径,Kerberos通过该文件来确定哪些Principal具有哪些权限。
- dict_file:存放一个由多行字符串构成的文本文件,该文件中的字符串禁止作为密码使用。
- admin_keytab:KDC进行校验的keytab,该keytab用于认证管理员的密钥。
- supported_enctypes:支持的加密算法类型。
以上该文件暂时不做修改。
- 所有客户端配置 krb5.conf
krb5.conf文件位于客户端/etc/目录下,下面在node1客户端配置/etc/krb5.conf文件,配置完成后分发到node2~node5所有的客户端。
#node1客户端配置 /etc/krb5.conf文件如下:
# Configuration snippets may be placed in this directory as well
includedir /etc/krb5.conf.d/
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
pkinit_anchors = FILE:/etc/pki/tls/certs/ca-bundle.crt
default_realm = EXAMPLE.COM
# default_ccache_name = KEYRING:persistent:%{uid}
[realms]
EXAMPLE.COM = {
kdc = node1
admin_server = node1
}
[domain_realm]
# .example.com = EXAMPLE.COM
# example.com = EXAMPLE.COM
关于该文件配置项的详细内容参考:https://web.mit.edu/kerberos/krb5-1.20/doc/admin/conf_files/krb5_conf.html#krb5-conf-5。该配置文件的解释如下:
- logging模块:配置默认即可,KDC和Kadmin服务的log文件路径。
- libdefaults模块:
- dns_lookup_realm:使用主机域名到kerberos domain的映射定位KDC。
- ticket_lifetime:ticket过期时间,超过这个时间ticket需要重新申请或renew。
- renew_lifetime:ticket可进行renew的时间限制。
- forwardable:如果配置为true,在KDC允许的情况下,初始ticket可以被转发。
- rdns:是否可使用逆向DNS。
- pkinit_anchors:签署KDC证书的根证书。
- default_realm:指定默认的realm,需要设置,否则后续Kerberos服务不能正常启动。
- default_ccache_name:默认凭据缓存的命名规则,这里注释掉,否则后续HDFS客户端不能认证操作HDFS。
- realms模块:
realms模块按照如下模板进行配置即可:
EXAMPLE.COM = {
kdc = kerberos.example.com
admin_server = kerberos.example.com
}
- kdc:KDC服务所在节点。
- admin_server:kadmin服务所在节点,即Kerberos administration server。
- domain_realm模块:
此模块配置了domain name 或者hostname同kerberos realm之间的映射关系。将以上配置好的文件,发送到node2~node5节点上:
[root@node1 ~]# scp /etc/krb5.conf node2:/etc/
[root@node1 ~]# scp /etc/krb5.conf node3:/etc/
[root@node1 ~]# scp /etc/krb5.conf node4:/etc/
[root@node1 ~]# scp /etc/krb5.conf node5:/etc/
- 服务端配置 kadm5.acl 文件
kadm5.acl位于服务端/var/kerberos/krb5kdc/kadm5.acl,该ACL文件用于控制kadmin数据库的访问权限,以及哪些Principal可以操作其他的Principal,配置如下:
*/admin@EXAMPLE.COM *
以上配置表示名称匹配*/admin@EXAMPLE.COM的Principal都认为是admin管理员角色,权限是*代表全部权限。可以根据自己配置情况修改对应的域,这里暂不做修改。
6.服务初始化Kadmin 数据库
初始化Kadmin数据库的命令格式为:
kdb5_util create -s -r [realm]
以上-s表示生成存储文件,-r指定realm name ,以上命令需要在服务端执行,执行后默认创建的数据库路径为:/var/kerberos/krb5kdc,如果需要重建数据库,将该目录下的principal相关的文件删除即可,请牢记数据库密码。
这里在node1节点上初始化Kadmin数据库,操作如下:
[root@node1 ~]# kdb5_util create -s -r EXAMPLE.COM
Loading random data
Initializing database '/var/kerberos/krb5kdc/principal' for realm 'EXAMPLE.COM',
master key name 'K/M@EXAMPLE.COM'
You will be prompted for the database Master Password.
It is important that you NOT FORGET this password.
Enter KDC database master key: 123456
Re-enter KDC database master key to verify:123456
当Kerberos database创建好了之后,在/var/kerberos/krb5kdc路径中可以看到生成的principal相关文件。
- 启动 Kerberos 服务并设置开机自启动
在服务端启动Kerberos服务。
#启动Kerberos服务命令,两个服务也可分开启动
[root@node1 ~]# systemctl start krb5kdc
[root@node1 ~]# systemctl start kadmin
#设置开机自启动
[root@node1 ~]# systemctl enable krb5kdc
[root@node1 ~]# systemctl enable kadmin
#查看两个服务启动状态
[root@node1 ~]# systemctl status krb5kdc kadmin
2.3Kerberos使用
2.3.1Kadmin 数据库操作
可以在客户端和服务端对Kadmin数据库进行操作,由于Kadmin数据库本身就在服务端,所以如果在服务端操作Kadmin数据库只需要通过输入"kadmin.local"命令即可,如果在客户端操作Kadmin数据库,可以直接输入"kadmin"命令,但需要先在客户端进行主体认证,才可以在客户端对数据库进行操作。
下面在服务端操作Kadmin数据库进行命令演示。在node1输入"kadmin.local"命令:
[root@node1 ~]# kadmin.local
Authenticating as principal root/admin@EXAMPLE.COM with password.
kadmin.local:
以上进入交互窗口,输入"?"可以获取所有命令和解释:
kadmin.local: ?
Available kadmin.local requests:
add_principal, addprinc, ank
Add principal
delete_principal, delprinc
Delete principal
modify_principal, modprinc
Modify principal
rename_principal, renprinc
Rename principal
change_password, cpw Change password
get_principal, getprinc Get principal
list_principals, listprincs, get_principals, getprincs
List principals
add_policy, addpol Add policy
modify_policy, modpol Modify policy
delete_policy, delpol Delete policy
get_policy, getpol Get policy
list_policies, listpols, get_policies, getpols
List policies
get_privs, getprivs Get privileges
ktadd, xst Add entry(s) to a keytab
ktremove, ktrem Remove entry(s) from a keytab
lock Lock database exclusively (use with extreme caution!)
unlock Release exclusive database lock
purgekeys Purge previously retained old keys from a principal
get_strings, getstrs Show string attributes on a principal
set_string, setstr Set a string attribute on a principal
del_string, delstr Delete a string attribute on a principal
list_requests, lr, ? List available requests.
quit, exit, q Exit program.
kadmin.local:
我们也可以直接在服务端执行:kadmin.local -q "命令",不进入交互窗口直接操作Kadmin数据库,下面介绍常见的操作命令。
2.3.1.1list princs
listprincs命令是列出所有的Principal主体
kadmin.local: listprincs
K/M@EXAMPLE.COM
kadmin/admin@EXAMPLE.COM
kadmin/changepw@EXAMPLE.COM
kadmin/node1@EXAMPLE.COM
kiprop/node1@EXAMPLE.COM
krbtgt/EXAMPLE.COM@EXAMPLE.COM
2.3.1.2addprinc
addprinc命令是添加一个principal。
kadmin.local: addprinc test/admin
WARNING: no policy specified for test/admin@EXAMPLE.COM; defaulting to no policy
Enter password for principal "test/admin@EXAMPLE.COM": 123456
Re-enter password for principal "test/admin@EXAMPLE.COM": 123456
Principal "test/admin@EXAMPLE.COM" created.
#再次查看principal
kadmin.local: listprincs
K/M@EXAMPLE.COM
kadmin/admin@EXAMPLE.COM
kadmin/changepw@EXAMPLE.COM
kadmin/node1@EXAMPLE.COM
kiprop/node1@EXAMPLE.COM
krbtgt/EXAMPLE.COM@EXAMPLE.COM
test/admin@EXAMPLE.COM
#再次添加principal,该principal没有指定对应的角色权限,也是可以的。
kadmin.local: addprinc test2
WARNING: no policy specified for test2@EXAMPLE.COM; defaulting to no policy
Enter password for principal "test2@EXAMPLE.COM": 123456
Re-enter password for principal "test2@EXAMPLE.COM": 123456
Principal "test2@EXAMPLE.COM" created.
#查看principal
kadmin.local: listprincs
K/M@EXAMPLE.COM
kadmin/admin@EXAMPLE.COM
kadmin/changepw@EXAMPLE.COM
kadmin/node1@EXAMPLE.COM
kiprop/node1@EXAMPLE.COM
krbtgt/EXAMPLE.COM@EXAMPLE.COM
test/admin@EXAMPLE.COM
test2@EXAMPLE.COM
注意:
- 以上创建的test/admin principal第二部分是admin,根据之前在kadm5.acl文件中指定的匹配规则,该principal就相当于是admin管理员用户。在创建Principal是也可以不指定第二部分,这种用户就是普通用户。
- 关于创建好的用户如何去认证,参考后续kinit命令。
2.3.1.3delprinc
delprinc可以删除principal
kadmin.local: delprinc test2
Are you sure you want to delete the principal "test2@EXAMPLE.COM"? (yes/no): yes
Principal "test2@EXAMPLE.COM" deleted.
Make sure that you have removed this principal from all ACLs before reusing.
kadmin.local: delprinc test/admin
Are you sure you want to delete the principal "test/admin@EXAMPLE.COM"? (yes/no): yes
Principal "test/admin@EXAMPLE.COM" deleted.
Make sure that you have removed this principal from all ACLs before reusing.
#再次查看principal,之前创建的principal已经被删除
kadmin.local: listprincs
K/M@EXAMPLE.COM
kadmin/admin@EXAMPLE.COM
kadmin/changepw@EXAMPLE.COM
kadmin/node1@EXAMPLE.COM
kiprop/node1@EXAMPLE.COM
krbtgt/EXAMPLE.COM@EXAMPLE.COM
2.3.1.4change_password
change_password命令可以修改principal密码。
#创建test/admin principal主体,指定密码为123123
kadmin.local: addprinc test/admin
WARNING: no policy specified for test/admin@EXAMPLE.COM; defaulting to no policy
Enter password for principal "test/admin@EXAMPLE.COM": 123123
Re-enter password for principal "test/admin@EXAMPLE.COM": 123123
Principal "test/admin@EXAMPLE.COM" created.
#修改test/admin principal主体密码为123456
kadmin.local: change_password test/admin
Enter password for principal "test/admin@EXAMPLE.COM": 123456
Re-enter password for principal "test/admin@EXAMPLE.COM": 123456
Password for "test/admin@EXAMPLE.COM" changed.
注意:对Principal主体修改密码后,需要使用kinit命令认证时需要使用新密码。
2.3.1.5ktadd
ktadd命令key生成一个keytab文件,或者将一个principal加入到keytab。Kerberos客户端的认证支持两种方式,一种是用户名和密码认证方式,适合交互式应用。另一种是可以使用keytab密钥文件认证,可以通过ktadd命令将对应的principal主体添加到keytab文件,这样客户端就可以拿着keytab文件进行认证。关于参看后文kinit命令。
#在node1上创建目录,用于存储keytab文件
[root@node1 ~]# mkdir /root/kerberos_keytab
#将test/admin@EXAMPLE.COM主体加入到keytab文件
kadmin.local: ktadd -norandkey -kt /root/kerberos_keytab/test.keytab test/admin@EXAMPLE.COM
Entry for principal test/admin@EXAMPLE.COM with kvno 2, encryption type aes256-cts-hmac-sha1-96 added to keytab WRFILE:/root/kerberos_keytab/test
.keytab.Entry for principal test/admin@EXAMPLE.COM with kvno 2, encryption type aes128-cts-hmac-sha1-96 added to keytab WRFILE:/root/kerberos_keytab/test
.keytab.Entry for principal test/admin@EXAMPLE.COM with kvno 2, encryption type des3-cbc-sha1 added to keytab WRFILE:/root/kerberos_keytab/test.keytab.
Entry for principal test/admin@EXAMPLE.COM with kvno 2, encryption type arcfour-hmac added to keytab WRFILE:/root/kerberos_keytab/test.keytab.
Entry for principal test/admin@EXAMPLE.COM with kvno 2, encryption type camellia256-cts-cmac added to keytab WRFILE:/root/kerberos_keytab/test.ke
ytab.Entry for principal test/admin@EXAMPLE.COM with kvno 2, encryption type camellia128-cts-cmac added to keytab WRFILE:/root/kerberos_keytab/test.ke
ytab.Entry for principal test/admin@EXAMPLE.COM with kvno 2, encryption type des-hmac-sha1 added to keytab WRFILE:/root/kerberos_keytab/test.keytab.
Entry for principal test/admin@EXAMPLE.COM with kvno 2, encryption type des-cbc-md5 added to keytab WRFILE:/root/kerberos_keytab/test.keytab.
针对以上"ktadd -norandkey -kt /root/kerberos_keytab/test.keytab test/admin@EXAMPLE.COM"命令解释如下:
- 命令中"-norandkey"表示不使用随机密码,如果不指定那么会对该主体随机生成密码,源密码不可用,建议指定,这样客户端使用该主体即可使用密码验证也可以使用keytab密钥文件验证。
- 命令执行后产生了8个entry,原因是在kdc.conf的supported_enctypes配置项指定了8种加密算法,因此这里会打印出8个entry。
- 关于生成keytab文件,如果指定路径下没有该文件,会生成一个新的keytbl文件,然后将指定principal添加到该keytab;如果有该keytab文件会直接追加写入。
- 关于如何使用keytab方式认证命令参考下文kinit命令。
我们也可以使用ktadd命令将多个principal加入到同一个keytab文件中,这样该keytab就可以用于认证多个用户,操作如下:
#创建新的principal主体demo/admin
kadmin.local: addprinc demo/admin
WARNING: no policy specified for demo/admin@EXAMPLE.COM; defaulting to no policy
Enter password for principal "demo/admin@EXAMPLE.COM": 123456
Re-enter password for principal "demo/admin@EXAMPLE.COM": 123456
Principal "demo/admin@EXAMPLE.COM" created.
#将demo/admin加入到/root/kerberos_keytab/test.keytab密钥中
kadmin.local: ktadd -norandkey -kt /root/kerberos_keytab/test.keytab demo/admin@EXAMPLE.COM
#可以退出kadmin.local数据库操作窗口,执行如下命令查看keytab 文件关联的principal
[root@node1 ~]# klist -kt /root/kerberos_keytab/test.keytab
Keytab name: FILE:/root/kerberos_keytab/test.keytab
KVNO Principal
---- --------------------------------------------------------------------------
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
1 demo/admin@EXAMPLE.COM
1 demo/admin@EXAMPLE.COM
1 demo/admin@EXAMPLE.COM
1 demo/admin@EXAMPLE.COM
1 demo/admin@EXAMPLE.COM
1 demo/admin@EXAMPLE.COM
1 demo/admin@EXAMPLE.COM
1 demo/admin@EXAMPLE.COM
2.3.1.6ktremove
keremove命令可以从keytab文件中删除关联的pricipal
针对keytab文件中关联的多个pricipal可以通过ktremove命令来删除pricipal主体与keytab密钥文件的关联。
[root@node1 ~]# kadmin.local
kadmin.local: ktremove -kt /root/kerberos_keytab/test.keytab demo/admin@EXAMPLE.COM
以上命令将demo/admin@EXAMPLE.COM主体与keytab文件删除了关联。再次查看keytab 文件关联的principal。
[root@node1 ~]# klist -kt /root/kerberos_keytab/test.keytab
Keytab name: FILE:/root/kerberos_keytab/test.keytab
KVNO Principal
---- --------------------------------------------------------------------------
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2 test/admin@EXAMPLE.COM
2.3.2Kerberos命令
2.3.2.1kinit
kinit命令可以对Principal主体进行认证,获取principal授予的票据并缓存。Kerberos客户端支持两种认证方式,一是使用Principal + Password,二是使用Principal + keytab,前者适合用户进行交互式应用,例如hadoop fs -ls 这种,后者适合服务,例如yarn的rm、nm等。principal + keytab就类似于ssh免密码登录,登录时不需要密码。
无论使用以上哪种认证方式需要在Kerberos数据库中创建对应Principal主体,下面在服务端创建主体test/test ,也可以不指定对应的角色,并且生成keytab文件。
#node1服务端创建test/test主体
[root@node1 ~]# kadmin.local -q "addprinc test/test"
Authenticating as principal root/admin@EXAMPLE.COM with password.
WARNING: no policy specified for test/test@EXAMPLE.COM; defaulting to no policy
Enter password for principal "test/test@EXAMPLE.COM": 123456
Re-enter password for principal "test/test@EXAMPLE.COM": 123456
Principal "test/test@EXAMPLE.COM" created.
#将主体添加到keytab文件中
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /root/kerberos_keytab/my.keytab test/test@EXAMPLE.COM"
- 使用 password 进行认证
在node1~node5任意客户端上使用kinit命令进行认证。
[root@node2 ~]# kinit test/test@EXAMPLE.COM
Password for test/test@EXAMPLE.COM: 123456
注意:可以使用kinit -h 查看kinit的使用参数。
- 使用 keytab 进行认证
在node1~node5任意客户端上准备keytab文件,然后通过kinit 命令指定keytab文件进行认证。
#将node1节点上生成的my.keytab文件分发到node2节点/root目录下
[root@node1 ~]# scp /root/kerberos_keytab/my.keytab node2:/root/
#在node2节点进行客户端认证
[root@node2 ~]# kinit test/test@EXAMPLE.COM -kt /root/my.keytab
注意:指定keytab文件时必须写成 -kt。
也可以在客户端节点上执行kadmin命令,需要使用具有admin权限的Principal主体,命令如下:
[root@node5 ~]# kadmin -p test/admin@EXAMPLE.COM -w 123456
Authenticating as principal test/admin@EXAMPLE.COM with password.
kadmin: listprincs
K/M@EXAMPLE.COM
demo/admin@EXAMPLE.COM
kadmin/admin@EXAMPLE.COM
kadmin/changepw@EXAMPLE.COM
kadmin/node1@EXAMPLE.COM
kiprop/node1@EXAMPLE.COM
krbtgt/EXAMPLE.COM@EXAMPLE.COM
test/admin@EXAMPLE.COM
test/test@EXAMPLE.COM
2.3.2.2klist
通过 klist命令可以查看当前凭据缓存内的票据Ticket。
[root@node2 ~]# klist
Ticket cache: KEYRING:persistent:0:0
Default principal: test/test@EXAMPLE.COM
Valid starting Expires Service principal
2023-05-10T15:03:37 2023-05-11T15:03:37 krbtgt/EXAMPLE.COM@EXAMPLE.COM
#如果在没有认证的客户端节点执行klist命令,查询不到缓存的Ticket
[root@node3 kerberos]# klist
klist: Credentials cache keyring 'persistent:0:0' not found
除之外,klist还可以列出keytab文件关联的Pricipal主体:
[root@node2 ~]# klist -kt /root/my.keytab
Keytab name: FILE:/root/my.keytab
KVNO Timestamp Principal
---- ------------------- ------------------------------------------------------
1 2023-05-10T14:58:23 test/test@EXAMPLE.COM
1 2023-05-10T14:58:23 test/test@EXAMPLE.COM
1 2023-05-10T14:58:23 test/test@EXAMPLE.COM
1 2023-05-10T14:58:23 test/test@EXAMPLE.COM
1 2023-05-10T14:58:23 test/test@EXAMPLE.COM
1 2023-05-10T14:58:23 test/test@EXAMPLE.COM
1 2023-05-10T14:58:23 test/test@EXAMPLE.COM
1 2023-05-10T14:58:23 test/test@EXAMPLE.COM
2.3.2.3kdestroy
kdestroy命令用来销毁当前认证缓存的票据,该命令不需要任何参数,可以指定kdestroy -A 删除所有用户的票据缓存,不指定-A 仅删除当前用户的票据缓存。
[root@node2 ~]# kdestroy
Other credential caches present, use -A to destroy all
3第三章 大数据技术组件搭建
这里使用5台节点组成大数据集群:node1~node5,所有技术组件搭建到该集群中,默认这些节点配置为4core+4G,每个节点都已经配置了IP、主机名称、关闭防火墙、关闭Selinux、配置阿里yum源、设置时间自动同步、所有节点配置安装jdk8、node2节点已经安装mysql5.7、节点之间root用户已经两两免密。节点信息如下:
| 节点IP | 节点名称 |
|---|---|
| 192.168.179.4 | node1 |
| 192.168.179.5 | node2 |
| 192.168.179.6 | node3 |
| 192.168.179.7 | node4 |
| 192.168.179.8 | node5 |
3.1安装Zookeeper
3.1.1节点划分
这里搭建zookeeper版本为3.6.3,搭建zookeeper对应的角色分布如下
| 节点IP | 节点名称 | Zookeeper |
|---|---|---|
| 192.168.179.4 | node1 | |
| 192.168.179.5 | node2 | |
| 192.168.179.6 | node3 | ★ |
| 192.168.179.7 | node4 | ★ |
| 192.168.179.8 | node5 | ★ |
3.1.2 安装Zookeeper
- 上传zookeeper 并解压 , 配置环境变量
将zookeeper安装包上传到node3节点/software目录下并解压:
[root@node3 software]# tar -zxvf ./apache-zookeeper-3.6.3-bin.tar.gz
在node3节点配置环境变量:
#进入vim /etc/profile,在最后加入:
export ZOOKEEPER_HOME=/software/apache-zookeeper-3.6.3-bin/
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#使配置生效
source /etc/profile
- 在node3 节点配置 zookeeper
进入"$ZOOKEEPER_HOME/conf"修改zoo_sample.cfg为zoo.cfg:
[root@node3 conf]# mv zoo_sample.cfg zoo.cfg
配置zoo.cfg中内容如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/data/zookeeper
clientPort=2181
server.1=node3:2888:3888
server.2=node4:2888:3888
server.3=node5:2888:3888
- 将配置好的zookeeper 发送到 node4,node5节点
[root@node3 software]# scp -r apache-zookeeper-3.6.3-bin node4:/software/
[root@node3 software]# scp -r apache-zookeeper-3.6.3-bin node5:/software/
- 各个节点上创建数据目录,并配置zookeeper环境变量
在node3,node4,node5各个节点上创建zoo.cfg中指定的数据目录"/opt/data/zookeeper"。
mkdir -p /opt/data/zookeeper
在node4,node5节点配置zookeeper环境变量
#进入vim /etc/profile,在最后加入:
export ZOOKEEPER_HOME=/software/apache-zookeeper-3.6.3-bin/
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#使配置生效
source /etc/profile
- 各个节点创建节点 ID
在node3,node4,node5各个节点路径"/opt/data/zookeeper"中添加myid文件分别写入1,2,3:
#在node3的/opt/data/zookeeper中创建myid文件写入1
#在node4的/opt/data/zookeeper中创建myid文件写入2
#在node5的/opt/data/zookeeper中创建myid文件写入3
- 各个节点启动zookeeper, 并检查进程状态
#各个节点启动zookeeper命令
zkServer.sh start
#检查各个节点zookeeper进程状态
zkServer.sh status
3.2安装HDFS
3.2.1节点划分
这里安装HDFS版本为3.3.4,搭建HDFS对应的角色在各个节点分布如下:
| 节点IP | 节点名称 | NN | DN | ZKFC | JN | RM | NM |
|---|---|---|---|---|---|---|---|
| 192.168.179.4 | node1 | ★ | ★ | ★ | |||
| 192.168.179.5 | node2 | ★ | ★ | ★ | |||
| 192.168.179.6 | node3 | ★ | ★ | ★ | |||
| 192.168.179.7 | node4 | ★ | ★ | ★ | |||
| 192.168.179.8 | node5 | ★ | ★ | ★ |
3.2.2 安装配置HDFS
- 各个节点安装HDFS HA自动切换必须的依赖
yum -y install psmisc
- 上传下载好的Hadoop 安装包到 node1节点上,并解压
[root@node1 software]# tar -zxvf ./hadoop-3.3.4.tar.gz
- 在node1 节点上配置 Hadoop的环境变量
[root@node1 software]# vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.3.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#使配置生效
source /etc/profile
- 配置$HADOOP_HOME/etc/hadoop 下的 hadoop-env.sh文件
#导入JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
- 配置$HADOOP_HOME/etc/hadoop 下的 hdfs-site.xml文件
<configuration>
<property>
<!--这里配置逻辑名称,可以随意写 -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- 禁用权限 -->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<!-- 配置namenode 的名称,多个用逗号分割 -->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<!-- namenode 共享的编辑目录, journalnode 所在服务器名称和监听的端口 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value>
</property>
<property>
<!-- namenode高可用代理类 -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 使用ssh 免密码自动登录 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- journalnode 存储数据的地方 -->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal/node/local/data</value>
</property>
<property>
<!-- 配置namenode自动切换 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
- 配置$HADOOP_HOME/ect/hadoop/core-site.xml
<configuration>
<property>
<!-- 为Hadoop 客户端配置默认的高可用路径 -->
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可
namenode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/name
datanode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/data
-->
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>ha.zookeeper.quorum</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
</configuration>
- 配置$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<!-- 配置yarn为高可用 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 集群的唯一标识 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster</value>
</property>
<property>
<!-- ResourceManager ID -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>yarn.resourcemanager.zk-address</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
<property>
<!-- 关闭虚拟内存检查 -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 启用节点的内容和CPU自动检测,最小内存为1G -->
<!--<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>-->
</configuration>
8. 配置$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 配置$HADOOP_HOME/etc/hadoop/workers文件
[root@node1 ~]# vim /software/hadoop-3.3.4/etc/hadoop/workers
node3
node4
node5
- 配置$HADOOP_HOME/sbin/start-dfs.sh 和 stop-dfs.sh 两个文件中顶部添加以下参数,防止启动错误
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
11. 配置 $HADOOP_HOME/sbin/start-yarn.sh 和 stop-yarn.sh 两个文件顶部添加以下参数,防止启动错误
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
- 将配置好的 Hadoop 安装包发送到其他 4个节点
[root@node1 ~]# scp -r /software/hadoop-3.3.4 node2:/software/
[root@node1 ~]# scp -r /software/hadoop-3.3.4 node3:/software/
[root@node1 ~]# scp -r /software/hadoop-3.3.4 node4:/software/
[root@node1 ~]# scp -r /software/hadoop-3.3.4 node5:/software/
也可以在对应其他节点上解压对应的安装包后,只发送对应的配置文件,这样速度较快。
- 在node2 、 node3 、 node4 、 node5 节点上配置 HADOOP_HOME
#分别在node2、node3、node4、node5节点上配置HADOOP_HOME
vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.3.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#最后记得Source
source /etc/profile
3.2.3初始化HDFS
#在node3,node4,node5节点上启动zookeeper
zkServer.sh start
#在node1上格式化zookeeper
[root@node1 ~]# hdfs zkfc -formatZK
#在每台journalnode中启动所有的journalnode,这里就是node3,node4,node5节点上启动
hdfs --daemon start journalnode
#在node1中格式化namenode
[root@node1 ~]# hdfs namenode -format
#在node1中启动namenode,以便同步其他namenode
[root@node1 ~]# hdfs --daemon start namenode
#高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行,这里就是在node2上执行):
[root@node2 software]# hdfs namenode -bootstrapStandby
3.2.4启动及停止
#node1上启动HDFS,启动Yarn
[root@node1 sbin]# start-dfs.sh
[root@node1 sbin]# start-yarn.sh
注意以上也可以使用start-all.sh命令启动Hadoop集群。
#停止集群
[root@node1 ~]# stop-dfs.sh
[root@node1 ~]# stop-yarn.sh
注意:以上也可以使用 stop-all.sh 停止集群。
3.2.5访问WebUI
#访问HDFS : http://node1:50070


3.3安装Hive
3.3.1节点划分
这里搭建Hive的版本为3.1.3,搭建Hive的节点划分如下:
| 节点IP | 节点名称 | Hive服务器 | Hive客户端 | MySQL |
|---|---|---|---|---|
| 192.168.179.4 | node1 | ★ | ||
| 192.168.179.5 | node2 | ★(已搭建) | ||
| 192.168.179.6 | node3 | ★ |
3.3.2安装配置Hive
- 将下载好的Hive 安装包上传到 node1 节点上 ,并修改名称
[root@node1 ~]# cd /software/
[root@node1 software]# tar -zxvf ./apache-hive-3.1.3-bin.tar.gz
[root@node1 software]# mv apache-hive-3.1.3-bin hive-3.1.3
- 将解压好的Hive 安装包发送到 node3节点上
[root@node1 software]# scp -r /software/hive-3.1.3/ node3:/software/
- 配置 node1 、 node3 两台节点的 Hive 环境变量
vim /etc/profile
export HIVE_HOME=/software/hive-3.1.3/
export PATH=$PATH:$HIVE_HOME/bin
#source 生效
source /etc/profile
- 在 node1 节点 $HIVE_HOME/conf 下创建 hive-site.xml 并配置
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node2:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
- 在node3 节点 $HIVE_HOME/conf/ 中创建 hive-site.xml并配置
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
</configuration>
- node1 、 node3 节点删除 $HIVE_HOME/lib 下" guava" 包,使用 Hadoop 下的包替换
#删除Hive lib目录下“guava-19.0.jar ”包
[root@node1 ~]# rm -rf /software/hive-3.1.3/lib/guava-19.0.jar
[root@node3 ~]# rm -rf /software/hive-3.1.3/lib/guava-19.0.jar
#将Hadoop lib下的“guava”包拷贝到Hive lib目录下
[root@node1 ~]# cp /software/hadoop-3.3.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.3/lib/
[root@node3 ~]# cp /software/hadoop-3.3.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.3/lib/
- 将"mysql-connector-java-5.1.47.jar" 驱动包上传到 $HIVE_HOME/lib目录下
这里node1,node3节点都需要传入,将mysql驱动包上传$HIVE_HOME/lib/目录下。
- 在node1 节点中初始化 Hive
#初始化hive,hive2.x版本后都需要初始化
[root@node1 ~]# schematool -dbType mysql -initSchema
3.3.3HiveServer2与Beeline
Hive Beeline 是Hive0.11版本引入的新命令行客户端,它是基于SQLLine Cli的JDBC客户端。Beeline工作模式有两种,即本地嵌入模式和远程模式。嵌入模式情况下,它返回一个嵌入式的Hive(类似于Hive CLI)。而远程模式则是通过Thrift协议与某个单独的HiveServer2进程进行连接通信。
想要通过Beeline写SQL查询Hive数据,必须配置HiveServer2服务,HiveServer2(HS2)是一种使客户端能够对Hive执行查询的服务。HiveServer2是已被废弃的HiveServer1(仅支持单客户端访问)的继承者。HiveServer2支持多客户端并发和身份验证。它旨在为JDBC和ODBC等开放API客户端提供更好的支持。
通过beeline和Hiverserver2连接操作Hive时,需要指定一个用户,这个用户可以随意指定,但是需要在HDFS中允许使用代理用户配置,需要在每台Hadoop 节点配置core-site.xml:
<!-- 配置代理访问用户 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
配置好完成之后,将以上文件分发到各个hadoo节点上,然后重新启动HDFS。
3.3.4Hive 操作
- 服务端和客户端 client 操作
在服务端和客户端操作Hive,操作Hive之前首先启动HDFS集群,命令为:start-all.sh,启动HDFS集群后再进行Hive以下操作:
#在node1中登录Hive ,创建表test
[root@node1 conf]# hive
hive> create table test (id int,name string,age int ) row format delimited fields terminated by '\t';
#向表test中插入数据
hive> insert into test values(1,"zs",18);
#在node1启动Hive metastore
[root@node1 hadoop]# hive --service metastore &
#在node3上登录Hive客户端查看表数据
[root@node3 lib]# hive
hive> select * from test;
OK
1 zs 18
- 本地嵌入模式使用 Beeline
首先在Hive服务端node1启动HiverServer2,然后在node1上可以直接登录beeline,操作如下:
#在node1 Hive服务端启动hiveserver2
[root@node1 ~]# hiveserver2
#在node1 Hive服务端进行操作
beeline
beeline> !connect jdbc:hive2://mynode1:10000
随意输入用户名和密码即可
另外也可以使用另外一种方式登录beeline:
beeline -u "jdbc:hive2://node1:10000"
- 远程模式使用 Beeline
在实际开发中建议远程模式使用beeline,这样并不是在Hive的服务端进行操作,比较安全。远程使用beeline就是直接找到Hive的客户端然后启动beeline,前提是需要在Hive的服务端启动Hiveserver2服务,这种情况下客户端的beeline是通过Thrift协议与服务端的HiveServer2进程进行连接通信。
#在node1节点上启动HiveServer2,如启动可以忽略
[root@node1 ~]# hiveserver2
#在node3客户端登录beeline,然后可以正常查询SQL语句
[root@node1 ~]# hiveserver2
beeline
beeline> !connect jdbc:hive2://mynode1:10000
3.4安装HBase
3.4.1节点划分
这里选择HBase版本为2.2.6,搭建HBase各个角色分布如下:
| 节点 IP | 节点名称 | HBase服务 |
|---|---|---|
| 192.168.179.6 | node3 | RegionServer |
| 192.168.179.7 | node4 | HMaster,RegionServer |
| 192.168.179.8 | node5 | RegionServer |
3.4.2安装配置HBase
- 将下载好的安装包发送到node4 节点上 , 并解压 , 配置环境变量
#将下载好的HBase安装包上传至node4节点/software下,并解压
[root@node4 software]# tar -zxvf ./hbase-2.2.6-bin.tar.gz
当前节点配置HBase环境变量
#配置HBase环境变量
[root@node4 software]# vim /etc/profile
export HBASE_HOME=/software/hbase-2.2.6/
export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效
[root@node4 software]# source /etc/profile
- 配置$HBASE_HOME/conf/hbase-env.sh
#配置HBase JDK
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
#配置 HBase不使用自带的zookeeper
export HBASE_MANAGES_ZK=false
#Hbase中的jar包和HDFS中的jar包有冲突,以下配置设置为true,启动hbase不加载HDFS jar包
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
- 配置$HBASE_HOME/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node3,node4,node5</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
- 配置$HBASE_HOME/conf/regionservers ,配置 RegionServer 节点
node3
node4
node5
- 配置backup-masters文件
手动创建$HBASE_HOME/conf/backup-masters文件,指定备用的HMaster,需要手动创建文件,这里写入node5,在HBase任意节点都可以启动HMaster,都可以成为备用Master ,可以使用命令:hbase-daemon.sh start master启动。
#创建 $HBASE_HOME/conf/backup-masters 文件,写入node5
[root@node4 conf]# vim backup-masters
node5
- 复制hdfs-site.xml 到 $HBASE_HOME/conf/ 下
[root@node4 ~]# cp /software/hadoop-3.3.4/etc/hadoop/hdfs-site.xml /software/hbase-2.2.6/conf/
- 将HBase 安装包发送到 node3 , node5 节点上,并在 node3 , node5 节点上配置 HBase 环境变量
[root@node4 ~]# scp -r /software/hbase-2.2.6 node3:/software/
[root@node4 ~]# scp -r /software/hbase-2.2.6 node5:/software/
注意:在node3、node5上配置HBase环境变量。
vim /etc/profile
export HBASE_HOME=/software/hbase-2.2.6/
export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效
source /etc/profile
- 重启Zookeeper 、重启 HDFS 及启动 HBase集群
#注意:一定要重启Zookeeper,重启HDFS,在node4节点上启动HBase集群
[root@node4 software]# start-hbase.sh
#访问WebUI,http://node4:16010。
停止集群:在任意一台节点上stop-hbase.sh
3.4.3HBase操作
在Hbase中创建表test,指定'cf1','cf2'两个列族,并向表test中插入几条数据:
#进入hbase
[root@node4 ~]# hbase shell
#创建表test
create 'test','cf1','cf2'
#查看创建的表
list
#向表test中插入数据
put 'test','row1','cf1:id','1'
put 'test','row1','cf1:name','zhangsan'
put 'test','row1','cf1:age',18
#查询表test中rowkey为row1的数据
get 'test','row1'
3.5安装Kafka
3.5.1节点划分
这里选择Kafka版本为3.3.1,对应的搭建节点如下:
| 节点IP | 节点名称 | Kafka服务 |
|---|---|---|
| 192.168.179.4 | node1 | kafka broker |
| 192.168.179.5 | node2 | kafka broker |
| 192.168.179.6 | node3 | kafka broker |
3.5.2安装配置Kafka
- 上传解压
[root@node1 software]# tar -zxvf ./kafka_2.12-3.3.1.tgz
- 配置Kafka环境变量
# 在node1节点上编辑profile文件,vim /etc/profile
export KAFKA_HOME=/software/kafka_2.12-3.3.1/
export PATH=$PATH:$KAFKA_HOME/bin
#使环境变量生效
source /etc/profile
- 配置Kafka
在node1节点上配置Kafka,进入$KAFKA_HOME/config中修改server.properties,修改内容如下:
broker.id=0 #注意:这里要唯一的Integer类型
log.dirs=/kafka-logs #真实数据存储的位置
zookeeper.connect=node3:2181,node4:2181,node5:2181 #zookeeper集群
- 将以上配置发送到node2 , node3节点上
[root@node1 software]# scp -r /software/kafka_2.12-3.3.1 node2:/software/
[root@node1 software]# scp -r /software/kafka_2.12-3.3.1 node3:/software/
发送完成后,在node2、node3节点上配置Kafka的环境变量。
- 修改node2,node3 节点上的 server.properties 文件
node2、node3节点修改$KAFKA_HOME/config/server.properties文件中的broker.id,node2中修改为1,node3节点修改为2。
- 创建Kafka启动脚本
在node1,node2,node3节点$KAFKA_HOME/bin路径中编写Kafka启动脚本"startKafka.sh",内容如下:
nohup /software/kafka_2.12-3.3.1/bin/kafka-server-start.sh /software/kafka_2.12-3.3.1/config/server.properties > /software/kafka_2.12-3.3.1/kafkalog.txt 2>&1 &
node1,node2,node3节点配置完成后修改"startKafka.sh"脚本执行权限:
chmod +x ./startKafka.sh
- 启动Kafka集群
在node1,node2,node3三台节点上分别执行startKafka.sh脚本,启动Kafka。
[root@node1 ~]# startKafka.sh
[root@node2 ~]# startKafka.sh
[root@node3 ~]# startKafka.sh
3.5.3Kafka命令操作
在Kafka 任意节点上操作如下命令测试Kafka。
#创建topic
kafka-topics.sh --create --bootstrap-server node1:9092,node2:9092,node3:9092 --topic testtopic --partitions 3 --replication-factor 3
#查看集群中的topic
kafka-topics.sh --list --bootstrap-server node1:9092,node2:9092,node3:9092
#console控制台向topic 中生产数据
kafka-console-producer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic testtopic
#console控制台消费topic中的数据
kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic testtopic
注意:以上创建好之后,可以向Kafka topic中写入数据测试Kafka是否正常。
#删除topic
kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --delete --topic testtopic
4第四章 Hadoop Kerberos安全配置
4.1安装libcrypto.so库
当使用Kerberos对Hadoop进行数据安全管理时,需要使用LinuxContainerExecutor,该类型Executor只支持在GNU / Linux操作系统上运行,并且可以提供更好的容器级别的安全性控制,例如通过在容器内运行应用程序的用户和组进行身份验证,此外,LinuxContainerExecutor还可以确保容器内的本地文件和目录仅能被应用程序所有者和NodeManager访问,这可以提高系统的安全性。
使用LinuxContainerExecutor时,会检测本地是否有libcrypto.so.1.1库,可以通过命令"find / -name "libcrypto.so.1.1""来确定该库是否存在,目前这里使用的Centos7系统中默认没有该库,这里需要在node1~node5各个节点上进行安装,安装步骤如下。
- 下载 openssl 源码包进行编译获取 libcrypto.so.1.1 库
在node1节点上下载openssl源码包,进行编译,步骤如下:
#下载openssl源码包,该源码也可以在资料中获取,名为:openssl-1.1.1k.tar.gz
[root@node1 ~]# cd /software && wget https://www.openssl.org/source/openssl-1.1.1k.tar.gz --no-check-certificate
#安装编译源码所需依赖
[root@node1 openssl-1.1.1k]# yum -y install gcc+ gcc-c++ zlib-devel
#解压并编译
[root@node1 software]# tar -zxvf openssl-1.1.1k.tar.gz
[root@node1 software]# cd openssl-1.1.1k
[root@node1 openssl-1.1.1k]# ./config --prefix=/usr/local/openssl --openssldir=/usr/local/openssl shared zlib
[root@node1 openssl-1.1.1k]# make
[root@node1 openssl-1.1.1k]# make install
经过以上步骤已经获取了libcrypto.so.1.1库,位于/software/openssl-1.1.1k目录下。
- 同步openssl 安装包到其他节点
这里同步编译好的openssl安装包到node2~node5节点:
[root@node1 ~]# cd /software/
[root@node1 software]# scp -r openssl-1.1.1k node2:/software/
[root@node1 software]# scp -r openssl-1.1.1k node3:/software/
[root@node1 software]# scp -r openssl-1.1.1k node4:/software/
[root@node1 software]# scp -r openssl-1.1.1k node5:/software/
- 各个节点创建libcrypto.so.1.1 软链接
#在node1~node5节点执行如下命令,创建软链接
ln /software/openssl-1.1.1k/libcrypto.so.1.1 /usr/lib64/libcrypto.so.1.1
4.2创建HDFS服务用户
企业Hadoop中一般由不同的用户来控制不同的服务,这些用户分为hdfs、yarn和mapred用户,多用户的目的是为了实现权限控制和管理,不同的用户只能访问其需要的资源和操作,从而提高整个Hadoop集群的安全性和稳定性。
官方对于以上三种用户、所属组及管理的服务如下:
| User:Group | Daemons |
|---|---|
| hdfs:hadoop | NameNode, Secondary NameNode, JournalNode, DataNode |
| yarn:hadoop | ResourceManager, NodeManager |
| mapred:hadoop | MapReduce JobHistory Server |
按照如下步骤在所有节点上创建以上用户组、用户及设置密码:
- 创建 hadoop 用户组
#node1~node5所有节点执行如下命令,创建hadoop用户组
groupadd hadoop
- 创建用户
#node1~node5所有节点执行如下命令,创建各用户并指定所属hadoop组
useradd hdfs -g hadoop
useradd yarn -g hadoop
useradd mapred -g hadoop
- 设置各个用户密码
#node1~node5所有节点上设置以上用户密码,这里设置为123456
passwd hdfs
passwd yarn
passwd mapred
4.3配置各服务用户两两节点免密
每个用户控制不同服务会涉及到各个节点之间通信,这时需要设置各个用户之间的免密通信,按照如下步骤实现。
- 设置 hdfs 用户两两节点之间免密
#所有节点切换成hdfs用户
su hdfs
cd ~
#node1~node5所有节点生成SSH密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
#node1~node5所有节点公钥复制到node1节点上,这个过程需要输入yes和密码
ssh-copy-id node1
#将node1 authorized_keys文件分发到node1~node5各节点,这个过程需要输入密码
[hdfs@node1 ~]$ cd ~/.ssh/
[hdfs@node1 .ssh]$ scp authorized_keys node2:`pwd`
[hdfs@node1 .ssh]$ scp authorized_keys node3:`pwd`
[hdfs@node1 .ssh]$ scp authorized_keys node4:`pwd`
[hdfs@node1 .ssh]$ scp authorized_keys node5:`pwd`
#两两节点进行ssh测试,这一步骤必须做,然后node1~node5节点退出当前hdfs用户
exit
- 设置 yarn 用户两两节点之间免密
#所有节点切换成yarn用户
su yarn
cd ~
#node1~node5所有节点生成SSH密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
#node1~node5所有节点公钥复制到node1节点上,这个过程需要输入yes和密码
ssh-copy-id node1
#将node1 authorized_keys文件分发到node1~node5各节点,这个过程需要输入密码
[yarn@node1 ~]$ cd ~/.ssh/
[yarn@node1 .ssh]$ scp authorized_keys node2:`pwd`
[yarn@node1 .ssh]$ scp authorized_keys node3:`pwd`
[yarn@node1 .ssh]$ scp authorized_keys node4:`pwd`
[yarn@node1 .ssh]$ scp authorized_keys node5:`pwd`
#两两节点进行ssh测试,这一步骤必须做,然后node1~node5节点退出当前yarn用户
exit
- 设置 mapred 用户两两节点之间免密
#所有节点切换成mapred用户
su mapred
cd ~
#node1~node5所有节点生成SSH密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
#node1~node5所有节点公钥复制到node1节点上,这个过程需要输入yes和密码
ssh-copy-id node1
#将node1 authorized_keys文件分发到node1~node5各节点,这个过程需要输入密码
[mapred@node1 ~]$ cd ~/.ssh/
[mapred@node1 .ssh]$ scp authorized_keys node2:`pwd`
[mapred@node1 .ssh]$ scp authorized_keys node3:`pwd`
[mapred@node1 .ssh]$ scp authorized_keys node4:`pwd`
[mapred@node1 .ssh]$ scp authorized_keys node5:`pwd`
#两两节点进行ssh测试,这一步骤必须做,然后node1~node5节点退出当前mapred用户
exit
4.4修改本地目录权限
Hadoop中不同的用户对不同目录拥有不同权限,下面是Hadoop官方给出的不同Hadoop相关目录对应的权限,这里需要按照该权限进行设置。
| Filesystem | Path | User:Group | Permissions |
|---|---|---|---|
| local | dfs.namenode.name.dir | hdfs:hadoop | drwx------ |
| local | dfs.datanode.data.dir | hdfs:hadoop | drwx------ |
| local | $HADOOP_LOG_DIR | hdfs:hadoop | drwxrwxr-x |
| local | $YARN_LOG_DIR | yarn:hadoop | drwxrwxr-x |
| local | yarn.nodemanager.local-dirs | yarn:hadoop | drwxr-xr-x |
| local | yarn.nodemanager.log-dirs | yarn:hadoop | drwxr-xr-x |
| local | dfs.journalnode.edits.dir | hdfs:hadoop | drwx------ |
对于以上目录的解释如下:
- dfs.namenode.name.dir
该配置项用于指定NameNode的数据存储目录,NameNode将所有的文件、目录和块信息存储在该目录下。该配置项配置在hdfs-site.xml中,默认值为file://${hadoop.tmp.dir}/dfs/name,${hadoop.tmp.dir}配置于core-site.xml中,默认为/opt/data/hadoop。这里我们需要修改/opt/data/hadoop/dfs/name路径的所有者和组为hdfs:hadoop,访问权限为700。
- dfs.datanode.data.dir
该配置项用于指定DataNode的数据存储目录,DataNode将块数据存储在该目录下。在hdfs-site.xml中配置,默认值为file://${hadoop.tmp.dir}/dfs/data,这里我们需要修改/opt/data/hadoop/dfs/data路径的所有者和组为hdfs:hadoop,访问权限为700。
- HADOOP_LOG_DIR与YARN_LOG_DIR
HADOOP_LOG_DIR为Hadoop各组件的日志目录,YARN_LOG_DIR为YARN各组件的日志目录,两者默认日志路径为HADOOP_HOME/logs。这里我们需要修改/software/hadoop-3.3.4/logs/路径的所有者和组为hdfs:hadoop,访问权限为775。
- yarn.nodemanager.local-dirs
该配置指定指定NodeManager的本地工作目录。在yarn-site.xml中配置,默认值为file://${hadoop.tmp.dir}/nm-local-dir。这里我们修改/opt/data/hadoop/nm-local-dir路径的所有者和组为yarn:hadoop,访问权限为755。
- yarn.nodemanager.log-dirs
该配置项指定NodeManager的日志目录。在yarn-site.xml中配置,默认值为 HADOOP_LOG_DIR/userlogs。这里我们修改/software/hadoop-3.3.4/logs/userlogs/路径的所有者和组为yarn:hadoop,访问权限为755。
- dfs.journalnode.edits.dir
该配置项指定JournalNode的edits存储目录。在hdfs-site.xml中配置,默认值为/tmp/hadoop/dfs/journalnode/。这里我们配置的路径为/opt/data/journal/node/local/data,所以这里修改该路径的所有者和组为hdfs:hadoop,访问权限为700。
下面在node1~node5各个节点上执行如下命令进行以上用户和组、权限设置:
#在node1~node2 NameNode节点执行
chown -R hdfs:hadoop /opt/data/hadoop/dfs/name
chmod 700 /opt/data/hadoop/dfs/name
#在node3~node5 DataNode节点执行
chown -R hdfs:hadoop /opt/data/hadoop/dfs/data
chmod 700 /opt/data/hadoop/dfs/data
#在node1~node5所有节点执行
chown hdfs:hadoop /software/hadoop-3.3.4/logs/
chmod 775 /software/hadoop-3.3.4/logs/
#在node3~node5 NodeManager、JournalNode节点执行
chown -R yarn:hadoop /opt/data/hadoop/nm-local-dir
chmod -R 755 /opt/data/hadoop/nm-local-dir
chown yarn:hadoop /software/hadoop-3.3.4/logs/userlogs/
chmod 755 /software/hadoop-3.3.4/logs/userlogs/
chown -R hdfs:hadoop /opt/data/journal/node/local/data
chmod 700 /opt/data/journal/node/local/data
4.5创建各服务Princial主体
Hadoop配置Kerberos安全认证后,为了让Hadoop集群中的服务能够相互通信并在集群中安全地进行数据交换,需要为每个服务实例配置其Kerberos主体,这样,各个服务实例就能够以其Kerberos主体身份进行身份验证,并获得访问Hadoop集群中的数据和资源所需的授权,Hadoop服务主体格式如下:ServiceName/HostName@REAL。
根据Hadoop集群各个节点服务分布,在Hadoop中创建的Kerbreos服务主体如下:
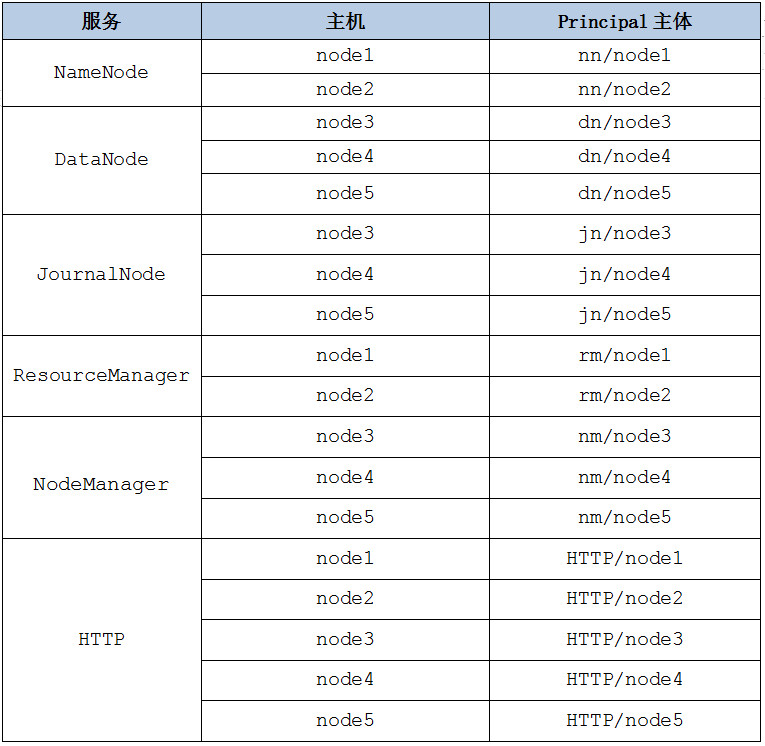
注意:以上HTTP服务主体用于Hadoop的Web控制台向Kerberos验证身份。
按照如下步骤在Kerberos服务端创建各个Hadoop服务主体并指定密码为123456。
#在Kerberos服务端node1节点执行如下命令
kadmin.local -q "addprinc -pw 123456 nn/node1"
kadmin.local -q "addprinc -pw 123456 nn/node2"
kadmin.local -q "addprinc -pw 123456 dn/node3"
kadmin.local -q "addprinc -pw 123456 dn/node4"
kadmin.local -q "addprinc -pw 123456 dn/node5"
kadmin.local -q "addprinc -pw 123456 jn/node3"
kadmin.local -q "addprinc -pw 123456 jn/node4"
kadmin.local -q "addprinc -pw 123456 jn/node5"
kadmin.local -q "addprinc -pw 123456 rm/node1"
kadmin.local -q "addprinc -pw 123456 rm/node2"
kadmin.local -q "addprinc -pw 123456 nm/node3"
kadmin.local -q "addprinc -pw 123456 nm/node4"
kadmin.local -q "addprinc -pw 123456 nm/node5"
kadmin.local -q "addprinc -pw 123456 HTTP/node1"
kadmin.local -q "addprinc -pw 123456 HTTP/node2"
kadmin.local -q "addprinc -pw 123456 HTTP/node3"
kadmin.local -q "addprinc -pw 123456 HTTP/node4"
kadmin.local -q "addprinc -pw 123456 HTTP/node5"
注意:以上命令也可以在客户端执行类似"kadmin -p test/admin -w 123456 -q "addprinc -pw 123456 xx/xx""这种命令来创建Hadoop各服务主体。
创建好Hadoop各服务主体后,可以将这些主体写入不同的Keytab密钥文件,然后将这些文件分发到Hadoop各个节点上,当Hadoop各服务之间通信认证时可以通过keytab密钥文件进行认证,按照如下步骤来完成keytab文件生成以及赋权:
- 创建存储 keytab 文件的路径
在node1~node5所有节点创建keytab文件路径,命令如下:
#node1~node5各节点执行如下命令
mkdir -p /home/keytabs
- 将 Hadoop 服务主体写入到 keytab 文件
在Kerberos服务端node1节点上,执行如下命令将Hadoop各服务主体写入到keytab文件。
#node1 节点执行如下命令
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/nn.service.keytab nn/node1@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/nn.service.keytab nn/node2@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/dn.service.keytab dn/node3@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/dn.service.keytab dn/node4@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/dn.service.keytab dn/node5@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/jn.service.keytab jn/node3@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/jn.service.keytab jn/node4@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/jn.service.keytab jn/node5@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/rm.service.keytab rm/node1@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/rm.service.keytab rm/node2@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/nm.service.keytab nm/node3@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/nm.service.keytab nm/node4@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/nm.service.keytab nm/node5@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/spnego.service.keytab HTTP/node1@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/spnego.service.keytab HTTP/node2@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/spnego.service.keytab HTTP/node3@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/spnego.service.keytab HTTP/node4@EXAMPLE.COM"
kadmin.local -q "ktadd -norandkey -kt /home/keytabs/spnego.service.keytab HTTP/node5@EXAMPLE.COM"
以上命令执行之后,可以在node1节点/home/keytabs路径下看到创建的各个keytab文件。
[root@node1 ~]# ls /home/keytabs/
dn.service.keytab nm.service.keytab rm.service.keytab
jn.service.keytab nn.service.keytab spnego.service.keytab
- 发送 keytab 文件到其他节点
将在node1 kerberos服务端生成的keytab文件发送到Hadoop各个节点。
#node1节点执行如下命令
[root@node1 ~]# scp -r /home/keytabs/* node2:/home/keytabs/
[root@node1 ~]# scp -r /home/keytabs/* node3:/home/keytabs/
[root@node1 ~]# scp -r /home/keytabs/* node4:/home/keytabs/
[root@node1 ~]# scp -r /home/keytabs/* node5:/home/keytabs/
- 修改keytab 文件权限
这里修改各个节点的keytab文件访问权限目的是为了保证hdfs、yarn、mapred各个用户能访问到这些keytab文件。
#node1~node5各节点执行如下命令
chown -R root:hadoop /home/keytabs
chmod 770 /home/keytabs/*
chmod 770 /home/keytabs/
4.6修改Hadoop配置文件
这里分别需要对Hadoop各个节点core-site.xml、hdfs-site.xml、yarn-site.xm配置kerberos安全认证。
4.6.1配置core-site.xml
在node1~node5各个节点上配置core-site.xml,追加如下配置:
<!-- 启用Kerberos安全认证 -->
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
<!-- 启用Hadoop集群授权管理 -->
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<!-- 外部系统用户身份映射到Hadoop用户的机制 -->
<property>
<name>hadoop.security.auth_to_local.mechanism</name>
<value>MIT</value>
</property>
<!-- Kerberos主体到Hadoop用户的具体映射规则 -->
<property>
<name>hadoop.security.auth_to_local</name>
<value>
RULE:[2:$1/$2@$0]([ndj]n\/.*@EXAMPLE\.COM)s/.*/hdfs/
RULE:[2:$1/$2@$0]([rn]m\/.*@EXAMPLE\.COM)s/.*/yarn/
RULE:[2:$1/$2@$0](jhs\/.*@EXAMPLE\.COM)s/.*/mapred/
DEFAULT
</value>
</property>
以上关于 "hadoop.security.auth_to_local"配置项中的value解释如下,规则 RULE:2:$1/$2@$0s/.*/hdfs/ 表示对于 Kerberos 主体中以 nn/、dn/、jn/ 开头的名称,在 EXAMPLE.COM 域中使用正则表达式 .* 进行匹配,将其映射为 Hadoop 中的 hdfs 用户名。其中,$0 表示 Kerberos 主体中的域名部分,$1 和 $2 表示其他两个部分。
4.6.2配置hdfs-site.xml
在node1~node5各个节点上配置core-site.xml,追加如下配置:
<!-- 开启访问DataNode数据块需Kerberos认证 -->
<property>
<name>dfs.block.access.token.enable</name>
<value>true</value>
</property>
<!-- NameNode服务的Kerberos主体 -->
<property>
<name>dfs.namenode.kerberos.principal</name>
<value>nn/_HOST@EXAMPLE.COM</value>
</property>
<!-- NameNode服务的keytab密钥文件路径 -->
<property>
<name>dfs.namenode.keytab.file</name>
<value>/home/keytabs/nn.service.keytab</value>
</property>
<!-- DataNode服务的Kerberos主体 -->
<property>
<name>dfs.datanode.kerberos.principal</name>
<value>dn/_HOST@EXAMPLE.COM</value>
</property>
<!-- DataNode服务的keytab密钥文件路径 -->
<property>
<name>dfs.datanode.keytab.file</name>
<value>/home/keytabs/dn.service.keytab</value>
</property>
<!-- JournalNode服务的Kerberos主体 -->
<property>
<name>dfs.journalnode.kerberos.principal</name>
<value>jn/_HOST@EXAMPLE.COM</value>
</property>
<!-- JournalNode服务的keytab密钥文件路径 -->
<property>
<name>dfs.journalnode.keytab.file</name>
<value>/home/keytabs/jn.service.keytab</value>
</property>
<!-- 配置HDFS支持HTTPS协议 -->
<property>
<name>dfs.http.policy</name>
<value>HTTPS_ONLY</value>
</property>
<!-- 配置DataNode数据传输保护策略为仅认证模式 -->
<property>
<name>dfs.data.transfer.protection</name>
<value>authentication</value>
</property>
<!-- HDFS WebUI服务认证主体 -->
<property>
<name>dfs.web.authentication.kerberos.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- HDFS WebUI服务keytab密钥文件路径 -->
<property>
<name>dfs.web.authentication.kerberos.keytab</name>
<value>/home/keytabs/spnego.service.keytab</value>
</property>
<!-- NameNode WebUI 服务认证主体 -->
<property>
<name>dfs.namenode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
<!-- JournalNode WebUI 服务认证主体 -->
<property>
<name>dfs.journalnode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@EXAMPLE.COM</value>
</property>
注意:以上配置中"_HOST" 将被替换为运行 Web 服务的实际主机名。
此外,还需要修改hdfs-site.xml中如下属性为hdfs用户下的rsa私钥文件,否则在节点之间HA切换时不能正常切换。
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_rsa</value>
</property>
4.6.3配置Yarn-site.xml
在node1~node5各个节点上配置yarn-site.xml,追加如下配置:
<!-- ResourceManager 服务主体 -->
<property>
<name>yarn.resourcemanager.principal</name>
<value>rm/_HOST@EXAMPLE.COM</value>
</property>
<!-- ResourceManager 服务keytab密钥文件 -->
<property>
<name>yarn.resourcemanager.keytab</name>
<value>/home/keytabs/rm.service.keytab</value>
</property>
<!-- NodeManager 服务主体-->
<property>
<name>yarn.nodemanager.principal</name>
<value>nm/_HOST@EXAMPLE.COM</value>
</property>
<!-- NodeManager 服务keytab密钥文件 -->
<property>
<name>yarn.nodemanager.keytab</name>
<value>/home/keytabs/nm.service.keytab</value>
</property>
4.7配置Hadoop Https访问
HTTP的全称是Hypertext Transfer Protocol Vertion (超文本传输协议),HTTPS的全称是Secure Hypertext Transfer Protocol(安全超文本传输协议),HTTPS基于HTTP开发,使用安全套接字层(SSL)进行信息交换,简单来说它是HTTP的安全版,HTTPS = HTTP+SSL。
SSL(Secure Sockets Layer)是一种加密通信协议,它使用公钥加密和私钥解密的方式来确保数据传输的安全性。Hadoop配置Kerberos对Hadoop访问进行认证时,官方建议对Hadoop采用HTTPS访问方式保证数据安全传输,防止在数据传输过程中被窃听、篡改或伪造等攻击,提高数据的保密性、完整性和可靠性。按照如下步骤对Hadoop设置HTTPS访问。
- 生成私钥和证书文件
在node1节点执行如下命令生成私钥和证书文件:
#执行如下命令需要输入密码,这里设置密码为123456
[root@node1 ~]# openssl req -new -x509 -keyout /root/hdfs_ca_key -out /root/hdfs_ca_cert -days 36500 -subj '/C=CN/ST=beijing/L=haidian/O=devA/OU=devB/CN=devC'
以上命令使用 OpenSSL 工具生成一个自签名的 X.509 证书,执行完成后,会在/root目录下生成私钥文件hdfs_ca_key和证书文件hdfs_ca_cert。
- 将证书文件和私钥文件发送到其他节点
这里将证书文件和私钥文件发送到node2~node5节点上,后续各节点需要基于两个文件生成SSL认证文件。
[root@node1 ~]# scp ./hdfs_ca_cert ./hdfs_ca_key node2:/root/
[root@node1 ~]# scp ./hdfs_ca_cert ./hdfs_ca_key node3:/root/
[root@node1 ~]# scp ./hdfs_ca_cert ./hdfs_ca_key node4:/root/
[root@node1 ~]# scp ./hdfs_ca_cert ./hdfs_ca_key node5:/root/
- 生成 keystore 文件
keystore文件存储了SSL握手所涉及的私钥以及证书链信息,在node1~node5各节点执行如下命令,各个节点对应--alise不同且CN不同, 这里的 CN 虽说是组织名随意取名,但是在后续配置中建议配置为各节点的 hostname ,这样不会出现验证出错。
[root@node1 ~]# keytool -keystore /root/keystore -alias node1 -genkey -keyalg RSA -dname "CN=node1, OU=dev, O=dev, L=dev, ST=dev, C=CN"
[root@node2 ~]# keytool -keystore /root/keystore -alias node2 -genkey -keyalg RSA -dname "CN=node2, OU=dev, O=dev, L=dev, ST=dev, C=CN"
[root@node3 ~]# keytool -keystore /root/keystore -alias node3 -genkey -keyalg RSA -dname "CN=node3, OU=dev, O=dev, L=dev, ST=dev, C=CN"
[root@node4 ~]# keytool -keystore /root/keystore -alias node4 -genkey -keyalg RSA -dname "CN=node4, OU=dev, O=dev, L=dev, ST=dev, C=CN"
[root@node5 ~]# keytool -keystore /root/keystore -alias node5 -genkey -keyalg RSA -dname "CN=node5, OU=dev, O=dev, L=dev, ST=dev, C=CN"
以上命令执行时需要密钥库口令,这里设置为123456,执行完成后会在/root目录下产生keystore文件。关于该命令每个选项和参数解释如下:
- keytool:Java密钥和证书管理工具的命令行实用程序。
- -keystore /home/keystore:指定密钥库的位置和名称,这里为"/home/keystore"。
- -alias jetty:指定别名,这里为各节点hostname,用于标识存储在密钥库中的密钥对。
- -genkey:指定将生成新密钥对的操作。
- -keyalg RSA:指定密钥算法,这里为RSA。
- -dname "CN=dev1, OU=dev2, O=dev3, L=dev4, ST=dev5, C=CN":指定用于生成证书请求的"主题可分辨名称",包含以下信息:
- CN(Common Name):指定通用名称,这里建议配置为各hostname。
- OU(Organizational Unit):指定组织单位。
- O(Organization):指定组织名称。
- L(Locality):指定所在城市或地点。
- ST(State or Province):指定所在省份或州。
- C(Country):指定所在国家或地区,这里为"CN"(中国)。
- 生成 truststore 文件
truststore文件存储了可信任的根证书,用于验证服务器证书链中的证书是否可信,在node1~node5各个节点执行如下命令生成truststore文件。
keytool -keystore /root/truststore -alias CARoot -import -file /root/hdfs_ca_cert
以上命令使用 Java 工具 keytool 将之前生成的自签名 CA 证书 hdfs_ca_cert 导入到指定的 truststore 文件中,并将其命名为 CARoot。命令执行后会在各个节点/root目录下生成truststore文件。
- 从 keystore 中导出 cert
在各个节点上执行命令,从对应的keystore文件中提取证书请求并保存在cert文件中。
#各节点-alias不同,需要输入口令,这里设置为123456
[root@node1 ~]# keytool -certreq -alias node1 -keystore /root/keystore -file /root/cert
[root@node2 ~]# keytool -certreq -alias node2 -keystore /root/keystore -file /root/cert
[root@node3 ~]# keytool -certreq -alias node3 -keystore /root/keystore -file /root/cert
[root@node4 ~]# keytool -certreq -alias node4 -keystore /root/keystore -file /root/cert
[root@node5 ~]# keytool -certreq -alias node5 -keystore /root/keystore -file /root/cert
注意:--alias 需要与各节点生成keystore指定的别名一致。命令执行后,在各个节点上会生成/root/cert文件。
- 生成自签名证书
这里使用最开始生成的hdfs_ca_cert证书文件和hdfs_ca_key密钥文件对cert进行签名,生成自签名证书。在node1~node5各节点执行如下命令,命令执行后会在/root下生成cert_signed文件。
#执行如下命令需要输入CA证书文件口令,默认123456
openssl x509 -req -CA /root/hdfs_ca_cert -CAkey /root/hdfs_ca_key -in /root/cert -out /root/cert_signed -days 36500 -CAcreateserial
- 将 CA 证书导入到 keystore
在node1~node5各个节点上执行如下命令,将之前生成的hdfs_ca_cert证书文件导入到keystore中。
#执行如下命令,需要输入keystore口令,默认123456
keytool -keystore /root/keystore -alias CARoot -import -file /root/hdfs_ca_cert
- 将自签名证书导入到 keystore
在node1~node5各个节点上执行如下命令,将生成的cert_signed自签名证书导入到keystore中。
#各个节点 alias不同。执行如下命令,需要输入keystore口令,默认123456
[root@node1 ~]# keytool -keystore /root/keystore -alias node1 -import -file /root/cert_signed
[root@node2 ~]# keytool -keystore /root/keystore -alias node2 -import -file /root/cert_signed
[root@node3 ~]# keytool -keystore /root/keystore -alias node3 -import -file /root/cert_signed
[root@node4 ~]# keytool -keystore /root/keystore -alias node4 -import -file /root/cert_signed
[root@node5 ~]# keytool -keystore /root/keystore -alias node5 -import -file /root/cert_signed
- 将 keystore 和 trustores 存入 /home 目录
将目前在/root目录下生成的keystore和trustores文件复制到/home目录下,并修改访问权限。
#在node1~node5所有节点执行如下命令
cp keystore truststore /home/
chown -R root:hadoop /home/keystore
chown -R root:hadoop /home/truststore
chmod 770 /home/keystore
chmod 770 /home/truststore
- 配置 ssl-server.xml 文件
ssl-server.xml位于HADOOP_HOME/etc/hadoop/目录下,包含了Hadoop服务器端(如NameNode和DataNode)用于配置SSL/TLS连接的参数。在node1~node5所有节点中都需要配置ssl-server.xml文件。
#node1~node5所有节点执行
cd /software/hadoop-3.3.4/etc/hadoop/
mv ssl-server.xml.example ssl-server.xml
#配置的ssl-server.xml文件内容如下:
<configuration>
<property>
<name>ssl.server.truststore.location</name>
<value>/home/truststore</value>
<description>Truststore to be used by NN and DN. Must be specified.
</description>
</property>
<property>
<name>ssl.server.truststore.password</name>
<value>123456</value>
<description>Optional. Default value is "".
</description>
</property>
<property>
<name>ssl.server.truststore.type</name>
<value>jks</value>
<description>Optional. The keystore file format, default value is "jks".
</description>
</property>
<property>
<name>ssl.server.truststore.reload.interval</name>
<value>10000</value>
<description>Truststore reload check interval, in milliseconds.
Default value is 10000 (10 seconds).
</description>
</property>
<property>
<name>ssl.server.keystore.location</name>
<value>/home/keystore</value>
<description>Keystore to be used by NN and DN. Must be specified.
</description>
</property>
<property>
<name>ssl.server.keystore.password</name>
<value>123456</value>
<description>Must be specified.
</description>
</property>
<property>
<name>ssl.server.keystore.keypassword</name>
<value>123456</value>
<description>Must be specified.
</description>
</property>
<property>
<name>ssl.server.keystore.type</name>
<value>jks</value>
<description>Optional. The keystore file format, default value is "jks".
</description>
</property>
<property>
<name>ssl.server.exclude.cipher.list</name>
<value>TLS_ECDHE_RSA_WITH_RC4_128_SHA,SSL_DHE_RSA_EXPORT_WITH_DES40_CBC_SHA,
SSL_RSA_WITH_DES_CBC_SHA,SSL_DHE_RSA_WITH_DES_CBC_SHA,
SSL_RSA_EXPORT_WITH_RC4_40_MD5,SSL_RSA_EXPORT_WITH_DES40_CBC_SHA,
SSL_RSA_WITH_RC4_128_MD5</value>
<description>Optional. The weak security cipher suites that you want excluded
from SSL communication.</description>
</property>
</configuration>
- 配置ssl-client.xml 文件
ssl-client.xml位于HADOOP_HOME/etc/hadoop/目录下,包含了Hadoop客户端端(如HDFS客户端和YARN客户端)用于配置SSL/TLS连接的参数。在node1~node5所有节点中都需要配置ssl-client.xml文件。
#node1~node5所有节点执行
cd /software/hadoop-3.3.4/etc/hadoop/
mv ssl-client.xml.example ssl-client.xml
#配置的ssl-client.xml文件内容如下:
<configuration>
<property>
<name>ssl.client.truststore.location</name>
<value>/home/truststore</value>
<description>Truststore to be used by clients like distcp. Must be
specified.
</description>
</property>
<property>
<name>ssl.client.truststore.password</name>
<value>123456</value>
<description>Optional. Default value is "".
</description>
</property>
<property>
<name>ssl.client.truststore.type</name>
<value>jks</value>
<description>Optional. The keystore file format, default value is "jks".
</description>
</property>
<property>
<name>ssl.client.truststore.reload.interval</name>
<value>10000</value>
<description>Truststore reload check interval, in milliseconds.
Default value is 10000 (10 seconds).
</description>
</property>
<property>
<name>ssl.client.keystore.location</name>
<value>/home/keystore</value>
<description>Keystore to be used by clients like distcp. Must be
specified.
</description>
</property>
<property>
<name>ssl.client.keystore.password</name>
<value>123456</value>
<description>Optional. Default value is "".
</description>
</property>
<property>
<name>ssl.client.keystore.keypassword</name>
<value>123456</value>
<description>Optional. Default value is "".
</description>
</property>
<property>
<name>ssl.client.keystore.type</name>
<value>jks</value>
<description>Optional. The keystore file format, default value is "jks".
</description>
</property>
</configuration>
注意:以上ssl-server.xml和ssl-client.xml也可以先在node1节点配置完成后,然后分发到node2~node5节点:
[root@node1 hadoop]# scp ./ssl-server.xml ./ssl-client.xml node2:`pwd`
[root@node1 hadoop]# scp ./ssl-server.xml ./ssl-client.xml node3:`pwd`
[root@node1 hadoop]# scp ./ssl-server.xml ./ssl-client.xml node4:`pwd`
[root@node1 hadoop]# scp ./ssl-server.xml ./ssl-client.xml node5:`pwd`
4.8Yarn配置LCE
LinuxContainerExecutor(LCE)是Hadoop用于管理容器的一种执行器,它可以创建、启动和停止应用程序容器,并且能够隔离和限制容器内的资源使用,例如内存、CPU、网络和磁盘等资源。在使用Kerberos进行身份验证和安全通信时,需要使用LCE作为容器的执行器。可以按照如下步骤进行配置。
- 修改 container-executor 所有者和权限
container-executor位于HADOOP_HOME/bin目录中,该文件是LinuxContainerExecutor的可执行脚本文件,该文件所有者和权限如下:
#node1~node5所有节点执行
chown root:hadoop /software/hadoop-3.3.4/bin/container-executor
chmod 6050 /software/hadoop-3.3.4/bin/container-executor
- 配置 container-executor.cfg 文件
container-executor.cfg文件位于HADOOP_HOME/etc/hadoop/中,该文件是Hadoop中LinuxContainerExecutor(LCE)使用的配置文件,它定义了LCE如何运行容器,以及如何设置容器的用户和组映射。
在node1~node5所有节点上修改HADOOP_HOME/etc/hadoop/container-executor.cfg文件配置,内容如下:
#在node1~node5所有节点配置container-executor.cfg
#vim /software/hadoop-3.3.4/etc/hadoop/container-executor.cfg
yarn.nodemanager.linux-container-executor.group=hadoop
banned.users=hdfs,yarn,mapred
min.user.id=1000
allowed.system.users=foo,bar
feature.tc.enabled=false
- 修改 container-executor.cfg 所有者和权限
container-executor.cfg文件所有者和权限设置如下:
#node1~node5所有节点执行
chown root:hadoop /software/hadoop-3.3.4/etc/hadoop/container-executor.cfg
chown root:hadoop /software/hadoop-3.3.4/etc/hadoop
chown root:hadoop /software/hadoop-3.3.4/etc
chown root:hadoop /software/hadoop-3.3.4
chown root:hadoop /software
chmod 400 /software/hadoop-3.3.4/etc/hadoop/container-executor.cfg
- 配置 yarn-site.xml
需要在hadoop各个节点上配置yarn-site.xml配置文件,指定使用LinuxContainerExecutor。这里在node1~node5各个节点上向yarn-site.xml追加如下内容。
#在node1~node5所有节点向yarn-site.xml中追加如下内容
#vim /software/hadoop-3.3.4/etc/hadoop/yarn-site.xml
<!-- 配置NodeManager使用LinuxContainerExecutor管理Container -->
<property>
<name>yarn.nodemanager.container-executor.class</name>
<value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor</value>
</property>
<!-- 配置NodeManager的启动用户的所属组 -->
<property>
<name>yarn.nodemanager.linux-container-executor.group</name>
<value>hadoop</value>
</property>
<!-- LinuxContainerExecutor脚本路径 -->
<property>
<name>yarn.nodemanager.linux-container-executor.path</name>
<value>/software/hadoop-3.3.4/bin/container-executor</value>
</property>
4.9启动安全认证的Hadoop集群
这里首先需要配置HADOOP_HOME/sbin/目录中的start-dfs.sh、stop-dfs.sh、start-yarn.sh、stop-yarn.sh启动脚本中不同服务对应用户信息。配置如下:
- 配置 dfs 启停脚本
在node1节点上配置start-dfs.sh && stop-dfs.sh,两文件中修改如下配置:
# 在两个文件中加入如下配置
HDFS_DATANODE_USER=hdfs
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=hdfs
HDFS_JOURNALNODE_USER=hdfs
HDFS_ZKFC_USER=hdfs
- 配置 yarn 启停脚本
在node1 节点上配置start-yarn.sh && stop-yarn.sh,两文件中修改如下配置:
#在两个文件中加入如下配置
YARN_RESOURCEMANAGER_USER=yarn
YARN_NODEMANAGER_USER=yarn
- 分发到所有 hadoop 节点
将以上配置文件分发到node2~node5所有节点上。
#node1节点执行,分发到其他节点
[root@node1 ~]# cd /software/hadoop-3.3.4/sbin/
[root@node1 sbin]# scp ./start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh node2:`pwd`
[root@node1 sbin]# scp ./start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh node3:`pwd`
[root@node1 sbin]# scp ./start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh node4:`pwd`
[root@node1 sbin]# scp ./start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh node5:`pwd`
以上配置完成后,在node1节点启动Kerberos认证的HDFS集群,命令如下:
#在node1节点执行如下命令启动Hadoop集群
[root@node1 ~]# start-dfs.sh
[root@node1 ~]# start-yarn.sh
注意启动HDFS后,由于开启的SSL配置,HDFS默认的WEBUI访问端口为9871。HDFS访问URL为https://node1:9871,Yarn访问URL为https://node1:8088。



4.10修改HDFS路径访问权限
Hadoop启动后,不同的用户对于HDFS中的目录访问权限不同,以下是官方建议的HDFS目录访问用户、组、权限。启动HDFS后按照如下权限进行设置。
| Filesystem | Path | User:Group | Permissions |
|---|---|---|---|
| hdfs | / | hdfs:hadoop | drwxr-xr-x |
| hdfs | /tmp | hdfs:hadoop | drwxrwxrwxt |
| hdfs | /user | hdfs:hadoop | drwxr-xr-x |
| hdfs | yarn.nodemanager.remote-app-log-dir | yarn:hadoop | drwxrwxrwxt |
| hdfs | mapreduce.jobhistory.intermediate-done-dir | mapred:hadoop | drwxrwxrwxt |
| hdfs | mapreduce.jobhistory.done-dir | mapred:hadoop | drwxr-x--- |
- yarn.nodemanager.remote-app-log-dir
该参数指定NodeManager在HDFS上存储应用程序日志的目录,在yarn-site.xml中配置,默认是/tmp/logs,目前在HDFS中没有该目录,需要先创建,然后进行用户及组、访问权限设置。
- mapreduce.jobhistory.intermediate-done-dir
该参数指定JobHistory Server在任务完成后将中间数据保存到的目录,在mapred-site.xml中配置,默认为/tmp/hadoop-yarn/staging/history/done_intermediate,目前在HDFS中没有该目录,需要先创建,然后进行用户及组、访问权限设置。
- mapreduce.jobhistory.done-dir
该参数指定JobHistory Server在任务完成后将最终结果保存到的目录,在mapred-site.xml中配置,默认为/tmp/hadoop-yarn/staging/history/done,该目录不存在,需要先创建,然后进行用户及组、访问权限设置。
下面对以上HDFS中的目录进行用户组和权限设置。
- 创建 hdfs Principal 用户主体
创建hdfs用户主体进行目录权限设置。
#在node1 kerberos 服务节点执行
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 hdfs"
#在node1~node5任意一节点进行认证hdfs用户主体,这里在node1节点认证
[root@node1 ~]# kinit hdfs
Password for hdfs@EXAMPLE.COM: 123456
#查看认证结果
[root@node1 ~]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: hdfs@EXAMPLE.COM
Valid starting Expires Service principal
2023-05-13T18:30:00 2023-05-14T18:30:00 krbtgt/EXAMPLE.COM@EXAMPLE.COM
- 登录 HDFS 创建缺失目录
#在node1登录hdfs创建目录
[root@node1 ~]# hdfs dfs -mkdir /tmp
[root@node1 ~]# hdfs dfs -mkdir /user
[root@node1 ~]# hdfs dfs -mkdir /tmp/logs
[root@node1 ~]# hdfs dfs -mkdir -p /tmp/hadoop-yarn/staging/history/done_intermediate
[root@node1 ~]# hdfs dfs -mkdir -p /tmp/hadoop-yarn/staging/history/done
- 设置对应目录用户、所属组及权限
#在node1登录hdfs,设置HDFS对应目录权限
[root@node1 ~]# hadoop fs -chown hdfs:hadoop / /tmp /user
[root@node1 ~]# hadoop fs -chmod 755 /
[root@node1 ~]# hadoop fs -chmod 777 /tmp
[root@node1 ~]# hadoop fs -chmod 755 /user
[root@node1 ~]# hadoop fs -chown yarn:hadoop /tmp/logs
[root@node1 ~]# hadoop fs -chmod 777 /tmp/logs
[root@node1 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/history/done_intermediate
[root@node1 ~]# hadoop fs -chmod 777 /tmp/hadoop-yarn/staging/history/done_intermediate
[root@node1 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/history/
[root@node1 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/
[root@node1 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/
[root@node1 ~]# hadoop fs -chmod 770 /tmp/hadoop-yarn/staging/history/
[root@node1 ~]# hadoop fs -chmod 770 /tmp/hadoop-yarn/staging/
[root@node1 ~]# hadoop fs -chmod 770 /tmp/hadoop-yarn/
[root@node1 ~]# hadoop fs -chown mapred:hadoop /tmp/hadoop-yarn/staging/history/done
[root@node1 ~]# hadoop fs -chmod 777 /tmp/hadoop-yarn/staging/history/done
5第五章 访问Kerberos安全认证Hadoop
5.1Shell访问HDFS
这里以普通用户访问Kerberos安全认证的HDFS为例来演示普通用户访问HDFS及提交MR任务。
- 创建 zhangsan 用户及设置组
在node1~node5所有节点创建zhangsan普通用户并设置密码,将zhangsan加入到hadoop组。
#node1~node5所有节点执行,设置用户密码为123456
useradd zhangsan -g hadoop
passwd zhangsan
目前登录zhangsan用户后,没有权限操作HDFS。
- 创建用户主体
在node1节点上创建执行如下命令,创建用户主体。
#node1 kerberos服务端执行
[root@node1 ~]# kadmin.local -q"addprinc -pw 123456 zhangsan"
- 操作 HDFS
可以在node1~node5任意节点认证zhangsan用户主体,这里选择在node5节点认证,并操作HDFS。
#在node1~node5任意节点认证zhangsan用户主体,这里选择在node5节点认证。
[root@node5 ~]# su zhangsan
[zhangsan@node5 ~]$
[zhangsan@node5 ~]# kinit zhangsan
Password for zhangsan@EXAMPLE.COM: 123456
#查看认证的用户主体
[zhangsan@node5 ~]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: zhangsan@EXAMPLE.COM
#在HDFS中创建目录
[zhangsan@node5 ~]# hdfs dfs -mkdir /input
#在node5节点准备a.txt文件,内容如下:
[zhangsan@node5 ~]# cat a.txt
aa
bb
cc
aa
#向HDFS中上传文件
[zhangsan@node5 ~]# hdfs dfs -put a.txt /input/
[zhangsan@node5 ~]# hdfs dfs -ls /input/
Found 1 items
-rw-r--r-- 3 zhangsan hadoop 12 2023-05-13 18:59 /input/a.txt
- 提交 MapReduce 任务
#在node5节点提交MR WordCount 程序
[zhangsan@node5 ~]# hadoop jar /software/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input/a.txt /output
#任务执行完成后,可以查看结果
[zhangsan@node5 ~]$ hdfs dfs -cat /output/part-r-00000
aa 2
bb 1
cc 1
也可以通过Yarn Webui查看提交的MR任务。


5.2Windows访问Kerberos认证HDFS
我们可以通过Window访问keberos安全认证的HDFS WebUI,如果Windows客户端没有进行kerberos主体认证会导致在HDFS WebUI中看不到HDFS目录,这时需要我们在Window客户端进行Kerberos主体认证,在Window中进行Kerberos认证时可以使用Kerberos官方提供的认证工具,该下载地址:http://web.mit.edu/kerberos/dist/


以上msi文件也可以在资料中获取,名为"kfw-4.1-amd64.msi",下载完成该keberos客户端后双击进行安装即可。
当Window kerberos客户端工具安装完成后,需要按照如下步骤进行配置才可以正确的进行Window 客户端kerberos主体认证。
- 配置 krb5.ini
当keberos客户端安装完成后自动会在C:\ProgramData\MIT\Kerberos5路径中创建krb5.ini配置文件,我们需要配置该文件指定Kerberos服务节点及域信息,配置如下,该文件配置可以参考Kerberos服务端/etc/krb5.conf文件。
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
default_realm = EXAMPLE.COM
[realms]
EXAMPLE.COM = {
kdc = node1
admin_server = node1
}
- 调整path 环境变量
Kerberos客户端工具安装完成后会自动在Window环境变量path中加入"C:\Program Files\MIT\Kerberos\bin",默认放在最后,当我们在window中进行Kerberos主体认证时需要输入kinit命令,该命令会和JDK中的kinit命令冲突,导致无法在CMD窗口内进行kinit认证,所以这里需要调整该条信息为path中的第一条,如下图示例:


- cmd 进行 Kerberos 主体认证
在window中打开cmd,进行kerberos主体认证,如下图:


经过以上认证,可以打开Kerberos客户端工具可以看到认证信息:


实际上我们也可以不在cmd中认证Kerberos主体,可以直接通过Kerberos客户端工具进行认证。操作如下:




- 配置浏览器访问 HDFS WebUI
通过浏览器访问Kerberos认证的HDFS时需要对浏览器进行一些设置以支持Kerberos,目前支持较好的浏览器只有火狐。下面在火狐中进行设置以访问HDFS WebUI。
在火狐浏览器中输入"about:config"进入高级设置:


搜索"network.negotiate-auth.trusted-uris"并设置为HDFS NameNode节点,多个节点之间使用逗号分割,如下:


搜索"network.auth.use-sspi"并设置为false,如下:


设置完成后重启火狐浏览器进行HDFS访问即可。
注意:目前在Hadoop3.3.x版本后,通过浏览器访问Kerberos认证的HDFS服务,会出现"Failed to obtain user group information: java.io.IOException: Security enabled but user not authenticated by filter"错误,如下:


该错误目前是一个bug,出现于Hadoop3.1.x版本后,详细信息参考:https://issues.apache.org/jira/browse/HDFS-16441
5.3代码访问Kerberos认证的HDFS
Hadoop通过Kerberos认证后,在本地IDEA中访问HDFS中的数据可以通过Keytab来进行认证,这里在本地Idea中操作HDFS以zhangsan用户为例,配置如下:
- 准备 krb5.conf 文件
将node1 kerberos服务端/etc/krb5.conf文件存放在IDEA项目中的resources资源目录中或者本地Window固定的某个目录中,用于编写代码时指定访问Kerberos的Realm。
- 生成用户keytab 文件
在kerberos服务端node1节点上,执行如下命令,对zhangsan用户主体生成keytab密钥文件。
#在node1 kerberos服务端执行
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /root/zhangsan.keytab zhangsan@EXAMPLE.COM"
以上命令执行之后,在/root目录下会生成zhangsan.keytab文件,将该文件复制到IDEA项目中的resources资源目录中或者本地window固定的某个目录中,该文件用于编写代码时认证kerberos。
- 准备访问 HDFS 需要的资源文件
将HDFS中的core-site.xml 、hdfs-site.xml 、yarn-site.xml文件上传到项目resources资源目录中。
- 编写代码操作 HDFS
编写Java代码操作Kerberos认证的HDFS集群:
/**
* 操作Kerberos认证的HDFS文件系统
*/
public class OperateAuthHDFS {
public static FileSystem fs = null;
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
final Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://mycluster");
System.setProperty("java.security.krb5.conf", "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\krb5.conf");
UserGroupInformation.loginUserFromKeytab("zhangsan", "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\zhangsan.keytab");
UserGroupInformation ugi = UserGroupInformation.getLoginUser();
fs = ugi.doAs(new PrivilegedExceptionAction<FileSystem>() {
@Override
public FileSystem run() throws Exception {
return FileSystem.get(conf);
}
});
//查看HDFS路径文件
listHDFSPathDir("/");
System.out.println("=====================================");
//创建目录
mkdirOnHDFS("/kerberos_test");
System.out.println("=====================================");
//向HDFS 中写入数据
writeFileToHDFS("D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\data\\test.txt","/kerberos_test/test.txt");
System.out.println("=====================================");
//读取HDFS中的数据
readFileFromHDFS("/kerberos_test/test.txt");
System.out.println("=====================================");
//删除HDFS中的目录或者文件
deleteFileOrDirFromHDFS("/kerberos_test");
System.out.println("=====================================");
//关闭fs对象
fs.close();
}
private static void listHDFSPathDir(String hdfsPath) throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path(hdfsPath));
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath());
}
}
private static void mkdirOnHDFS(String dirpath) throws IOException {
Path path = new Path(dirpath);
//判断目录是否存在
if(fs.exists(path)) {
System.out.println("目录" + dirpath + "已经存在");
return;
}
//创建HDFS目录
boolean result = fs.mkdirs(path);
if(result) {
System.out.println("创建目录" + dirpath + "成功");
} else {
System.out.println("创建目录" + dirpath + "失败");
}
}
private static void writeFileToHDFS(String localFilePath, String hdfsFilePath) throws IOException {
//判断HDFS文件是否存在,存在则删除
Path hdfsPath = new Path(hdfsFilePath);
if(fs.exists(hdfsPath)) {
fs.delete(hdfsPath, true);
}
//创建HDFS文件路径
Path path = new Path(hdfsFilePath);
FSDataOutputStream out = fs.create(path);
//读取本地文件写入HDFS路径中
FileReader fr = new FileReader(localFilePath);
BufferedReader br = new BufferedReader(fr);
String newLine = "";
while ((newLine = br.readLine()) != null) {
out.write(newLine.getBytes());
out.write("\n".getBytes());
}
//关闭流对象
out.close();
br.close();
fr.close();
System.out.println("本地文件 ./data/test.txt 写入了HDFS中的"+path.toString()+"文件中");
}
private static void readFileFromHDFS(String hdfsFilePath) throws IOException {
//读取HDFS文件
Path path= new Path(hdfsFilePath);
FSDataInputStream in = fs.open(path);
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String newLine = "";
while((newLine = br.readLine()) != null) {
System.out.println(newLine);
}
//关闭流对象
br.close();
in.close();
}
private static void deleteFileOrDirFromHDFS(String hdfsFileOrDirPath) throws IOException {
//判断HDFS目录或者文件是否存在
Path path = new Path(hdfsFileOrDirPath);
if(!fs.exists(path)) {
System.out.println("HDFS目录或者文件不存在");
return;
}
//第二个参数表示是否递归删除
boolean result = fs.delete(path, true);
if(result){
System.out.println("HDFS目录或者文件 "+path+" 删除成功");
} else {
System.out.println("HDFS目录或者文件 "+path+" 删除成功");
}
}
}
注意以上代码maven引入依赖如下:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
- Spark代码操作 HDFS
向HDFS中上传wc.txt文件,在node5节点中准备wc.txt文件,文件内容如下:
hello zs
hello ls
hello ww
上传操作如下:
[root@node5 ~]# su zhangsan
[zhangsan@node5 root]$ cd
[zhangsan@node5 ~]$ hdfs dfs -put ./wc.txt /
编写Spark代码操作Kerberos认证的HDFS集群:
/**
* Spark操作Kerberos认证的HDFS
*/
public class SparkOperateAuthHDFS {
public static void main(String[] args) throws IOException {
//进行kerberos认证
System.setProperty("java.security.krb5.conf", "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\krb5.conf");
String principal = "zhangsan@EXAMPLE.COM";
String keytabPath = "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\zhangsan.keytab";
UserGroupInformation.loginUserFromKeytab(principal, keytabPath);
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("SparkOperateAuthHDFS");
JavaSparkContext jsc = new JavaSparkContext(conf);
jsc.textFile("hdfs://mycluster/wc.txt").foreach(line -> System.out.println(line));
jsc.stop();
}
}
注意,以上代码maven引入依赖如下,需要提前在HDFS中上传wc.txt文件。
<!-- Spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.4.0</version>
</dependency>
- Flink 代码操作 HDFS
/**
* Flink 读取Kerberos认证的HDFS文件
*/
public class FlinkOperateAuthHDFS {
public static void main(String[] args) throws Exception {
//进行kerberos认证
System.setProperty("java.security.krb5.conf", "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\krb5.conf");
String principal = "zhangsan@EXAMPLE.COM";
String keytabPath = "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\zhangsan.keytab";
UserGroupInformation.loginUserFromKeytab(principal, keytabPath);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FileSource<String> fileSource = FileSource.forRecordStreamFormat(
new TextLineInputFormat(),
new Path("hdfs://mycluster/wc.txt")).build();
DataStreamSource<String> dataStream = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "file-source");
dataStream.print();
env.execute();
}
}
以上代码需要导入以下maven依赖:
<!-- Flink批和流开发依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.16.0</version>
</dependency>
<!-- DataStream files connector -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.16.0</version>
</dependency>
6第六章 Hive Kerberos安全配置及访问
Hive底层数据存储在HDFS中,HQL执行默认会转换成MR执行在Yarn中,当HDFS配置了Kerberos安全认证时,只对HDFS进行认证是不够的,因为Hive作为数据仓库基础架构也需要访问HDFS上的数据。因此,为了确保整个大数据环境的安全性,Hive也需要配置Kerberos安全认证,这样可以控制对Hive和底层HDFS数据的访问权限,防止未经授权的访问和操作,确保数据的安全性。
目前对HDFS进行了Kerberos安全认证后,在Hive 客户端 虽然进行了用户主体认证,但在操作Hive时也不能正常操作Hive,需要对Hive进行kerberos安全认证。
#切换zhangsan用户,查看kerberos认证主体,目前没有认证
[root@node3 ~]# su zhangsan
[zhangsan@node3 root]$ cd
[zhangsan@node3 ~]$ klist
klist: No credentials cache found (filename: /tmp/krb5cc_1003)
#进行zhangsan主体认证
[zhangsan@node3 root]$ kinit zhangsan
Password for zhangsan@EXAMPLE.COM: 123456
[zhangsan@node3 ~]$ klist
Ticket cache: FILE:/tmp/krb5cc_1003
Default principal: zhangsan@EXAMPLE.COM
#登录并操作Hive,需要先在node1 hive服务端启动metastore服务。
[zhangsan@node3 ~]$ hive
hive> create table test (id int,name string,age int ) row format delimited fields terminated by '\t';
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:Got exception: java.io.IOException Dest
Host:destPort node1:8020 , LocalHost:localPort node1/192.168.179.4:0. Failed on local exception: java.io.IOException: org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS])
6.1Hive 配置 Kerberos
Hive配置Kerberos的前提是Hadoop需要配置Kerberos,这里已经在Hadoop集群中配置了Kerberos。按照如下步骤进行Hive使用Kerberos配置即可。
- 创建 hive 用户并设置组
在Hadoop集群中操作不同的服务有不同的用户,这里使用hive用户操作hive。在node1~node5所有hadoop节点上创建hive用户(非hive服务端和客户端也需要创建),后续执行HQL时会转换成MR任务执行于各个NodeManager节点,所以这里在所有集群节点中创建hive用户并设置所属组为hadoop。
#node1~node5所有节点执行命令创建hive用户,设置密码为123456
useradd hive -g hadoop
passwd hive
注意:创建hive用户以后,最好重启下HDFS集群,否则后续使用hive用户执行SQL时没有操作目录的权限。
- 创建Hive 服务的 Princial 主体
在kerberos 服务端执行如下命令,创建Hive服务的kerberos Princial主体,然后将服务主体写入keytab文件。
#在kerberos 服务端node1节点执行如下命令
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 hive/node1"
#将hive服务主体写入keytab文件
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /home/keytabs/hive.service.keytab hive/node1@EXAMPLE.COM"
以上命令执行后,可以在node1节点的/home/keytabs目录下看到生成对应的hive.server.keytab文件。
- 分发 keytab 文件并修改所属用户和组
将生成的hive服务对应的keytab密钥文件发送到hive服务端和客户端,这里node1为hive服务端,只需要发送到hive客户端node3节点即可。
#发送keytab 到node3节点
[root@node1 ~]# scp /home/keytabs/hive.service.keytab node3:/home/keytabs/
#在node1、node3两个节点修改keytab所属用户和组
chown root:hadoop /home/keytabs/hive.service.keytab
chmod 770 /home/keytabs/hive.service.keytab
- 修改 hive-site.xml 配置文件
在hive服务端和客户端配置hive-site.xml,向该配置中追加如下配置:
<!-- hiveserver2 支持kerberos认证 -->
<property>
<name>hive.server2.authentication</name>
<value>KERBEROS</value>
</property>
<!-- hiveserver2 kerberos主体 -->
<property>
<name>hive.server2.authentication.kerberos.principal</name>
<value>hive/node1@EXAMPLE.COM</value>
</property>
<!-- hiveserver2 keytab密钥文件路径 -->
<property>
<name>hive.server2.authentication.kerberos.keytab</name>
<value>/home/keytabs/hive.service.keytab</value>
</property>
<!-- hivemetastore 开启kerberos认证 -->
<property>
<name>hive.metastore.sasl.enabled</name>
<value>true</value>
</property>
<!-- metastore kerberos主体 -->
<property>
<name>hive.metastore.kerberos.principal</name>
<value>hive/node1@EXAMPLE.COM</value>
</property>
<!-- metastore keytab密钥文件路径 -->
<property>
<name>hive.metastore.kerberos.keytab.file</name>
<value>/home/keytabs/hive.service.keytab</value>
</property>
- 修改 Hadoop core-site.xml
修改core-site.xml中相关代理配置为hive代理用户,node1~node5节点core-site.xml中修改如下配置项:
<!-- 允许hive用户在任意主机节点代理任意用户和任意组 -->
<property>
<name>hadoop.proxyuser.hive.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hive.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hive.groups</name>
<value>*</value>
</property>
以上配置分发到Hadoop各个集群节点后, 需要重新启动HDFS 。
- 准备core-site.xml 和 hdfs-site.xml
将HDFS中配置的core-site.xml 和 hdfs-site.xml 发送到所有hive节点的HIVE_HOME/conf目录中。
6.2Hive Cli使用Kerberos
使用Hive Client操作Kerberos需要首先启动HDFS,然后在Hive服务端启动Hive Metastore,操作如下:
#启动zookeeper及HDFS
[root@node3 ~]# zkServer.sh start
[root@node4 ~]# zkServer.sh start
[root@node5 ~]# zkServer.sh start
[root@node1 ~]# start-all.sh
#在Hive服务端node1节点启动Hive Metastore,这里可以切换成Hive用户,也可以不切换
[root@node1 ~]# su hive
[hive@node1 ~]$ hive --service metastore &
在Hive客户端node3节点上登录hive客户端:
#需要切换用户为hive,其他用户没有操作hql底层转换成mr操作的目录权限
[root@node3 ~]# su hive
[hive@node3 root]$ cd
#进行节点认证kerberos
[hive@node3 ~]$ kinit hive/node1
Password for hive/node1@EXAMPLE.COM:123456
#登录hive,建表、插入数据及查询
[hive@node3 ~]$ hive
hive> create table person (id int,name string,age int ) row format delimited fields terminated by '\t';
OK
Time taken: 0.236 seconds
hive> insert into person values (1,'zs',18);
...
hive> select * from person;
OK
1 zs 18
#在node3节点准备如下文件及数据
[hive@node3 ~]$ cat /home/hive/person.txt
2 ls 19
3 ww 20
#在hive客户端将以上文件数据加载到hive person表中,操作如下
hive> load data local inpath '/home/hive/person.txt' into table person;
hive> select * from person;
OK
1 zs 18
2 ls 19
3 ww 20
6.3Hive beeline使用Kerberos
除了在hive客户端操作Hive外,还可以通过beeline方式操作Hive,具体步骤如下:
- 在 Hive 服务端启动 hiveserver2
#启动hiveserver2
[hive@node1 root]$ hiveserver2
- 在 Hive 客户端执行 beeline 登录 hive
#在hive 客户端通过beeline登录hive
[hive@node3 ~]$ beeline
beeline> !connect jdbc:hive2://node1:10000/default;principal=hive/node1@EXAMPLE.COM
0: jdbc:hive2://node1:10000/default> select * from person;
+------------+--------------+-------------+
| person.id | person.name | person.age |
+------------+--------------+-------------+
| 1 | zs | 18 |
| 2 | ls | 19 |
| 3 | ww | 20 |
+------------+--------------+-------------+
#也可以通过以下方式通过beeline直接操作hive
[hive@node3 ~]$ beeline -u "jdbc:hive2://node1:10000/default;principal=hive/node1@EXAMPLE.COM"
注意:无论使用哪种方式通过beeline连接hive,针对kerberos认证的hive都需要指定principal参数。
6.4JDBC访问Kerberos认证Hive
在IDEA中使用JDBC方式读取Kerberos认证Hive时需要指定krb5.conf文件、Principal主体、keytab密钥文件,然后在代码中进行设置即可JDBC方式访问Kerberos认证的Hive。具体操作步骤如下:
- 准备 krb5.conf 及 keytab 文件
在node1 kerberos服务端将/etc/krb5.conf文件放在window固定路径中,同时将hive主体对应的keytab密钥文件放在windows固定路径中。
- 启动 HiveServer2
需要在Hive服务端启动HiveServer2服务:
#在Hive服务端node1节点执行如下命令
[root@node1 ~]# su hive
[hive@node1 root]$ hiveserver2
- 编写JDBC 访问 Hive 代码
/**
* 通过JDBC方式读取Kerberos认证Hive的数据
*/
public class JDBCReadAuthHive {
// Kerberos主体
static final String principal = "hive/node1@EXAMPLE.COM";
// Kerberos配置文件路径
static final String krb5FilePath = "D:\\idea_space\\KerberosAuth\\KerberosAuthHive\\src\\main\\resources\\krb5.conf";
// Keytab文件路径
static final String keytabFilePath = "D:\\idea_space\\KerberosAuth\\KerberosAuthHive\\src\\main\\resources\\hive.service.keytab";
public static void main(String[] args) throws SQLException, ClassNotFoundException, IOException {
// 1.加载Kerberos配置文件
System.setProperty("java.security.krb5.conf", krb5FilePath);
// 2.设置Kerberos认证
Configuration configuration = new Configuration();
configuration.set("hadoop.security.authentication", "kerberos");
UserGroupInformation.setConfiguration(configuration);
UserGroupInformation.loginUserFromKeytab(principal, keytabFilePath);
// 3.JDBC连接字符串
String jdbcURL = "jdbc:hive2://node1:10000/default;principal=hive/node1@EXAMPLE.COM";
Class.forName("org.apache.hive.jdbc.HiveDriver");
try {
// 4.创建Hive连接
Connection connection = DriverManager.getConnection(jdbcURL, "", "");
// 5.执行Hive查询
Statement statement = connection.createStatement();
ResultSet rs = statement.executeQuery("SELECT id,name,age FROM person");
// 6.处理查询结果
while (rs.next()) {
System.out.println(rs.getInt(1) + "," +
rs.getString(2)+ "," +
rs.getInt(3)) ;
}
// 7.关闭连接
rs.close();
statement.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
以上代码需要在项目maven pom.xml文件中加入如下依赖:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.3</version>
</dependency>
以上代码运行结果如下:
1,zs,18
2,ls,19
3,ww,20
6.5Spark访问Kerberos认证Hive
这里是通过SparkSQL来读取Kerberos认证Hive中的数据,按照如下步骤配置即可。
- 准备 krb5.conf 及 keytab 文件
在node1 kerberos服务端将/etc/krb5.conf文件放在window固定路径中,同时将hive主体对应的keytab密钥文件放在windows固定路径中。这里项目中已经有了,可以忽略。
- 准备访问 Hive 需要的资源文件
将HDFS中的core-site.xml 、hdfs-site.xml 、yarn-site.xml文件及Hive客户端配置hive-site.xml上传到项目resources资源目录中。
- 准备 Maven 项目依赖
在IDEA项目中将hive-jdbc依赖进行注释,该包与SparkSQL读取Hive中的数据的包有冲突,向maven依赖中导入如下依赖包:
<!-- Spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.4.0</version>
</dependency>
<!-- SparkSQL -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.4.0</version>
</dependency>
<!-- SparkSQL ON Hive-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.4.0</version>
</dependency>
- 编写 SparkSQL 读取 Hive 代码
/**
* Spark 读取Kerberos认证Hive的数据
*/
public class SparkReadAuthHive {
public static void main(String[] args) throws IOException {
//进行kerberos认证
System.setProperty("java.security.krb5.conf", "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\krb5.conf");
String principal = "hive/node1@EXAMPLE.COM";
String keytabPath = "D:\\idea_space\\KerberosAuth\\KerberosAuthHive\\src\\main\\resources\\hive.service.keytab";
UserGroupInformation.loginUserFromKeytab(principal, keytabPath);
SparkSession spark = SparkSession.builder().appName("SparkReadAuthHive")
.master("local")
// .config("hive.metastore.uris", "thrift://node1:9083")
.enableHiveSupport()
.getOrCreate();
spark.sql("select * from person").show();
spark.stop();
}
}
以上代码编写完成后执行可以查询hive表中对应的数据。
6.6Flink访问Kerberos认证Hive
Flink读取Kerberos认证Hive也需要进行认证,这里以FlinkSQL读取Hive中数据为例来演示,步骤如下。
- 准备krb5.conf 及 keytab 文件
在node1 kerberos服务端将/etc/krb5.conf文件放在window固定路径中,同时将hive主体对应的keytab密钥文件放在windows固定路径中。 这里项目中已经有了,可以忽略。
- 准备访问 Hive 需要的资源文件
将HDFS中的core-site.xml 、hdfs-site.xml 、yarn-site.xml文件及Hive客户端配置hive-site.xml上传到项目resources资源目录中。 这里项目中已经有了,可以忽略。
- 准备 Maven 项目依赖
在IDEA项目中引入如下Flink依赖包:
<!-- Flink 读取Hive表数据需要依赖 -->
<!-- Flink批和流开发依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.16.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.16.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>1.16.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.16.0</version>
</dependency>
<!-- Flink Dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>1.16.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>1.16.0</version>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
注意:Spark操作Hive依赖与Flink操作Hive依赖也有冲突,这里由于把代码放在一个项目中,所以执行Spark或者Flink代码时把对方依赖注释掉即可。
- 编写 FlinkSQL 读取 Hive 代码
/**
* Spark 读取Kerberos认证Hive的数据
*/
public class SparkReadAuthHive {
public static void main(String[] args) throws IOException {
//进行kerberos认证
System.setProperty("java.security.krb5.conf", "D:\\idea_space\\KerberosAuth\\KerberosAuthHDFS\\src\\main\\resources\\krb5.conf");
String principal = "hive/node1@EXAMPLE.COM";
String keytabPath = "D:\\idea_space\\KerberosAuth\\KerberosAuthHive\\src\\main\\resources\\hive.service.keytab";
UserGroupInformation.loginUserFromKeytab(principal, keytabPath);
SparkSession spark = SparkSession.builder().appName("SparkReadAuthHive")
.master("local")
// .config("hive.metastore.uris", "thrift://node1:9083")
.enableHiveSupport()
.getOrCreate();
spark.sql("select * from person").show();
spark.stop();
}
}
以上代码编写完成后执行可以查询hive表中对应的数据。
7第七章 HBase Kerberos安全配置
大数据组件HBase也可以通过Kerberos进行安全认证,由于HBase中需要zookeeper进行元数据管理、主节点选举、故障恢复,所以这里对HBase进行Kerberos安全认证时,建议也对Zookeeper进行安全认证。
7.1Zookeeper Kerberos配置
zookeeper集群节点分布如下:
| 节点IP | 节点名称 | Zookeeper |
|---|---|---|
| 192.168.179.4 | node1 | |
| 192.168.179.5 | node2 | |
| 192.168.179.6 | node3 | ★ |
| 192.168.179.7 | node4 | ★ |
| 192.168.179.8 | node5 | ★ |
目前启动zookeeper集群后,可以通过任意Zookeeper客户端操作Zookeeper,可以通过Kerberos对Zookeeper进行认证避免非认证用户操作Zookeeper。按照如下步骤进行zookeeper kerberos认证。
- 创建 zookeeper Princial 服务主体
在node1节点执行如下命令创建zookeeper Princial服务主体。
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 zookeeper/node3"
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 zookeeper/node4"
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 zookeeper/node5"
- 将 zookeeper 服务主体写入到 keytab 文件
在node1节点执行如下命令,将zookeeper服务主体写入到keytab文件:
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /home/keytabs/zookeeper.service.keytab zookeeper/node3@EXAMPLE.COM"
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /home/keytabs/zookeeper.service.keytab zookeeper/node4@EXAMPLE.COM"
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /home/keytabs/zookeeper.service.keytab zookeeper/node5@EXAMPLE.COM"
以上命令执行完成后,可以在node1节点/home/keytabs目录下生成zookeeper.service.keytab文件。
- 将 keytab 文件分发到其他节点并修改权限
这里将node1节点生成的zookeeper.service.keytab文件分发到node2~node5节点,这里也可以直接分发到zookeeper服务所在节点,为了保持集群各个节点keytab文件一致,这里将该keytab文件分发到集群各个节点中。
#在node1节点中执行如下命令进行分发
[root@node1 ~]# scp /home/keytabs/zookeeper.service.keytab node2:/home/keytabs/
[root@node1 ~]# scp /home/keytabs/zookeeper.service.keytab node3:/home/keytabs/
[root@node1 ~]# scp /home/keytabs/zookeeper.service.keytab node4:/home/keytabs/
[root@node1 ~]# scp /home/keytabs/zookeeper.service.keytab node5:/home/keytabs/
分发到node2~node5各个节点后,执行如下命令对zookeeper.service.keytab修改权限。
#node1~node5所有节点执行如下命令
chown root:hadoop /home/keytabs/zookeeper.service.keytab
chmod 770 /home/keytabs/zookeeper.service.keytab
- 配置 zoo.cfg 文件
在node3~node5 zookeeper节点上配置zoo.cfg配置文件,每个节点在该文件最后追加如下配置:
kerberos.removeHostFromPrincipal=true
kerberos.removeRealmFromPrincipal=true
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
jaasLoginRenew=3600000
sessionRequireClientSASLAuth=false
skipACL=yes
以上配置项的解释如下:
- kerberos.removeHostFromPrincipal
kerberos认证时是否从Principal中移除主机名部分。
- kerberos.removeRealmFromPrincipal
kerberos认证时是否从Principal中移除领域(Realm)部分。
- authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
指定ZooKeeper对客户端进行身份验证时使用的身份验证类。
- jaasLoginRenew
Jaas登录(Java Authentication and Authorization Service)的续约时间,这里是每隔1小时需要续约Jaas登录。
- sessionRequireClientSASLAuth
是否要求客户端进行SASL认证,SASL(Simple Authentication and Security Layer)认证是一种安全机制,用于在客户端和服务器之间进行身份验证和加密通信。当设置为要求客户端进行SASL认证时,客户端必须提供有效的凭证(如用户名和密码)来证明其身份,并与ZooKeeper服务器进行安全的通信。
这里需要将该值设置为false,否则Hadoop HA 不能正常启动。
- skipACL=yes
跳过Zookeeper 访问控制列表(ACL)验证,允许连接zookeper后进行读取和写入。这里建议跳过,否则配置HBase 启动后不能向Zookeeper中写入数据。
这里在node3节点进行zoo.cfg文件的配置,配置完成后,将zoo.cfg文件分发到node4、node5 zookeeper节点上。
[root@node3 ~]# scp /software/apache-zookeeper-3.6.3-bin/conf/zoo.cfg node4:/software/apache-zookeeper-3.6.3-bin/conf/
[root@node3 ~]# scp /software/apache-zookeeper-3.6.3-bin/conf/zoo.cfg node5:/software/apache-zookeeper-3.6.3-bin/conf/
- 配置 jaas.conf 文件
在node3~node5各个zookeeper节点中ZOOKEEPER_HOME/conf/目录下创建jaas.conf文件,该文件用于zookeeper服务端与客户端进行认证。配置内容如下:
Server {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/keytabs/zookeeper.service.keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/node3@EXAMPLE.COM";
};
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/keytabs/zookeeper.service.keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/node3@EXAMPLE.COM";
};
以上配置文件是在node3 zookeeper节点配置,将以上文件分发到node4、node5节点后,需要将principal修改成对应节点的信息。
node4 zookeeper节点jaas.conf配置如下:
Server {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/keytabs/zookeeper.service.keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/node4@EXAMPLE.COM";
};
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/keytabs/zookeeper.service.keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/node4@EXAMPLE.COM";
};
node5 zookeeper节点jaas.conf配置如下:
Server {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/keytabs/zookeeper.service.keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/node5@EXAMPLE.COM";
};
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/keytabs/zookeeper.service.keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/node5@EXAMPLE.COM";
};
- 配置 java.env 文件
在zookeeper各个节点ZOOKEEPER_HOME/conf目录下创建java.env文件,写入如下内容,这里在node3~node5各个节点都需配置。
#指定jaas.conf文件路径
export JVMFLAGS="-Djava.security.auth.login.config=/software/apache-zookeeper-3.6.3-bin/conf/jaas.conf"
以上可以先在node3节点进行配置,然后分发到node4~node5节点上。如下:
[root@node3 ~]# scp /software/apache-zookeeper-3.6.3-bin/conf/java.env node4:/software/apache-zookeeper-3.6.3-bin/conf/
[root@node3 ~]# scp /software/apache-zookeeper-3.6.3-bin/conf/java.env node5:/software/apache-zookeeper-3.6.3-bin/conf/
- 启动 zookeeper
在node3~node5各个节点执行如下命令,启动zookeeper。
#启动zookeeper
zkServer.sh start
#检查zookeeper状态
zkServer.sh status
7.2HBase配置Kerberos
HBase也支持Kerberos安全认证,经过测试,HBase2.5.x版本在经过Kerberos认证后与Hadoop通信认证有异常,具体报错如下:
hdfs.DataStreamer: Exception in createBlockOutputStream java.io.IOException: Invalid token in javax.security.sasl.qop: DI
这里建议使用HBase2.5.x以下版本与kerberos进行整合,但HBase版本的选择也需要参考Hadoop的版本,可以在Hbase官网找到Hadoop版本匹配的HBase版本,地址为:https://hbase.apache.org/book.html#hadoop
我们这里使用的Hadoop版本为3.3.4,HBase版本选择2.2.6版本。HBase Kerberos安全认证配置步骤如下:
- 创建 HBase 服务用户并两两节点进行免密
在Hadoop体系中操作HBase时通常使用hbase用户,这里在集群各个节点创建hbase用户并设置在HBase用户下,节点之间的免密。
在node1~node5节点创建hbase用户,所属hadoop组。
#这里设置用户密码为123456
useradd hbase -g hadoop
passwd hbase
各个节点切换到hbase用户,并设置各个节点两两免密。
#所有节点切换成hbase用户
su hbase
cd ~
#node1~node5所有节点生成SSH密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
#node1~node5所有节点公钥复制到node1节点上,这个过程需要输入yes和密码
ssh-copy-id node1
#将node1 authorized_keys文件分发到node1~node5各节点,这个过程需要输入密码
[hbase@node1 ~]$ cd ~/.ssh/
[hbase@node1 .ssh]$ scp authorized_keys node2:`pwd`
[hbase@node1 .ssh]$ scp authorized_keys node3:`pwd`
[hbase@node1 .ssh]$ scp authorized_keys node4:`pwd`
[hbase@node1 .ssh]$ scp authorized_keys node5:`pwd`
#两两节点进行ssh测试,这一步骤必须做,然后node1~node5节点退出当前hbase用户
exit
- 创建 HBase 服务 Princial 主体并写入到 keytab 文件
在kerberos服务端node1节点执行如下命令创建HBase服务主体:
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 hbase/node3"
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 hbase/node4"
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 hbase/node5"
在kerberos服务端node1节点执行如下命令将hbase主体写入到keytab文件
#node1节点执行命令,将主体写入到keytab
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /home/keytabs/hbase.service.keytab hbase/node3@EXAMPLE.COM"
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /home/keytabs/hbase.service.keytab hbase/node4@EXAMPLE.COM"
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /home/keytabs/hbase.service.keytab hbase/node5@EXAMPLE.COM"
以上命令执行完成后,在node1节点/home/keytabs目录下生成hbase.service.keytab文件,将该文件分发到各个节点并赋权,这里可以只发送到node3~node5 Hbase所在节点,为了保证各个大数据集群节点的keytabs一致,这里分发到所有节点。
[root@node1 ~]# scp /home/keytabs/hbase.service.keytab node2:/home/keytabs/
[root@node1 ~]# scp /home/keytabs/hbase.service.keytab node3:/home/keytabs/
[root@node1 ~]# scp /home/keytabs/hbase.service.keytab node4:/home/keytabs/
[root@node1 ~]# scp /home/keytabs/hbase.service.keytab node5:/home/keytabs/
分发完成后,在集群各个节点上执行如下命令,修改hbase.service.keytab密钥文件所属用户和组信息:
chown root:hadoop /home/keytabs/hbase.service.keytab
chmod 770 /home/keytabs/hbase.service.keytab
- 修改 hbase-site.xml 配置文件
在所有hbase节点中修改HBASE_HOME/conf/hbase-site.xml文件内容,配置支持kerberos,向hbase-site.xml文件中追加如下内容:
<!-- hbase开启安全认证 -->
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<!-- hbase配置kerberos安全认证 -->
<property>
<name>hbase.security.authentication</name>
<value>kerberos</value>
</property>
<!-- HMaster配置kerberos安全凭据认证 -->
<property>
<name>hbase.master.kerberos.principal</name>
<value>hbase/_HOST@EXAMPLE.COM</value>
</property>
<!-- HMaster配置kerberos安全证书keytab文件位置 -->
<property>
<name>hbase.master.keytab.file</name>
<value>/home/keytabs/hbase.service.keytab</value>
</property>
<!-- Regionserver配置kerberos安全凭据认证 -->
<property>
<name>hbase.regionserver.kerberos.principal</name>
<value>hbase/_HOST@EXAMPLE.COM</value>
</property>
<!-- Regionserver配置kerberos安全证书keytab文件位置 -->
<property>
<name>hbase.regionserver.keytab.file</name>
<value>/home/keytabs/hbase.service.keytab</value>
</property>
这里可以先在node3节点进行配置,配置完成后分发到node4、node5节点:
[root@node3 ~]# scp /software/hbase-2.2.6/conf/hbase-site.xml node4:/software/hbase-2.2.6/conf/
[root@node3 ~]# scp /software/hbase-2.2.6/conf/hbase-site.xml node5:/software/hbase-2.2.6/conf/
- 准备 hdfs-site.xml 和 core-site.xml 文件
HBase底层存储使用HDFS,这里需要将Hadoop中hdfs-site.xml和core-site.xml文件发送到hbase各个节点HBASE_HOME/conf/目录中。在node3~node5各个HBase节点中执行如下命令:
#node3~node5各个节点执行
cp /software/hadoop-3.3.4/etc/hadoop/hdfs-site.xml /software/hbase-2.2.6/conf/
cp /software/hadoop-3.3.4/etc/hadoop/core-site.xml /software/hbase-2.2.6/conf/
- 准备 zk-jaas.conf 文件
HBase中会使用zookeeper管理元数据和选主,这里由于Zookeeper中已经开启了Kerberos认证,所以需要准备zk-jaas.conf文件连接zookeeper时进行认证。在HBase各个节点HBASE_HOME/conf目录下创建zk-jaas.conf文件,写入如下内容,不同的节点设置的principal是对应HBase主机节点。
node3节点HBASE_HOME/conf/zk-jaas.conf文件内容:
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/keytabs/hbase.service.keytab"
useTicketCache=false
principal="hbase/node3@EXAMPLE.COM";
};
node4节点HBASE_HOME/conf/zk-jaas.conf文件内容:
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/keytabs/hbase.service.keytab"
useTicketCache=false
principal="hbase/node4@EXAMPLE.COM";
};
node5节点HBASE_HOME/conf/zk-jaas.conf文件内容:
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/home/keytabs/hbase.service.keytab"
useTicketCache=false
principal="hbase/node5@EXAMPLE.COM";
};
- 修改 hbase-env.sh 配置
在各个hbase节点上配置HBASE_HOME/conf/hbase-env.sh,将HBASE_OPTS选项修改为如下:
#node3~node5各个节点修改hbase-env.sh中的HBASE_OPTS配置
export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC -Djava.security.auth.login.config=/software/hbase-2.2.6/conf/zk-jaas.conf"
- 修改 HBase 安装目录权限
在HBase各个节点创建HBASE_HOME/logs目录,如果该目录不存在需要提前创建,存在即可忽略,该目录为HBase日志目录,需要将该目录权限修改为root:hadoop、访问权限为770,否则hbase用户在启动Hbase集群时没有向该目录写日志权限。
#在node3~node5 HBase节点执行命令创建HBASE_HOME/logs
mkdir -p /software/hbase-2.2.6/logs
将各个节点的hbase安装目录权限修改为root:hadoop,logs目录访问权限为770:
#在node3~node5 HBase节点执行命令
chown -R root:hadoop /software/hbase-2.2.6
chmod -R 770 /software/hbase-2.2.6/logs
7.3HBase启动及访问验证
在启动HBase集群之前,需要将Zookeeper和HDFS集群重启,Zookeeper和HDFSQ启动命令如下:
#停止hadoop集群
[root@node1 ~]# stop-all.sh
#node3~node5节点,重启zookeeper
[root@node3 ~]# zkServer.sh restart
[root@node3 ~]# zkServer.sh restart
[root@node3 ~]# zkServer.sh restart
#启动HDFS集群
[root@node1 ~]# start-all.sh
如果HBase之前启动过,在HDFS中将会有/hbase 目录,需要使用hdfs超级管理员用户将该目录的用户和所属组修改成hbase:hadoop
#在node5节点执行
[root@node5 ~]# su hdfs
[hdfs@node5 ~]$ kinit hdfs
Password for hdfs@EXAMPLE.COM: 123456
[hdfs@node5 logs]$ hdfs dfs -ls /
Found 6 items
drwxr-xr-x - root supergroup 0 2023-05-23 10:50 /hbase
#修改用户和所属组
[hdfs@node5 logs]$ hadoop dfs -chown -R hbase:hadoop /hbase
在HBase主节点node4上执行如下命令启动HBase集群:
#无需切换hbase用户,可以直接在node4节点执行如下命令启动hbase集群
[root@node4 ~]# sudo -i -u hbase start-hbase.sh
注意:以上启动Hbase集群命令中没有切换到hbase用户,sudo为使用超级用户权限执行命令,-i表示交互模式执行命令,-u指定切换的用户。
HBase启动后,可以通过http://node4:16010进行访问:


7.4HBase Shell操作HBase
在node3~node5任意节点登录hbase shell,可以看到如果节点没有进行用户认证,读取HBase数据时没有权限:
#假设在node4登录hbase客户端
[root@node4 ~]# klist
klist: No credentials cache found (filename: /tmp/krb5cc_0)
[root@node4 ~]# hbase shell
hbase(main):001:0> list
TABLE
ERROR: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)
如果想要正常读取HBase中的数据需要进行客户端认证,这里以zhangsan用户为例,进行Kerberos主体认证,认证后操作HBase,操作如下:
#进行用户认证
[root@node4 ~]# kinit zhangsan
Password for zhangsan@EXAMPLE.COM: 123456
[root@node4 ~]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: zhangsan@EXAMPLE.COM
#登录hbase shell
[root@node4 ~]# hbase shell
hbase(main):001:0> create 'person','cf1','cf2'
Created table person
hbase(main):002:0> list
person
hbase(main):003:0> put 'person','row1','cf1:id','1'
hbase(main):004:0> put 'person','row1','cf1:name','zs'
hbase(main):005:0> put 'person','row1','cf1:age',18
hbase(main):006:0> scan 'person'
ROW COLUMN+CELL
row1 column=cf1:age, timestamp=1684317908851, value=18
row1 column=cf1:id, timestamp=1684317879179, value=1
row1 column=cf1:name, timestamp=1684317894358, value=zs
7.5Java API操作HBase
java API操作经过Kerberos安全认证的HBase按照如下步骤实现即可。
- 准备 krb5.conf 文件
将node1 kerberos服务端/etc/krb5.conf文件存放在IDEA项目中的resources资源目录中或者本地Window固定的某个目录中,用于编写代码时指定访问Kerberos的Realm。
- 生成用户 keytab 文件
在kerberos服务端node1节点上,执行如下命令,对zhangsan用户主体生成keytab密钥文件。
#在node1 kerberos服务端执行
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /root/zhangsan.keytab zhangsan@EXAMPLE.COM"
以上命令执行之后,在/root目录下会生成zhangsan.keytab文件,将该文件复制到IDEA项目中的resources资源目录中或者本地window固定的某个目录中,该文件用于编写代码时认证kerberos。
- 准备访问 HDFS 需要的资源文件
将HDFS中的core-site.xml 、hdfs-site.xml 、yarn-site.xml、hbase-site.xml文件上传到项目resources资源目录中。
- 编写代码操作 HBase
项目代码中引入如下maven依赖:
<!-- hbase依赖包 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.6</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.6</version>
</dependency>
编写Java代码操作Kerberos认证的HBase代码如下:
/**
* Java API 操作Kerberos 认证的HBase
*/
public class OperateAuthHBase {
private static Configuration conf;
private static Connection connection;
private static Admin admin;
/**
* 初始化:进行kerberos认证并设置hbase configuration
*/
static {
try {
String principal = "zhangsan@EXAMPLE.COM";
String keytabPath = "D:\\idea_space\\KerberosAuth\\KerberosAuthHBase\\src\\main\\resources\\zhangsan.keytab";
conf = HBaseConfiguration.create();
// 设置Kerberos 认证
System.setProperty("java.security.krb5.conf", "D:\\idea_space\\KerberosAuth\\KerberosAuthHBase\\src\\main\\resources\\krb5.conf");
conf.set("hadoop.security.authentication", "kerberos");
UserGroupInformation.setConfiguration(conf);
UserGroupInformation.loginUserFromKeytab(principal, keytabPath);
//设置zookeeper集群地址及端口号
conf.set("hbase.zookeeper.quorum","node3,node4,node5");
conf.set("hbase.zookeeper.property.clientPort","2181");
//创建连接
connection = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws IOException {
try{
//获取Admin对象
admin = connection.getAdmin();
//创建表
createHBaseTable("tbl1", "cf1");
System.out.println("===========================");
//查看Hbase中所有表
listHBaseTables();
System.out.println("===========================");
//向表中插入数据
putTableData("tbl1","row1", "cf1", "id", "100");
putTableData("tbl1","row1", "cf1", "name", "zs");
putTableData("tbl1","row1", "cf1", "age", "18");
putTableData("tbl1","row2", "cf1", "id", "200");
putTableData("tbl1","row2", "cf1", "name", "ls");
putTableData("tbl1","row2", "cf1", "age", "19");
System.out.println("===========================");
//查询表中的数据
scanTableData("tbl1");
System.out.println("===========================");
//查询指定row数据
getRowData("tbl1", "row1","cf1","name");
System.out.println("===========================");
//删除指定row数据
deleteRowData("tbl1", "row1","cf1","name");
System.out.println("===========================");
//查询表中的数据
scanTableData("tbl1");
System.out.println("===========================");
//删除表
deleteHBaseTable("tbl1");
//查看Hbase中所有表
listHBaseTables();
System.out.println("===========================");
}catch (Exception e) {
e.printStackTrace();
}finally {
if(admin != null) {
admin.close();
}
if(connection != null) {
connection.close();
}
}
}
//判断表是否存在
private static boolean isTableExist(String tableName) {
try {
return admin.tableExists(TableName.valueOf(tableName));
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
private static void createHBaseTable(String tableName, String... cfs) {
if(isTableExist(tableName)) {
System.out.println("表已经存在!");
return;
}
if(cfs == null || cfs.length == 0){
System.out.println("列族不能为空!");
return;
}
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName));
List<ColumnFamilyDescriptor> cFDBList = new ArrayList<>();
for (String cf : cfs) {
cFDBList.add(ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(cf)).build());
}
tableDescriptorBuilder.setColumnFamilies(cFDBList);
try {
admin.createTable(tableDescriptorBuilder.build());
System.out.println("创建表" + tableName + "成功!");
} catch (IOException e) {
System.out.println("创建失败!");
e.printStackTrace();
}
}
//查看Hbase中所有表
private static void listHBaseTables() {
try {
TableName[] tableNames = admin.listTableNames();
System.out.println("打印所有命名空间表名:");
for (TableName tableName : tableNames) {
System.out.println(tableName);
}
} catch (IOException e) {
e.printStackTrace();
}
}
//向表中插入数据
private static void putTableData(String tableName, String rowKey, String cf, String column, String value) {
Table table = null;
try {
table = connection.getTable(TableName.valueOf(tableName));
Put p = new Put(Bytes.toBytes(rowKey));
p.addColumn(Bytes.toBytes(cf), Bytes.toBytes(column), Bytes.toBytes(value));
table.put(p);
System.out.println("插入数据成功!");
} catch (IOException e) {
e.printStackTrace();
} finally {
closeTable(table);
}
}
//查询表中的数据
private static void scanTableData(String tableName) {
if(tableName == null || tableName.length() == 0) {
System.out.println("请正确输入表名!");
return;
}
Table table = null;
try {
table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
ResultScanner resultScanner = table.getScanner(scan);
Iterator<Result> iterator = resultScanner.iterator();
while(iterator.hasNext()) {
Result result = iterator.next();
Cell[] cells = result.rawCells();
for(Cell cell : cells) {
//得到rowkey
System.out.println("rowkey: " + Bytes.toString(CellUtil.cloneRow(cell)));
//得到列族
System.out.println("列族: " + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列: " + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值: " + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
closeTable(table);
}
}
//查询指定row数据
private static void getRowData(String tableName, String rowkey,String colFamily, String col) {
Table table = null;
try {
table = connection.getTable(TableName.valueOf(tableName));
Get g = new Get(Bytes.toBytes(rowkey));
// 获取指定列族数据
if(col == null && colFamily != null) {
g.addFamily(Bytes.toBytes(colFamily));
} else if(col != null && colFamily != null) {
// 获取指定列数据
g.addColumn(Bytes.toBytes(colFamily), Bytes.toBytes(col));
}
Result result = table.get(g);
System.out.println("查询指定rowkey 数据如下");
for(Cell cell : result.rawCells()) {
//得到rowkey
System.out.println("rowkey: " + Bytes.toString(CellUtil.cloneRow(cell)));
//得到列族
System.out.println("列族: " + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列: " + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值: " + Bytes.toString(CellUtil.cloneValue(cell)));
}
} catch (IOException e) {
e.printStackTrace();
} finally {
closeTable(table);
}
}
//删除指定row数据
private static void deleteRowData(String tableName , String rowKey, String colFamily, String ... cols) {
if(tableName == null || tableName.length() == 0) {
System.out.println("请正确输入表名!");
return;
}
Table table = null;
try {
table = connection.getTable(TableName.valueOf(tableName));
Delete del = new Delete(Bytes.toBytes(rowKey));
// 删除指定列族
del.addFamily(Bytes.toBytes(colFamily));
// 删除指定列
for (String col : cols) {
del.addColumn(Bytes.toBytes(colFamily), Bytes.toBytes(col));
}
table.delete(del);
System.out.println("删除数据成功!");
} catch (IOException e) {
e.printStackTrace();
} finally {
closeTable(table);
}
}
//删除表
private static void deleteHBaseTable(String tableName) {
try {
if(!isTableExist(tableName)) {
System.out.println("要删除的表不存在!");
return;
}
admin.disableTable(TableName.valueOf(tableName));
admin.deleteTable(TableName.valueOf(tableName));
} catch (IOException e) {
e.printStackTrace();
}
}
//关闭表
private static void closeTable(Table table) {
if(table != null) {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
8第八章 Kafka Kerberos安全配置
8.1Kafka配置Kerberos
Kafka也支持通过Kerberos进行认证,避免非法用户操作读取Kafka中的数据,对Kafka进行Kerberos认证可以按照如下步骤实现。
- 创建 Kafka 服务 Princial 主体并写入到 keytab 文件
在kerberos服务端node1节点执行如下命令创建Kafka服务主体:
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 kafka/node1"
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 kafka/node2"
[root@node1 ~]# kadmin.local -q "addprinc -pw 123456 kafka/node3"
在kerberos服务端node1节点执行如下命令将Kafka服务主体写入到keytab文件
#node1节点执行命令,将主体写入到keytab
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /home/keytabs/kafka.service.keytab kafka/node1@EXAMPLE.COM"
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /home/keytabs/kafka.service.keytab kafka/node2@EXAMPLE.COM"
[root@node1 ~]# kadmin.local -q "ktadd -norandkey -kt /home/keytabs/kafka.service.keytab kafka/node3@EXAMPLE.COM"
以上命令执行完成后,在node1节点/home/keytabs目录下生成kafka.service.keytab文件,将该文件分发到各个节点并赋权,这里可以只发送到node1~node3 Kafka所在节点,为了保证各个大数据集群节点的keytabs一致,这里分发到所有节点。
[root@node1 ~]# scp /home/keytabs/kafka.service.keytab node2:/home/keytabs/
[root@node1 ~]# scp /home/keytabs/kafka.service.keytab node3:/home/keytabs/
[root@node1 ~]# scp /home/keytabs/kafka.service.keytab node4:/home/keytabs/
[root@node1 ~]# scp /home/keytabs/kafka.service.keytab node5:/home/keytabs/
分发完成后,在集群各个节点上执行如下命令,修改kafka.service.keytab密钥文件访问权限:
chmod 770 /home/keytabs/kafka.service.keytab
- 修改配置 server.properties 文件
在Kafka各个节点KAFKA_HOME/config/server.properties文件中加入如下配置以支持Kerberos安全认证。
#在node1~node3所有节点单独配置
listeners=SASL_PLAINTEXT://:9092
inter.broker.listener.name=SASL_PLAINTEXT
sasl.mechanism.inter.broker.protocol=GSSAPI
sasl.enabled.mechanisms=GSSAPI
sasl.kerberos.service.name=kafka
authorizer.class.name=kafka.security.authorizer.AclAuthorizer
zookeeper.set.acl=false
allow.everyone.if.no.acl.found=true
该配置需要在node1~node3所有节点配置,以上参数解释如下:
- listeners=SASL_PLAINTEXT://:9092
指定kafka监听的协议和端口,SASL_PLAINTEXT表示使用SASL(Simple Authentication and Security Layer)机制进行认证和加密通信。
- inter.broker.listener.name=SASL_PLAINTEXT
指定Kafka Broker 之间通信使用SASL_PLAINTEXT机制进行认证和加密通信。
- sasl.mechanism.inter.broker.protocol=GSSAPI
指定broker之间通信使用SASL机制,GSSAPI是一种基于Kerberos的SASL机制,它使用GSS-API(Generic Security Services Application Programming Interface)进行认证。
- sasl.enabled.mechanisms=GSSAPI
只启用了GSSAPI机制,表示Kafka只接受使用Kerberos进行认证的连接。
- sasl.kerberos.service.name=kafka
指定Kafka在Kerberos中注册的服务名称,以便用于进行身份验证和授权。
authorizer.class.name=kafka.security.authorizer.AclAuthorizer
指定Kafka使用的授权器类。
- zookeeper.set.acl=false
是否在ZooKeeper中设置ACL(Access Control List),这里设置为false,表示不对ZooKeeper节点设置ACL。
- allow.everyone.if.no.acl.found=true
指定当没有匹配的ACL规则时,是否允许所有用户访问。
- 准备 kafka_jaas.conf 文件
在node1~node3各个节点中准备kafka_jaas.conf文件,该文件配置kafka服务端和zookeeper客户端的身份验证和授权配置,由于zookeeper开启了Kerberos认证,所以这里需要进行zookeeper客户端的身份验证配置。
这里在各个kafka节点KAFKA_HOME/config/目录中创建kafka_jaas.conf文件,内容如下:
KafkaServer {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/home/keytabs/kafka.service.keytab"
serviceName="kafka"
principal="kafka/node1@EXAMPLE.COM";
};
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
serviceName="zookeeper"
keyTab="/home/keytabs/zookeeper.service.keytab"
principal="zookeeper/node3@EXAMPLE.COM";
};
以上在可以在node1 kafka客户端配置完成后,分发到node2~node3节点中,如下:
#在node1节点分发,分发后在node2、node3节点配置对应Server principal
[root@node1 config]# scp /software/kafka_2.12-3.3.1/config/kafka_jaas.conf node2:/software/kafka_2.12-3.3.1/config/
[root@node1 config]# scp /software/kafka_2.12-3.3.1/config/kafka_jaas.conf node3:/software/kafka_2.12-3.3.1/config/
注意:在node1~node3各个kafka节点中该文件中的KafkaServer对应的principal不同,为对应各个节点hostname。
- 准备 kafka_client_jaas.conf
在各个kafka节点配置kafka_client_jaas.conf配置文件,该文件作用主要是对kafka 客户端进行身份认证。这里在node1~node3节点KAFKA_HOME/config/中创建kafka_client_jaas.conf文件,内容如下:
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/home/keytabs/kafka.service.keytab"
serviceName="kafka"
principal="kafka/node1@EXAMPLE.COM";
};
可以在node1节点配置该文件后分发到node2~node3节点中:
#分发到node2、node3节点,需要在对应节点配置对应的principal
[root@node1 config]# scp /software/kafka_2.12-3.3.1/config/kafka_client_jaas.conf node2:/software/kafka_2.12-3.3.1/config/
[root@node1 config]# scp /software/kafka_2.12-3.3.1/config/kafka_client_jaas.conf node3:/software/kafka_2.12-3.3.1/config/
以上文件分发完成后,需要在对应节点修改配置对应的Principal信息为对应的hostname。
- 修改启动脚本 kafka-server-start.sh
在kafka各个节点中配置KAFKA_HOME/bin/kafka-server-start.sh启动脚本,在该脚本中加入kafka_jaas.conf配置,加入的内容如下:
#在node1~node3各个节点都要配置kafka-server-start.sh
export KAFKA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/software/kafka_2.12-3.3.1/config/kafka_jaas.conf"
- 修改 kafka 操作脚本
在当前集群中node1~node3节点是kafka服务端,同时如果在这3个节点上进行kafka 命令操作,这三个节点也是kafka客户端。在操作kafka时我们通常会操作KAFKA_HOME中的kafka-topic.sh、kafka-console-producer.sh、kafka-console-consumer.sh脚本,这些脚本需要进行kerberos认证,可以通过前面配置的kafka_client_jaas.conf文件进行Kerberos认证,所以这里在各个脚本中加入如下配置,避免在操作对应脚本时没有进行认证从而没有操作权限。
在node1~node3各个kafka 客户端配置以上脚本,可以先在node1节点进行配置各文件然后分发到其他kafka客户端,对应操作文件增加如下配置:
#vim /software/kafka_2.12-3.3.1/bin/kafka-topics.sh
export KAFKA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/software/kafka_2.12-3.3.1/config/kafka_client_jaas.conf"
#vim /software/kafka_2.12-3.3.1/bin/kafka-console-producer.sh
export KAFKA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/software/kafka_2.12-3.3.1/config/kafka_client_jaas.conf"
#vim /software/kafka_2.12-3.3.1/bin/kafka-console-consumer.sh
export KAFKA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf -Djava.security.auth.login.config=/software/kafka_2.12-3.3.1/config/kafka_client_jaas.conf"
在node1 kafka 客户端配置完成后,将配置后的各个脚本文件分发到其他kafka客户端节点上:
[root@node1 ~]# cd /software/kafka_2.12-3.3.1/bin/
[root@node1 bin]# scp ./kafka-topics.sh ./kafka-console-producer.sh ./kafka-console-consumer.sh node2:`pwd`
[root@node1 bin]# scp ./kafka-topics.sh ./kafka-console-producer.sh ./kafka-console-consumer.sh node3:`pwd`
- 准备 client.properites
在node1~node3各个kafka 客户端中准备client.properties配置文件,该配置文件内容如下,这里将该文件创建在各个节点的/root目录下。
security.protocol=SASL_PLAINTEXT
sasl.mechanism=GSSAPI
sasl.kerberos.service.name=kafka
当Kafka通过Kerberos认证后,在执行KAFKA_HOME/bin目录下的脚本时,需要使用正确的协议、SASL机制及kerberos服务,所以这里将以上信息配置到client.properties文件中,在执行各个脚本时需要通过参数指定该文件,这样客户端可以和服务端正常通信。
在node1配置完成/root/client.properties文件后,分发到node2~node3节点中:
[root@node1 ~]# scp ./client.properties node2:`pwd`
[root@node1 ~]# scp ./client.properties node3:`pwd`
- 启动 kafka 集群
启动kafka集群前需要先启动Zookeeper,然后在各个kafka服务节点启动kafka,完成kafka集群启动。操作如下:
#node3~node5各节点启动zookeeper
zkServer.sh start
#node1~node3各节点启动kafka
startKafka.sh
8.2客户端操作Kafka
启动Kafka集群后,通过如下命令在Kafka集群查询、创建topic以及向topic中写入数据,以下命令可以执行在node1~node3各个kafka 客户端中。
#创建kafka topic
kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic test --partitions 3 --replication-factor 1 --command-config /root/client.properties
#查看集群topic
kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list --command-config /root/client.properties
#向kafka topic中写入数据
[root@node1 ~]# kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic test --producer.config /root/client.properties
>1
>2
>3
>4
>5
#读取kafka topic中的数据
[root@node1 ~]# kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic test --from-beginning --consumer.config /root/client.properties
1
2
3
4
5
8.3Java API操作Kafka
可以按照如下步骤实现Java API操作Kerberos认证的Kafka数据。
- 准备 krb5.conf 文件
将node1 kerberos服务端/etc/krb5.conf文件存放在IDEA项目中的resources资源目录中或者本地Window固定的某个目录中,用于编写代码时指定访问Kerberos的Realm。
- 准备用户 keytab 文件
在kerberos服务端node1节点上将生成的kafka.server.keytab文件存入到window路径中,这里放在项目resource资源目录下,后续需要该文件进行客户端认证。
- 准备 kafka_client_jaas.conf 文件
将Kafka 中kafka_client_jaas.conf文件放在window中某个路径中,并修改该文件中keytab路径为window路径:
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="D:/idea_space/KerberosAuth/KerberosAuthKafka/src/main/resources/kafka.service.keytab"
serviceName="kafka"
principal="kafka/node1@EXAMPLE.COM";
};
特别需要注意的是该文件中指定window路径时使用"/"或"\"隔开各目录,否则客户端认证时读取不到keytab文件。这里将修改后的kafka_client_jaas.conf文件存入到项目resource资源目录下。
- 编写 Java 代码向 Kafka topic 中读写数据
编写代码前,需要在项目pom.xml中引入如下依赖:
<!-- kafka client依赖包 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.1</version>
</dependency>
Java API读写Kafka Topic代码如下:
/**
* Java API 操作Kerbros认证的Kafka
* 使用 JAAS 来进行 Kerberos 认证
* 注意:kafka_client_jaas.conf文件中的keytab文件路径需要使用双斜杠或者反单斜杠
*/
public class OperateAuthKafka {
public static void main(String[] args) {
//准备JAAS配置文件路径
String kafkaClientJaasFile = "D:\\idea_space\\KerberosAuth\\KerberosAuthKafka\\src\\main\\resources\\kafka_client_jaas.conf";
// Kerberos配置文件路径
String krb5FilePath = "D:\\idea_space\\KerberosAuth\\KerberosAuthKafka\\src\\main\\resources\\krb5.conf";
System.setProperty("java.security.auth.login.config", kafkaClientJaasFile);
System.setProperty("java.security.krb5.conf", krb5FilePath);
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//kerberos安全认证
props.setProperty("security.protocol", "SASL_PLAINTEXT");
props.setProperty("sasl.mechanism", "GSSAPI");
props.setProperty("sasl.kerberos.service.name", "kafka");
//向Kafka topic中发送消息
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props);
kafkaProducer.send(new ProducerRecord<>("test", "100"));
kafkaProducer.send(new ProducerRecord<>("test", "200"));
kafkaProducer.send(new ProducerRecord<>("test", "300"));
kafkaProducer.send(new ProducerRecord<>("test", "400"));
kafkaProducer.send(new ProducerRecord<>("test", "500"));
kafkaProducer.close();
System.out.println("消息发送成功");
/**
* 从Kafka topic中消费消息
*/
props.setProperty("group.id", "test"+ UUID.randomUUID());
//设置消费的位置,earliest表示从头开始消费,latest表示从最新的位置开始消费
props.setProperty("auto.offset.reset", "earliest");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(props);
kafkaConsumer.subscribe(Arrays.asList("test"));
while (true) {
// 拉取数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : consumerRecords) {
// 获取数据对应的分区号
int partition = record.partition();
// 对应数据值
String value = record.value();
//对应数据的偏移量
long lastoffset = record.offset();
//对应数据发送的key
String key = record.key();
System.out.println("数据的key为:"+ key +
",数据的value为:" + value +
",数据的offset为:"+ lastoffset +
",数据的分区为:"+ partition);
}
}
}
}
8.4StructuredStreaming操作Kafka
StructuredStreaming操作Kafka时同样需要准备krb5.conf、kafka.service.keytab、kafka_client_jaas.conf配置文件,步骤参考Java API操作Kafka部分。
编写代码前,需要在项目pom.xml中引入如下依赖:
<!-- SparkSQL -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.4.0</version>
</dependency>
<!-- Kafka 0.10+ Source For Structured Streaming-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>3.4.0</version>
</dependency>
StructuredStreaming操作Kafka代码如下:
/**
* StructuredStreaming 读取Kerberos 认证的Kafka数据
*/
public class StructuredStreamingReadAuthKafka {
public static void main(String[] args) throws TimeoutException, StreamingQueryException {
//准备JAAS配置文件路径
String kafkaClientJaasFile = "D:\\idea_space\\KerberosAuth\\KerberosAuthKafka\\src\\main\\resources\\kafka_client_jaas.conf";
// Kerberos配置文件路径
String krb5FilePath = "D:\\idea_space\\KerberosAuth\\KerberosAuthKafka\\src\\main\\resources\\krb5.conf";
System.setProperty("java.security.auth.login.config", kafkaClientJaasFile);
System.setProperty("java.security.krb5.conf", krb5FilePath);
//1.创建对象
SparkSession spark = SparkSession.builder()
.master("local")
.appName("kafka source")
.config("spark.sql.shuffle.partitions", 1)
.getOrCreate();
spark.sparkContext().setLogLevel("Error");
//2.读取kafka 数据
Dataset<Row> df = spark.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "node1:9092,node2:9092,node3:9092")
.option("subscribe", "test")
.option("startingOffsets", "earliest")
//kerberos安全认证
.option("kafka.security.protocol", "SASL_PLAINTEXT")
.option("kafka.sasl.mechanism", "GSSAPI")
.option("kafka.sasl.kerberos.service.name", "kafka")
.load();
Dataset<Row> result = df.selectExpr("cast (key as string)", "cast (value as string)");
StreamingQuery query = result.writeStream()
.format("console")
.start();
query.awaitTermination();
}
}
8.5Flink 操作Kafka
Flink操作Kafka时同样需要准备krb5.conf、kafka.service.keytab、kafka_client_jaas.conf配置文件,步骤参考Java API操作Kafka部分。
编写代码前,需要在项目pom.xml中引入如下依赖:
<!-- Flink批和流开发依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.16.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.16.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.16.0</version>
</dependency>
Flink操作Kafka代码如下:
/**
* Flink 读取Kerberos 认证的Kafka数据
*/
public class FlinkReadAuthKafka {
public static void main(String[] args) throws Exception {
//准备JAAS配置文件路径
String kafkaClientJaasFile = "D:\\idea_space\\KerberosAuth\\KerberosAuthKafka\\src\\main\\resources\\kafka_client_jaas.conf";
// Kerberos配置文件路径
String krb5FilePath = "D:\\idea_space\\KerberosAuth\\KerberosAuthKafka\\src\\main\\resources\\krb5.conf";
System.setProperty("java.security.auth.login.config", kafkaClientJaasFile);
System.setProperty("java.security.krb5.conf", krb5FilePath);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<Tuple2<String, String>> kafkaSource = KafkaSource.<Tuple2<String, String>>builder()
.setBootstrapServers("node1:9092,node2:9092,node3:9092") //设置Kafka 集群节点
.setTopics("test") //设置读取的topic
.setGroupId("my-test-group") //设置消费者组
//kerberos安全认证
.setProperty("security.protocol", "SASL_PLAINTEXT")
.setProperty("sasl.mechanism", "GSSAPI")
.setProperty("sasl.kerberos.service.name", "kafka")
.setStartingOffsets(OffsetsInitializer.earliest()) //设置读取数据位置
.setDeserializer(new KafkaRecordDeserializationSchema<Tuple2<String, String>>() {
//设置key ,value 数据获取后如何处理
@Override
public void deserialize(ConsumerRecord<byte[], byte[]> consumerRecord, Collector<Tuple2<String, String>> collector) throws IOException {
String key = null;
String value = null;
if(consumerRecord.key() != null){
key = new String(consumerRecord.key(), "UTF-8");
}
if(consumerRecord.value() != null){
value = new String(consumerRecord.value(), "UTF-8");
}
collector.collect(Tuple2.of(key, value));
}
//设置置返回的二元组类型
@Override
public TypeInformation<Tuple2<String, String>> getProducedType() {
return TypeInformation.of(new TypeHint<Tuple2<String, String>>() {
});
}
})
.build();
DataStreamSource<Tuple2<String, String>> kafkaDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka-source");
kafkaDS.print();
env.execute();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号