

8.SpringBoot集成MongoDB
环境准备
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
配置yml
spring:
data:
mongodb:
uri: mongodb://zh:zh@127.0.0.1:27010/test?authSource=admin
#uri等同于下面的配置
#database: test
#host: 127.0.0.1
#port: 27010
#username: zh
#password: zh
#authentication-database: admin
连接配置参考文档:https://docs.mongodb.com/manual/reference/connection-string/
使用时注入MongoTemplate
@Autowired
MongoTemplate mongoTemplate;
集合操作
@Test
public void testCollection(){
boolean exists = mongoTemplate.collectionExists("emp");//判断集合是否存在
if (exists) {
//删除集合
mongoTemplate.dropCollection("emp");
}
//创建集合
mongoTemplate.createCollection("emp");
}
文档操作
相关注解
-
@Document
修饰范围: 用在类上
作用: 用来映射这个类的一个对象为mongo中一条文档数据。
属性:( value 、collection )用来指定操作的集合名称
-
@Id
修饰范围: 用在成员变量、方法上
作用: 用来将成员变量的值映射为文档的_id的值
-
@Field
修饰范围: 用在成员变量、方法上
作用: 用来将成员变量及其值映射为文档中一个key:value对。
属性:( name , value )用来指定在文档中 key的名称,默认为成员变量名
-
@Transient 修饰范围:用在成员变量、方法上 作用:用来指定此成员变量不参与文档的序列化
创建实体
@Document("emp") //对应emp集合中的一个文档
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Employee {
@Id //映射文档中的_id
private Integer id;
@Field("username")
private String name;
@Field
private int age;
@Field
private Double salary;
@Field
private Date birthday;
}
添加文档
insert方法返回值是新增的Document对象,里面包含了新增后id的值。如果集合不存在会自动创建集 合。通过Spring Data MongoDB还会给集合中多加一个class的属性,存储新增时Document对应Java中 类的全限定路径。这么做为了查询时能把Document转换为Java类型。
Employee employee = new Employee(1, "小明", 30,10000.00, new Date());
//添加文档
// sava: _id存在时更新数据
//mongoTemplate.save(employee);
// insert: _id存在抛出异常 支持批量操作
mongoTemplate.insert(employee);
List<Employee> list = Arrays.asList(
new Employee(2, "张三", 21,5000.00, new Date()),
new Employee(3, "李四", 26,8000.00, new Date()),
new Employee(4, "王五",22, 8000.00, new Date()),
new Employee(5, "张龙",28, 6000.00, new Date()),
new Employee(6, "赵虎",24, 7000.00, new Date()),
new Employee(7, "赵六",28, 12000.00, new Date()));
//插入多条数据
mongoTemplate.insert(list,Employee.class);
查询文档
Criteria是标准查询的接口,可以引用静态的Criteria.where的把多个条件组合在一起,就可以轻松地将 多个方法标准和查询连接起来,方便我们操作查询语句。
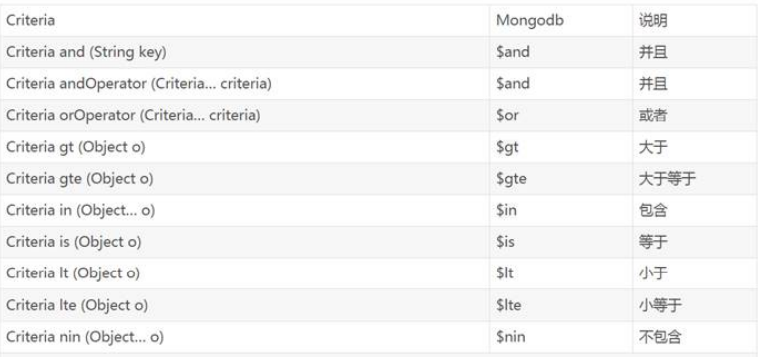
- 使用Query查询
System.out.println("==========查询所有文档===========");
//查询所有文档
List<Employee> list = mongoTemplate.findAll(Employee.class);
list.forEach(System.out::println);
System.out.println("==========根据_id查询===========");
//根据_id查询
Employee e = mongoTemplate.findById(1, Employee.class);
System.out.println(e);
System.out.println("==========findOne返回第一个文档===========");
//如果查询结果是多个,返回其中第一个文档对象
Employee one = mongoTemplate.findOne(new Query(), Employee.class);
System.out.println(one);
System.out.println("==========条件查询===========");
//new Query() 表示没有条件
//查询薪资大于等于8000的员工
//Query query = new Query(Criteria.where("salary").gte(8000));
//查询薪资大于4000小于10000的员工
//Query query = new Query(Criteria.where("salary").gt(4000).lt(10000));
//正则查询(模糊查询) java中正则不需要有//
//Query query = new Query(Criteria.where("name").regex("张"));
//and or 多条件查询
Criteria criteria = new Criteria();
//and 查询年龄大于25&薪资大于8000的员工
//criteria.andOperator(Criteria.where("age").gt(25),Criteria.where("salary").gt(8000));
//or 查询姓名是张三或者薪资大于8000的员工
criteria.orOperator(Criteria.where("name").is("张三"),Criteria.where("salary").gt(5000));
Query query = new Query(criteria);
//sort排序
//query.with(Sort.by(Sort.Order.desc("salary")));
//skip limit 分页 skip用于指定跳过记录数,limit则用于限定返回结果数量。
query.with(Sort.by(Sort.Order.desc("salary")))
.skip(0) //指定跳过记录数
.limit(4); //每页显示记录数
//查询结果
List<Employee> employees = mongoTemplate.find(
query, Employee.class);
employees.forEach(System.out::println);
-
使用JSON字符串查询
//使用json字符串方式查询 //等值查询 //String json = "{name:'张三'}"; //多条件查询 String json = "{$or:[{age:{$gt:25}},{salary:{$gte:8000}}]}"; Query query = new BasicQuery(json); //查询结果 List<Employee> employees = mongoTemplate.find( query, Employee.class); employees.forEach(System.out::println);
更新文档
在Mongodb中无论是使用客户端API还是使用Spring Data,更新返回结果一定是受行数影响。如果更新 后的结果和更新前的结果是相同,返回0。
- updateFirst() 只更新满足条件的第一条记录
- updateMulti() 更新所有满足条件的记录
- upsert() 没有符合条件的记录则插入数据
//query设置查询条件
Query query = new Query(Criteria.where("salary").gte(15000));
System.out.println("==========更新前===========");
List<Employee> employees = mongoTemplate.find(query, Employee.class);
employees.forEach(System.out::println);
Update update = new Update();
//设置更新属性
update.set("salary",13000);
//updateFirst() 只更新满足条件的第一条记录
//UpdateResult updateResult = mongoTemplate.updateFirst(query, update,Employee.class);
//updateMulti() 更新所有满足条件的记录
//UpdateResult updateResult = mongoTemplate.updateMulti(query, update,Employee.class);
//upsert() 没有符合条件的记录则插入数据
//update.setOnInsert("id",11); //指定_id
UpdateResult updateResult = mongoTemplate.upsert(query, update,Employee.class);
//返回修改的记录数
System.out.println(updateResult.getModifiedCount());
System.out.println("==========更新后===========");
employees = mongoTemplate.find(query, Employee.class);
employees.forEach(System.out::println);
删除文档
//删除所有文档
//mongoTemplate.remove(new Query(),Employee.class);
//条件删除
Query query = new Query(Criteria.where("salary").gte(10000));
mongoTemplate.remove(query,Employee.class);
聚合操作
match精准匹配
//精准匹配
MatchOperation salary1 = Aggregation.match(Criteria.where("salary").is(8000).and("age").lt(26));//精准匹配 salary=8000 and age<26
match范围匹配
//范围匹配
MatchOperation salary2 = Aggregation.match(Criteria.where("salary").gte(6000).lt(10000));//匹配salary>=6000 and salary <10000的数据
group分组统计
//分组统计
GroupOperation group = Aggregation.group("salary").sum("1").as("count");//根据salary分组,并且获得同样数值出现次数,以“count”字段输出
limit查询N条记录(分页)
//查询N条记录(分页)
LimitOperation limit = Aggregation.limit(1);//查询一条记录(分页:每页多少条数据)
skip结果中跳过N条记录(分页)
//结果中跳过N条记录(分页)
SkipOperation skip = Aggregation.skip(1l);//在结果中跳过第一条,从第二条开始显示(分页:读取多少页的数据=页数*每页条数)
count查询结果中总条数(分页)
//查询结果中总条数(分页)
CountOperation count = Aggregation.count().as("count");//查询结果中总条数(分页:总记录数)
根据上面查出的每页多少条数据、读取多少页的数据、总记录数,可实现分页
project别名、显示|隐藏字段
//别名、显示|隐藏字段
Field field1 = Fields.field("uname", "username");//设置别名,将字段名username映射为uname返回
Field field2 = Fields.field("uage", "age");//设置别名,将字段名age映射为uage返回
Fields fields = Fields.from(field1,field2);
ProjectionOperation projectAS1 = Aggregation.project(fields);//这时就会只查出uname,uage两列,这种方式默认不会查出_id字段
ProjectionOperation projectAS2 = Aggregation.project("username").andExclude("_id");//只查询username字段,并且把默认展示的_id去掉
match模糊查询
//模糊查询 匹配name字段中包含“小”的
MatchOperation regex = Aggregation.match(Criteria.where("name").regex("小"));
sort排序
SortOperation sort1 = Aggregation.sort(Sort.by(Sort.Order.desc("_id")));
lookup跨集合查询(join连表查询)
//join连表查询
LookupOperation lookup1 = Aggregation.lookup("emp", "userId", "_id", "user");//连表查询:order中有userid和emp中_id关联
LookupOperation lookup2 = Aggregation.lookup("item", "orderNo", "orderNo", "items");//连表查询:item中有orderNo和order中orderNo关联
MatchOperation match = Aggregation.match(Criteria.where("orderNo").is("orderNo"));//连表查询:查询条件只能是order中的字段
//注意:不支持像mysql中 a表关联b表,b表关联c表,c表关联d表,查找的主表必须要和子表有关联关系,我没找到lookup还有没有其他的方式
TypedAggregation<Order> typedAggregation =Aggregation.newAggregation(Order.class,sort1,lookup1,lookup2);//将管道封装进Aggregation,连表查询结果
排序去除数据100M大小限制
AggregationOptions aggregationOptions = AggregationOptions.builder().allowDiskUse(true).build();//内存中排序有100M的限制,要执行大型排序,需要启用allowDiskUse选项将数据写入临时文件以进行排序
typedAggregation.withOptions(aggregationOptions);
应用定义的管道
根据业务,调整管道的顺序,放到Aggregation.newAggregation中
TypedAggregation<Order> typedAggregation =Aggregation.newAggregation(Order.class,sort1,lookup1,lookup2,。。。。。);
aggregate执行查询
//执行查询,类型可定义成对象
AggregationResults<Map> aggregate = mongoTemplate.aggregate(typedAggregation, Map.class);
List<Map> mappedResults = aggregate.getMappedResults();
mappedResults.forEach(System.out::println);
常用的差不多就这些,其他的命令同理,无非就是先通过Aggregation创建一个管道,然后根据业务,调整管道的顺序,放到Aggregation.newAggregation中
事务
用SpringBoot的MongoTemplate,有两种方式
- 注解
@Transactional
- 添加配置
@Configuration
public class TransactionConfig {
@Bean
MongoTransactionManager transactionManager(MongoDbFactory factory){
return new MongoTransactionManager(factory);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号